 本文收录于《深入浅出讲解自然语言处理》专栏,此专栏聚焦于自然语言处理领域的各大经典算法,将持续更新,欢迎大家订阅!
本文收录于《深入浅出讲解自然语言处理》专栏,此专栏聚焦于自然语言处理领域的各大经典算法,将持续更新,欢迎大家订阅! 个人主页:有梦想的程序星空
个人主页:有梦想的程序星空 个人介绍:小编是人工智能领域硕士,全栈工程师,深耕Flask后端开发、数据挖掘、NLP、Android开发、自动化等领域,有较丰富的软件系统、人工智能算法服务的研究和开发经验。
个人介绍:小编是人工智能领域硕士,全栈工程师,深耕Flask后端开发、数据挖掘、NLP、Android开发、自动化等领域,有较丰富的软件系统、人工智能算法服务的研究和开发经验。 如果文章对你有帮助,欢迎
如果文章对你有帮助,欢迎
关注、
点赞、
关系抽取的背景和定义
关系抽取(Relation Extraction,简称RE)的概念是1988年在MUC大会上提出,是信息抽取的基本任务之一,目的是为了识别出文本实体中的目标关系,是构建知识图谱的重要技术环节。
知识图谱是语义关联的实体,它将人们对物理世界的认知转化为计算机能够以结构化的方式理解的语义信息。关系抽取通过识别实体之间的关系来提取实体之间的语义关系。在现实世界中,关系的提取要比实体提取复杂得多,自然句子的形式也多种多样,所以关系的提取比实体提取困难得多。
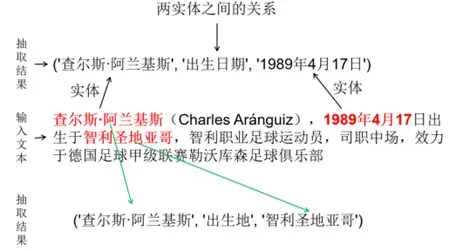
图1 关系抽取的示例
关系抽取是从纯文本中提取未知关系事实并将其加入到知识图谱中,是自动构建大规模知识图谱的关键。传统方法高度依赖于特征工程,深度学习正在改变知识图谱和文本的表示学习。
关系抽取的详细分类
关系抽取就是从非结构化文本中提取实体之间的关系。依据实体是否在文本中被标记,关系抽取方法可分为联合抽取和流水线式抽取。
联合抽取是指从文本中完成实体识别和关系分类任务,流水线式抽取是指先使用实体识别模型识别文本中的实体对,然后判断实体对的关系。一个完整的流水线式关系抽取系统包括:命名实体识别、实体链接和关系分类。
关系抽取模型大致可分为三类:基于pattern的方法、统计机器学习和神经网络。其中神经网络方法效果更好。依据抽取语料形式,关系抽取模型又可分为句子级关系抽取和段落级关系抽取。句子级关系抽取指两个实体在一个句子中,段落级关系抽取指两个实体不在同一个句子中。句子级关系抽取在实际业务中更常见。
神经网络可以从大规模数据中自动学习特征,此类方法的研究多集中在设计模型结构捕获文本语义。当前最好的关系抽取模型都是有监督模型,需要大量标注数据并且只能抽取预定义的关系。这种方法不能面对复杂的现实场景,例如少样本。目前已有不少工作探索在现实场景下的关系抽取任务。
关系抽取的主要任务
关系抽取主要分为两个任务:
(1)关系分类
基于预先给定的关系,对实体对进行分类匹配。
(2)开放关系抽取
直接从文本中抽取结构化文本关系,对文本关系映射到知识库的规范关系。
关系抽取经典算法和模型详解
(1)基于规则的关系提取
-
基于触发词模式的提取
许多实体的关系可以通过手工模式的方式来提取,寻找三元组(X,α,Y),X,Y是实体,α是实体之间的单词。比如,“Paris is in France”的例子中,α=“is”。这可以用正则表达式来提取。
这些是使用word sequence patterns的例子,因为规则指定了一个遵循文本顺序的模式。不幸的是,这些类型的规则对于较长范围的模式和具有更大多样性的序列来说是不适用的。例如:“Fred and Mary got married”就不能用单词序列模式来成功地处理。
相反,我们可以利用句子中的从属路径,知道哪个词在语法上依赖于另一个词。这可以极大地增加规则的覆盖率,而不需要额外的努力。
我们也可以在应用规则之前对句子进行转换。例如:“The cake was baked by Harry”或者“The cake which Harry baked”可以转化成“Harry bake The cake”。然后我们改变顺序来使用我们的“线性规则”,同时去掉中间多余的修饰词。
-
基于依存关系(语法树)
以动词为起点构建规则,对节点上的词性和边上的依存关系进行限定。
基于规则的关系抽取算法的优点:人类可以创造出具有高准确率的模式,可以为特定的领域定制。缺点:人类模式的召回率仍然很低(语言种类太多),需要大量的人工工作来创建所有可能的规则,必须为每个关系类型创建规则。
(2)有监督关系抽取:
有监督神经网络方法是指采用深度学习方法在大规模有监督数据集上训练模型,此类方法是目前效果最好且研究最深入的。
进行有监督关系提取的一种常见方法是训练一个层叠的二分类器(或常规的二分类器)来确定两个实体之间是否存在特定的关系。这些分类器将文本的相关特征作为输入,从而要求文本首先由其他NLP模型进行标注。典型的特征有:上下文单词、词性标注、实体间的依赖路径、NER标注、tokens、单词间的接近距离等。
我们可以通过下面的方式训练和提取:
(1)根据句子是否与特定关系类型相关或不相关来手动标注文本数据。例如“CEO”关系:“Apple CEO Steve Jobs said to Bill Gates.” 是相关的,“Bob, Pie Enthusiast, said to Bill Gates.”是不相关的。
(2)如果相关句子表达了这种关系,就对正样本/负样本进行手工的标注。“Apple CEO Steve Jobs said to Bill Gates.”:(Steve Jobs, CEO, Apple) 是正样本,(Bill Gates, CEO, Apple)是负样本。
(3)学习一个二分类器来确定句子是否与关系类型相关。
(4)在相关的句子上学习一个二分类器,判断句子是否表达了关系。
(5)使用分类器检测新文本数据中的关系。
有监督关系抽取任务并没有实体识别这一子任务,因为数据集中已经标出了subject实体和object实体分别是什么,所以全监督的关系抽取任务更像是做分类任务。模型的主体结构都是特征提取器+关系分类器。特征提取器比如CNN,LSTM,GNN,Transformer和BERT等。
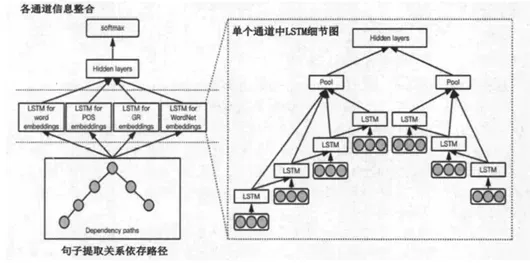
图2 基于LSTM的有监督关系抽取方法
有监督关系抽取的优点:高质量的监督信号(确保所提取的关系是相关的),有明确的负样本。缺点:标注样本很贵,增加新的关系又贵又难(需要训练一个新的分类器),对于新的领域不能很好的泛化,只对一小部分相关类型可用。
(3)远程监督模型:
论文:《Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks》
链接:https://aclanthology.org/D15-1203.pdf
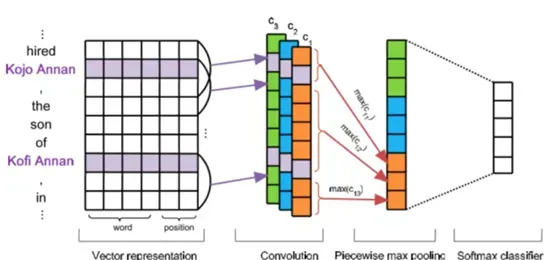
图3 PCNN模型架构
这篇论文工作是将Fully Supervised 转化为Distant Supervised。Distant supervised 会产生有大量噪音或者被错误标注的数据,直接使用supervised的方法进行关系分类,效果很差。原始方法大都是基于词法、句法特征来处理, 无法自动提取特征。而且句法树等特征句子长度变长的话,正确率很显著下降。因此文中使用Multi Instance Learning的at least one假设来解决第一个问题;在Zeng 2014 的CNN基础上修改了Pooling的方式,解决第二个问题。
训练强大的关系抽取模型需要更多的高质量数据,但是构建这样的数据集需要大量人工标注,耗时费力。Mike Mintz[22]首次使用远程监督方法生成标注数据,远程监督的假设是:如果两个实体有关系,那么任何包含这两个实体的句子都可以表达这种关系。例如,Ra{e1, e2}表示实体e1和e2具有关系Ra,若存在一个句子同时包含e1和e2,则认为该句子表达了关系Ra,将该句子标注为关系Ra的一个正样本。使用这种方法只需一个知识库和一个文本库便可自动得到标注数据。
远程监督似乎是一种解决监督数据不足的完美解决方案,但实际上远程监督数据存在如下问题:1)并非所有同时包含e1和e2的句子都可以表达关系Ra,因此数据集中存在大量标注错误问题;2)无法解决一对实体含有多关系的情况;3)False negative问题,标记为负样本的实例实际存在关系,但这种知识在知识图谱中不存在,导致标记错误。第二个问题是远程监督无法解决的问题,因为在知识图谱中两个节点间只能存在一条边,所以无法建模一对实体存在多个关系的情况。第三个问题可以通过更好的生成负样本方式缓解,例如选择包含两个明显不存在关系的实体对的句子作为负样本。第一个问题是最严重的,目前大量的研究多集中于此。
缓解远程监督数据噪声有三种方法:1)多实例学习,从多个实例中选择最有效的实例作为训练样本;2)使用外部信息选择有效实例;3)使用复杂的模型和训练方法,例如soft label、增强学习、对抗学习。
(4)联合关系抽取
参数共享的联合模型抽取spo三元组的过程是分成多步完成的(不同步),整个模型的loss是各个过程的loss之和,在求梯度和反向更新参数时会同时更新整个模型各过程的参数,后面过程的训练可以使用前面过程的结果作为特征 (注:管道模型各子过程之间没有联系)。目前多数SOTA方法都使用这种方式。
联合解码的联合模型则更符合“联合”的思想,没有明确的将抽取过程分为实体识别和关系分类两个子过程,spo三元组是在同一个步骤中进行识别得到的,真正实现了子任务间的信息共享(缺陷:不能识别重叠的实体关系)。
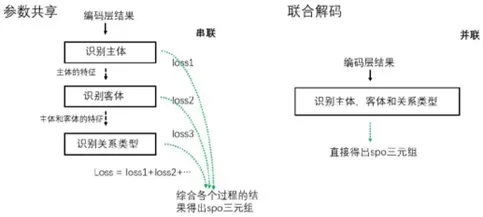
图4 联合关系抽取模型的种类
-
使用参数共享的经典模型
论文:《End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures》
链接:https://aclanthology.org/P16-1105.pdf
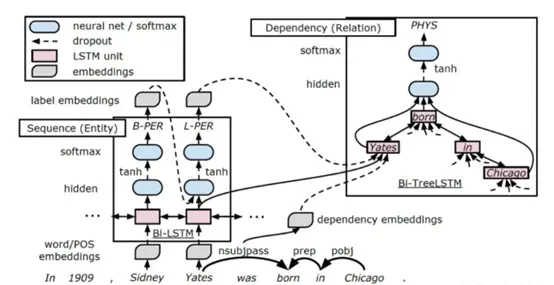
模型中有两个BiLSTM,一个基于word sequence,主要用于实体检测;另一个基于tree structures,主要用于关系抽取;后者堆叠在前者上,前者的输出和隐层作为后者输入的一部分。
该论文提出了一个新的端到端模型来提取实体之间的关系。模型使用双向序列RNNs(从左到右和从右到左)和双向树结构(自下而上和自上而下)LSTM-RNNs,对实体和关系进行联合建模。首先检测实体,然后使用一个递增解码的nn结构提取被检测实体之间的关系,并且使用实体和关系标签共同更新nn参数。与传统的端到端提取模型不同,模型在训练过程中还包含两个增强功能:实体预训练(预培训实体模型)和计划抽样,在一定概率内用gold标签替换(不可靠)预测标签。这些增强功能缓解了早期实体检测低性能问题。
该模型主要由三个表示层组成:字嵌入层(嵌入层)、基于字序列的LSTM-RNN层(序列层)和基于依赖子树的LSTM-RNN层(依赖层)。解码期间,在序列层上建立基于贪心思想的从左到右的实体检测,在依赖层上,利用dependency embedding和TreeLSTM中的实体对最小路径,来辅助关系分类,依赖层堆叠在序列层上,这样共享参数由实体标签和关系标签的决定。
(2)使用联合解码的经典模型
论文:《Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme》
链接:https://aclanthology.org/P17-1113.pdf
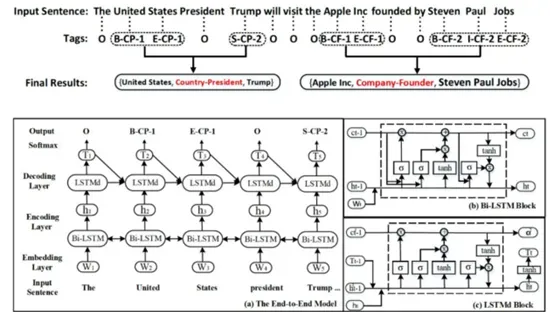
将实体识别和关系分类转化为序列标注问题,采用一种端到端模型, 通过编码器对句子进行编码,将隐层向量输入解码器后直接得到spo三元组,没有将抽取过程分为实体识别和关系分类两个子过程。
此文将实体关系联合抽取转换成一种新的标注模式,无需像以往研究一样,将实体和关系分步处理,直接对三元组建模。新的标签模式还可兼顾关系的方向性。针对新的标签模式,设计了一种新的loss bias函数。这为我们提供了一种新的思路,即复杂的模型往往不一定会有更好的效果,尤其对于工业及应用,代价更是无法预测。但是任务转换上的巧思,能让模型轻量的同时,得到好的效果。
(3)预训练模型+关系分类
输入层BERT:分别用特殊符号$和#号标识两个实体的边界和位置;
利用了BERT特征抽取后2个部分的特征:BERT [CLS]位置的embedding和两个实体相对应的embedding;
将上述3类特征拼接起来,再接一个FC和softmax层输出关系的分类。
(4)预训练模型+联合抽取
使用一个模型得到输入文本中的实体以及实体之间的关系,包括实体抽取模块、关系分类模块和共享的特征抽取模块。
关系分类模块包括:BERT对输入序列编码得到特征序列;NER模块的输出,经过argmax函数得到一个与输入序列长度相同,转化为固定维度的序列;拼接得到的向量分别通过一个FFN层,通过一个Biaffine分类器,预测出实体之间的关系。
关注微信公众号【有梦想的程序星空】,了解软件系统和人工智能算法领域的前沿知识,让我们一起学习、一起进步吧!
文章出处登录后可见!