原文标题 :TabNet: The End of Gradient Boosting?
TabNet:梯度提升的终结?
TabNet 在表格数据上平衡了可解释性和模型性能,但它能否取代增强树模型?
Introduction
长期以来,XGBoost、LightGBM 和 Catboost 等梯度提升模型一直被认为是表格数据中最好的模型。即使在 NLP 和计算机视觉方面取得了快速进展,神经网络仍然经常被基于树的表格数据模型所超越。[0]
2019 年进入谷歌的 TabNet。根据论文,该神经网络能够在各种基准测试中超越领先的基于树的模型。不仅如此,它比增强树模型更易于解释,因为它具有内置的可解释性。它也可以在没有任何特征预处理的情况下使用。如果是这样的话……为什么没有流行起来?[0]
TabNet 平衡了可解释性与最先进的性能。它很容易实现,并且需要有限的超参数调整。那么为什么 XGBoost 仍然是 Kaggle 大师的首选武器呢?
本文研究了 TabNet 的理论,并展示了如何实现该模型的一些示例。
Prerequisites
这篇文章适合你,如果……
- 您了解什么是神经网络以及它是如何工作的。
- 您了解 Batch Normalisation、ReLU 和 Gradient Descent 等术语。
- 你已经在神经网络中遇到了注意力的概念。
Table of Contents
- What is TabNet
– Overview
– 它是如何工作的?[0][1][2] - Implementation
– Code
– 为什么可以解释?
– Self Supervised Learning[0][1][2][3] - Conclusion[0]
What is TabNet?
Overview
- TabNet 无需任何预处理即可输入原始表格数据,并使用基于梯度下降的优化进行训练。
- TabNet 在每个决策步骤中使用顺序注意来选择特征,从而实现可解释性和更好的学习,因为学习能力用于最有用的特征。
- 特征选择是基于实例的,例如对于训练数据集的每一行,它可能不同。
- TabNet 采用单一的深度学习架构进行特征选择和推理,这被称为软特征选择。
- 上述设计选择允许 TabNet 启用两种可解释性:可视化特征重要性的局部可解释性以及它们如何组合成一行,以及全局可解释性,量化每个特征对整个数据集的训练模型的贡献。
Key Points
尽管它提供了可解释性,但这是一个复杂的模型。我将尝试总结主要概念,但我强烈建议阅读原始 TabNet 论文以获取技术细节。[0]
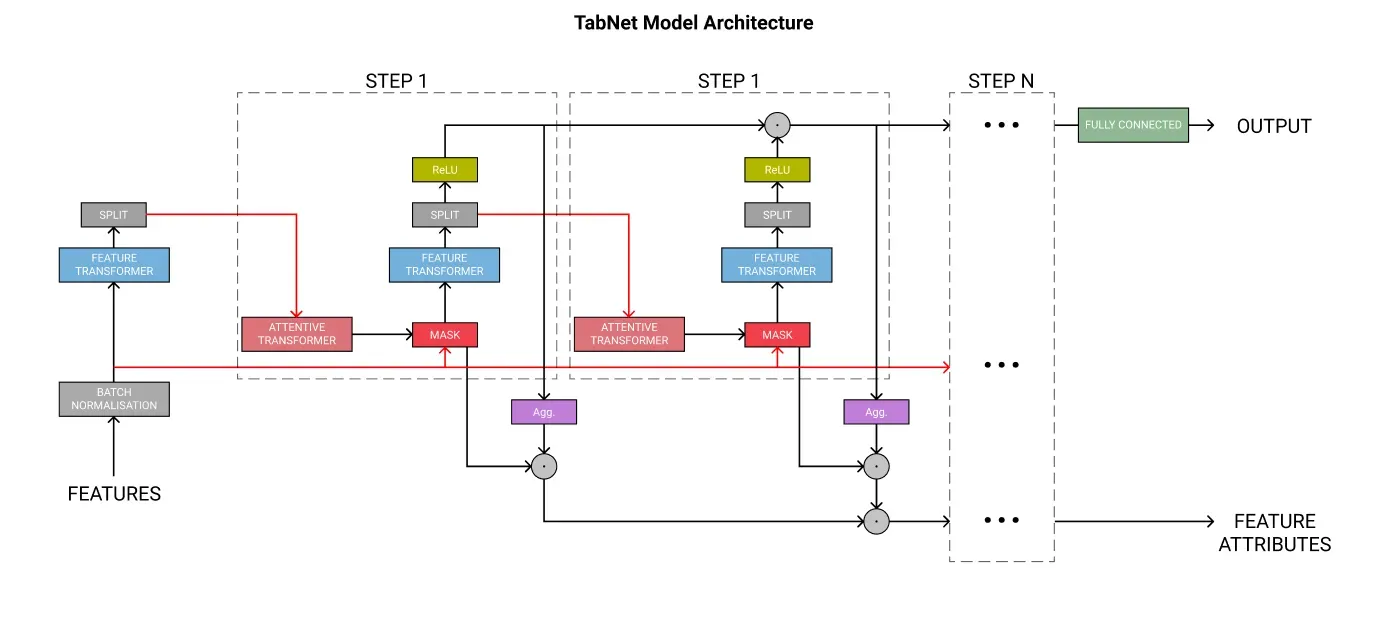
下面的架构图概述了 TabNet 中的不同组件。
Steps
每个步骤都是一个组件块。训练模型时,步数是一个超参数选项。增加这将增加模型的学习能力,但也会增加训练时间、内存使用和过度拟合的机会。
每个步骤在最终分类中都有自己的投票,这些投票的权重相同。这模仿了集成分类。
Feature Transformer
Feature Transformer 是一个拥有自己架构的网络。
它有多个层,其中一些在每个步骤中共享,而另一些对于每个步骤是唯一的。每层都包含一个全连接层、批量归一化和一个门控线性单元激活。如果您不熟悉这些术语,Google 的 ML Glossary 是一个不错的起点。[0]
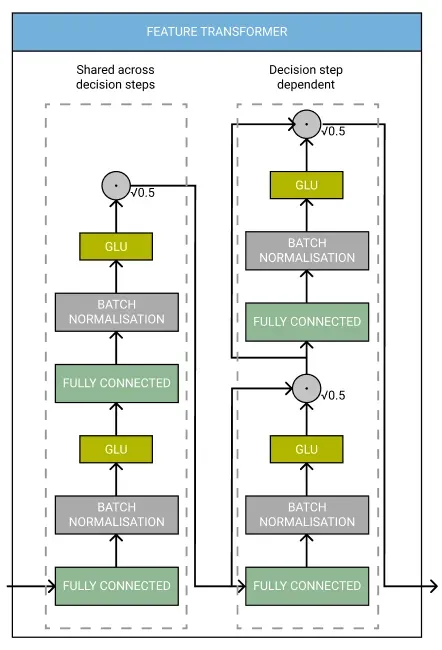
TabNet 论文的作者指出,在决策步骤之间共享一些层会导致“具有高容量的参数高效和稳健的学习”,而根 0.5 的归一化“有助于通过确保整个方差不会发生显着变化来稳定学习”。特征转换器的输出使用 ReLU 激活函数。
Feature Selection
一旦特征被转换,它们就会被传递给 Attentive Transformer 和 Mask 进行特征选择。
Attentive Transformer 由全连接层、批量归一化和 Sparsemax 归一化组成。它还包括先前的比例,这意味着它知道前面的步骤使用了多少每个特征。这用于使用来自先前特征转换器的处理后的特征来派生掩码。
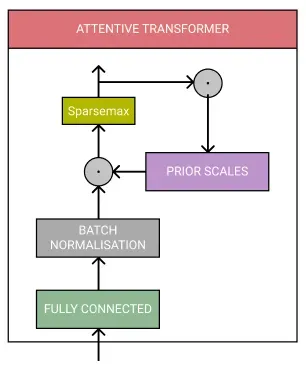
Mask 确保模型专注于最重要的特征,也用于导出可解释性。它基本上涵盖了功能,这意味着该模型只能使用那些被 Attentive Transformer 认为重要的功能。
我们还可以通过查看一个特征对于所有决策和单个预测被屏蔽了多少来理解特征的重要性。
TabNet 在端到端学习中采用稀疏度可控的软特征选择
这意味着一个模型联合执行特征选择和输出映射,从而获得更好的性能。
TabNet 使用实例特征选择,这意味着为每个输入选择特征并且每个预测可以使用不同的特征。
这种特征选择是必不可少的,因为它允许将决策边界推广到特征的线性组合,其中系数决定每个特征的比例,最终导致模型的可解释性
Implementation in PyTorch
使用 TabNet 的最佳方式是使用 Dreamquark 的 PyTorch 实现。它使用 scikit-learn 风格的包装器,并且与 GPU 兼容。该 repo 有很多正在使用的模型示例,因此我强烈建议您查看它。[0]
训练模型其实很简单,几行代码就可以搞定,TabNet 也没有太多的超参数。
Code
Dreamquark 还提供了一些非常棒的笔记本,它们完美地展示了如何实现 TabNet,同时还努力验证原作者声称的模型在某些基准上的准确性。
Classification
Regression
这两个示例都是可重现的,并包含一个 XGBoost 模型来与 TabNet 的性能进行比较。
Explainability
TabNet 相对于 Boosted Trees 的一个关键优势是它更易于解释。如果不使用 SHAP 或 LIME 之类的东西,我们就无法剖析梯度提升中的预测。由于有了掩码,我们可以了解我们的 TabNet 模型在全局(跨整个数据集)和本地(用于单个预测)中使用的特征。
为了探索这一点,我将使用上面的分类示例,该示例使用人口普查收入数据集。
Feature Importances
我们可以查看各个特征的重要性,它们的总和正好等于 1。当我们从基于树的模型中获取这些数据时,它可能会偏向一个变量,或者具有大量唯一值的分类变量。在某些情况下,这可能会歪曲模型实际在做什么。
在这个例子中,我们看到使用 TabNet 时重要性的分布要大得多,这意味着它更平等地使用了特征。这可能不一定更好,并且 TabNet 过程中可能存在缺陷。然而,原始论文的作者确实将特征重要性与合成数据示例进行了比较,发现 TabNet 使用了他们预期的特征。
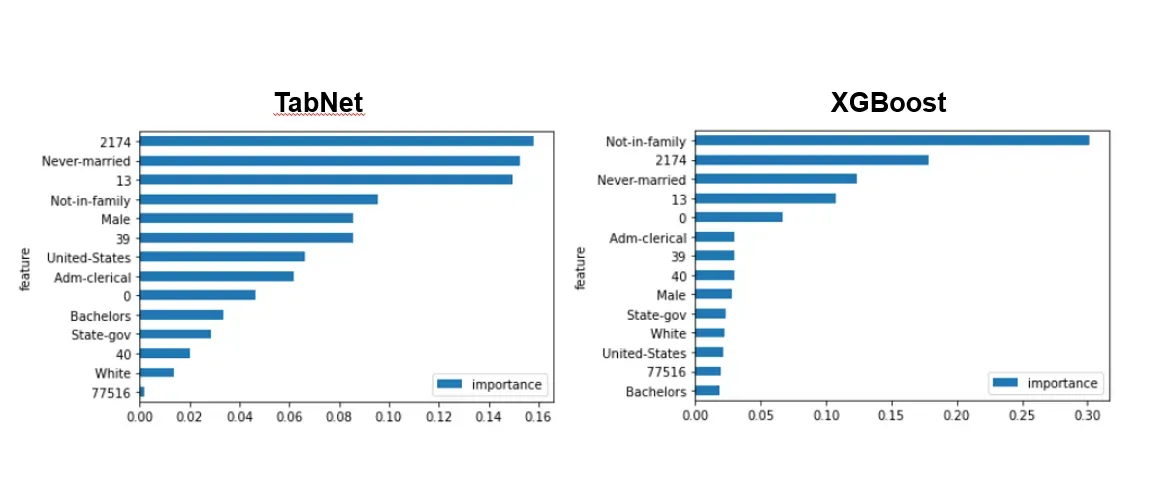
注意:以数字作为特征名称的特征(例如 2174)似乎是匿名特征。
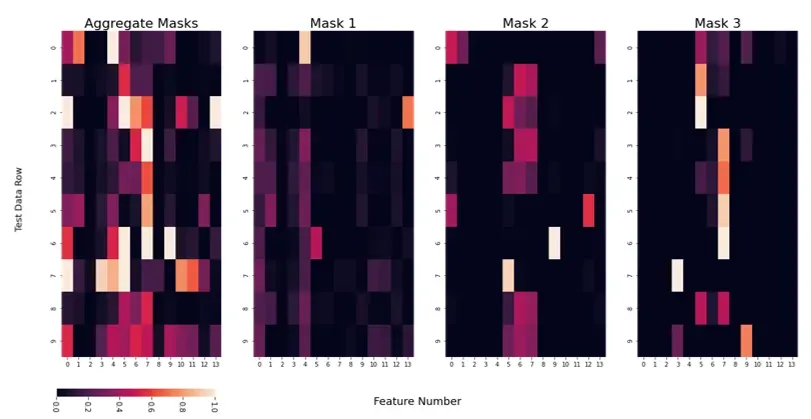
Masks
通过使用掩码,我们可以了解在预测级别使用了哪些特征,我们可以查看所有掩码或单个掩码的聚合。
因此,对于第 0 行,即我们测试数据的第一行,Mask 1 似乎优先考虑数据集中的第 4 个特征,而其他 Masks 使用不同的特征。
这可以让我们了解模型用来进行预测的哪些特征,让我们更有信心,因为我们可以找出模型预测背后的“原因”,并可以帮助我们理解它如何处理看不见的数据。
然而,目前尚不清楚这与实际特征值有何关系——我们不知道模型是否使用该特征,因为它是高还是低。更重要的是,我们无法轻易理解交互术语。
通过自我监督学习改善结果
TabNet 论文还提出将自我监督学习作为一种预训练模型权重并减少训练数据量的方法。
为此,数据集中的特征被屏蔽,模型试图预测它们。然后使用解码器输出结果。
这也可以在 Dreamquark 的包中完成
使用自我监督学习应该可以用更少的训练数据产生更好的结果。
Conclusion
TabNet 是一种用于表格学习的深度学习模型。它使用顺序注意力来选择一个有意义的特征子集,以便在每个决策步骤进行处理。实例特征选择允许模型的学习能力集中在最重要的特征上,模型掩码的可视化提供了可解释性。
希望您能看到 TabNet 允许我们在保持可解释性的同时实现最先进的结果。随着人工智能监管变得更加严格,了解我们的模型如何工作在未来只会变得更加重要。我强烈建议您在下一个项目或 Kaggle 比赛中尝试一下 TabNet!
Learn More
将我的内容直接发送到您的收件箱!
文章出处登录后可见!