如何从 Github 语言统计中忽略 Jupyter Notebook
不要让这些文件掩盖项目的其他重要语言
如果您像我一样是 Github 用户,您可能知道存储库右侧的这个小部分:语言。
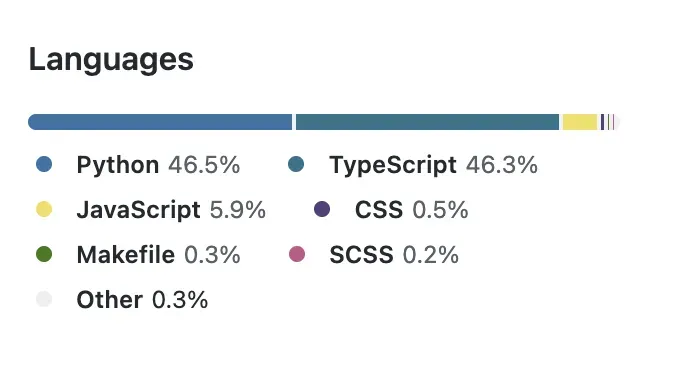
本节列出了项目中涉及的编程语言以及它们的使用百分比:这给出了堆栈和开发人员使用的不同技术的粗略概念。
如果你想知道这些统计数据是如何计算的,Github 工程师已经开源了一个 Ruby 库,它可以在后台完成这项工作:它被称为 linguist。[0]
为什么这个部分甚至有用?
除了为您提供正在使用的编程语言的细分之外,此语言统计部分还为 Github 提供了一种方法来索引您的项目,方法是通过按语言搜索功能使其可被发现。
jupyter 笔记本和语言统计的问题
当您在 Python 项目中有一堆笔记本时,在计算语言统计信息时会将它们考虑在内。由于这些文件的元数据行数过多,因此它们通常出现在顶部,掩盖了项目中涉及的重要语言。
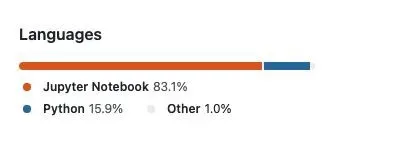
这是我的一个项目中发生的事情:我有一个 notebooks 文件夹作为我的代码库的一部分,其中的文件提交给 Git 是有意义的,因为它们共享了该库的使用示例。
当 Github 编译统计数据时,它给出了这种不切实际的细分,因为 Jupyter Notebook 不是纯文本文件,而是大量元数据。
The solution 💡
在深入研究了 linguist 的文档后,我找到了一个快速解决方案:只需将 notebooks 文件夹添加为 .gitattributes 文件中的 linguist-vendred 即可。
基本上,将此行添加到 .gitattributes 并提交此文件:
notebooks/** linguist-vendored通过这样做,Github 将在计算统计信息时忽略 notebooks 文件夹中的文件(这基本上适用于您想忽略的任何类型的文件)
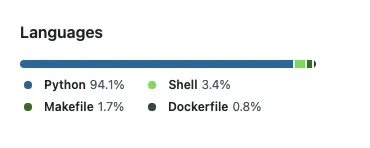
推送代码后,语言统计信息会更新,显示 Shell、Makefile 和 Dockerfile:我用来编写、打包和部署库的三个工具。
That’s all! :)
新媒体?您可以以每月 5 美元的价格订阅并解锁关于各种主题(技术、设计、创业……)的无限文章。您可以通过单击我的推荐链接来支持我[0]

文章出处登录后可见!
已经登录?立即刷新