
一、姿态识别整体过程
基于图像视频
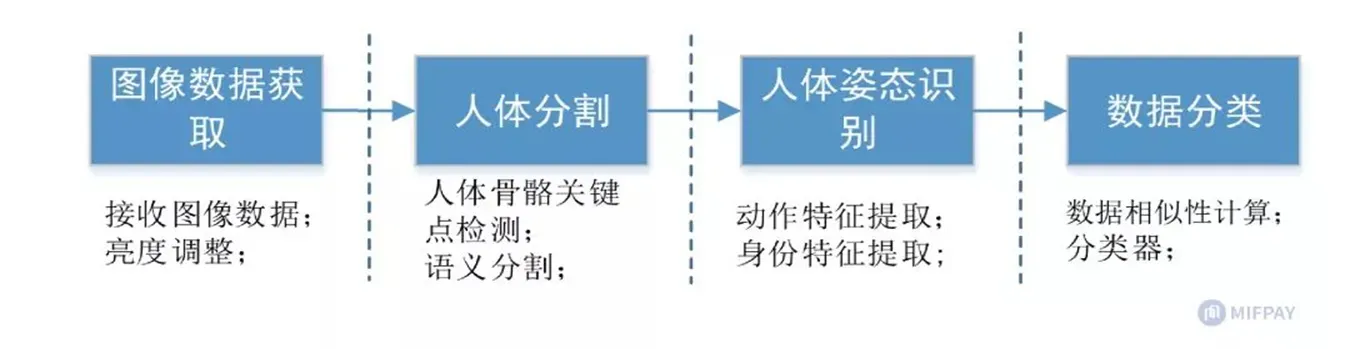
基于mems传感器(高性能三维运动姿态测量系统)
二、人体分割
•人体分割使用的方法可以大体分为人体骨骼关键点检测、语义分割等方式实现。这里主要分析与姿态相关的人体骨骼关键点检测。人体骨骼关键点检测输出是人体的骨架信息,一般主要作为人体姿态识别的基础部分,主要用于分割、对齐等。一般实现流程为:
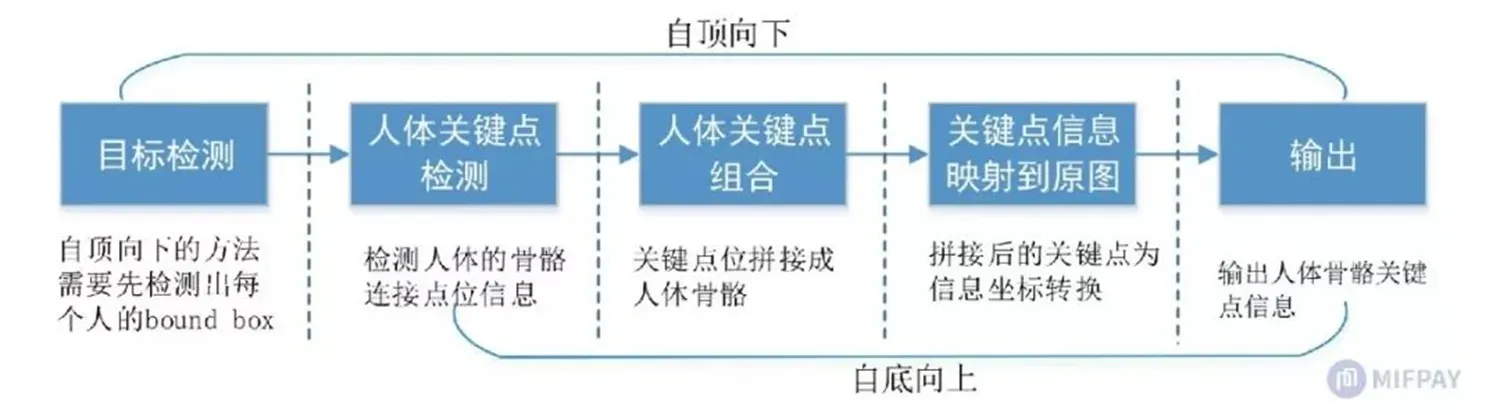
三、人体姿态识别
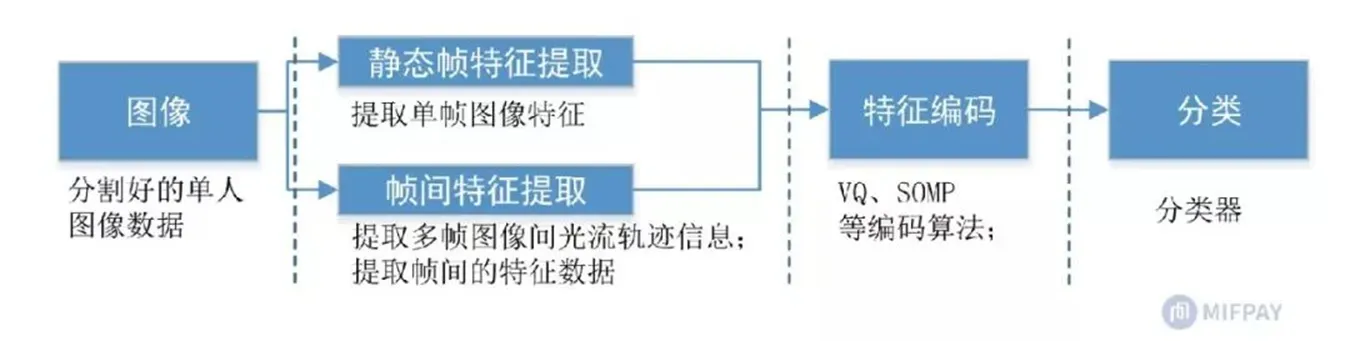
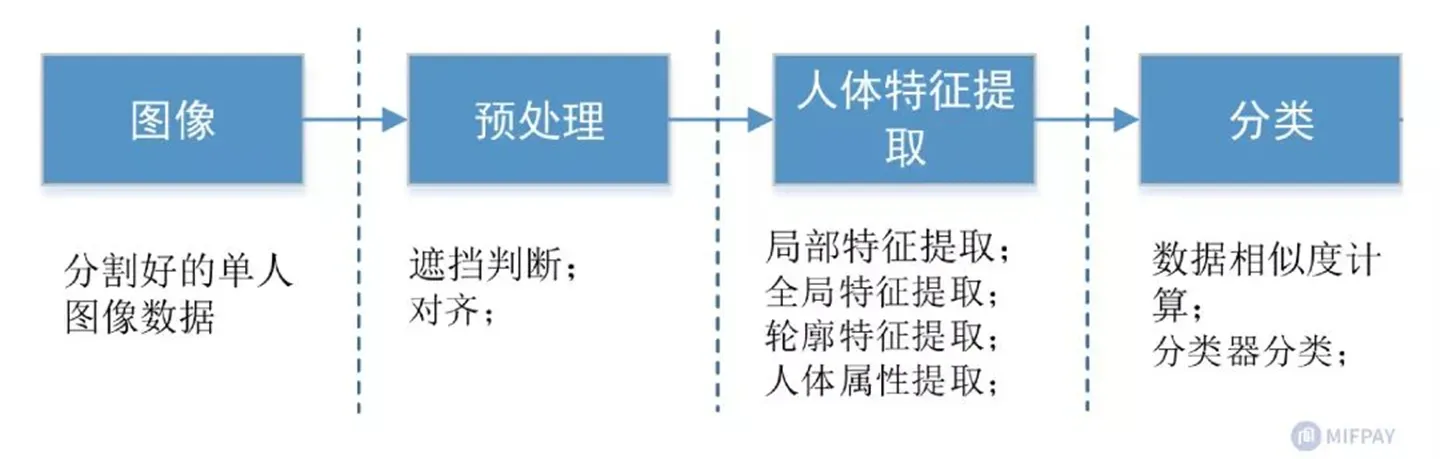
四、人体骨骼关键点检测
•主要检测人体的关键点信息,如关节,五官等,通过关键点描述人体骨骼信息,常用来作为姿态识别、行为分析等的基础部件,如下图所示:
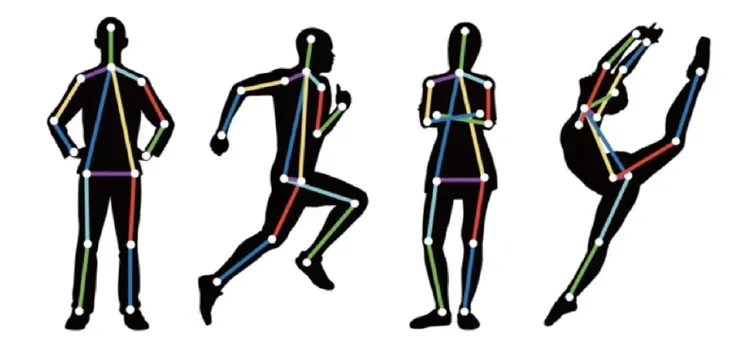
分为两种模式:
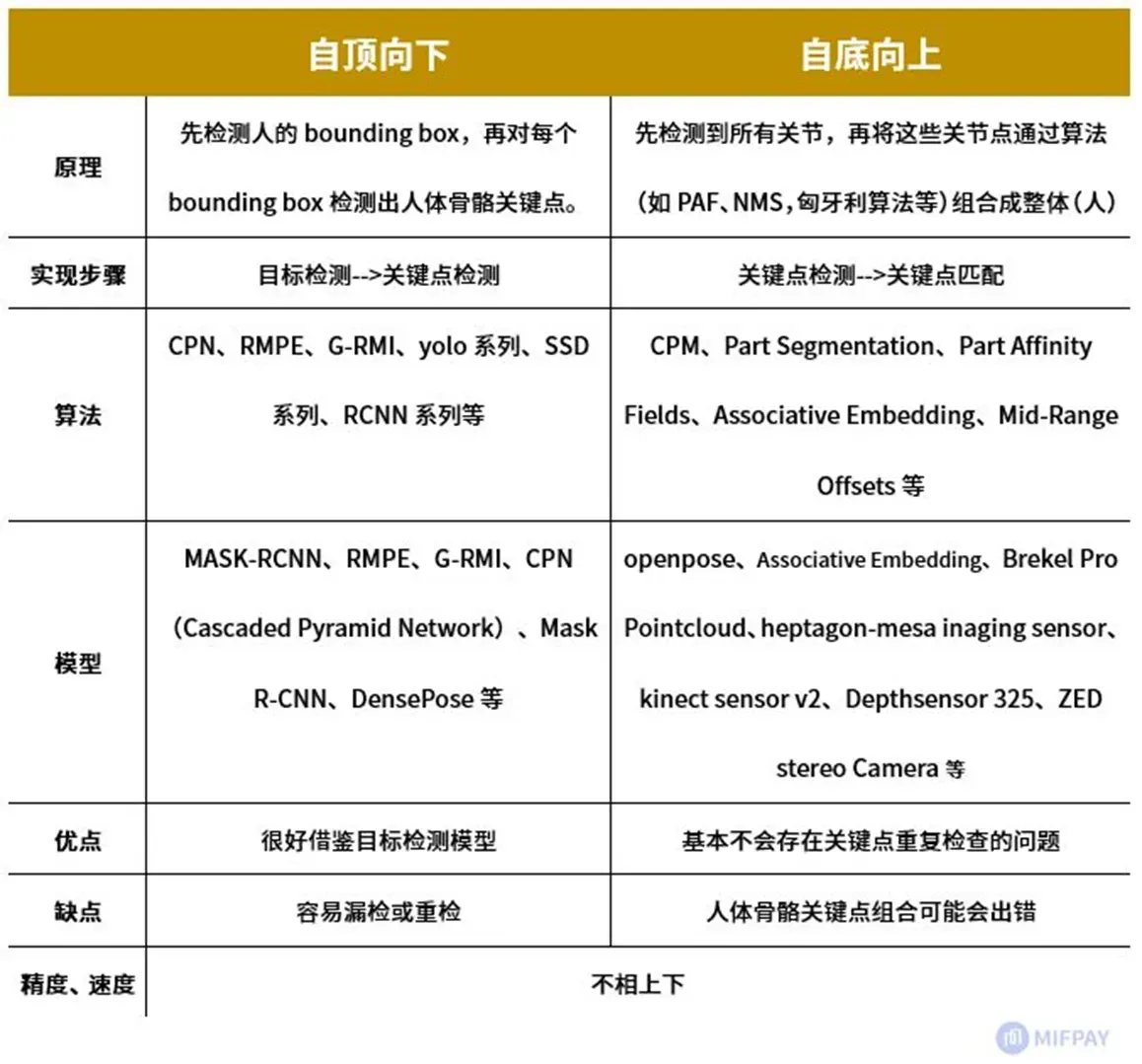
自顶向下的关键点是目标检测到人体框,然后再进行关键点的检测
自底向上(BottomUp)的人体骨骼关键点检测算法主要包含两个部分:关键点检测和关键点聚类连接,关键点检测目的是将图片中所有人的所有关键点全部检测出来。关键点检测完毕之后需要对这些关键点进行聚类处理,将每一个人的不同关键点连接在一块,从而连接
以openpose为例:
•openpose的检测流程为:
•1)计算出所有关键点(头部,肩膀,手肘,手腕…)
•2)计算出所有关联区域
•3)根据关键点和关联区域进行矢量连接,由前两步得到的关键点和关联区域,而后需要依据关联区域将关键点连接以组成人体真正的骨骼结构。作者提出了以一个最小限度的边数量来获得个体姿势的生成树图(用了二分图+匈牙利算法等),在保证不错的准确度的同时,大大减少了复杂度,提高了实时性,解决了对关键点聚类配对时需要每对点都试验一遍然后找到最优的划分和组合结构的难题。
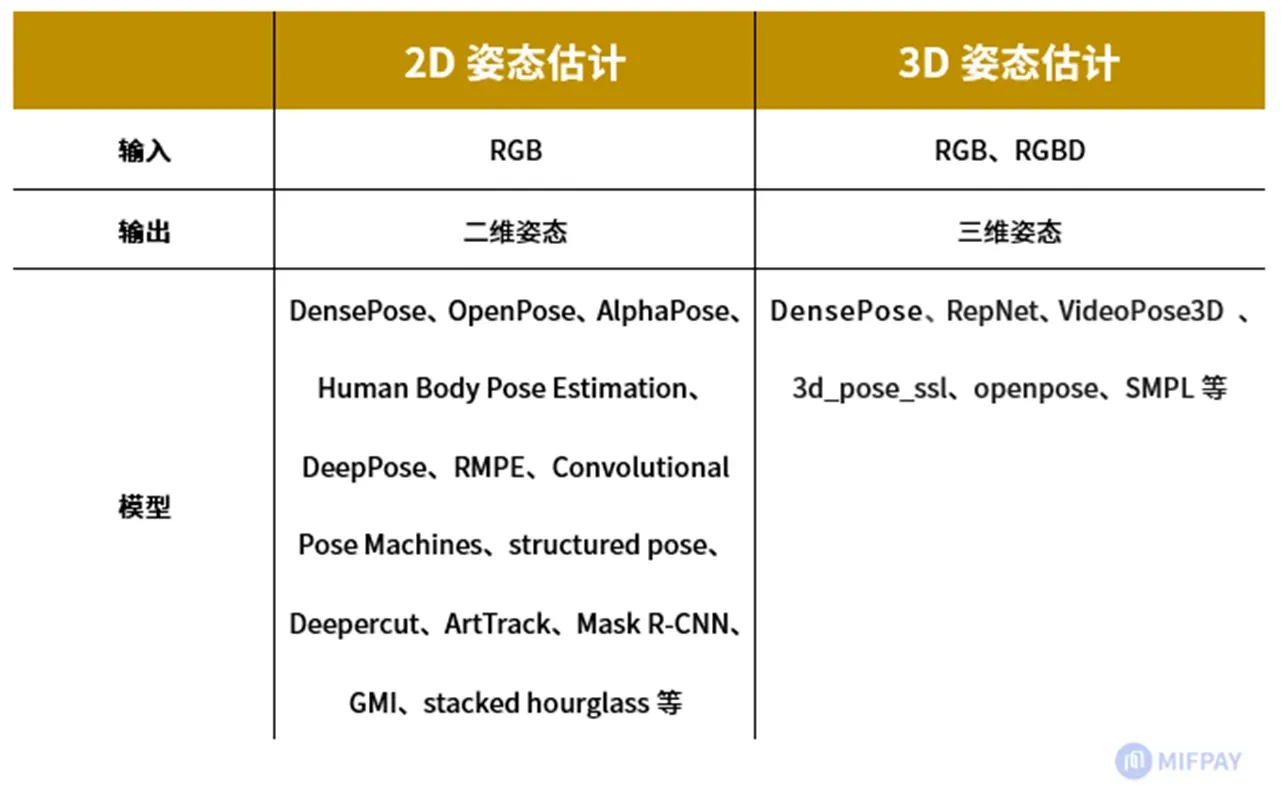
五、2D+人体骨骼关键点检测
•DensePose-RCNN采用的是金字塔网络(FPN)特征的RCNN结构,区域特征聚集方式ROIalign pooling以获得每个选定区域内的密集部分标签和坐标。将2D图像中人的表面图像数据投影到3D人体表面上,将人体的3D表面模型切分为24个部分,然后为每一部分构建一个UV坐标系,将2D图像上的人体部分的每一个点映射到相应的3D表面部分。也可以在估计出图像中人体的UV之后,将3Dmodel通过变换,将空间坐标转换为UV坐标之后,贴到图像上。
•DensePose借鉴了Mask-RCNN的结构,同时带有FeaturePyramid Network(FPN)的特征,以及ROI-Align池化。整体流程为:首先使用Faster-RCNN得到人物区域boundingbox,然后使用CNN网络模块分块,分块后用CNN网络模型处理每一个分块,最后得到目标的热力图IVU。
六、3D人体骨骼关键点检测实现
七、常用算法
•DensePose
•OpenPose
•Realtime Multi-Person Pose Estimation
•AlphaPose(RMPE)
•Human Body Pose Estimation
•DeepPose
•Mediapipe(MoveNet)
1、RMPE算法(自顶向下)
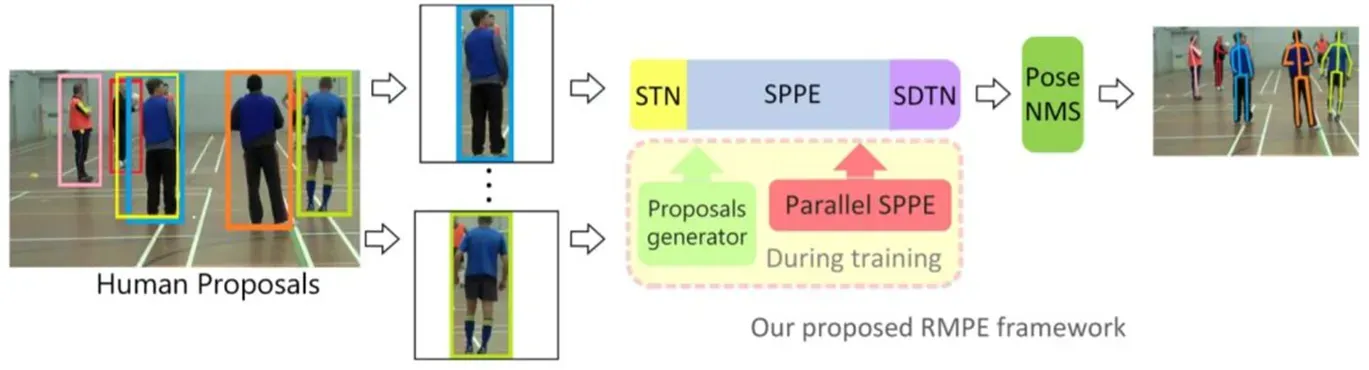
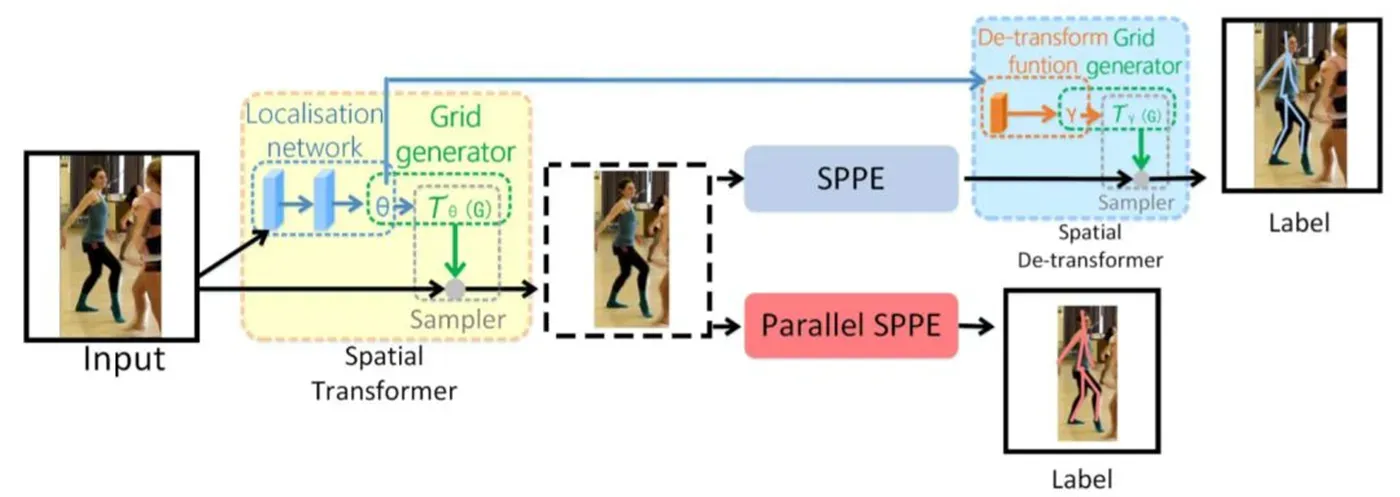
先进行行人检测,得到边界框,然后在每一个边界框中检测人体关键点,连接成一个人形,缺点就是受检测框的影响太大,漏检,误检,IOU大小等都会对结果有影响
2、Mediapipe(自底向上)
•MoveNet模型:Google在2021年5月推出的一款轻量化姿态估计模型
•bottom-up的模型,这种范式一般用在多人姿态估计中,而更特别的是,MoveNet是一个bottom-up的单人姿态估计模型。从MoveNet的技术博客分享中,它在两种范式之间取得了优秀的平衡,既避免了单独训练一个det模型,又尽量保留了单人姿态估计的精度优势。
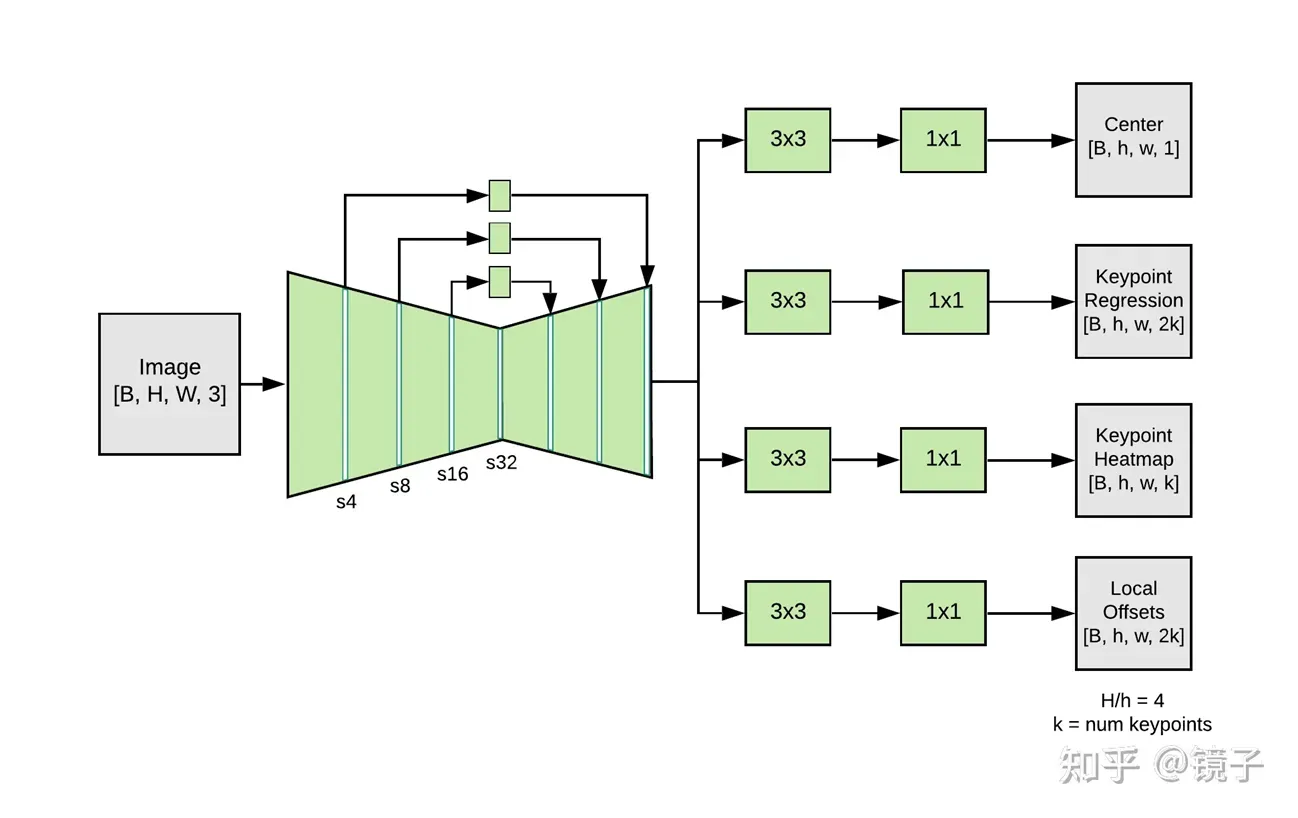
·快速下采样:尽量快地压缩图片尺寸,降低整体的计算量
·残差结构:获取浅层特征和梯度,一定程度上弥补快速下采样造成的一些问题(下采样太快信息损失太严重,模型来不及学出一些高级的有意义的语义特征),强化特征中的空间信息
·参数集中在主干:在残差分支上的参数和计算量尽量少,把本来就比较可怜的算力全用在主干分支上
输出:
·CenterHeatmap[B, 1, H, W]:预测每个人的几何中心,主要用于存在性检测,用Heatmap上一个锚点来代替目标检测的bbox
·KeypointRegression[B, 2K, H, W]:基于中心点来回归17个关节点坐标值
·KeypointHeatmap[B, K, H, W]:每种类型的关键点使用一张Heatmap进行检测,这意味着多人场景下这张Heatmap中会出现多个高斯核
·OffsetRegression[B, 2K, H, W]:回归Keypoint Heatmap中各高斯核中心跟真实坐标的偏移值,用于消除Heatmap方法的量化误差
八、代码实操
采用了mediapipe算法进行简单的演示:
import cv2
import mediapipe as mp
import time #计算fps值
#两个初始化
mpPose = mp.solutions.pose
pose = mpPose.Pose()
#初始化画图工具
mpDraw = mp.solutions.drawing_utils
#调用摄像头,在同级目录下新建Videos文件夹,然后在里面放一些MP4文件,方便读取
cap = cv2.VideoCapture('只因.mp4')
#计算pfs值需要用到的变量,先初始化以一下
pTime = 0
while True:
#读取图像
success, img = cap.read()
#转换为RGB格式,因为Pose类智能处理RGB格式,读取的图像格式是BGR格式
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
#处理一下图像
results = pose.process(imgRGB)
# print(results.pose_landmarks)
#检测到人体的话:
if results.pose_landmarks:
#使用mpDraw来刻画人体关键点并连接起来
mpDraw.draw_landmarks(img, results.pose_landmarks, mpPose.POSE_CONNECTIONS)
#如果我们想对33个关键点中的某一个进行特殊操作,需要先遍历33个关键点
for id, lm in enumerate(results.pose_landmarks.landmark):
#打印出来的关键点坐标都是百分比的形式,我们需要获取一下视频的宽和高
h, w, c = img.shape
print(id, lm)
#将x乘视频的宽,y乘视频的高转换成坐标形式
cx, cy = int(lm.x * w), int(lm.y * h)
#使用cv2的circle函数将关键点特殊处理
cv2.circle(img, (cx, cy), 5, (255, 0, 0), cv2.FILLED)
#计算fps值
cTime = time.time()
fps = 1 / (cTime - pTime)
pTime = cTime
cv2.putText(img, str(int(fps)), (70, 50), cv2.FONT_HERSHEY_PLAIN, 3,
(255, 0, 0), 3)
cv2.imshow("Image", img)
cv2.waitKey(1)效果如下图所示:
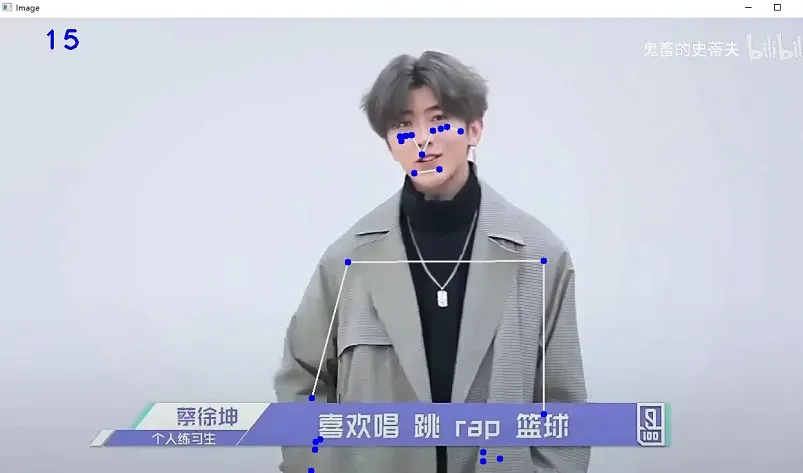


因为mediapipe是自底向上的算法,可以看出来即使人没有完全出现也能识别到关键点,之后连到一起,对于单人姿态识别的话效果还是很不错的。
文章出处登录后可见!