YOLOv5代码注释版更新啦,注释的是最近的2021.07.14的版本,且注释更全
github:https://github.com/Laughing-q/yolov5_annotations
Yolov5技术总结
- Backbone
- Detection (YOLO) layer
- 标签分配
- 损失函数
- Yolov5-1.0、2.0、3.0、4.0、5.0
Backbone
Focus:网络第一层进行 pixel un-shuffling而不是stride=2的卷积;该模块的设计主要是减少计算量加快速度;
作者原话:https://github.com/ultralytics/yolov5/issues/847
Focus() module is designed for FLOPS reduction and speed increase, not mAP increase.
Also designed for layer count reduction. 1 Focus module replaces 3 yolov3/4 layers.
SPP:分别采用5/9/13(v5.0采用3/5/7)的最大池化,再进行concat融合,提高感受野;
BottleNeckCSP/C3:Cross Stage Partial Networks,减少计算量,提高卷积神经网络学习能力;
具体网络结构可以查看:Yolov5网络结构
Detection (YOLO) layer
Anchor:根据超参数中的hyp[‘anchor_t’]来检查默认anchor与数据集标签的契合度,如果<0.98,则根据数据集标签进行聚类重新获得anchor;
默认anchor如下:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/3
v5.0:
anchors:
- [ 19,27, 44,40, 38,94 ] # P3/8
- [ 96,68, 86,152, 180,137 ] # P4/16
- [ 140,301, 303,264, 238,542 ] # P5/32
- [ 436,615, 739,380, 925,792 ] # P6/64
参考:https://github.com/ultralytics/yolov5/issues/471
边框回归:在进行边框回归 筛选样本对应anchor的时候,就是通过hyp[‘anchor_t’]来筛选,而不是iou;
新的边界回归方法:
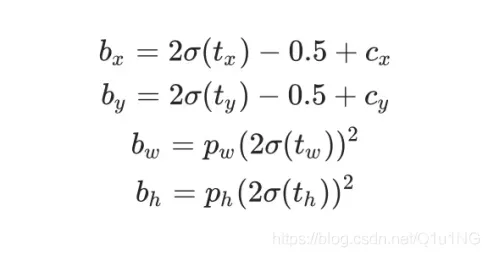
标签分配
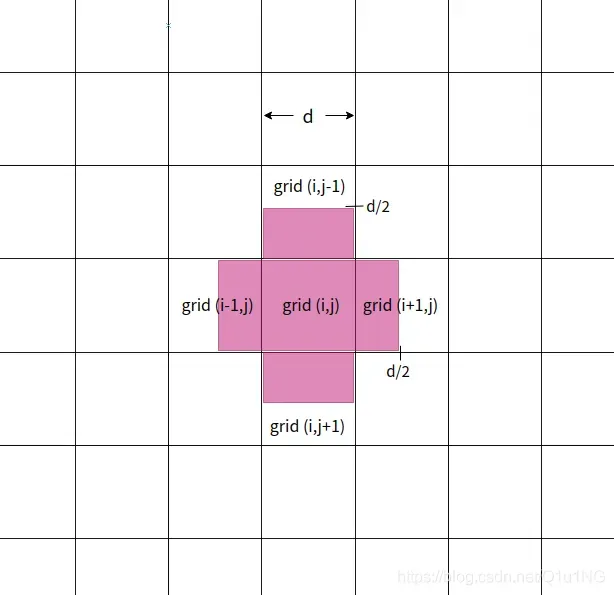
每个网格除了返回中心点在网格中的目标外,还返回中心点在网格附近的周围网格的目标,
grid(i, j)也会回归grid(i, j+1),grid(i, j-1),grid(i+1, j),grid(i-1, j)中的部分框,如下图中红色部分,
这也契合了上面的边框回归中心点的范围为-0.5~1.5;
笔者尝试过如果改成grid(i, j)仅回归中心点在grid(i, j)的目标(边框回归范围依旧是0.5~1.5),
召回率会下降,准确率会上升,但总体map会下降,也就是说yolov5的标签分配应该会带来一定的map提升,
毕竟一个目标采用了更多的anchor去回归,召回率提高也是有道理的;
(当然,我只是在自己的数据集上做了简单的实验)
代码:
off = torch.tensor([[0, 0],
[1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
], device=targets.device).float() * g # offsets
# Matches
r = t[:, :, 4:6] / anchors[:, None] # wh ratio
j = torch.max(r, 1. / r).max(2)[0] < self.hyp['anchor_t'] # compare
# j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
t = t[j] # filter
# Offsets
gxy = t[:, 2:4] # grid xy
gxi = gain[[2, 3]] - gxy # inverse
j, k = ((gxy % 1. < g) & (gxy > 1.)).T
l, m = ((gxi % 1. < g) & (gxi > 1.)).T
j = torch.stack((torch.ones_like(j), j, k, l, m))
t = t.repeat((5, 1, 1))[j]
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
gij = (gxy - offsets).long()
gi, gj = gij.T # grid xy indices
损失函数
边框回归:CIOU loss
Objectness:CIOU
分类:BCE
损失平衡:ciou=0.05,objectness=1, cls=0.5;
三个输出层损失平衡:4.0, 1.0, 0.4分别对应下采样8,16,32的输出层
优化策略:
Warmup热身训练;
Cosine余弦退火;
梯度累积;
EMA;
数据增强:
Mosaic;
仿射变换、随机旋转、平移、缩放、裁剪、上下翻转;
随机hsv;
进行数据增强操作还有一个bbox筛选的过程:
去除被裁剪过小的框(面积小于裁剪前的20%) ,并且还有长和宽必须大于2个像素,且长宽比范围在(1/20, 20)之间的限制;
Yolov5-1.0、2.0、3.0、4.0、5.0
1.0->2.0:
yolov5x mAP有提升,但yolov5s mAP却下降了,
训练策略的改变,包括余弦退火的公式更新了,以及类别损失cls_loss的系数gain,对数据进行仿射变换(dataset.py数据增强部分)的超参数进行调整,三个output的损失比重balance的调整。
2.0->3.0:
V3.0据作者所说,大约10%的推理速度为代价提高了所有模型的mAP。尽管CUDA内存需求增加了约10%,但训练速度并未受到明显影响,具体未测试;
最小的模型从Hardswish()激活中受益最大,YOLOv5s / m / l / x的增加幅度为+0.9/+0.8/+0.7/+0.2mAP@0.5:0.95。
主要做出的变化是,采用了hardswish激活函数替换CONV模块的LeakyReLu,但是注意:BottleneckCSP模块中的LeakyReLu未被替换,采用了CIOU作为损失函数(但这个更新好像是还在v2.0版本过度的时候已经更新),还更改了一个默认超参数:translate=0.5 → 0.1(数据增强的仿射系数)。
3.0->4.0:
更改网络结构:C3模块代替BottleNeckCSP模块,使用SiLU激活函数代替hardswish和leakyrelu;
4.0->5.0:
yolov5s/m/l/x6系列,输入分辨率640 -> 1280,增加一次下采样,增加一层特征金字塔网络(PANet),在coco数据及上map达到55;
spp的最大池化改为3/5/7;
由于没有发paper,只有自己看代码学习,有不正确欢迎指正,谢谢!
附上yolov5代码注释解析
版权声明:本文为博主Laughing-q原创文章,版权归属原作者,如果侵权,请联系我们删除!