原文标题 :A detailed guide to PyTorch’s nn.Transformer() module.
PyTorch 的 nn.Transformer() 模块的详细指南。
分步指南,可全面了解如何实施、训练和推断创新的 Transformer 模型。
我最近越来越多地参与机器学习的世界。当我在理解复杂问题或编码神经网络时遇到问题时,互联网似乎提供了所有答案:从简单的线性回归到复杂的卷积网络。至少我是这么认为的……
一旦我开始在深度学习方面做得更好,我偶然发现了光荣的变压器。原论文:“Attention is all you need”,提出了一种构建神经网络的创新方法。没有更多的卷积!该论文提出了一种由重复的编码器和解码器块组成的编码器-解码器神经网络。结构如下:[0]
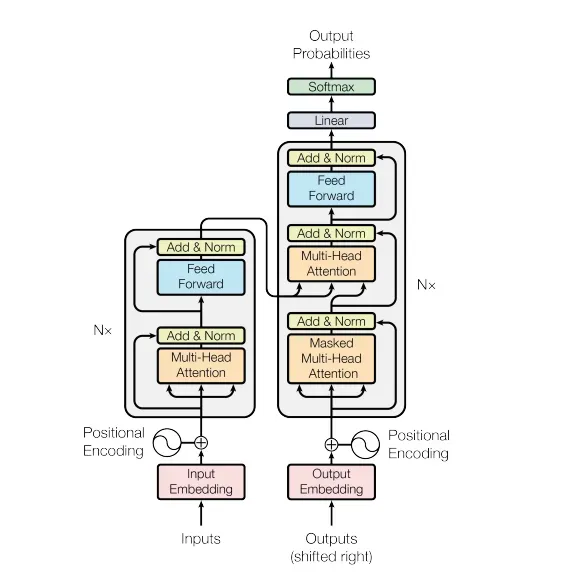
左块是编码器,右块是解码器。如果您还不了解该模型的各个部分,我强烈建议您阅读哈佛的“The Annotated Transformer”指南,他们在其中从头开始在 PyTorch 中编写变压器模型。在本教程中,我不会涉及诸如“多头注意力”或“前馈层”之类的重要概念,因此您应该在继续阅读之前了解它们。如果您已经从头开始查看过代码,您可能想知道是否必须为您创建的每个项目将代码复制粘贴到各处。谢天谢地,没有。 PyTorch 和 Tensorflow 等现代 Python 库已经通过导入包含了易于访问的转换器模型。然而,它不仅仅是导入模型并插入它。今天我将解释如何使用和调整 PyTorch nn.Transformer() 模块。我个人很难找到有关如何实施、训练和推断的信息,因此我决定为大家创建自己的指南。[0][1]
First steps
Imports
首先,我们需要导入 PyTorch 和我们将要使用的其他一些库:
Basic transformer structure
现在,让我们仔细看看变压器模块。我建议首先阅读 PyTorch 的相关文档。正如他们解释的那样,没有强制性参数。该模块带有“Attention is all you need”模型超参数。要使用它,让我们从创建一个简单的 PyTorch 模型开始。我只会更改一些默认参数,这样我们的模型就不会花费不必要的时间来训练。我将这些参数作为我们课程的一部分:[0]
Positional encoding
转换器块不关心输入序列的顺序。这当然是个问题。说“我吃了一个菠萝披萨”和说“一个菠萝吃了我和披萨”是不一样的。幸运的是,我们有一个解决方案:位置编码。这是一种根据元素位置“赋予重要性”的方法。可以在此处找到有关其工作原理的详细说明,但快速解释是我们为每个元素创建一个向量,表示其相对于序列中每个其他元素的位置。位置编码遵循这个看起来非常复杂的公式,在实践中,我们真的不需要理解:[0]
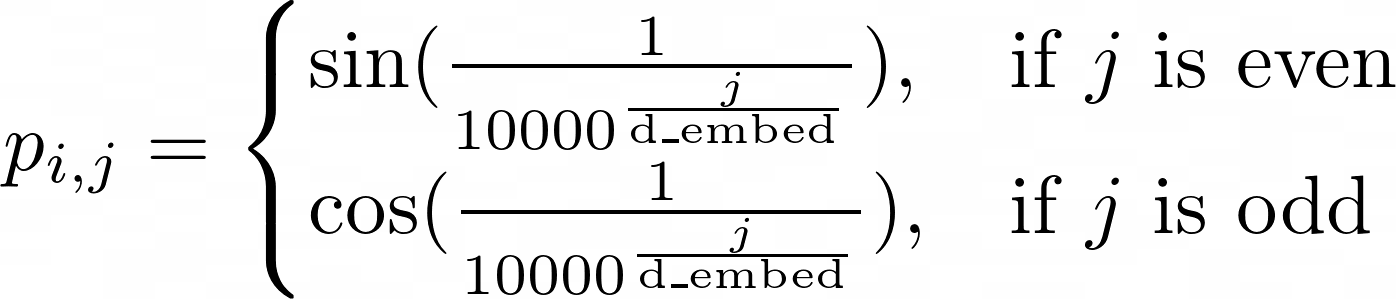
为了组织和可重用性,让我们为位置编码层创建一个单独的类(看起来很难但实际上只是公式、dropout 和残差连接):[0]
Completing our model
现在我们有了唯一没有包含在 PyTorch 中的层,我们已经准备好完成我们的模型了。在添加位置编码之前,我们需要一个嵌入层,以便将序列中的每个元素转换为我们可以操作的向量(而不是固定整数)。我们还需要一个最终的线性层,以便我们可以将模型的输出转换为所需输出的维度。最终模型应如下所示:[0]
我知道……它看起来很吓人,但如果你了解每个部分的作用,它实际上是一个非常简单的模型来实现。
刷新一些重要信息:目标掩蔽
您可能还记得模型结构中有一个特殊的块,称为“masked multi-head attention”:

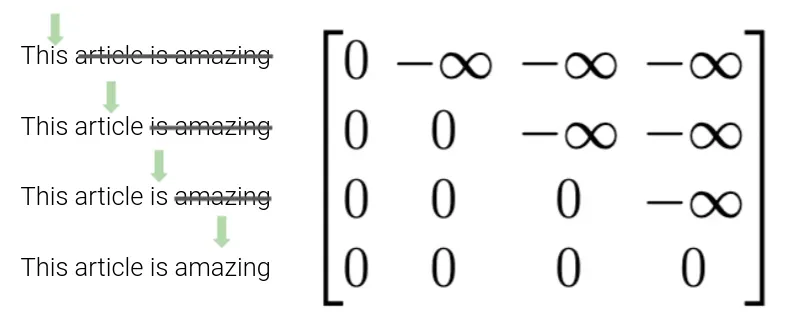
那么……什么是掩蔽?在我向你解释之前,让我们快速回顾一下当我们将张量输入模型时发生了什么。首先,我们嵌入和编码(位置编码)我们的源张量。然后,我们的源张量被编码成一个难以理解的编码张量,我们将其与我们嵌入和编码(位置)的目标向量一起输入我们的解码器。为了让我们的模型学习,我们不能只向它展示整个目标张量!这只会直接给他答案。
对此的解决方案是掩蔽张量。这个张量由大小(序列长度 x 序列长度)组成,因为对于序列中的每个元素,我们都会向模型显示一个更多元素。该矩阵将被添加到我们的目标向量中,因此该矩阵将由变压器可以访问元素的位置的零和不能访问的位置的负无穷大组成。图解说明可能会对您有所帮助:
刷新一些重要信息:padding masking
如果您不知道,张量是可以存储在 GPU 中的矩阵,并且由于它们是矩阵,因此所有维度必须具有相同大小的元素。当然,在处理 NLP 或不同大小的图像等任务时不会发生这种情况。因此,我们使用所谓的“特殊代币”。这些标记让我们的模型知道句子的开头在哪里 (
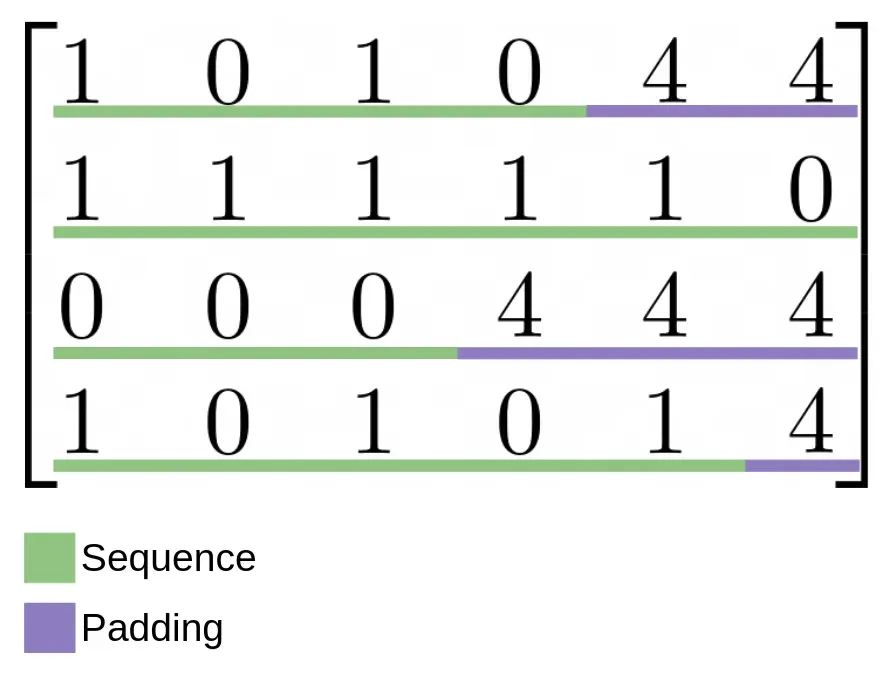
为了告诉我们的模型这些标记应该是不相关的,我们使用一个二进制矩阵,其中填充标记所在的位置有一个 True 值,而没有填充标记的位置有 False:

创建掩蔽方法
要创建我们讨论过的两个掩蔽矩阵,我们需要扩展我们的转换器模型。如果您对 NumPy 有所了解,那么您将毫无问题地理解这些方法的作用。如果你看不懂,我建议你打开一个 Jupyter notebook,一步一步去了解它们是做什么的。[0]
完整的扩展模型如下所示(注意 forward 方法的变化):
Getting our data
为了这个项目,我将创建一组可用于训练模型的假数据。该数据将由以下序列组成:
- 1, 1, 1, 1, 1, 1, 1, 1 → 1, 1, 1, 1, 1, 1, 1, 1
- 0, 0, 0, 0, 0, 0, 0, 0 → 0, 0, 0, 0, 0, 0, 0, 0
- 1, 0, 1, 0, 1, 0, 1, 0 → 1, 0, 1, 0, 1, 0, 1, 0
- 0, 1, 0, 1, 0, 1, 0, 1 → 0, 1, 0, 1, 0, 1, 0, 1
如果您对数据创建部分不感兴趣,请随意跳到下一部分。
我不会费心解释这些函数的作用,因为使用基本的 NumPy 知识它们很容易理解。我将创建所有大小为 8 的句子,这样我就不需要填充,我会将它们随机组织成大小为 16 的批次:
Training & Validation
Training
现在我们有了可以使用的数据,我们可以开始训练我们的模型了。让我们从创建模型、损失函数和优化器的实例开始。我们将使用随机梯度下降优化器、交叉熵损失函数和 0.01 的学习率。我还将使用我的显卡进行此培训,因为它会花费更少的时间,但没有必要。[0][1]
在继续之前我们需要理解的一个重要概念是,我们作为输入到转换器的目标张量必须向右移动一个(与目标输出张量相比)。换句话说,我们要给模型训练的张量必须在开始时有一个额外的元素,在结束时少一个元素,并且我们计算损失函数的张量必须向另一个方向移动。这样一来,如果我们在推理过程中给模型一个元素,它就会给我们下一个元素。

现在我们已经掌握了这个概念,让我们开始编码吧!训练循环是标准训练循环,除了:
- 在预测期间将目标张量传递给模型
- 生成目标掩码以隐藏下一个单词
- 可能会生成填充掩码并将其传递给模型
Validation
验证循环与我们的训练循环完全相同,只是我们不读取或更新梯度:
执行训练和验证
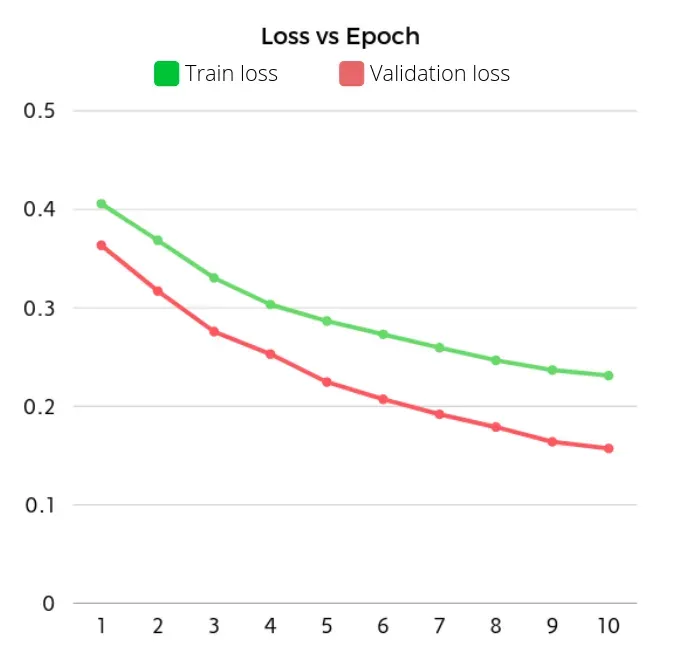
在此示例中,我将模型训练 10 个 epoch。为了简化训练,我创建了一个 fit 函数,它在每个 epoch 调用训练和验证循环并打印损失:
这会产生以下结果
Training and validating model
------------------------- Epoch 1 -------------------------
Training loss: 0.5878
Validation loss: 0.4172------------------------- Epoch 2 -------------------------
Training loss: 0.4384
Validation loss: 0.3981------------------------- Epoch 3 -------------------------
Training loss: 0.4155
Validation loss: 0.3852------------------------- Epoch 4 -------------------------
Training loss: 0.4003
Validation loss: 0.3700------------------------- Epoch 5 -------------------------
Training loss: 0.3842
Validation loss: 0.3443------------------------- Epoch 6 -------------------------
Training loss: 0.3592
Validation loss: 0.3069------------------------- Epoch 7 -------------------------
Training loss: 0.3291
Validation loss: 0.2652------------------------- Epoch 8 -------------------------
Training loss: 0.2956
Validation loss: 0.2195------------------------- Epoch 9 -------------------------
Training loss: 0.2684
Validation loss: 0.1947------------------------- Epoch 10 ------------------------- Training loss: 0.2501
Validation loss: 0.1930
Results
训练后,我们在每个 epoch 中获得以下损失:
Inference
正如我们所看到的,我们的模型似乎学到了一些东西。是时候检查它是否有了,但是……我们如何检查它?对于从未见过的数据,我们没有目标张量。这是改变我们的输入目标和输出目标张量产生影响的地方。正如我们之前看到的,我们的模型学会了在给定一个元素时预测下一个标记。因此,我们应该能够给我们的模型输入张量和起始标记,它应该给我们下一个元素。如果当模型预测一个标记时,我们将它与我们之前的输入连接起来,我们应该能够慢慢地将单词添加到我们的输出中,直到我们的模型预测到
这是该过程的代码:
def predict(model, input_sequence, max_length=15, SOS_token=2, EOS_token=3):
"""
Method from "A detailed guide to Pytorch's nn.Transformer() module.", by
Daniel Melchor: https://medium.com/@danielmelchor/a-detailed-guide-to-pytorchs-nn-transformer-module-c80afbc9ffb1
"""
model.eval()
y_input = torch.tensor([[SOS_token]], dtype=torch.long, device=device)
num_tokens = len(input_sequence[0])
for _ in range(max_length):
# Get source mask
tgt_mask = model.get_tgt_mask(y_input.size(1)).to(device)
pred = model(input_sequence, y_input, tgt_mask)
next_item = pred.topk(1)[1].view(-1)[-1].item() # num with highest probability
next_item = torch.tensor([[next_item]], device=device)
# Concatenate previous input with predicted best word
y_input = torch.cat((y_input, next_item), dim=1)
# Stop if model predicts end of sentence
if next_item.view(-1).item() == EOS_token:
break
return y_input.view(-1).tolist()
# Here we test some examples to observe how the model predicts
examples = [
torch.tensor([[2, 0, 0, 0, 0, 0, 0, 0, 0, 3]], dtype=torch.long, device=device),
torch.tensor([[2, 1, 1, 1, 1, 1, 1, 1, 1, 3]], dtype=torch.long, device=device),
torch.tensor([[2, 1, 0, 1, 0, 1, 0, 1, 0, 3]], dtype=torch.long, device=device),
torch.tensor([[2, 0, 1, 0, 1, 0, 1, 0, 1, 3]], dtype=torch.long, device=device),
torch.tensor([[2, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 3]], dtype=torch.long, device=device),
torch.tensor([[2, 0, 1, 3]], dtype=torch.long, device=device)
]
for idx, example in enumerate(examples):
result = predict(model, example)
print(f"Example {idx}")
print(f"Input: {example.view(-1).tolist()[1:-1]}")
print(f"Continuation: {result[1:-1]}")
print()运行此代码的输出是:
Example 0
Input: [0, 0, 0, 0, 0, 0, 0, 0]
Continuation: [0, 0, 0, 0, 0, 0, 0, 0, 0]Example 1
Input: [1, 1, 1, 1, 1, 1, 1, 1]
Continuation: [1, 1, 1, 1, 1, 1, 1, 1, 1]Example 2
Input: [1, 0, 1, 0, 1, 0, 1, 0]
Continuation: [1, 0, 1, 0, 1, 0, 1, 0]Example 3
Input: [0, 1, 0, 1, 0, 1, 0, 1]
Continuation: [1, 0, 1, 0, 1, 0, 1, 0]Example 4
Input: [0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0]
Continuation: [0, 1, 0, 1, 0, 1, 0, 1, 0]Example 5
Input: [0, 1]
Continuation: [0, 1, 0, 1, 0, 1, 0]
所以该模型确实掌握了我们序列的要点,但在尝试预测延续时仍然会犯一些错误。例如,在“示例 4”中,模型应该预测 1 作为第一个标记,因为输入的结尾是 0。我们还可以看到在推理过程中我们的句子不需要具有相同的长度,并且输出也不会具有相同的长度(参见“示例 5”)。
Conclusion
我相信这篇文章可以帮助很多初学者/中级机器学习开发人员学习如何在 PyTorch 中使用 Transformer 模型,并且由于其他语言的结构相同,本教程可能对 Tensorflow 等其他框架也有用(希望)。
如果您有任何建议或发现任何错误,请随时发表评论,我会尽快修复。
完整的 Colab 笔记本:https://drive.google.com/file/d/15gyTrsd-OU6YZVyjwis48ysrXFPEcv9r/view?usp=sharing[0]
网站:https://danielmelchor.com[0]
联系方式:dmh672@gmail.com[0]
文章出处登录后可见!