原文标题 :How to Forecast Time Series Data Using Deep Learning
如何使用深度学习预测时间序列数据
亚马逊开发的自回归循环神经网络
时间序列 (TS) 预测是出了名的挑剔。也就是说,直到现在。
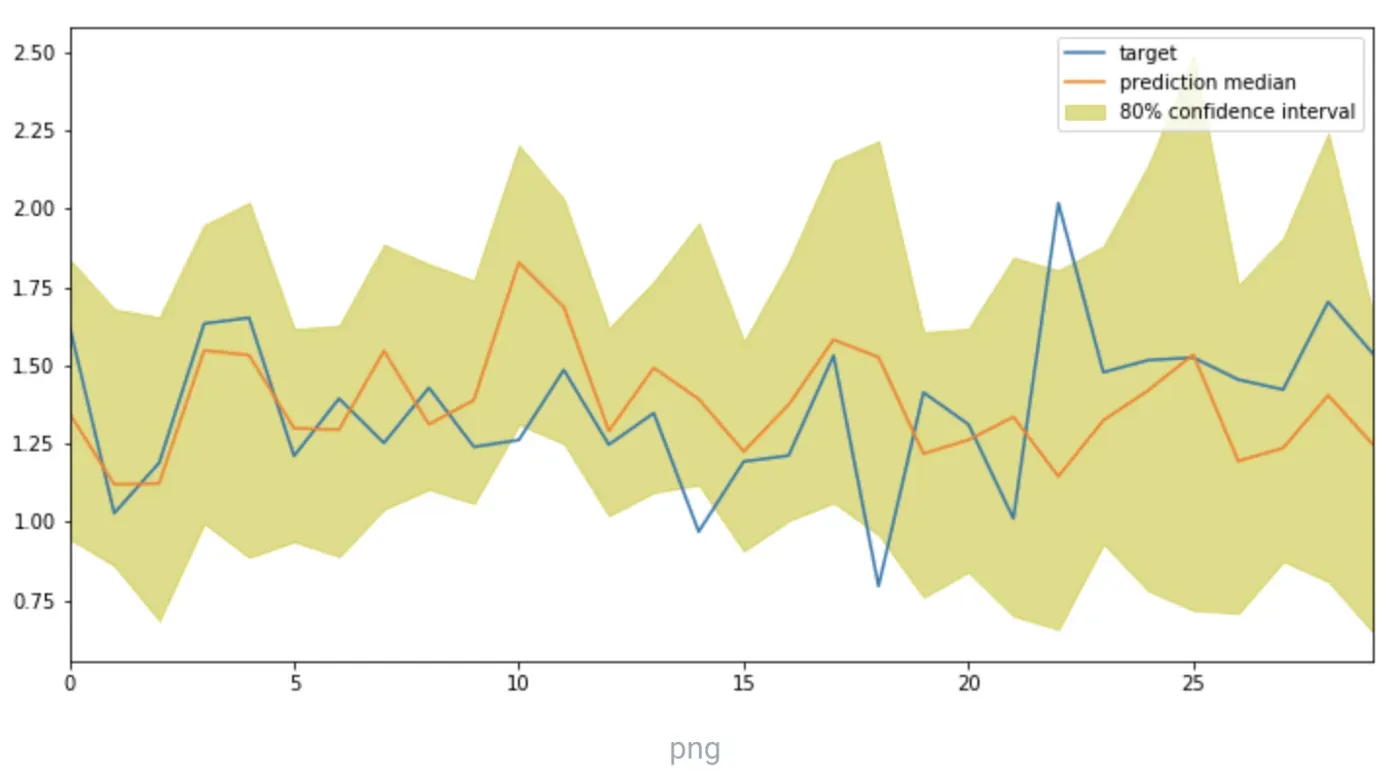
2019 年,亚马逊的研究团队开发了一种名为 DeepAR 的深度学习方法,与最先进的 TS 预测模型相比,该方法的准确率提高了约 15%。它开箱即用,可以从许多不同的时间序列中学习,因此如果您有大量不稳定的数据,DeepAR 可能是一个有效的解决方案。
从实现的角度来看,DeepAR 在计算上比其他 TS 方法更复杂。它还需要比 ARIMA 或 Facebook 的先知等传统 TS 预测方法更多的数据。
话虽如此,如果您有大量复杂的数据并且需要非常准确的预测,那么 DeepAR 可以说是最强大的解决方案。
Technical TLDR
简而言之,DeepAR 是一种 LSTM RNN,具有一些花里胡哨的功能,可以提高复杂数据的准确性。相对于传统的 TS 预测方法,DeepAR 有 4 个主要优势……
- DeepAR 可以有效地通过最少的调整来学习季节性依赖关系。这种开箱即用的性能使该模型成为 TS 预测的良好起点。
- DeepAR 可以使用几乎没有训练历史的协变量。通过利用类似的观察和加权重采样技术,该模型可以有效地确定不频繁协变量的行为方式。
- DeepAR 进行概率预测。这些概率,以蒙特卡罗样本的形式,可用于开发分位数预测。
- DeepAR 支持广泛的似然函数。如果您的因变量呈现非正态或非连续分布,您可以指定相关的似然函数。
该模型受到了很多关注,目前在 PyTorch 中得到支持。教程和代码在评论中链接。
但是,究竟发生了什么?
好的,让我们放慢速度,讨论一下亚马逊的 DeepAR 模型是如何工作的……
传统时间序列预测
让我们从第一格开始。
如上所述,时间序列预测非常困难,主要有两个原因。首先是大多数时间序列模型需要大量的主题知识。如果您使用传统的 TS 模型对股票价格进行建模,重要的是要了解哪些协变量会影响价格,这些协变量的影响是否存在延迟,价格是否呈现季节性趋势等。
工程师通常缺乏创建有效特征所需的主题知识。
第二个原因是 TS 建模是一个非常小众的技能组合。给定时间步的先前输出是下一个时间步的输入,因此我们不能使用通常的建模技术或评估标准。
因此,工程师不仅需要对数据有深入的了解,还必须对 TS 建模技术有深入的了解。
传统的递归神经网络 (RNN)
机器学习可以提供传统 TS 预测的替代方案,这些预测通常更准确且更易于构建。支持序列数据的最简单的 ML 算法是循环神经网络。
RNN 本质上是一堆堆叠在一起的神经网络。 h1 处模型的输出馈送到 h2 处的下一个模型,如图 2 所示。
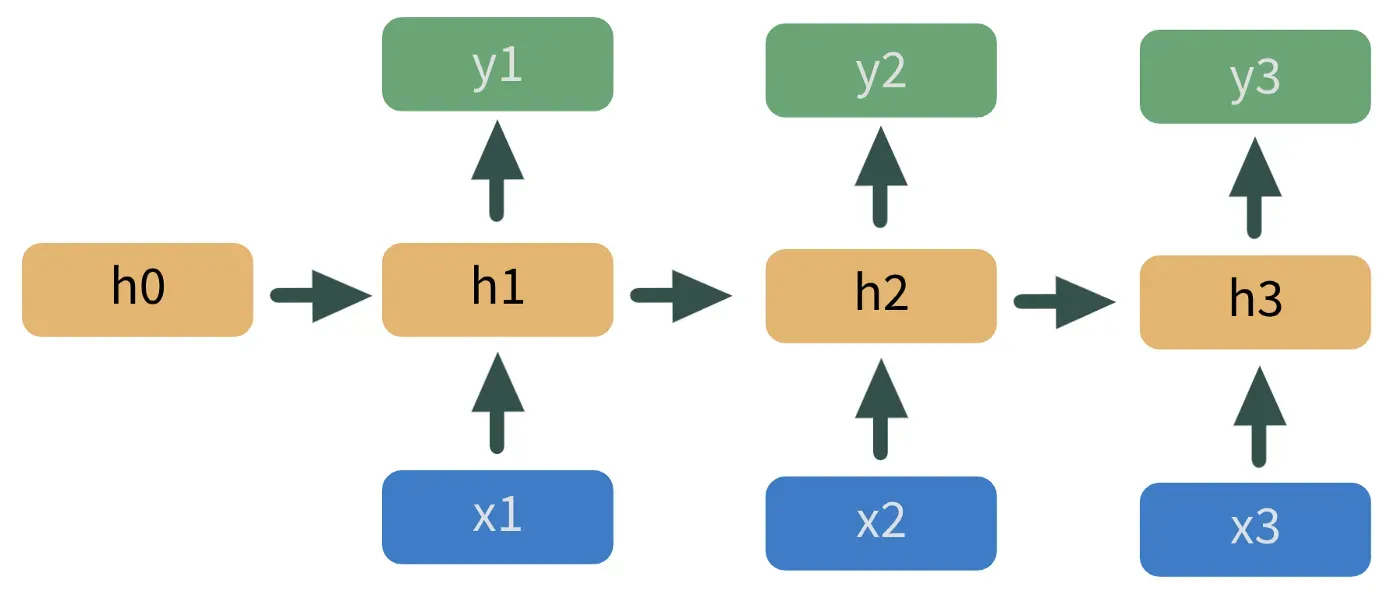
这里,蓝色的 x 是预测变量,黄色的 h 是隐藏层,绿色的 y 是预测值。这种模型架构会自动处理我们上面讨论的许多挑战。
但即使是 RNN 在某些领域也存在不足。首先,他们对应该传递给下一个隐藏层的内容的假设过于简单化。 RNN 的更高级组件,例如长短期记忆 (LSTM) 和门循环单元 (GRU) 层,为哪些信息在链中传递提供了过滤器。而且它们通常提供比普通 RNN 更好的预测,但遗憾的是它们也可能达不到要求。
亚马逊的 DeepAR 模型是 LSTM 的最新迭代,解决了它的两个主要缺点:
- 由于采样分布均匀,异常值拟合不佳。 DeepAR 的优势之一是它聚合了来自许多时间序列的信息,以开发单个单元的预测,例如一个用户。如果所有单位都有相同的抽样机会,异常值就会被平滑,我们的预测值会变得不那么极端(并且可能不太准确)。
- RNN 不能很好地处理时间缩放。随着时间的推移,时间序列数据通常会表现出总体趋势——想想你在 COVID 期间最喜欢(或最不喜欢)的股票。这些时间趋势使拟合我们的模型变得更加困难,因为它必须在拟合时移除这种趋势,然后将其添加回我们的模型输出。这是很多不必要的工作。
DeepAR 解决了这两个问题。
DeepAR 是如何工作的?
基于 RNN 架构,DeepAR 使用 LSTM 单元将我们的预测变量与我们感兴趣的变量相匹配。就是这样…
序列到序列编码器-解码器
首先,为了使我们的数据更有用,我们利用序列对编码器-解码器进行序列化。该方法采用一组 n 个输入,用神经网络对这些输入进行编码,然后输出 m 个解码值。
有趣的事实——它们是所有语言翻译算法的支柱,比如谷歌翻译。因此,使用下面的图 3,让我们从将英语翻译成西班牙语的角度来考虑这种方法。
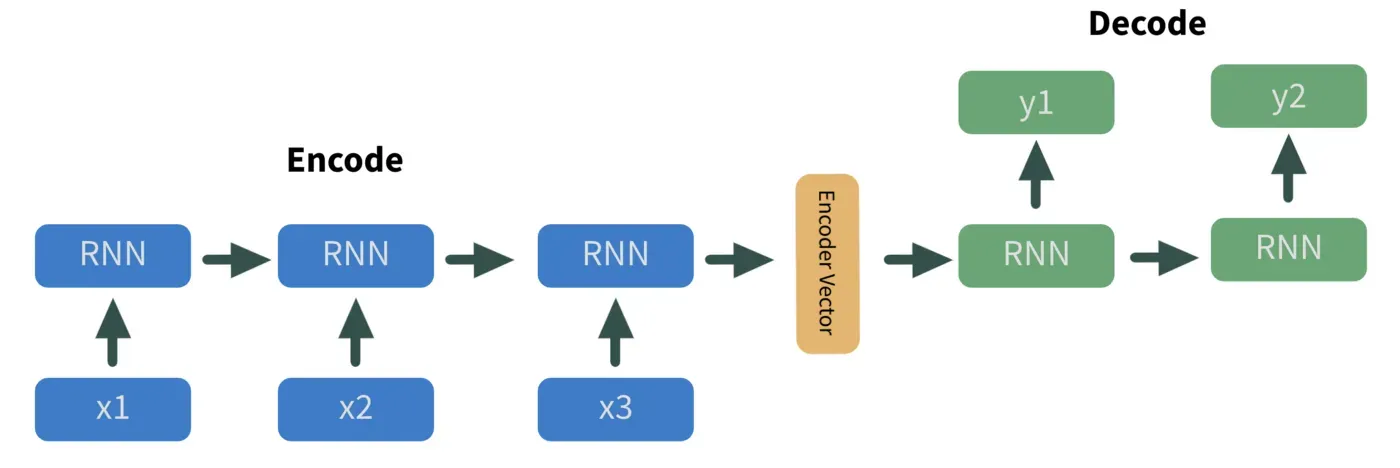
在这里,蓝色的每个 x_n 值都是我们模型的输入,即英文单词。它们被依次输入到 RNN 中,RNN 对它们的信息进行编码并将其作为编码器向量(黄色)输出。编码器向量的信息表示为我们隐藏状态的权重向量。从那里,我们的编码器向量被输入到我们的解码器,这是一个 RNN。最终输出,以绿色标记为 y_n,是西班牙语单词。
Pretty cool, right?
根据我们的数据进行扩展
其次,我们解决了使基本 LSTM 不如 DeepAR 的两个问题:均匀采样和时间缩放。
这两个都是使用比例因子处理的。缩放因子是用户指定的超参数,但推荐值只是给定时间序列的平均值:
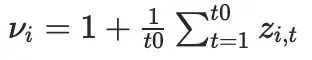
为了处理极值的不均匀采样,我们使采样概率与 v_i 成正比。因此,如果给定时间序列的平均值较高,则更有可能对其进行抽样,反之亦然。
为了处理时间缩放,我们将每个 LSTM 单元的输入除以 v_i。通过在将我们的值输入到每个单元格之前缩小我们的值,我们的模型可以专注于我们的预测变量和结果变量之间的关系,而不是拟合时间趋势。在单元格适合我们的数据后,我们将其输出乘以 v_i 以将我们的数据返回到其原始比例。
不那么酷,但仍然很酷。还有一个部分要走……
使用似然函数拟合
第三也是最后一点,在处理完所有复杂数据后,在给定预测变量和模型参数的情况下,我们通过最大化因变量的条件概率来拟合(图 5)。该估计器称为最大似然估计器 (MLE)。
上面的简化表达式是我们想要最大化的——我们想要找到使因变量 (z) 的概率最大化的模型参数 (θ)。我们还以协变量 (x_t) 和先前节点的输出 (z_t-1) 为条件。
因此,给定我们的协变量和前一时间步的预测值,我们可以找到最大化在给定参数的情况下进行观察的可能性的参数值。
现在可能性还包括一个数据转换步骤,但从理解和实现的角度来看,它并不是非常重要。如果您好奇,请查看评论中链接的论文。
有了它——简而言之,DeepAR。在你去这里之前,有一些关于实施该方法的实用技巧……
Implementation Notes
- 作者建议标准化协变量,即减去均值并除以标准差。
- 丢失数据可能是 DeepAR 的一个大问题。作者建议通过从条件预测分布中抽样来估算缺失数据。
- 对于论文中引用的示例,作者创建了与时间信息相对应的协变量。一些例子是年龄(以天为单位)和星期几。
- 使用网格搜索优化参数是调整模型的有效方法。但是,学习率和编码器/解码器长度是特定于主题的,应该手动调整。
- 为了确保模型不适合基于我们在 TS 中的因变量的索引,作者建议在我们的开始阶段之前在“空”数据上训练模型。只需使用一堆零作为我们的因变量。
谢谢阅读!我将再写 41 篇将“学术”研究带入 DS 行业的文章。查看我对构建 DeepAR 模型的链接/教程的评论。
文章出处登录后可见!