前言
这篇博客主要对目前视觉SLAM和其他各个领域交叉(主要是深度学习领域和传感器领域)所产生的成果进行记录
1 视觉SLAM与深度学习的融合
视觉SLAM与深度学习的结合是很顺其自然的,视觉SLAM处理的是图像信息,深度学习处理的最好的也是图像信息,所以,深度学习能为视觉SLAM提供助力是可接受的。
参考文献包括:
[1] 深度学习结合SLAM的研究思路/成果整理之(一)
[2] 当前深度学习和 SLAM 结合有哪些比较好的论文
1.1 用深度学习替换SLAM前端工作中的一个/几个部分
SLAM前端需要处理的工作总结为两个方面:获取相机和路标点的位姿估计。这里面根据方法的不同,又可细分成很多不同的分类,深度学习也主要是帮助SLAM解决相机和路标点的位姿估计问题中的一些难点。
a. 对基于
特征点的SLAM算法,有深度学习辅助进行特征点的提取与特征点的匹配
本部分内容参考自:基于深度学习的特征提取和匹配方法介绍
SIFT/SURF/FAST之类特征点已经得到了很好的应用,但现在通过CNN模型形成的特征图来定义的特征点已经在很大程度上超过了手工设计的特征点的效果
本文和参考文献的关注点不同,更为关注方法本身是否实时,因为特征提取和匹配仅仅是SLAM前端的一部分工作,前端处理图像的实时速度一般要达到30Hz(数据来源视觉SLAM十四讲高博P146的注释),也就是在30ms内完成对一帧图像的特征提取和匹配,目前传统方法中,只有ORB和FAST可以满足。
下表显示了,目前的深度学习方法中,只有SuperPoint方法达到了实时的要求(来源于特征提取:传统算法 vs 深度学习,但该方法是在Titan X GPU上可以输出70HZ的结果,而换成普通CPU后速度会显著性下降,此时是否还满足实时性,笔者没有验证)
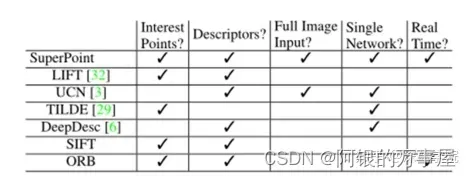
在这里,我们主要介绍一下SuperPoint这个方法
1. SuperPoint: Self-Supervised Interest Point Detection and Description
该方法采用了自监督的全卷积网络框架,训练得到特征点(keypoint)和描述子(descriptors)。自监督指的是该网络训练使用的数据集也是通过深度学习的方法构造的。该网络可分为三个部分(见图1),a. BaseDetector(特征点检测网络),b. 真值自标定模块。c. SuperPoint网络,输出特征点和描述子。
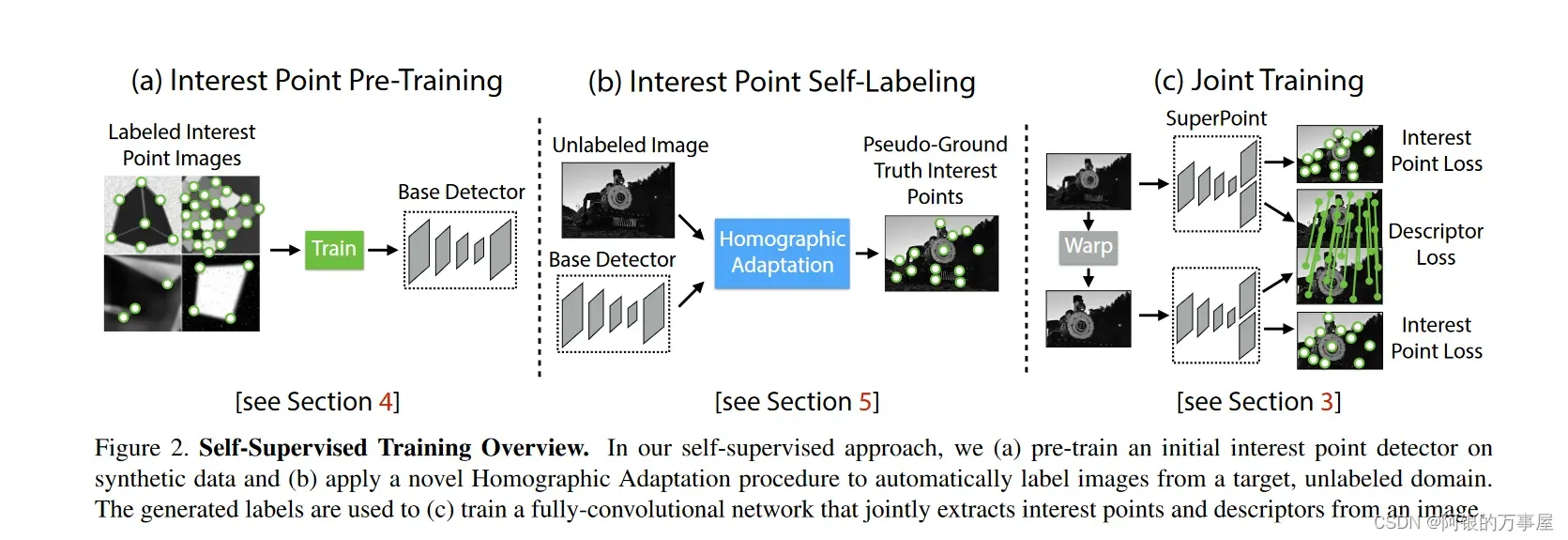
下面分别介绍一下三个部分:
BaseDetector特征点检测:
首先创建一个大规模的合成数据集:由渲染的三角形、四边形、线、立方体、棋盘和星星组成的合成数据,每个都有真实的角点位置。渲染合成图像后,将单应变换应用于每个图像以增加训练数据集。单应变换对应着变换后角点真实位置。为了增强其泛化能力,作者还在图片中人为添加了一些噪声和不具有特征点的形状,比如椭圆等。该数据集用于训练 MagicPoint 卷积神经网络,即BaseDetector。注意这里的检测出的特征点不是SuperPoint,还需要经过真值自标定操作。
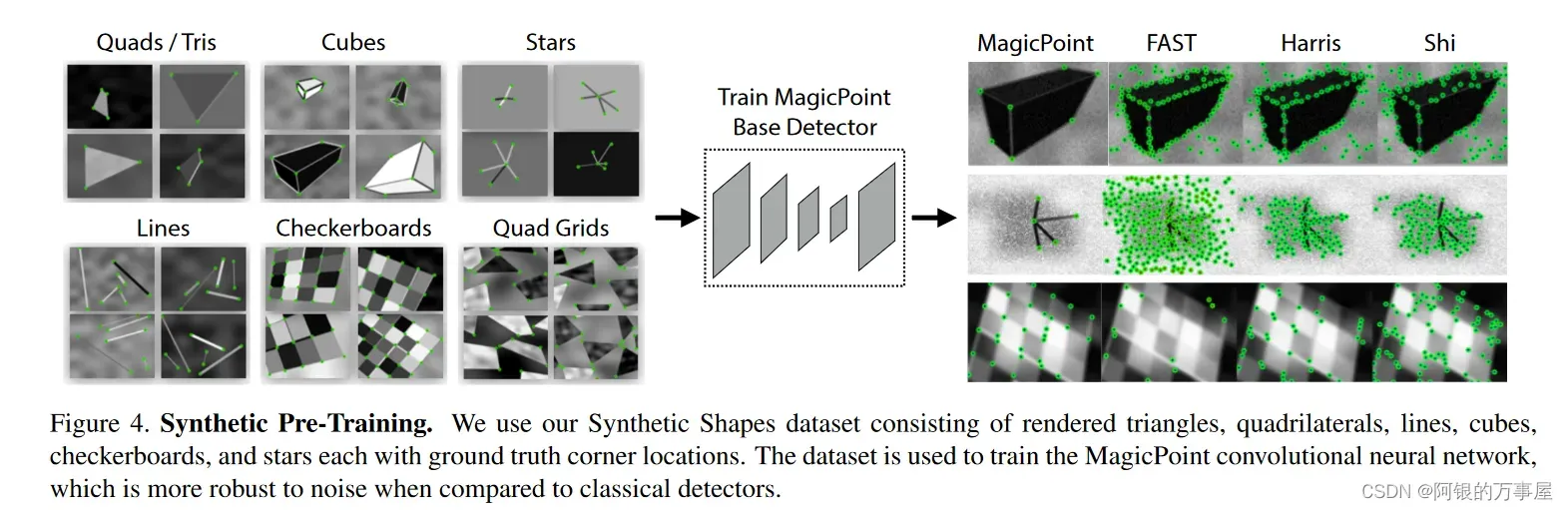
真值自标定:
Homographic Adaptation 旨在实现MagicPoint的自我监督训练。它多次将输入图像进行单应变换(所以实验部分只说明了方法在单应变换下的提取有效性),以帮助MagicPoint从许多不同的视点和尺度看到场景。以提高检测器的性能并生成伪真实特征点。
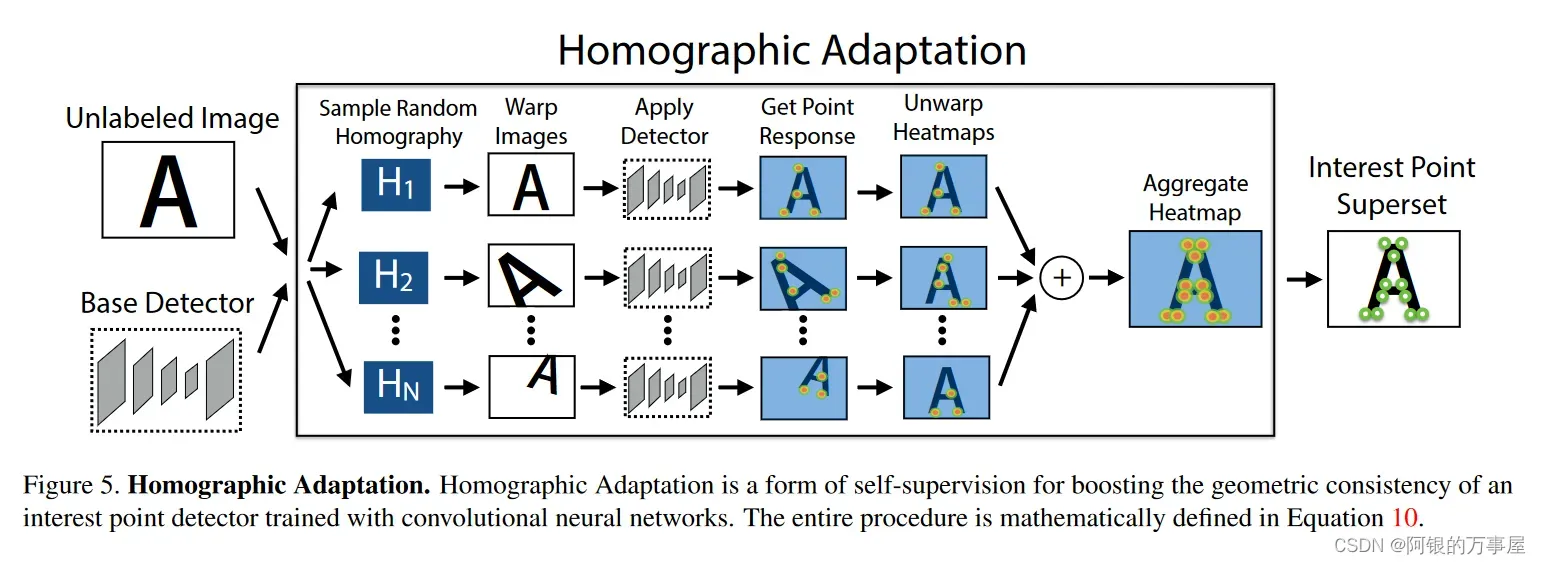
Homographic Adaptation可以提高卷积神经网络训练的特征点检测器的几何一致性。该过程可以反复重复,以不断自我监督和改进特征点检测器。Homographic Adaptation 与 MagicPoint 检测器结合使用后的模型就称为 SuperPoint。
SuperPoint网络:
SuperPoint 是全卷积神经网络架构,它在全尺寸图像上运行,并在单次前向传递中产生带有固定长度描述符的特征点检测。该模型有一个共享的编码器来处理和减少输入图像的维数。在编码器之后,该架构分为两个解码器“头”,它们学习特定任务的权重——一个用于特征检测,另一个用于描述子计算。大多数网络参数在两个任务之间共享,这与传统系统不同,传统系统首先检测兴趣点,然后计算描述符,并且缺乏在两个任务之间共享计算和表示的能力。
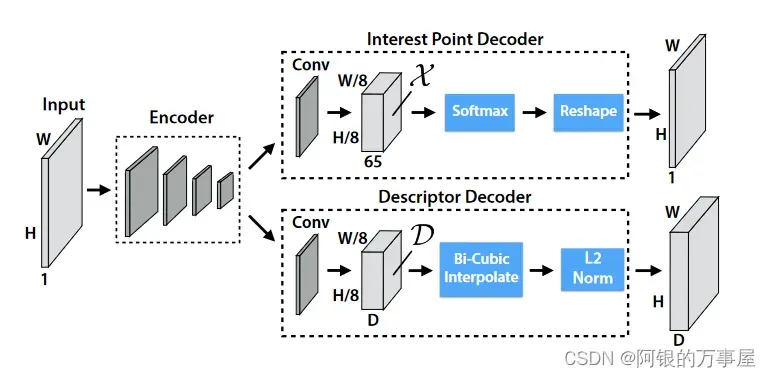
SuperPoint 架构使用类似VGG编码器来降低图像的维度。编码器由卷积层、通过池化的空间下采样和非线性激活函数组成。解码器对图片的每个像素都计算一个概率,这个概率表示的就是其为特征点的可能性大小。
描述子输出网络也是一个解码器。先学习半稠密的描述子(不使用稠密的方式是为了减少计算量和内存),然后进行双三次插值算法(bicubic interpolation)得到完整描述子,最后再使用L2标准化(L2-normalizes)得到单位长度的描述。
最终损失是两个中间损失的总和:一个用于兴趣点检测器 Lp,另一个用于描述符 Ld。我们使用成对的合成图像,它们具有真实特征点位置和来自与两幅图像相关的随机生成的单应性 H 的地面实况对应关系。同时优化两个损失,如图所示。使用λ来平衡最终的损失:
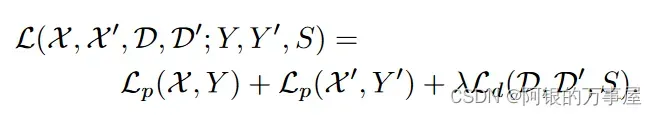
对特征点提取的精度(正确匹配)的实验结果如下:
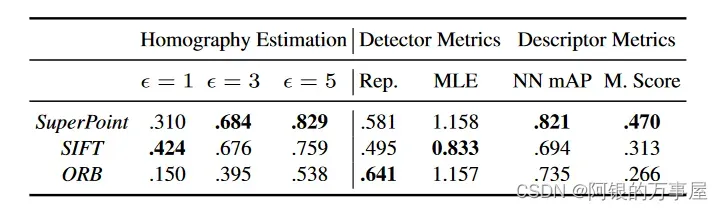
展示效果良好,值得注意的是,虽然文章最后的Homograpyhy Estimation指标,SuperPiont超过了传统算法,但是评估的是单应变换精度。单应变换在并不能涵盖所有的图像变换。比如具有一般性质的基础矩阵或者本质矩阵的变换,SurperPoint表现可能不如传统方法。
2. Toward Geometric Deep SLAM
这篇文章是和SuperPonit同年同意团队产出的另一篇文章(真是高产啊),该方法是对SuperPoint做了简化,使得在普通CPU上也可以达到30+Hz的处理速度(然而这也说明了,SuperPoint在普通CPU上可能无法达到SLAM的要求)
简化主要体现在去除了描述子层,而是直接通过MagicWrap给出单应矩阵H,网络结构如下:
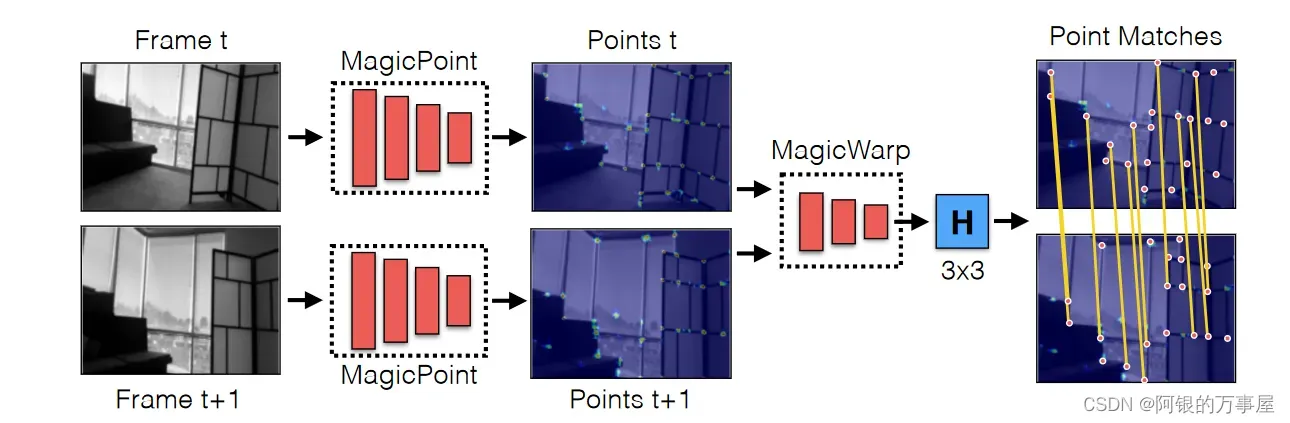
对该文章的解析可以移步这位博主的讲解Toward Geometric Deep SLAM
b. 利用深度学习进行
单目深度估计
这个方法就目前的水平而言,还很难应用到SLAM中去,查阅了这位博主的记录低成本测距方案—单目深度估计,目前在精度和速度上平衡的比较优秀的方案,如BTS(关于论文的解读请移步从大到小:多尺度局部平面引导的单目深度估计),目前精度上已在KITTI数据集上达到第一位,但推理速度需要60ms,这严重超出SLAM的“预算”
而且SLAM中,对极约束处理特征点的深度已经是一个比较好的方案了,毕竟深度信息是会被不断优化的,开始的不准会在之后逐步修正,这也是SLAM相对于深度学习的数学优势。
所以这部分我不是特别看好,简单举了一个BTS的例子,供大家了解
2 视觉SLAM与其他传感器的融合
2.1 视觉+IMU
文章出处登录后可见!