
目录
A. Visual Question Answering (VQA)
B. Learning Compositional Representation
E. Comparison with Other Models
摘要
现有的视觉问答方法在数据量大的情况下表现良好,但在数据缺乏的情况下,对新的问题、对象、答案类别等准确度有限。然而,人类却可以快速适应这些新的类别,因为人们会组织以前见过的概念来描述新的类别,而深度学习方法几乎无法探索这些概念。在本文中,我们建议从有足够数据的答案中提取属性,然后将这些属性组合起来,以约束few-shot的学习。我们生成了few-shot VQA数据集,其中包含各种答案及其属性,无需人工操作。利用这个数据集,我们构建了属性网络,通过从图像的部分而不是整个图像中学习属性的特征来分离属性。VQA v2.0验证集证明了我们提出的属性网络的有效性,以及答案与相应属性之间的约束,以及我们的方法在很少训练数据的情况下预测答案的能力。
一、介绍、
与image caption相比,VQA需要复杂的推理过程来推断各种问题的正确答案。

VQA涉及来自输入图像的许多视觉任务,如图1所示,图像识别(“黑熊”,左上图)、对象检测(“儿童”,右上图)、场景识别和人类行为识别(“切割”,右下图)。

相比之下,VQA的答案是合成的,组合的,比如“切蛋糕”、“红黄相间”和“玩Wii游戏”,这些答案具有一些共同的属性。例如,在图2中,左上一行和右上一列中的所有答案都有相同的“骑行”动作,但对象不同,其中“骑摩托车”、“骑自行车”和“骑马”很容易被模型识别,因为有许多训练样本。尽管左下一行有很多“大象”的例子,但“骑大象”仍然很难正确分类,因为“骑大象”这样的样本很少。然而,当我们把这个新物体分成我们所知道的部分时,人类只需通过很少的示例来学习这个新的类别。如图2右栏所示,我们通过顶行图像中的大量示例以及底行中“大象”的含义了解了“骑行”的含义之后,我们可以通过组合这两个概念轻松识别“骑行大象”。
Learning Compositional Representations for Few-shot Recognition这篇论文学习了细粒度数据集中的属性,但它需要花费大量人力来标注每个图像的属性,并且没有明确地建模属性的表示。视觉问答作为一个元学习任务[17]是VQA中为数不多的few-shot研究之一,它从元学习的角度解决了这一问题,需要额外的记忆来存储支持集的权重,并且只针对答案仅在0到6之间变化的“数字”问题。在MAML[18]之后,Fast Parameter Adaptation[19]学习图像文本任务的适当初始权重,但其类别的数量多达20个,限制了其在现实中的使用。
在本文中,我们的目标是在few-shot设置下回答VQA的一般问题,这些问题更复杂,答案也多种多样。我们首先创建了学习网络主干的base set,以及用于few-shot答案的novel set。这两组都来自VQA v2的训练集,不需要额外的人力来标注答案的属性,然后我们重点学习属性的表示。视觉识别任务使用CNN的平均池化层,如ResNet[20]、GoogLeNet[21]和ResNext[22]进行分类,因为它描述了整个图像,但属性是来自图像的不同部分,例如,图2上部的“骑马”和下部的“大象”。因此,我们提出了属性网络,使图像的每个部分分别对属性进行评分。最后,我们对答案与其在base set中对应的属性之间的约束进行建模,然后将这些约束转移到novel set中学习few-shot答案的表示。
我们在VQA v2上进行了实验,在有1859个新答案的验证集上,我们的方法比直接在主干网络上分类获得了更高的准确率,在top-1和top-5的5-shot上分别接近2%和3%。此外,我们的模型在1-shot和5-shot上与[14]相当,在10-shot上更好,这表明了我们网络的有效性。
二、RELATED WORK
在本节中,我们将首先介绍VQA的相关研究,然后介绍少数镜头学习的方法。
A. Visual Question Answering (VQA)
VQA是基于输入图像回答给定问题的任务。问题通常用LSTM嵌入,图像由从预训练的模型中提取的固定大小网格特征表示,然后融合这两个特征,通过MLP进行答案预测。然而,并不是图像上的所有特征都与给定的问题相关,其中一些特征在融合之前应该被过滤掉,因此引入注意力机制来学习每个网格特征的权重,例如SAN[23]和DAN[24]。
由于问题和图像特征的分布不同,与线性方法相比,这两种特征的外积具有更好的解释性和性能。但由于其高维输出,很难进行优化。在Transformer模型[9]的推动下,DFAF的动态融合和MCAN涉及词和对象之间的所有关系,包括词和词、词和对象以及对象和对象。此外,Vilbert、VL bert、Structbert和LXMERT甚至直接微调了bert模型,而不考虑问题和图像特征的不同分布,并且该过程需要大量的域外数据,例如image caption数据集和基于文本的问答数据集。
B. Few-shot Learning
Few-shot learning旨在通过少量带标签的样本识别新的类别,这些few-shot算法中的第一类是元学习,它learns to learn。模型不可知元学习(MAML)[18]在各种任务上学习一个易于适应的模型,只需要几个梯度步骤就可以获得好的结果。优化模型[41]提出了一种基于LSTM的元学习器,用于更快地训练网络。元网络[42]和作为元学习任务的视觉问答[17]利用外部记忆来更新权重。另一类是metric learning,它学习对示例之间的相似度进行排序。Siamese neural networks[43]通过比较看不见的图像和标记的图像来对其进行分类。在计算查询特征和支持特征之间的距离时,匹配网络[44]用余弦相似度取代softmax,而原型网络[45]使用查询特征和支持特征平均值之间的欧氏距离。使用图神经网络的Few-shot learning[46]在标记和未标记的示例上构建图。除了这两类之外,数据增强方法,例如[47],[48]在基础数据中学习生成器,产生新数据。
C. Learning with attributes
学习组合属性是人类学习few-shot和zero-shot样本的自然方式。通过对这些组合属性的转换网络建模,从红酒到红番茄[50]可以对看不见的概念组合进行分类。表征学习中的组合性测量[51]建立了一个新的评估指标,以估算输入图像的属性之和(???)。基于密集属性的Attention[52]将图像中的区域特征分配给GloVe[53]中的语义向量。学习组合表示[14]将类别的特征空间分解为与其属性对应的子空间,这与我们的方法类似,但它忽略了编码特征的每个部分对属性的不同贡献。
三、METHODS
VQA任务的目标是基于图像回答问题。我们将图像转换为对象特征,其中
是检测到的对象数量,
是每个对象特征维度。问题由
A. Bilinear Graph Network
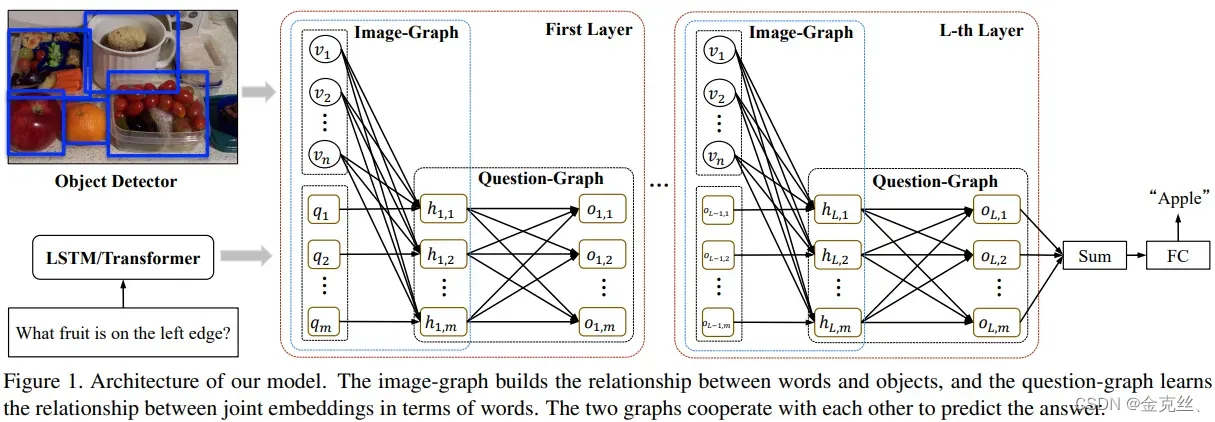
上图为BGN模型结构图,图像用n个对象级特征表示,问题用m个单词嵌入表示,Image-Graph建模单词和对象的关系,输出表示单词和对象的联合嵌入,Question-Graph建模联合嵌入之间的关系,输出
用以最终输出结果。
B. Learning Compositional Representation
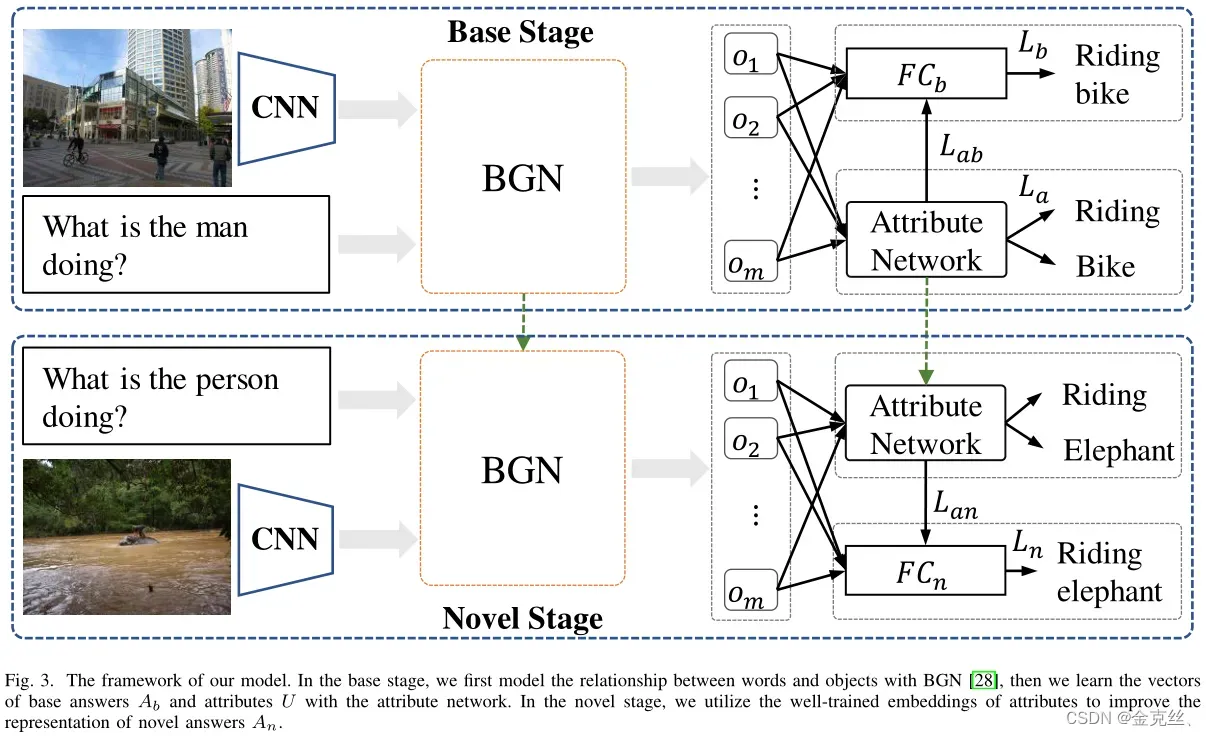
根据训练集的答案集,我们将其分为两个集合,一个是训练样本数较多的base set
,另一个是训练样本数较少的novel one
,其中
,
.
计算答案和单词及对象的联合嵌入之间的分数的简单方法如下:
![]()
其中,
,
是base set
的大小。此外,
表示答案
。此外,一对问题和图像可能存在多个正确答案,因此我们利用BCE作为损失函数:
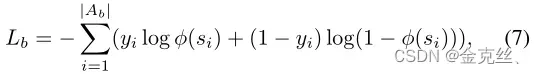
其中是答案
的分数,
,参考VQA v2评估指标。
正如我们在第一节中提到的,答案由几个属性组成,表示为
,其中
,
是属性集,
是答案
中的属性数。
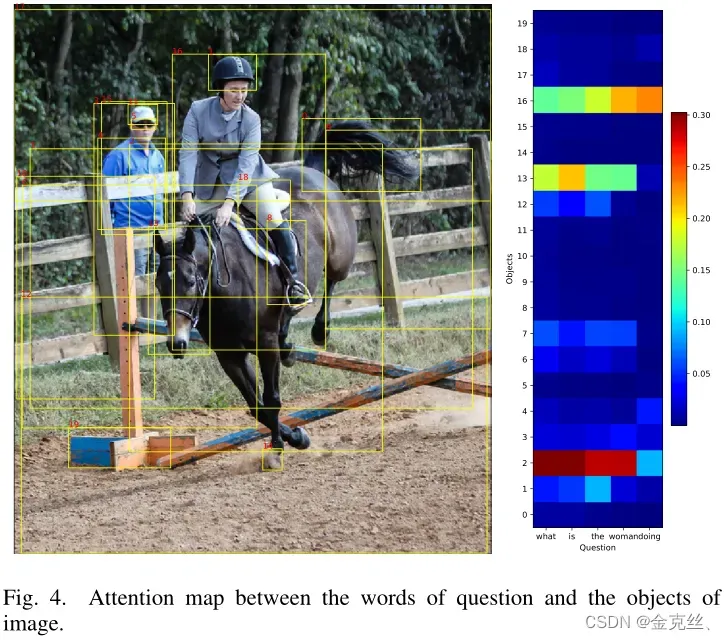
Attribute Network: 学习组合答案的关键是生成其属性的良好表示,我们也可以使用像公式6这样的图的统一向量来学习这些属性。但是正确答案中的属性可能来自给定图像的不同部分,应该分别处理,例如,在图4中,短语“what is”侧重于“horse”的对象(对象2),而“woman doing”则更关注“woman”的对象(对象16)。因此,我们建议使用属性网络来分别计算图的每个节点和属性之间的得分,而不是计算整个节点的得分(这里就是作者的方法部分,BGN模型就是直接计算所有节点的得分):
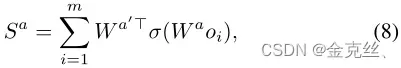
其中,
,
表示属性
。
由于多个属性构成了答案,因此我们还利用BCE作为其损失函数,计算如下:
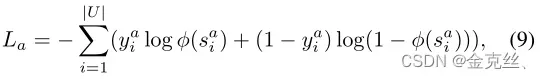
其中是属性
的标签。
此外,答案可以从其属性的表示中重建,因此我们最小化了它们之间的距离:
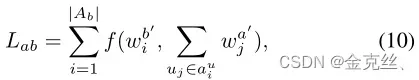
其中f是距离函数,例如余弦相似性和均方误差(MSE)。总的来说,我们在学习答案和属性向量的基础阶段,以及图3上半部分所示的框架的主干时,会有所有的损失:
![]()
其中λ是调整距离损失重要性的超参数。
Constrained by Attributes: 在新的数据集中,答案的表示很难学习,因为只有几个例子,这很容易导致过度拟合。然而,它们的属性是在我们的属性网络的基础阶段获得的,可以帮助学习这些答案的嵌入,如图3的下半部分所示:
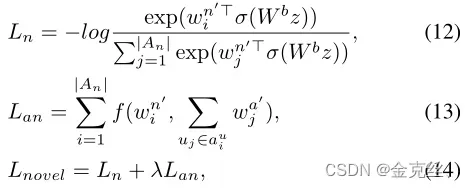
其中是novel answer
,基于few-shot learning的设置,我们只从正确答案中抽取一个答案
。请注意,我们只计算
和
损失中
的梯度来更新其权重,同时保持属性参数固定,以规范novel answers的学习。
四、EXPERIMENTS
在本节中,我们将在VQA v2上评估我们的方法。我们首先介绍了这个数据集,然后构建了few-shot数据集,然后描述了我们的实现细节和结果,最后进行了定性分析。
A、VQA v2.0 Datasets
该数据集基于MSCOCO图像构建,包含110万个问题,每个问题由10个人注释。
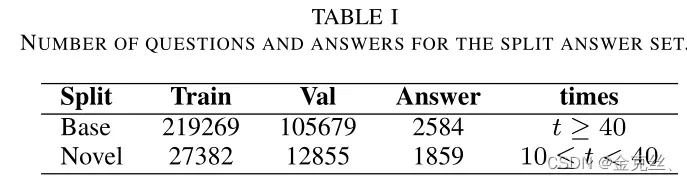
Constructing the few-shot dataset: VQA数据集的答案可以分为三种类型,即“yes\no”、“number”和“others”,我们重点关注“其他”的答案,因为它们比其他两类更复杂、更多样。我们首先收集base answer set,这些答案在训练数据集均中出现了40多次,结果是=2584。与[55]、[5]中使用的策略不同,我们收集了多个回答过的答案,而[55]、[5]中对每个问题只收集了一个正确答案。然后,我们使用spacy将这些答案分成tokens,这些token被视为它们的属性,并在删除一些无意义的单词(’and’、’is’、’do’、’&’和’are’)后组织到属性集中,从而得到
=2108个属性。通过组合这些属性,我们得到了一个novel answer set,其中的答案不在
中,并且出现了10次以上,共1859个答案,并且在验证数据集上也应用了类似的程序进行评估。表一显示了两个数据集的问题和答案数量。
B、Implementation Details
实验设置见原文。
BGN被选为我们的基准模型。在novel stage时,我们只需将base stage的FC层替换为novel stage的FC层,并学习它们在固定主干中的表示。由于在novel few-shot数据集上容易过度拟合,我们将1、5和10-shot learning的训练epoch分别缩短为40、20和14。
C、Evaluation Metrics
我们的目标是解决与其他类似模型[5]、[28]、[1]、[26]、[29]一样的一般VQA问题,因此我们使用[3]中的方法评估VQA v2验证数据集在1、5和10-shot设置下的top-1精度。此外,我们考虑了[14]之后的top-5表现。
D、Ablation Study
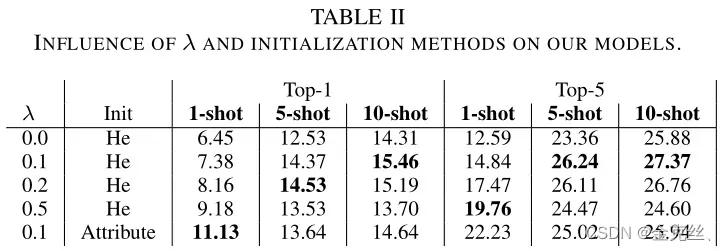
我们进行消融研究,以验证表2中属性网络的贡献。注意,当λ变为零时,我们的网络与BGN相同。对于top-1和top-5,性能随着λ的增加而增长,这表明了我们提出的网络的有效性。然而,当λ>0.2时,5-shot和10shot的性能会下降,可以解释的是,答案可以在一定程度上通过λ=0.1和λ=0.2的属性嵌入的总和来表示,但是像λ=0.5这样的更高值限制了它从few-shot数据集领域学习新信息的潜力。在最后一行中也发现了这种现象,它直接从属性初始化答案的嵌入,而不是初始化[21],在1-shot中,精确度提高了很多,但在其他两种设置中,精确度迅速下降。因此,我们选择λ=0.1作为参数,并将初始化作为初始化方法。
E. Comparison with Other Models
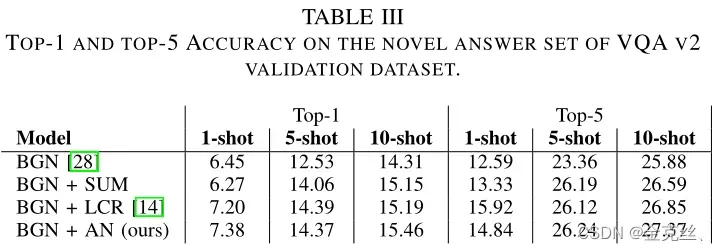
在表3中,我们将我们的方法与其他方法进行了比较:BGN从头开始训练新答案的权重;BGN+SUM直接利用联合嵌入z,利用答案与其属性之间的约束,学习新答案的权重;BGN+LCR与我们的类似,只是它使用距离函数f的余弦相似性,并且不涉及网络来建模属性和输入表示之间的损失(图[14]和图[VQA]的图和问题)。
表3的最后三行显示,与BGN相比,对类别及其相应属性之间的约束进行建模的额外模块可以提高few-shot学习的性能。此外,我们的BGN+AN模型在1-shot和5-shot激发学习中的性能与BGN+LCR[14]相当,并且比10-shot激发学习中的性能要好得多。因为LCR没有考虑关节嵌入和属性之间的关系,比如图3中的LA。在给定更多训练数据的情况下,我们的模型在基础阶段学习到了更好的属性表示,之后用于改进新阶段类别的训练。此外,在相同主干网的情况下,BGN+AN中提出的属性网络比BGN+sum中的sum方法工作得更好。因为这些属性来自给定图像的不同部分,如图2所示的下部的“大象”和上部的“骑行”。因此,问题图的每个输出节点O既有来自问题的文本信息,也有来自图像的相关视觉信息,因此可以用它来表示图像的关注部分中的属性,证明像其他一般识别任务[14]、[20]一样简单地汇总这些节点并不适合表示所有属性。
F、Qualitative Analysis

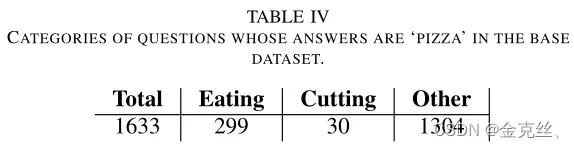
为了可视化我们的方法的效果,我们在图5中展示了BGN和我们的BGN+AN网络预测的答案。在最下面一行的第二张图片中,BGN无法正确回答问题。因为在base阶段,当它在正确答案中出现的图像中出现“pizza”时,它总是与问题中的“进食”相关,这是BGN模型学习到的一种强烈偏见,如表IV所示。相比之下,我们的模型从除“pizza”之外的其他示例中学习“切割”动作,如“蛋糕”、“苹果”和“纸”。在novel阶段,使用给定图像中检测到的“切割”和“披萨”属性来改进答案“切割披萨”的表示。类似的问题也出现在第一排的第三张图片(人们坐在长凳上)和第一张图片(猫坐在沙发上)中。此外,一个对象总是用多种颜色来描绘,例如顶行的第四个图像和底行的第三个图像。除了在novel阶段从零开始学习新组合颜色的矢量外,我们在base阶段利用训练有素的单一颜色表示来增强它,而无需额外的人工注释。这也适用于查找图像中的对象,例如顶行第二个图像中的花瓶和花,以及底行第四个图像中的勺子和叉子。
五、结论
在这项工作中,我们将few-shot设置应用于一般的VQA问题,然后我们提出了一个两阶段网络来克服它。我们提出VQA中的few-shot数据集,它有两个子集,即base set和novel set,我们不需要人工就能生成答案的属性。在给定大量的base数据集训练数据的情况下,我们利用BGN对问题中的单词和图像中的对象之间的关系进行建模,并在base阶段生成它们的联合嵌入。此外,我们还利用所设计的属性网络以及属性与其源答案之间的约束,得到了属性的表示。在经过良好训练的属性向量的帮助下,我们改进了在novel阶段只有几个样本的合成答案的表示。将我们的方法应用于VQA v2的验证集。我们的方法在top-1和top-5精度方面比基线方法和其他类似网络具有更好的性能。然而,与base set(BGN为61.18%)相比,结果(top-1名准确度中10-shot的15.46%)远不能令人满意,这一问题还需要进一步研究。
文章出处登录后可见!