本文主要讲述人工智能(AI)的发展历程,从早起的符号主义和专家系统,到互联网兴起后的数据驱动,再到机器学习、深度学习和大模型的发展。通过本次学习,可以了解深度学习的重要性和价值,以及大模型如何输入和输出大数据。此外,本文还介绍了大模型微调的重要性和应用场景,以及大语言模型预训练的概念。
AI大模型的四次发展
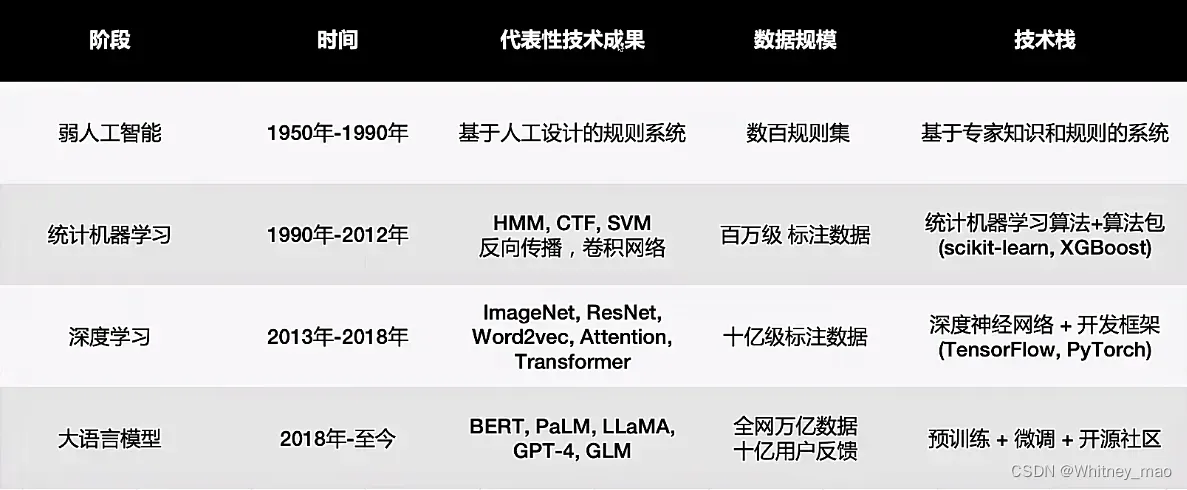
AI大模型从早期的人工智能实验,经历了机器学习、深度学习方技术浪潮,如今正推动着大语言模型技术的发展。在其发展过程中,数据和模型的增长是关键,而微调技术则让大模型更好地适应商业化场景。
技术浪潮
每一次的技术浪潮总会产出大量的成果,包括论文、书籍以及不同研究人员发表的创新观点等等。对此,我们搜集了技术浪潮下极具有代表性的成果来反馈不同技术浪潮的发展和特点。
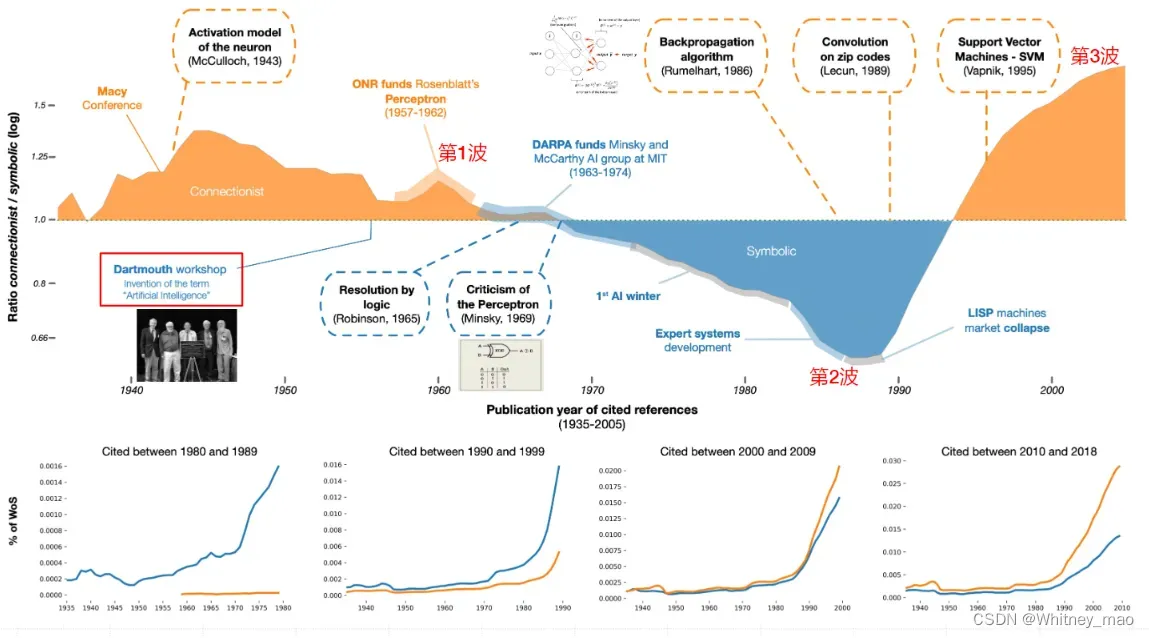
上图黄色部分代表的是联结主义产出的相关成果,蓝色部分代表了符号主义的相关成果。第一波技术浪潮主要在1957年到1960年,该阶段已经有部分学者研究生物和脑神经相关方向,并诠释了神经元如何传递信息等重要成果。第二波浪潮侧重在专家系统的发展,但已经出现卷积神经网络等相关算法的研究。第三波技术浪潮联结主义再次兴起,1995年维克发表了支持向量机等感知机的研究成果,推动了深度学习的研究热潮。
应用浪潮
随着科技和大量研究成果的产生,以数据和模型为驱动的人工智能应用也逐渐达到新高潮。
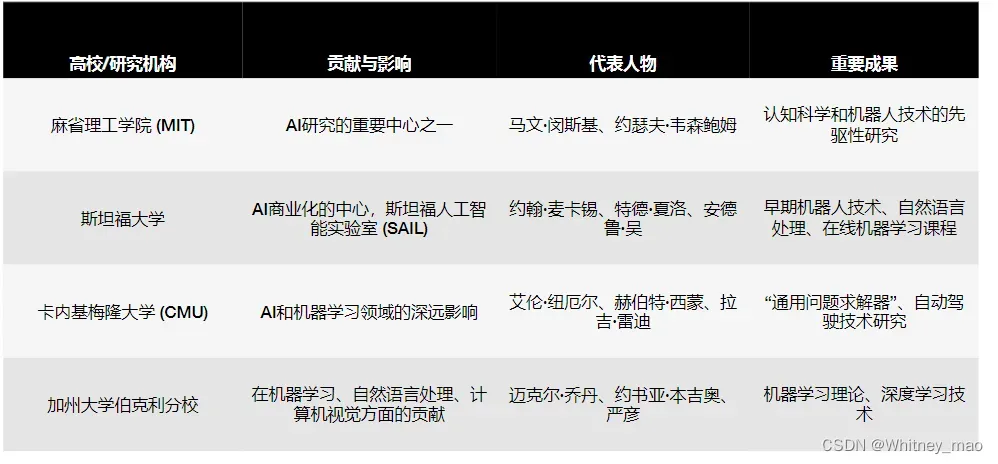
高校共识
- 1950年,英国密码学家、逻辑学家、计算机科学家艾伦 图灵发表了划时代的论文《计算机与智能》,文中预言了创造出具有真正智能的机器的可能性,并提出著名的图灵测试。其中,文中对“智慧”的定义十分典型,他表明“如果一台机器能够与人类展开对话而不被辨别出其机器身份,那么称这台机器具有智慧。”
- 早稻田大学发明世界首个拟人机器人
- 斯坦福大学研制首个人工智能移动机器人
- 斯坦福大学研制首个“自动驾驶”小车Stanford Cart
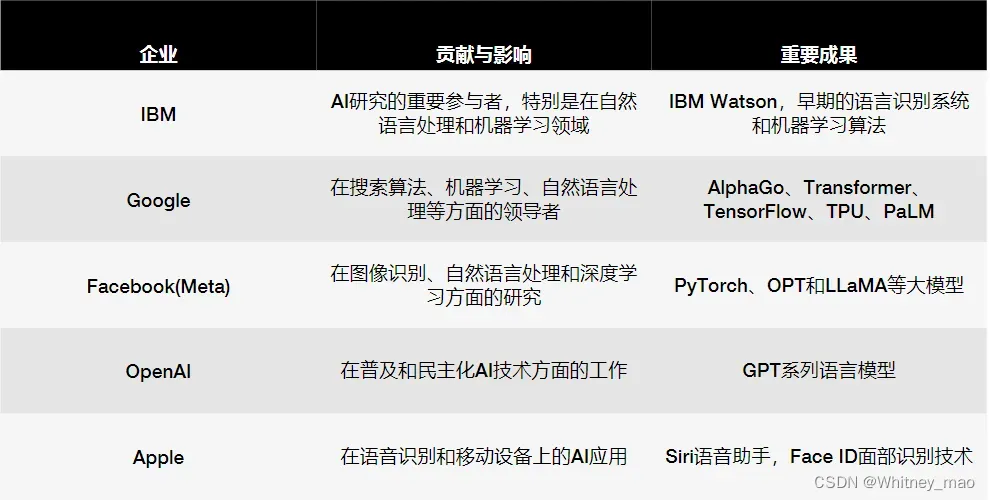
硅谷创新
- 蒂姆·伯纳斯-李 发明的万维网首次上线
- IBM 深蓝计算机击败卡斯巴罗夫(1997)
- Google 搜索引擎正式成立公司(1998)
- NVIDIA 公司正式推出 CUDA 统一计算架构(2007)
- 普林斯顿大学 李飞飞团队主导的 ImageNet 项目诞生(2009)
- Apple 公司推出人工智能语音助手 Siri(2010)等等
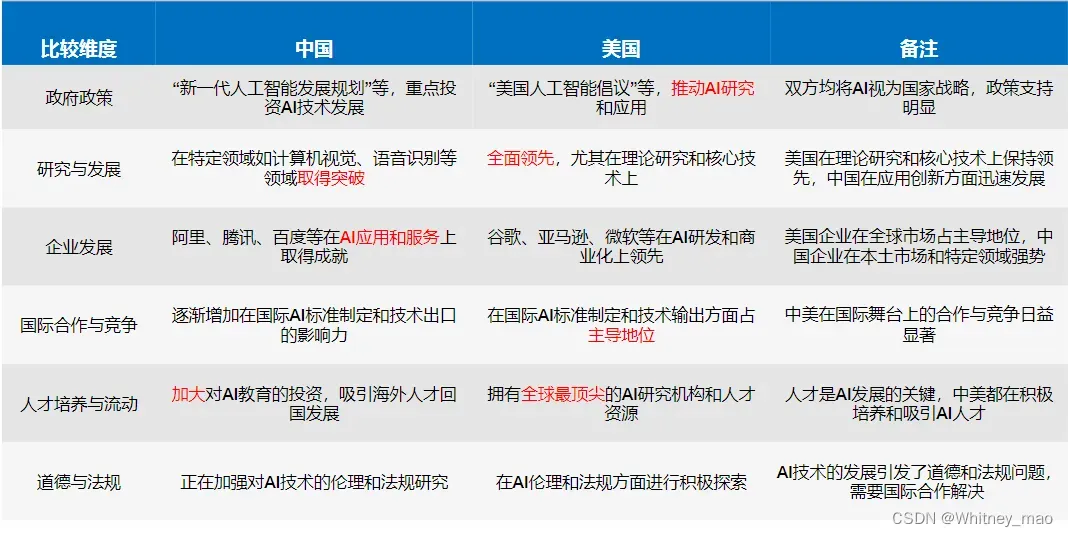
中美博弈
中国部分企业在人工智能研究和应用上的创新
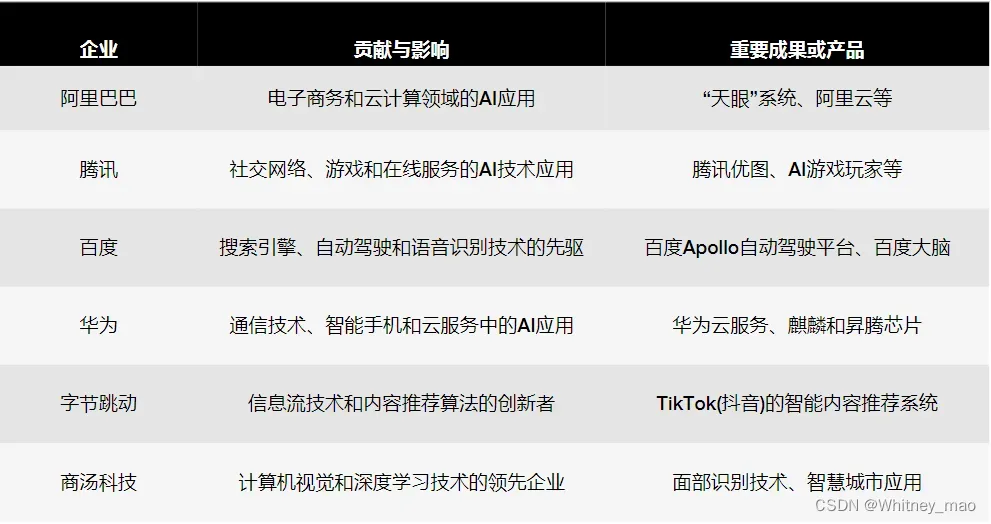
中国与美国在人工智能上的博弈:
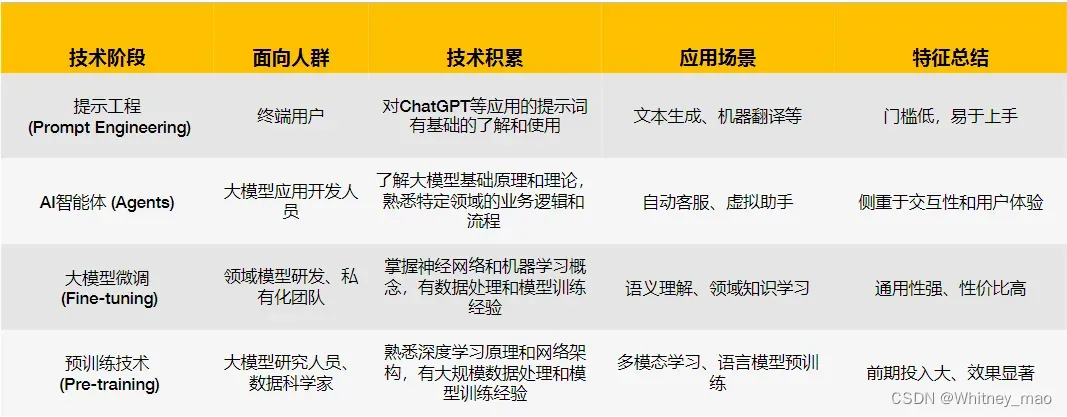
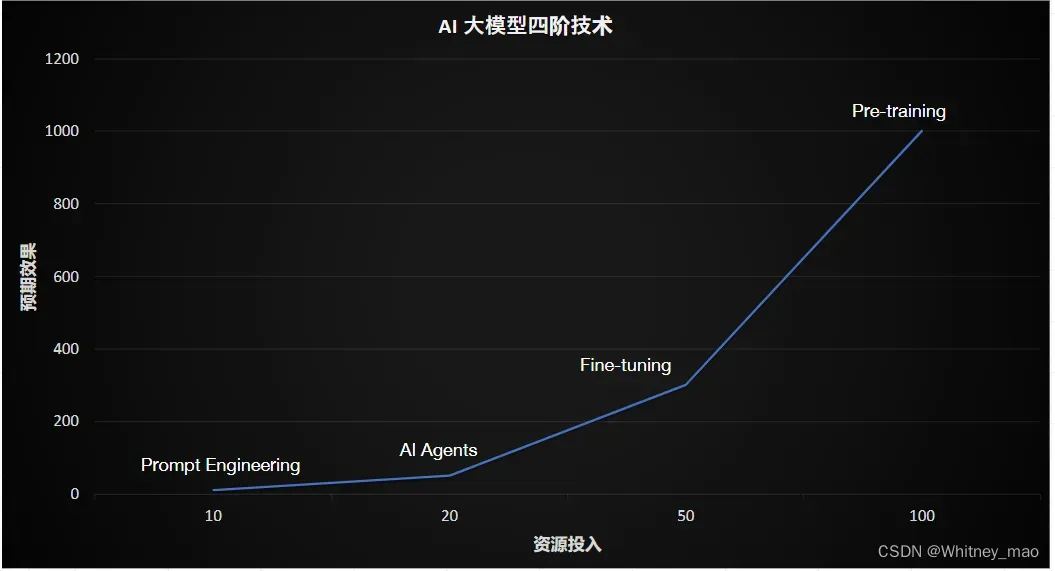
AI大模型四阶技术总览
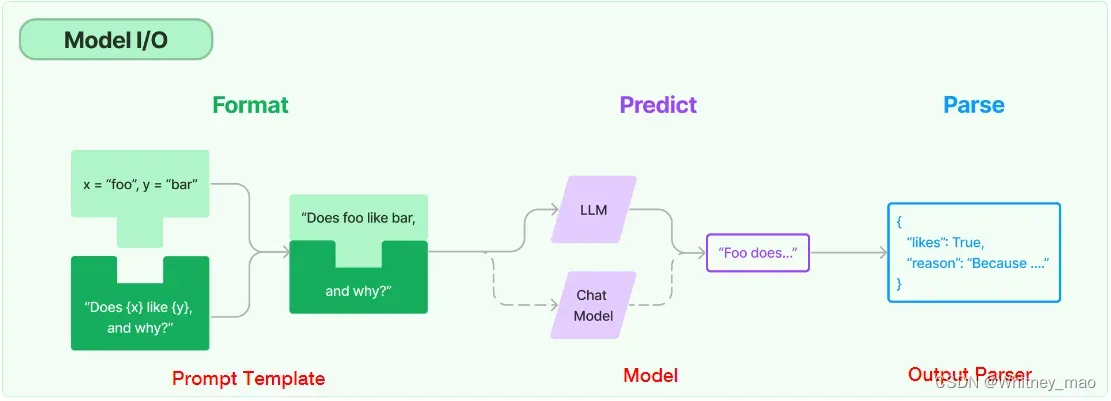
一、提示工程(Prompt Engineering)
Prompt
Prompt可以理解为“提示语”,它的目的是让ChatGPT进入某种场景下的对话模式。在ChatGPT中,prompt通常是指一个输入的文本段落或短语,作为生成模型输入的起点或引导提示语。prompt可以是一个问题、一段文字描述、一段对话或任何形式的“文本输入”。模型会基于prompt所提供的上下文和语义信息,生成对应的输出文本,。输出的质量在很大程度上受prompt影响。
基于GPT的prompt技巧最佳实践
- 角色设定:使用System给GPT设置角色和任务;
- 指令注入:在System中注入常驻任务指令,如“主题创作”;
- 问题拆解:将复杂问题拆解成子问题,分步骤执行;
- 分层设计:分层提问,先概览再章节,最后补充细节;
- 编程思维:将prompt当做编程语言,主动设计变量、模版和正文;
- Few-Shot:基于样例的prompt设计,规范推理路径和输出样式。
使用场景设定
- 使用prompt构造标注数据
- 使用prompt帮助Debug
Prompt Engineering
Prompt Engineering可以理解为将prompt由手动输入转为自动化的程序,且实现 Prompt Engineering的方法很多。例如:
使用LangChain和OpenAI API自动化构造Prompt
二、AI智能体(Agents)
ReACT范式的理解
ReACT可以理解为大模型的思考推理能力和反馈能力。AI Agents就是让大模型具备思考推断能力,通过输入的问题来判断是否具有相应的答案。如果判断结果为没有直接的答案,那么就要思考是否具有工具,比如API接口,来形成解决问题的一套解决方案。这个解决过程就需要大模型先寻找解决问题的环境,通过环境来使用工具并操作得出解决方案的结果,同时还要判断这个结果是完整结果还是过程结果。如果是过程结果,就要判断大模型能否通过推理得出完整结果,如果还不能,则还需要继续调用工具,直到得出完整结果。整个过程其实就是ReACT范式。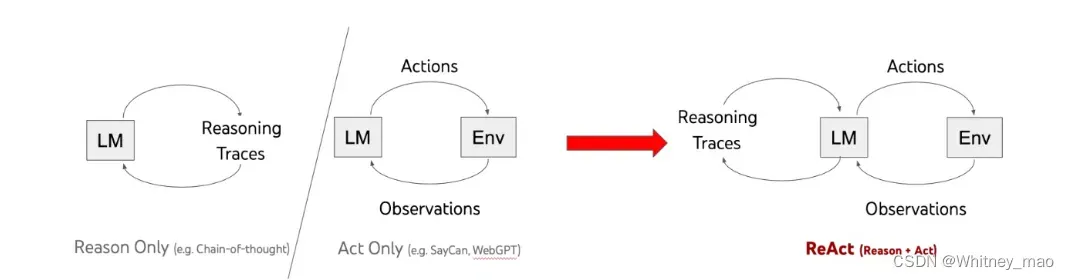
LangChain Agent
构建复杂应用的代理系统:
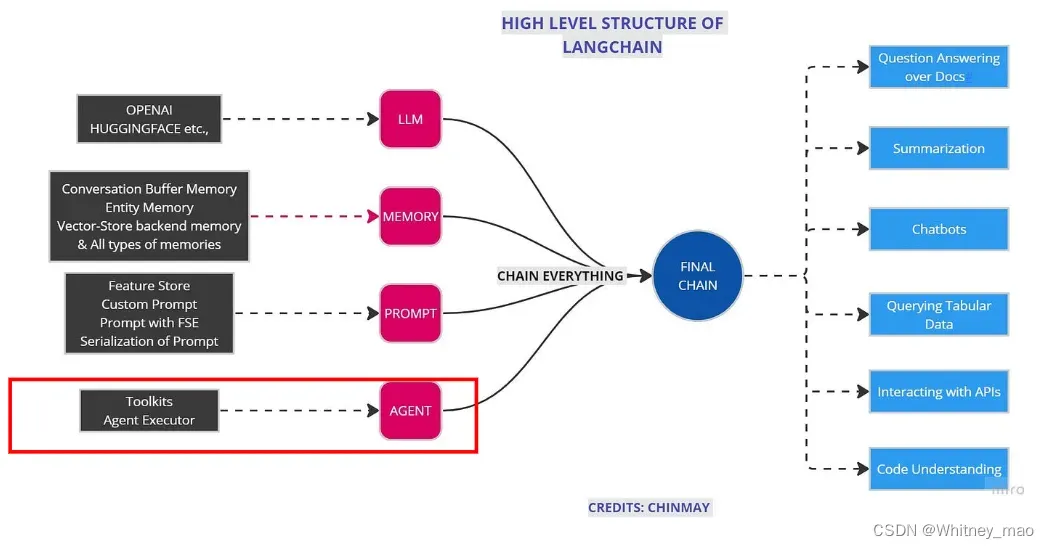
LangChain Agents设计原理:
Agents 的核心思想是使用LLM来决策一系列要执行的动作,以完成目标。
- 在链式结构(Chains)中,一系列动作执行是硬编码的( Sequential Chain 和 Router Chain 也仅实现了面向过程);
- 在代理(Agents)中,语言模型被用作推理引擎,以确定应该采取哪些动作以及执行顺序。

伪代码实现逻辑:
next_action = agent.get_action(...)
while next_action != AgentFinish:
observation = run(next_action)
next_action = agent.get_action(...,next_action, observation)
return next_action
LangChain Agents Ecosystem
规划(Planning)
- 提示(prompt)
–LLM多角色赋能;
–给予充分的上下文
–学习策略 - 代理(Agent):决策下一步做什么
记忆(memory)
- 短期记忆:内存
- 长期记忆:向量数据库
工具(Tools):大量外部可调用服务
智能代理分类:
- 行动代理(Action agents):旨在决定行动序列(工具使用)(例如OpenAI Funciton Call,ReAct);
- 模拟代理(Simulation agents):通常设计用于角色扮演,在模拟环境中进行(例如生成式智能体,CAMEL);
- 自主智能体(Autonomous agent):旨在独立执行以实现长期目标(例如Auto-GPT, BabyAGI)。

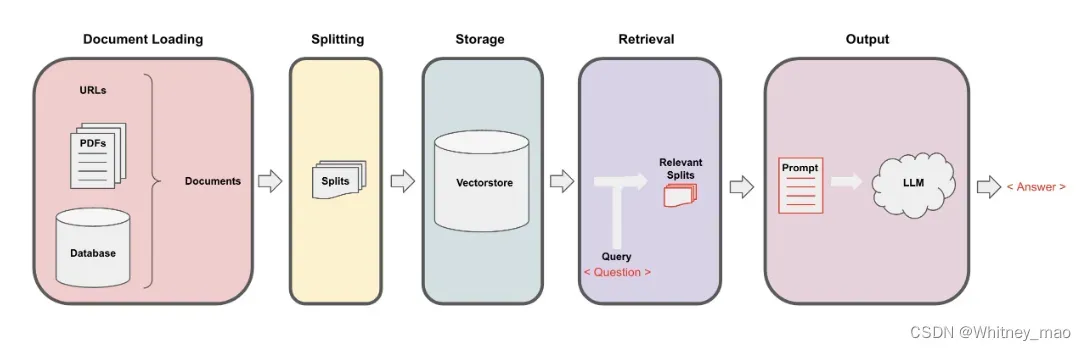
基于 LangChain 的 RAG 应用设计
检索增强生成(Retrieval Augmented Generation,RAG),它可以将一个信息检索组件和文本生成模型整合在一起。RAG的过程可以根据缩写进行解析,Retrieval 即为检索,可以从特定的目录里进行检索,如向量数据库、知识库等任何地方;Augmented即增强,主要针对大语言模型特定的Prompt设计或Prompt模版进行整合,最后将整合好的内容反馈给用户。通过解析内容可以看出,RAG应用主要分为两个阶段,第一个阶段是生成知识库,第二个阶段为检索文本生成。
三、大模型微调(Fine-tuning)
为什么需要微调大模型?
- 预训练成本高,导致大模型微调基本上是科技前沿企业在持续发展,而没有在高校内体现出较大的贡献
- 提示工程有天花板,主要由于token上限和推理成本
- 基础模型缺少特定领域数据
- 数据安全和隐私(应用层面)
- 个性化服务需要私有化的微调大(应用层面)
大模型微调技术路线
1. 全量微调(Full Fine-Tune, FFT)
全量微调存在的问题:
- 训练成本高:需要把整个大语言模型加载到显存;
- 灾难性遗忘:预训练好模型后,训练因子权重将会固定,使得部分权重丢失
2. 高效微调(Parameter-Efficient Fine-Tune, PEFT)
—有监督(Supervised Fine-tune, SFT)
—基于人类反馈的强化学习(RLHF)
—基于AI反馈的强化学习(RLAIF)
PEFT主流方案:
- 围绕 Token 做文章:语言模型(PLM)不变
—— Prompt Tuning
—— Prefix Tuning
—— P-Tuning - 特定场景任务:训练“本质”的低维模型
—— LoRA
—— QLoRA
—— AdaLoRA - 新思路:少量数据、统一框架
—— IA3
—— UniPELT
四、预训练技术(Pre-training)
预训练语言模型 (Pre-trained language models):预训练将大量低成本收集的训练数据放在一起,经过某种预训练的方法去学习其中的共性,然后将其中的共性 “移植” 到特定任务的模型中,再使用相关特定领域的少量标注数据进行 “微调”。因此,模型只需要从“共性” 出发,去 “学习” 该特定任务的 “特殊” 部分。
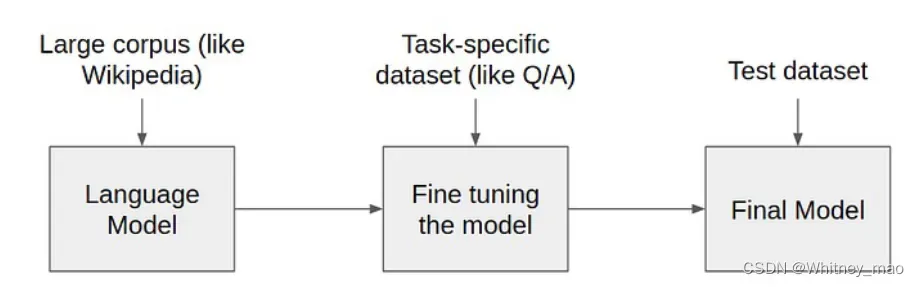
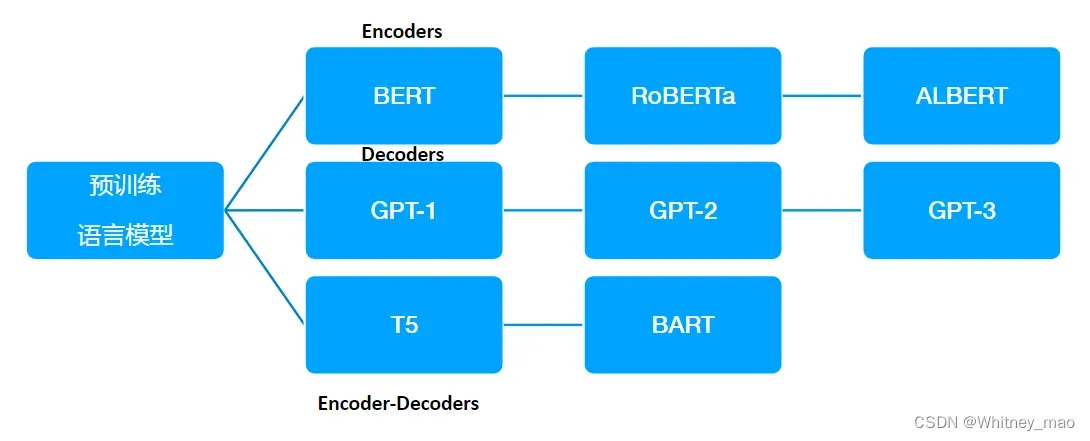
预训练语言模型的三种网络架构
编码器
编码器主要用于处理和理解输入信息。这些模型可以获得双向的上下文,即可以同时考虑一个词的前面和后面的信息。由于编码器可以考虑到未来的信息,它们非常适合用于需要理解整个句子的任务,如文本分类、命名实体识别等。预训练编码器需要使其能够构建强大的表示,这通常通过预测某个被遮蔽的单词、预测下一个句子或者其它的预训练任务来实现。BERT就是一种典型的预训练编码器。
解码器
解码器主要用于生成输出信息。它们是语言模型的基础,用于预测下一个单词。解码器只能考虑到过去的词,而不能考虑到未来的
词,这使得它们非常适合于生成任务,如文本生成、对话系统等。GPT就是一种典型的预训练解码器。
编码器-解码器
编码器-解码器结构结合了编码器和解码器的优点。编码器首先处理输入信息,然后解码器生成输出信息。这种结构可以考虑到全局的上下文信息,因此非常适合于需要理解输入信息并生成相应的输出的任务,如机器翻译、文本摘要等。如何预训练编码器-解码器模型是一个开放的问题,因为需要考虑到如何有效地使用编码器和解码器的特点。*T5和BART都是典型的预训练编码器-解码器模型。
版权声明:本文为博主作者:Whitney_mao原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/Whitney66/article/details/136977669