因为文本不能直接输入到模型当中从而进行相关计算,所以需要首先需要将文本转换为向量的形式。
把文本转换成向量化的方法主要有两种:
- 转换成one-hot编码
- 转换成word embedding
one-hot 编码
在使用one-hot编码中,我们常常是将每一个token使用一个长度为N的向量来表示,N通常等于编码中词典的数量。通常是先将待处理的文本进行分词或者N-gram预处理,去除重复后得到相应的词典。
例如词典中有4个词语:{‘项目’,‘电脑’,‘手机’,‘导管’},则对应的one-hot编码为:
| token | one-hot encoding |
|---|---|
| 项目 | 1000 |
| 电脑 | 0100 |
| 手机 | 0010 |
| 导管 | 0001 |
由于文本是用稀疏向量表示的,当字典数量很多时,空间开销非常大,所以实际项目中通常不会使用这种方法。
word embedding
word embedding是深度学习中的一种最常用的表示文本的方法。与one-hot 编码不同的是,word embedding使用了一个MxN的浮点型的稠密矩阵来表示token,占用空间会更小。根据词典中的数量M的大小,我们通常使用不同维度的N维向量,N可以是128,256,512等。其中向量中的每一个值是一个超参数,初始值通常是有随机生成,之后会在神经网络训练的过程中学习得到。具体如下:
| token | num | word embedding vector |
|---|---|---|
| 词1 | 0 | [w11,w12,w13,…,w1N] |
| 词2 | 1 | [w21,w22,w23,…,w2N] |
| 词3 | 2 | [w31,w32,w33,…,w3N] |
| … | … | … |
| 词M | M-1 | [wM1,wM2,wM3,…,wMN] |
具体使用的话,通常是先将token使用数字来表示,再把数字用向量来表示。
即:token –> num –> vector
如下所示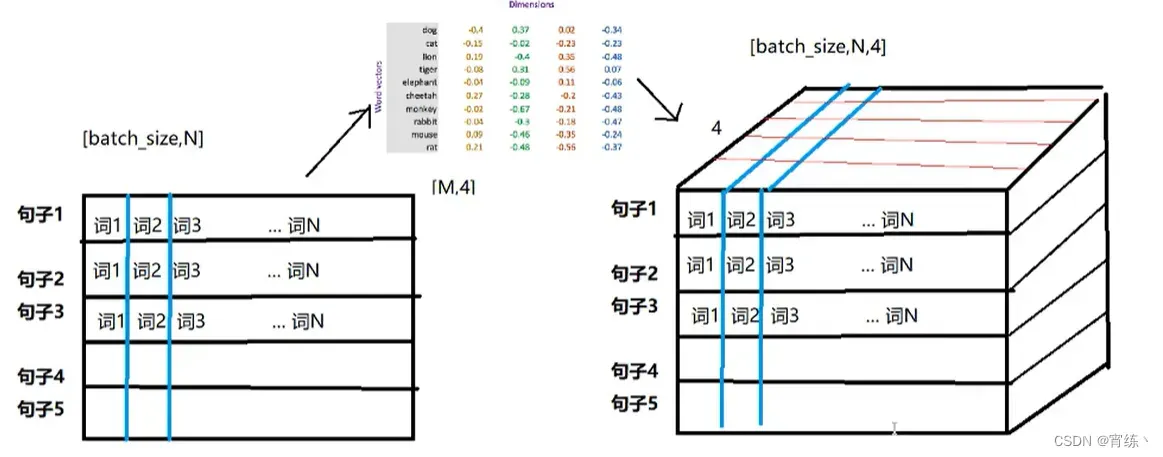
word embedding API
pytorch中的使用方法:
torch.nn.Embedding(num_embedding, embedding_dim)
参数介绍:
- num_embedding:词典的大小
- embedding_dim:词的维度N
Instructions:
import torch.nn as nn
#实例化
embedding = nn.Embedding(vocab, 256)
#进行embedding操作
input_embeded = embedding(word_input)
文章出处登录后可见!
已经登录?立即刷新