文章投稿
提出了一个提取、建模优化语义道路元素的视觉SLAM方法,结合深度学习模型提取语义。
①语义信息提取的深度学习模块;
②道路语义的参数化(用关键点对道路线和路标建模、用分段三次样条曲线参数化车道线)并用其设计了相关的loss function
③用这些信息建立了完整的SLAM系统;
提到语义SLAM相关的综述:
最常用的是基于关键点特征,效率和鲁棒性不够,无法应对光照变化,也不处理高概率消失(即高遮挡)
应对方法之一:利用语义信息建立持久的紧凑的地图,地图构成元素持久,稀疏且经常被观测,可以频繁查询(路标standardized traffic signs、车道线、灯杆等)
除特征点外的常见的高维元素:line、plane、box
系统框架
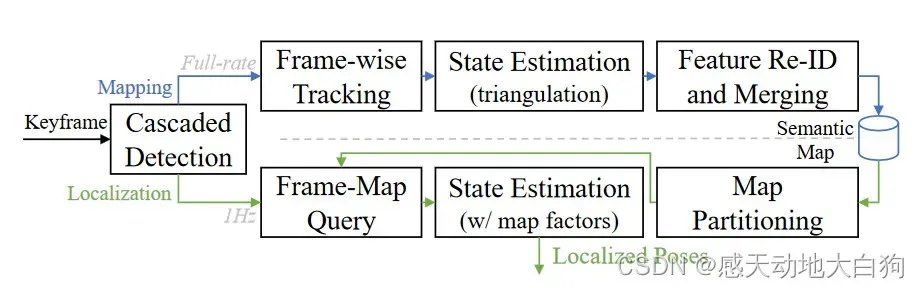
与使用类似框架的现有结果不同,作者使用了各种语义信息
框架分为离线语义图构建+在线定位、带批处理的紧耦合状态优化和滑动窗口策略;
语义实例分为三类:地面上的物体(路灯、路标)、地面元素(左转和右转标志)、线(车道线)
各部分功能
1.Selection of Road Features
选择作为语义标记的元素:
①道路上方的路灯和交通标志稳定,足以被前置摄像头捕捉到;
② 道路上醒目的标志占据了屏幕上大部分的道路信息,虽然大多是被遮挡的;
🌂实线和虚线,实线提供方向约束,虚线矩形块的角点标记为一系列点;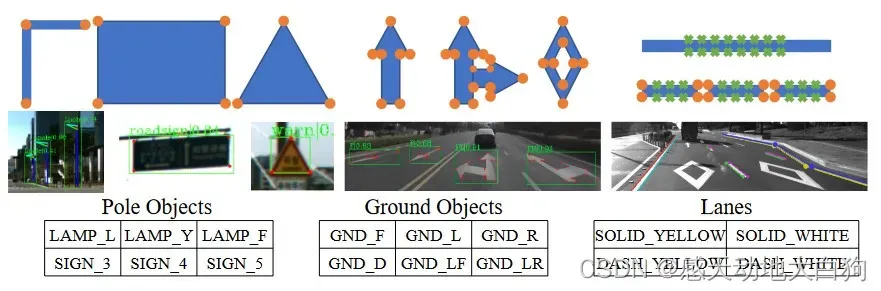
问题:还有其他有用的语义信息吗?
2.Detection of Road Features
两步检测模块:
①物体级检测获取道路上方和道路上的语义信息框,以及车道轮廓上的采样像素
②沿虚线检测虚线的拐角
为了减少前端的重复工作使用无锚检测方法CenterNet(an anchor free detection method CenterNet)
使用DLA-34和DCN module作为特征提取部分。后面这一部分没看懂,好像是设计不同的loss function得到各种具有不同意义的H,然后通过对H的聚类得到属于哪一类语义信息?
①Object boxes and keypoints:在CenterNet的基础基础上提出六个head用于检测这类语义;
②Lanes:输出左右边界点和上下边界点,
是个左右边界点 or 上下边界点 or 都不是的三分类,
用于降低位置特征的维度,最后通过DBSCAN聚类;
🌂Dashed lane corners:给定64*64的图像检测角点练成线段表示虚线块,计算角度上的differences,
计算长度上的differences;
3.Feature Tracking for Semantic Entities
对于地面上的标志和车道线等地面物体ground objects的追踪,相较于常见的追踪多了一个有趣的约束:表示特征点在某个平面上,其中:
①表示像素点反投影到世界坐标系的坐标
②表示一个世界坐标系下的平面,其物理意义为ground objects像素点所在的地面,对于
上面一点
有:
如何搭配:
使用Hungarian matching strategy,对像素进行物体级(instance-wise)和像素级(pixel-wise)的匹配
①instance-wise:在规则物体的多边形面上和车道线的5像素宽的折线上计算交集(像素点和面怎么做交集?用像素点所在的平面做?)
②pixel-wise:计算重投影误差[0]
对于垂直平面上的路灯等,使用光流法跟踪由GFTT extractor和FREAK descriptor提取的特征点来检测这类语义目标
4.Representation and Initialization of Road Lanes
控制点到模拟车道线
用一系列控制点构造的分段三次Catmull-Rom样条曲线(the piecewise cubic Catmull-Rom spline curves)表示车道线的左右轮廓。分段三次Catmull-Rom样条曲线就是用四个点模拟一段由
到
的曲线,其中
和
控制曲线两端点的朝向,具体公式如下:
其中,
代表控制点之间曲线的弯曲程度,
代表从
到
的某个中间位置。
由此,我们可以将控制点分为
组,并用它们来描述通过
这些控制点的曲线,其方向由
和
控制。
控制点的生成
首先使用3得到一系列车道线上的点组成的点集,然后从中随机取N个样本点组成点集
,用这个点集构造样条曲线
模拟车道线,误差为:
①左项表示拟合曲线与观测曲线上各点的误差,其中通过求解公式
得到;
②右边的item代表正则item,保证了控制点的均匀采样,即两个控制点的距离最好是差;
🌂with项用于初始化确定曲线初始方向的线外点。
表示
在以
为圆心,
为半径的球面上;第二个式子没有看懂;如果
有多个结果的话选择和
在反方向的;
④点的确定与🌂类似;
生成车道线的步骤
①随机选择一个初始点;
②递归随机选取点两侧内的点;
🌂为每个曲线生成最多500组点集,选取各个点集生成的候选曲线中误差项最小的那条
5.State Estimator Design
| 符号 | 意义 | 符号 | 意义 |
|---|---|---|---|
| a | 地面或垂直物体 | i | 物体a在c第几个像素,表示为 |
| b | 曲线 | k | 曲线b的第几个控制点,表示为 |
| c | 照片帧 | m | 曲线b在c的第几个采样点,表示为 |
| j | n | 曲线b的角点,表示为 |
提出5种优化变量
①关键点i在地面或者直立的物体a中的3D位置;
②3中提到的平面表示;
🌂直立物体在全局坐标系下的垂直平面表示为,其中
,它相较于2少一个维度;
④曲线b的控制点;
⑤曲线b上被帧c观测的像素点相关的一个动态参数
,表示曲线上哪个地方(上面有提到),其作用为确保曲线投影的正确性;
五个变量和原始相机位姿构成三个约束:
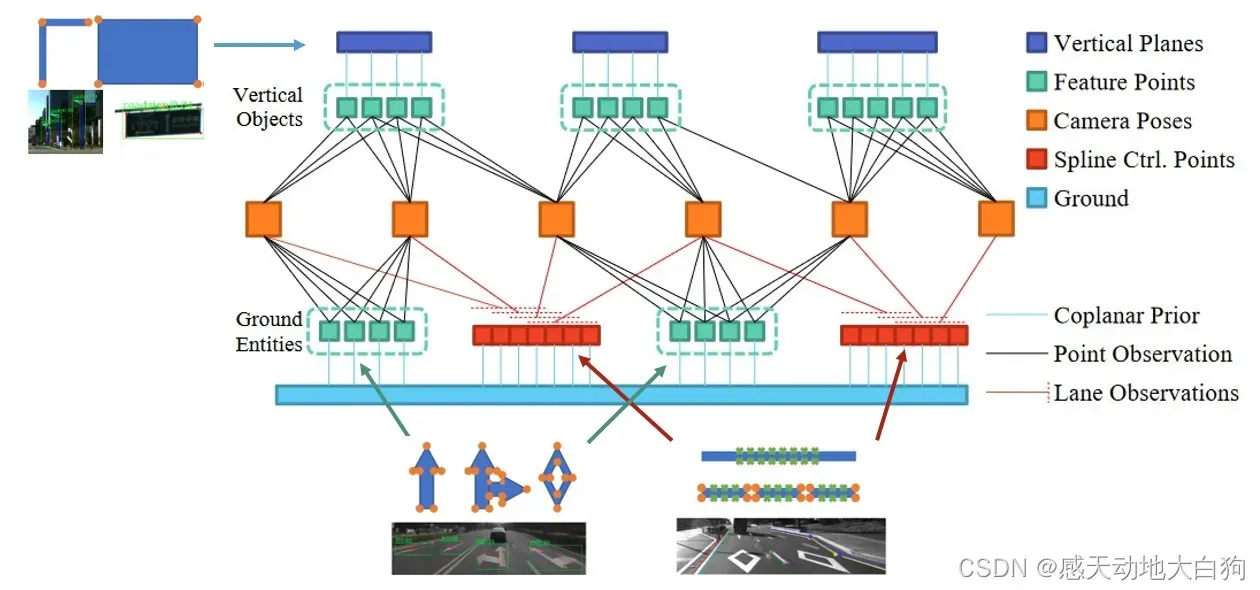
①Points observation factors:常规的重投影误差
②Spline observation factors:曲线观测误差,即曲线上的边沿的点和角点
的投影误差
🌂Coplanar prior factors:平面先验残差,
为水平平面,
为竖直平面,点在平面上的话残差项应该为0
公式中的三个
力的具体含义和具体用法不清楚。
状态估计步骤
①初始化优化变量(这里的理解不一定正确,要对比代码):
1)用GNSS-VIO轨迹中恢复的位姿三角化特征点;
2)将三角化后的地面点转化到观测帧,做3D平面拟合;
3)用已有点对垂直语义对象做2D曲线拟合,得到,然后用于对检测的2D box中的特征点的检测;
4)有了2)后用3计算车道线;
5)求解样条4)的过程中将求解得到的3D association parameter分配给,然后使用独立的非线性优化refine。(后续具体描述没有看懂)
②离线映射:
所有变量都初始化后,用推导的视觉惯导里程计因子图优化,所有的关键帧和检测到的优化变量参与最终的BA优化
🌂在线定位:固定上面①和②式子中的语义要素(语义上的3D点和样条曲线的控制点等),以此来对定位增加约束,实现语义信息在定位中的使用。因为③式是用构建语义时的共面约束,在定位时不再使用。
6.Re-Identification and Feature Merging
Re-Identification:使用3D到3D的语义关联而不是词袋,因为这类信息是稀疏的且在外观上难以辨别。将质心小于5m的三角化物体认为是用一个物体并使用Hungarian strategy合并。对于伴随的GFTT点,使用FREAK描述子在多帧间投票,使用union-find algorithm合并再进行全局状态优化
7.Data Structure of Semantic Maps
语义地图=set(观测帧
,语义路标
,共视图
(连接
和
));
观测保存全局位姿
和GNSS测量值;
垂直的语义路标保存语义信息、点的3D位置
不要存储描述符
8.Localization Based on Semantic Maps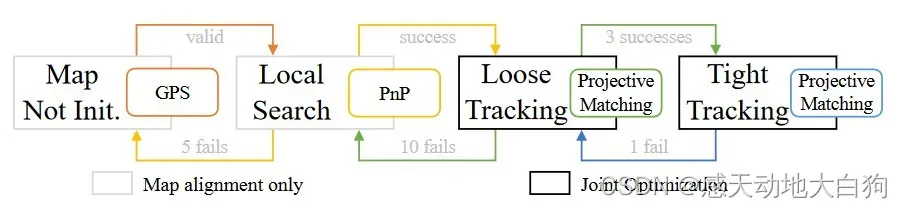
四个阶段
①map uninitialized:地图到当前位姿的转换为止,用GPS得到一小段距离(小于30m)的粗略位置信息,得到观测帧
,并转入②阶段;
②local search:获得标签,建立2D-3D的PnP-Ransac,初始化
并转入🌂④阶段;
🌂④loose tracking和tight tracking:两个tracking阶段设定的阈值不同,都往滑动窗口添加reconstructed associations,并用5中的①和②优化,初始位姿转化为
和
两个变量来优化。将所有map 元素投影到当前帧,用一个准则确定投影关系
阈值
在loose和tight中对deep特征点和classical 特征点的对应值是不同的
question
1、1Hz的在线定位有啥用?
2、怎么区分两个长得相似的语义信息?
3、还有什么可能有用的语义信息?
4、车道采样像素怎么得到?
5、这个网络的选定是怎么让低级别的特征提取分离出来的?
6、网络设计部分再讲什么?
7、只考虑跟踪语义对象吗?
8、文章中提的路灯是有转角的,即倒着的L型,那纯竖着的I型路灯呢?
9、deep and classical keypoints是什么?
文章出处登录后可见!