《老饼讲解机器学习》–一个专业且经典的机器学习网站![]() http://ml.bbbdata.com/teach#199
http://ml.bbbdata.com/teach#199
目录
本文我们详细介绍什么是AUC、ROC,和AUC的具体计算逻辑、实现代码,以及AUC的使用经验值。
开文之前,先特别说明:AUC是专门针对逻辑回归这种输出概率(或评分)的二分类模型设计的模型效果评估指标。
一.划分阈值的意义
对于二分类模型,模型如果输出的是概率或者评分,那么模型是不能直接使用来判别类别的,还需要划分阈值,再根据阈值确定类别。
采用不同的阈值,模型对样本类别的判别结果会不一样,模型也就会有不一样的效果:
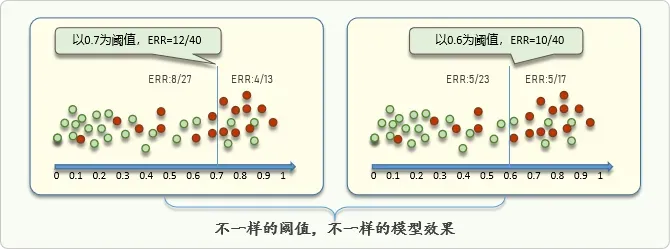
二、阈值划分方法:查全率,虚警率与ROC
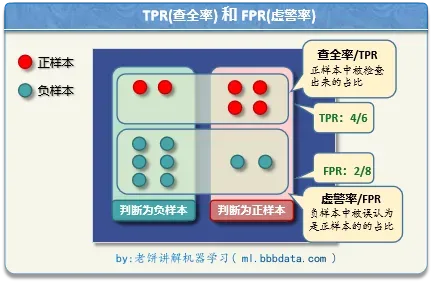
(一) 阈值划分凭据–查全率,虚警率
阈值划分的凭据是什么?
最直接是用准确率进行凭估,即阈值划哪里能令准确率最大,就划哪里。
但在真实案例中,我们并不用准确率去划分阈值,因为我们更关注的是查全率和虚警率。
查全率TPR(True PositiveRate) : 是 1 的样本,被检查出来的占比。
虚警率FPR(False PositiveRate): 是 0 的样本,被误检成1的占比。
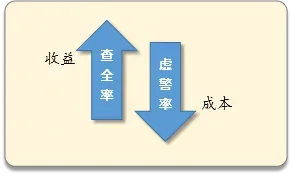
为什么关注查全率(TPR)和虚警率(FPR) ?因为很多时候,查全率就是收益,虚警率就是成本
例如投放广告,我们成功检查出的目标客户,那就是我们的收益。
相反,虚警(0类被检查了1类)是成本,这部分人并非我们的客户,我们误判为是目标客户,就产生了不必要的投放成本。
所以,在实际项目中,最终决定采用哪个阈值,不是根据准确率,而是根据查全率和虚警率,因为我们需要在收益与成本之间权衡,而不是一味追求准确率。
我们希望查全率越高越好,虚警率越低越好。但两者往往不可兼得。
所以,实际中阈值的划分方法是,先算出所有阈值对应的【查全率,虚警率】组合,然后哪组【查全率,虚警率】最适合业务实际需要,我们就把阈值划在哪里。
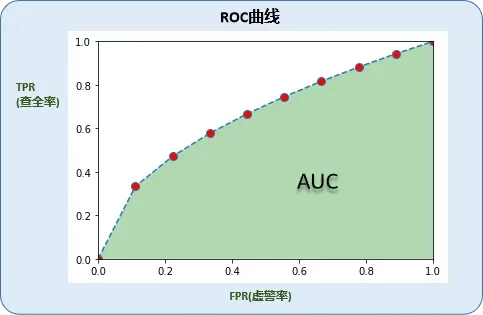
(二)ROC曲线
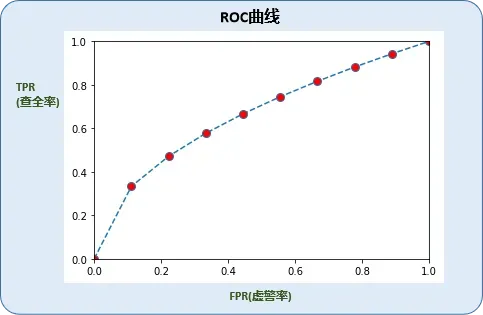
为了更方便找出最佳阈值划分点,可以把虚警率作为x轴,查全率作为y轴,画出如下图表(称为ROC曲线receiver operating characteristic curve):
根据ROC曲线,可以更直观的查看【查全率,虚警率】的各种组合,也就更方便我们找出性价比最好的【查全率,虚警率】(往往是曲线的拐点)。
从图中也可以看到,ROC曲线越往上拱,就代表我们能挑到性价比更好的【查全率,虚警率】。
PASS:把虚警率看作成本,y轴查全率作为收益,ROC曲线则是收益/成本曲线,它体现了随着成本增加,收益的变化情况。
三、所有阈值的综合评估:AUC
我们刚建完模型,并不会马上划分阈值,至少要在ROC曲线足够拱,我们才去划分阈值。(如果ROC太平坦,那我们怎么划都没法找到性价比好的【查全率,虚警率】)。
那怎么评估ROC曲线的拱度呢?直接使用ROC曲线下的面积,面积越大,就代表ROC曲线越拱。ROC曲线下的面积称为AUC(Area Under Curve),即AUC是评估ROC曲线拱度的指标。
AUC越大,代表ROC往上拱得越厉害。而ROC往上拱得越厉害,就代表我们更容易从中选出更优秀的【查全率,虚警率】。
所以,我们刚建完模,第一个看的就是AUC的值,AUC足够大,我们才能找到较好的【查全率,虚警率】组合。因此,AUC也就成为了评估模型优劣的第一指标。
PASS:AUC同时也是查全率对虚警率的积分,所以某种意义上,它代表着平均查全率(相对虚警率)。
四、AUC的使用经验值
那么,AUC要达到多少,我们才挑具体的【查全率,虚警率】组合对呢?
我们通过以下实验进行一些感性认知。
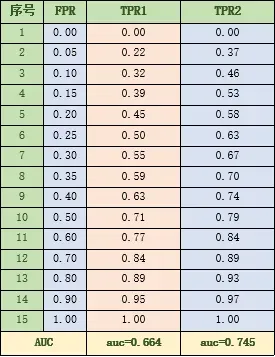
分别由和
生成两组数据,它们的AUC分别为0.664和0.745,具体数据如下,
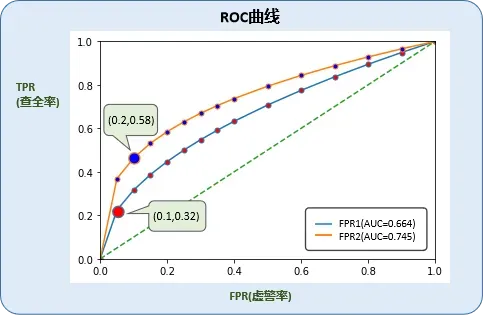
它们的ROC曲线如下:
AUC=0.664的FPR-TPR里,我们挑得性价比比较好的组合是:查全率,虚警率 [0.32,0.1]
在AUC=0.745的FPR-TPR里,我们挑得性价比比较好的组合是:查全率,虚警率 [0.58,0.2]对AUC=0.745的分析:
对于一般业务来说,投入20%的虚警成本,排查出58%的目标样本,应该是挺有价值了。
例如,小贷中,虽然损失了20%的好客户,但是排掉了58%的坏客户。58%坏客户带来的损失远远大于20%好客户带来的利润,那这时候使用模型的价值就非常明显了。对AUC=0.664的分析:
对于一般业务来说,投入10%的虚警成本,排查32%的目标样本,虽然也是有价值,但排查出的目标样本占比还是过少了。因此,0.66的AUC不是不可用,这时候模型已经是有区分度了,只是对于实际使用,力度不够。
总结:
AUC=0.666 代表模型对目标样本已经有初步的识别度。
AUC=0.745 代表模型不仅有识别度,对目标样本还有较大的识别力度。
用人话来说,0.66代表模型还弱,还需要继续优化,0.75代表模型基本已经有不错的商用价值了。
PASS:以上都为实验数据,细节仅为参考。但本实验结论与实际项目中经验结论基本是一致的。
五、AUC的计算过程
(一)计算过程分析
AUC的主要计算过程如下
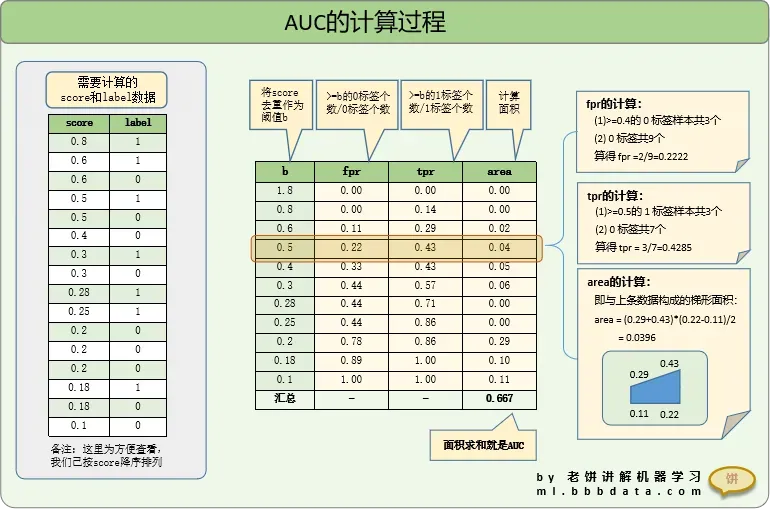
用上面计得的FPR和TPR即可画得ROC曲线:
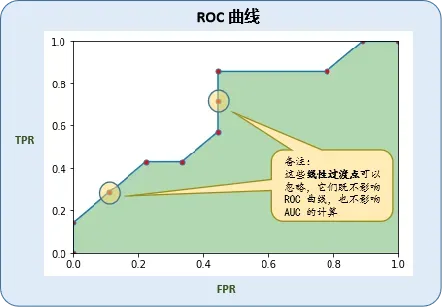
(二) 自写代码实现
按照以上逻辑,编写代码如下:
# -*- coding: utf-8 -*-
"""
AUC计算与ROC曲线绘画
"""
import numpy as np
import pandas as pd
#=====================标签与score数据=============================
lable = np.array([0, 1 ,0,1 ,1,1 ,0 ,1,0,1,0,0,0,0,1,0])
score = np.array([0.2, 0.28,0.1 ,0.6,0.5, 0.3, 0.6, 0.8,0.2,0.25,0.4,0.2,0.5,0.3,0.18,0.18])
#===================计算FPR和TPR==========================================
df = pd.DataFrame({'score':score,'label':lable})
df = df.sort_values('score',ascending=False).reset_index(drop=True)
df['last_score'] = df['score'].diff(-1)!=0
df['csum0'] = (df['label']==0).cumsum()
df['csum1'] = df['label'].cumsum()
df['fpr'] = df['csum0']/(df['label']==0).sum()
df['tpr'] = df['csum1']/df['label'].sum()
df = df[df['last_score']==True]
start_row = pd.DataFrame( {'score':score.max()+1,'fpr':0,'tpr':0},pd.Index(range(1)))
df = pd.concat([start_row,df[['score','fpr','tpr']]]).reset_index(drop=True)
#=============绘画ROC曲线===================================
import matplotlib.pyplot as plt
plt.plot(df['fpr'],df['tpr'], marker='o', markerfacecolor='r', markersize=5)
plt.fill_between(df['fpr'],0, df['tpr'], facecolor='green', alpha=0.3)
plt.xlim(0,1);plt.ylim(0,1);
plt.title('ROC');plt.xlabel('fpr');plt.ylabel('tpr')
#===============计算AUC======================================
df['area'] = 0
for i in range(1,df.shape[0]):
df.loc[i,'area']= (df['tpr'][i]+df['tpr'][i-1])*(df['fpr'][i]-df['fpr'][i-1])/2
auc = df['area'].sum()
#=======打印结果=======================================
print('=====FPR和TPR====================')
print(df)
print('=====AUC====================')
print('AUC:'+str(auc))运行结果:
=====FPR和TPR====================
score fpr tpr area
0 1.80 0.000000 0.000000 0.000000
1 0.80 0.000000 0.142857 0.000000
2 0.60 0.111111 0.285714 0.023810
3 0.50 0.222222 0.428571 0.039683
4 0.40 0.333333 0.428571 0.047619
5 0.30 0.444444 0.571429 0.055556
6 0.28 0.444444 0.714286 0.000000
7 0.25 0.444444 0.857143 0.000000
8 0.20 0.777778 0.857143 0.285714
9 0.18 0.888889 1.000000 0.103175
10 0.10 1.000000 1.000000 0.111111
=====AUC====================
AUC:0.6666666666666667(三)调用sklearn实现
调用sklearn包计算AUC
# -----调用sklearn包计算AUC--------
from sklearn import metrics
import numpy as np
import pandas as pd
#=====================标签与score数据=============================
lable = np.array([0, 1 ,0,1 ,1,1 ,0 ,1,0,1,0,0,0,0,1,0])
score = np.array([0.2, 0.28,0.1 ,0.6,0.5, 0.3, 0.6, 0.8,0.2,0.25,0.4,0.2,0.5,0.3,0.18,0.18])
#=====================标签与score数据=============================
fpr, tpr, thresholds = metrics.roc_curve(lable,score,drop_intermediate=False)
auc = metrics.auc(fpr, tpr)
print('FPR:'+str(fpr))
print('TPR:'+str(tpr))
print('AUC:'+str(auc))运行结果:
FPR:[0. 0. 0.11111111 0.22222222 0.33333333 0.44444444 0.44444444 0.44444444 0.77777778 0.88888889 1. ]
TPR:[0. 0.14285714 0.28571429 0.42857143 0.42857143 0.57142857 0.71428571 0.85714286 0.85714286 1. 1. ]
AUC:0.6666666666666666可见,自行计算结果与sklearn包运行结果一致。
备注:使用时需要注意哦,metrics.roc_curve默认drop_intermediate为True,算出的fpr和tpr会删掉线性过渡点(即上面图中标黄的点)哦!
六、总结
本文我们学习了二分类模型划分阈值的凭据:【查全率,虚警率】、ROC, 以及ROC拱度的评估值AUC.
(1) 投产时通过【查全率,虚警率】去确定阈值 (查全率TPR代表收益,虚警率FPR代表成本)。ROC曲线是以虚警率为X轴,查全率为Y轴画出的曲线,可以更方便我们挑选【查全率,虚警率】。
(2) 在划分阈值前,先以AUC评估模型。AUC是ROC曲线下的面积,它代表了ROC的拱度。AUC越大,ROC越拱,我们越有机会挑出性价比更高的【查全率,虚警率】组合。
相关文章
文章出处登录后可见!