基于视觉的闭环检测可以描述为,给定一张输入图像,在历史图像数据库中高效准确地搜索出与之相似的图像。而通常的穷举搜索法效率低下,类帧差法受制于图像视角变化、光照变化、曝光等因素无法稳定识别相似图像。
词袋模型可以解决上述问题,其基于大量图像数据事先训练词袋字典,字典中包含各类图像特征,在实际应用时将输入图像和历史图像转化为几何特征集合进行相似度对比,这一方式更为符合人类的认知方式;通过设计特定的描述子实现特征的稳定提取,利用直接索引和倒排索引实现图像的快速搜索。
- 论文:Gálvez-López D, Tardos J D. Bags of binary words for fast place recognition in image sequences[J]. IEEE Transactions on Robotics, 2012, 28(5): 1188-1197.
- 源码:
1.离线词袋字典生成
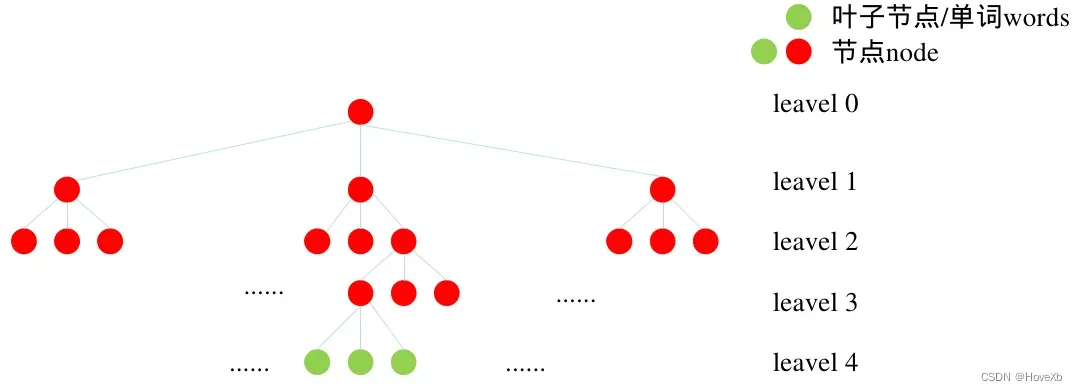
图像首先提取ORB 特征点,将描述子通过 k-means 进行聚类,根据设定的树的分支数和深度,从根节点一直聚类到叶子节点,得到一个 vocabulary tree,图二展示了分支数为3,深度为4的词袋字典。
- 遍历所有的训练图像,对每幅图像提取ORB特征点。
- 设定vocabulary tree的分支数K和深度L。将特征点的每个描述子用 K-means聚类,变成 K个集合,作为vocabulary tree 的第1层级,然后对每个集合重复该聚类操作,就得到了vocabulary tree的第2层级,继续迭代最后得到满足条件的vocabulary tree,它的规模通常比较大,比如ORB-SLAM2使用的离线字典就有108万+ 个节点。
- 离根节点最远的一层节点称为叶子节点或者单词 Word,对每个单词均会计算一个节点权重(见权重计算部分,权重=节点权重*在线权重)。
相关参数说明:
单词数:
节点数:
2.在线使用词袋模型
在线使用词典模型时:
- 对新来图像帧进行ORB特征提取,得到一定数量的特征点与对应的描述子;
- 将每个描述子转化为词袋向量
BowVector与特征向量FeatureVector(见下述与源码3.1); - 基于词袋向量与特征向量完成相关的特征匹配、相似度对比等任务。
其中:
词袋向量BowVector:
数据类型:std::map<WordId, WordValue>
WordId和 WordValue 分别表示描述子对应的单词id 和权重。
特征向量FeatureVector:
数据类型:std::map<NodeId, std::vector<unsigned int> >
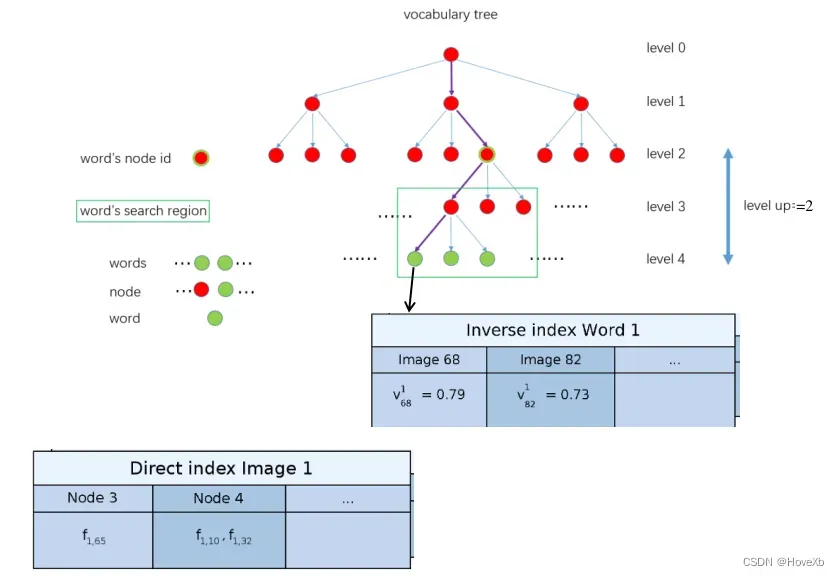
NodeId :距离叶子节点深度为level up对应的节点的id。
std::vector:图像中落在NodeId 下的描述子对应的特征点索引。
FeatureVector 中的 NodeId为什么不直接设置为父节点?因为后面搜索该Word 的匹配点的时候是在和它具有同样node id下面所有子节点中的Word 进行匹配,搜索区域见下图的 Word’s search region。所以搜索范围大小是根据level up来确定的,level up 值越大,搜索范围越广,速度越慢;level up 值越小,搜索范围越小,速度越快,但能够匹配的特征就越少。
词袋向量中权重的计算方法如下表所示,所有权重均可表示为节点权重NodeWeights和在线权重的乘积,其中节点权重为构建字典时确定,在线权重在输入每张图像时计算
| 权重(WordValue)计算方法 | 节点权重 | 在线权重 |
|---|---|---|
| TF_IDF | IDF | TF |
| TF | 1 | TF |
| IDF | IDF | 1 |
| BINARY | 1 | 1 |
IDF称为逆文档频率,表示某单词在词典出现频率的高低,若词典中出现该单词的频率较高,表明该单词很常见,故其值越低,公式如下:
其中表示数据集中所有特征的总数,
表示某一词汇的出现数量。
TF称为词频:表示某一单词在图像中出现的频率,若图像中出现该单词的频率越高,说明该单词越能代表该图像,故其值越高。
其中表示图像中所有单词(特征)的总数,
表示图像中某单词的数量。
将每个描述子转化为词袋向量BowVector与特征向量FeatureVector流程:
- 如图三,每个特征点的描述子,从离线创建好的vocabulary tree中开始找自己的位置,从根节点开始,
用该描述子和每个节点的描述子计算汉明距离,选择汉明距离最小的作为自己所在的节点,一直遍历到
叶子节点。描述子最终转换为单词id(WordId),节点权重(Word weight 即 NodeWeights),父节点ID(NodeId距离叶子节点深度为level up的节点id);(见源码3.2) - 计算
WordValue、构建词袋向量与特征向量;
3.源码
3.1 将描述子转为词袋向量与特征向量源码
/
**
* @brief 将一幅图像所有的描述子转化为BowVector和FeatureVector
* *
@tparam TDescriptor
* @tparam F
* @param[in] features 图像中所有的描述子
* @param[in & out] v BowVector
* @param[in & out] fv FeatureVector
* @param[in] levelsup 距离叶子的深度
*/
template<class TDescriptor, class F>
void TemplatedVocabulary<TDescriptor,F>::transform(
const std::vector<TDescriptor>& features,
BowVector &v, FeatureVector &fv, int levelsup) const
{
v.clear();
fv.clear();
if(empty()) // safe for subclasses
{
return;
}
// normalize
// 根据选择的评分类型来确定是否需要将BowVector 归一化
LNorm norm;
bool must = m_scoring_object->mustNormalize(norm);
typename vector<TDescriptor>::const_iterator fit;
if(m_weighting == TF || m_weighting == TF_IDF)
{
unsigned int i_feature = 0;
// 遍历图像中所有的特征点
for(fit = features.begin(); fit < features.end(); ++fit, ++i_feature)
{
WordId id; // 叶子节点的Word id
NodeId nid; // FeatureVector 里的NodeId,用于加速搜索
WordValue w; // 叶子节点Word对应的权重
// 将当前描述子转化为Word id, Word weight,节点所属的父节点id(这里的父节点不是叶子
//的上一层,它距离叶子深度为levelsup)
// w is the idf value if TF_IDF, 1 if TF
transform(*fit, id, w, &nid, levelsup);
if(w > 0) // not stopped
{
// 如果Word 权重大于0,将其添加到BowVector 和 FeatureVector
v.addWeight(id, w);
fv.addFeature(nid, i_feature);
}
}
if(!v.empty() && !must)
{
// unnecessary when normalizing
const double nd = v.size();
for(BowVector::iterator vit = v.begin(); vit != v.end(); vit++)
vit->second /= nd;
}
}
else// IDF || BINARY
{
unsigned int i_feature = 0;
for(fit = features.begin(); fit < features.end(); ++fit, ++i_feature)
{
WordId id;
NodeId nid;
WordValue w;
// w is idf if IDF, or 1 if BINARY
transform(*fit, id, w, &nid, levelsup);
if(w > 0) // not stopped
{
v.addIfNotExist(id, w);
fv.addFeature(nid, i_feature);
}
}
if(must) v.normalize(norm);
}
3.2:3.1中 描述子转换为单词id(WordId),节点权重(Word weight 即 NodeWeights),父节点ID(NodeId 距离叶子节点深度为level up的节点id)源码:
/** @brief 将描述子转化为Word id, Word weight,节点所属的父节点id(这里的父节点不是叶子的上
一层,它距离叶子深度为levelsup)
* *
@tparam TDescriptor
* @tparam F
* @param[in] feature 特征描述子
* @param[in & out] word_id Word id
* @param[in & out] weight Word 权重
* @param[in & out] nid 记录当前描述子转化为Word后所属的 node id,它距离
叶子深度为levelsup
* @param[in] levelsup 距离叶子的深度
*/
template<class TDescriptor, class F>
void TemplatedVocabulary<TDescriptor,F>::transform(const TDescriptor &feature,
WordId &word_id, WordValue &weight, NodeId *nid, int levelsup) const
{
// propagate the feature down the tree
vector<NodeId> nodes;
typename vector<NodeId>::const_iterator nit;
// level at which the node must be stored in nid, if given
// m_L: depth levels, m_L = 6 in ORB-SLAM2
// nid_level 当前特征点转化为的Word 所属的 node id,方便索引
const int nid_level = m_L - levelsup;
if(nid_level <= 0 && nid != NULL) *nid = 0; // root
NodeId final_id = 0; // root
int current_level = 0;
do
{
++current_level;
nodes = m_nodes[final_id].children;
final_id = nodes[0];
// 取当前节点第一个子节点的描述子距离初始化最佳(小)距离
double best_d = F::distance(feature, m_nodes[final_id].descriptor);
// 遍历nodes中所有的描述子,找到最小距离对应的描述子
for(nit = nodes.begin() + 1; nit != nodes.end(); ++nit)
{
NodeId id = *nit;
double d = F::distance(feature, m_nodes[id].descriptor);
if(d < best_d)
{
best_d = d;
final_id = id;
}
} /
/ 记录当前描述子转化为Word后所属的 node id,它距离叶子深度为levelsup
if(nid != NULL && current_level == nid_level)
*nid = final_id;
} while( !m_nodes[final_id].isLeaf() );
// turn node id into word id
// 取出 vocabulary tree中node距离当前feature 描述子距离最小的那个node的 Word id 和 weight
word_id = m_nodes[final_id].word_id;
weight = m_nodes[final_id].weight;
}
3.3 3.1中添加词袋向量BowVector源码
void BowVector::addWeight(WordId id, WordValue v)
{
// 返回指向大于等于id的第一个值的位置
BowVector::iterator vit = this->lower_bound(id);
// http://www.cplusplus.com/reference/map/map/key_comp/
if(vit != this->end() && !(this->key_comp()(id, vit->first)))
{
// 如果id = vit->first, 说明是同一个Word,权重更新
vit->second += v;
}
else
{
// 如果该Word id不在BowVector中,新添加进来
this->insert(vit, BowVector::value_type(id, v));
}
}
3.4 3.1中添加特征向量FeatureVector源码:
void FeatureVector::addFeature(NodeId id, unsigned int i_feature)
{
FeatureVector::iterator vit = this->lower_bound(id);
// 将同样node id下的特征放在一个vector里
if(vit != this->end() && vit->first == id)
{
vit->second.push_back(i_feature);
}
else
{
vit = this->insert(vit, FeatureVector::value_type(id,
std::vector<unsigned int>() ));
vit->second.push_back(i_feature);
}
}
3.5节点权重NodeWeights计算源码:
template<class TDescriptor, class F>
void TemplatedVocabulary<TDescriptor,F>::setNodeWeights
(const vector<vector<TDescriptor> > &training_features)
{
const unsigned int NWords = m_words.size();
const unsigned int NDocs = training_features.size();
if(m_weighting == TF || m_weighting == BINARY)
{
// idf part must be 1 always
for(unsigned int i = 0; i < NWords; i++)
m_words[i]->weight = 1;
}
else if(m_weighting == IDF || m_weighting == TF_IDF)
{
// IDF and TF-IDF: we calculte the idf path now
// Note: this actually calculates the idf part of the tf-idf score.
// The complete tf-idf score is calculated in ::transform
vector<unsigned int> Ni(NWords, 0);
vector<bool> counted(NWords, false);
typename vector<vector<TDescriptor> >::const_iterator mit;
typename vector<TDescriptor>::const_iterator fit;
for(mit = training_features.begin(); mit != training_features.end(); ++mit)
{
fill(counted.begin(), counted.end(), false);
for(fit = mit->begin(); fit < mit->end(); ++fit)
{
WordId word_id;
transform(*fit, word_id);
if(!counted[word_id])
{
Ni[word_id]++;
counted[word_id] = true;
}
}
}
// set ln(N/Ni)
for(unsigned int i = 0; i < NWords; i++)
{
if(Ni[i] > 0)
{
m_words[i]->weight = log((double)NDocs / (double)Ni[i]);
}// else // This cannot occur if using kmeans++
}
}
}
备注:
-
论文中显示,在这个过程每帧图像会建立自身的直接索引表(Direct index),其中记录着该帧图像中特征所述的节点ID,如图三的直接索引表表示:图像1的特征65属于词袋词典的节点3,特征10、32属于节点44;同时,词袋库会维护逆向索引表(inverse index),其记录着包含第i个word id的所有关键帧,以及每个关键帧对应特征的权重,如图三逆向索引表;id为1的单词在图像65,82中均有出现,且分别对应图像68中的1号特征(其权重为0.79)、图像82的1号特征(权重为0.73)。在实际代码操作中,该部分内容通过BowVector和FeatureVector实现。
-
FeatureVector主要用于不同图像特征点快速匹配,加速几何关系验证,比如ORBmatcher::SearchByBoW 中是这样用的
DBoW2::FeatureVector::const_iterator f1it = vFeatVec1.begin();
DBoW2::FeatureVector::const_iterator f2it = vFeatVec2.begin();
DBoW2::FeatureVector::const_iterator f1end = vFeatVec1.end();
DBoW2::FeatureVector::const_iterator f2end = vFeatVec2.end();
while(f1it != f1end && f2it != f2end)
{
// Step 1:分别取出属于同一node的ORB特征点(只有属于同一node,才有可能是匹配点)
if(f1it->first == f2it->first)
// Step 2:遍历KF中属于该node的特征点
for(size_t i1=0, iend1=f1it->second.size(); i1<iend1; i1++)
{
const size_t idx1 = f1it->second[i1];
MapPoint* pMP1 = vpMapPoints1[idx1];
// 省略
// ..........
文章出处登录后可见!