AI、元宇宙、大模型…每一个火爆名词的背后都代表着巨大的算力需求。据了解,AI模型所需的算力每100天就要翻一倍,远超摩尔定律的18-24个月。5年后,AI所需的算力规模将是今天的100万倍以上。
在这种背景下,加速计算提供了必要的计算能力和内存,其解决方案涉及硬件、软件和网络的组合。接下来,我们将回顾和梳理常见的硬件加速器,如GPU、ASIC、TPU、FPGA等,以及如CUDA、OpenCL等软件解决方案。此外,还将探讨PCIe、NVLink、CXL、InfiniBand、以太网等网络互联技术。
硬件、软件和网络互联
摩尔定律的终结标志着 CPU 性能增长的放缓,人们开始对当前价值 1 万亿美元的纯 CPU 服务器市场的未来发展产生质疑。随着对更强大的应用程序和系统的需求不断增加,传统的 CPU 难以与加速计算竞争。与传统CPU相比,加速计算利用 GPU、ASIC、TPU 和 FPGA 等专用硬件来加速某些任务的执行。
加速计算适用于可并行化的任务,如HPC、AI/ML、深度学习和大数据分析等。通过将某些类型的工作负载卸载到专用硬件设备上,加速计算可极大提高性能和效率。
硬件加速器
硬件加速器是加速计算的基础,包括图形处理单元 (GPU)、专用集成电路 (ASIC) 和现场可编程门阵列 (FPGA)。
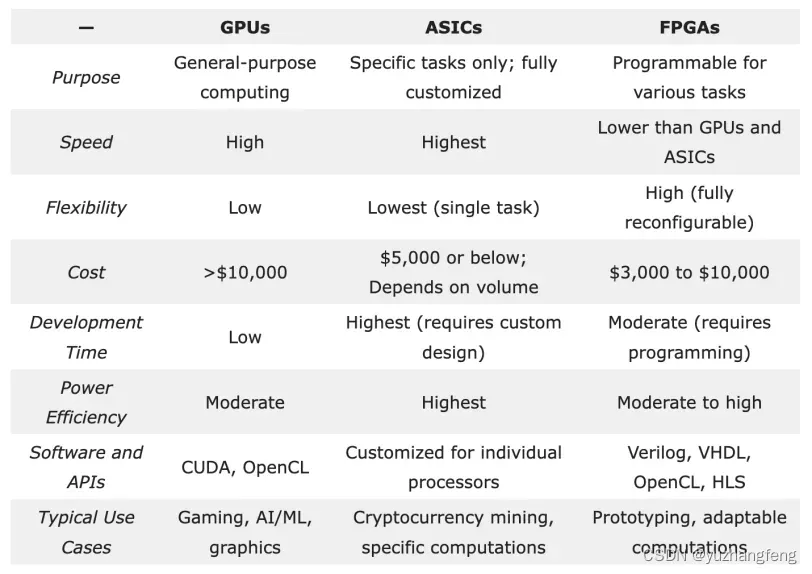
GPU广泛应用于各种计算密集
版权声明:本文为博主作者:沐风—云端行者原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/yuzhangfeng/article/details/135749812