简介
首先,这篇文章介绍了短文本分类的一些分类思想,比方说说LDA(潜在语义分析)、p-LDA(概率潜在语义分析)、潜在狄利克雷分析等等。
但是在我阅读学习的过程中仍然是还存在许多不足之处,比方说:阅读的速度过慢,记笔记不知道怎么记,包括这篇博客都是之后才进行覆写的,接下来我会进行相关阅读结果的阐述。
文章结构
本文献的主要结构如下:
1、This paper analyzes the challenges associated with classifying short text and systemic summarizes the existing related methods to short text classification using analytical measures.
2、After the analysis of the feature and difficulty of short text, we point out the process of short text classification in section II
3、short text classification based on semantic analysis is introduced(基于语义分析的短文本呢分类在第三部分被介绍)
4、some algorithms on semi-supervised short text classification in section IV(第四部分会介绍一些的针对于短文本分类的半监督算法)
5、Section V and Section VI introduce the ensemble model for classifying short text and online shor text classification, respectively
6、relevant evaluating measures in Section VII
7、we summarize the methods for classifying short text.
文章一开始指出由于短文本的自然特性,比方说分散性、大规模、及时性以及非标准化,因而对短文本进行分类是一个挑战。因为短文本中有限的单词不能代表特征空间以及单词与文档之间的关系,因此,对于传统的分类方法而言,很难对短文本进行分类。(首先指出,短文本分类是一个挑战,同时指出短文本分类很难使用传统的方法来进行分类)
这篇文章主要是从介绍短文本的特点->短文本分类的难度->现在主流的针对短文本分类器以及模型的工作。
- short text classification using sematic analysis, semi-supervised short text classification, ensemble short text classification, and
real-time classification.- evaluations of short text classification are analyzed in our paper.
- summarize the existing classification technology
- prospect for development trend of short text classification.
摘要
顺利的运用短文本分类变得格外重要对于许多web网站以及IR(信息检索)的应用,然而,对这些类型的文本和Web数据进行分类是一个新的挑战。
并不像普通的文档那样,这些文本以及Web信息片段通常是更加嘈杂,有更低的话题关注度,并且更加短,他们由十几个单词至一些句子来构成。由于长度较短,它们不能提供足够的词共现,或共享上下文来进行良好的相似性度量。 由于数据的分散性,所以通常依赖于词的频率、充足的词共现或者是通过共享上下文来度量文档的相似性的机器学习方法 常常不能达到我们所要的精确性。
背景
1、短文本的特征
its main characteristic of the text length is very short, no longer than 200 characters
通常情况下,短文本的特征:
-
稀疏性:
a short text only contains several to a dozen words with a few features, it does not provide enough words co-occurrence or shared context for a good similarity measure. It is difficult to extract its valid language features.
-
及时性:
short texts are sent immediately and received in real time. In addition, the quantity is very large.
-
非标准性
The description of the short text is concise, with many misspellings, non-standard terms and noise.
-
噪声和分布不均衡:
The application background (such as network security) needs to deal with massive amounts of short textual data. However, we may focus on only a small part (detecting objects) among the large-scale data. Therefore, useful instances are limited, and the distribution of short text is imbalanced.
-
数据量大、标签瓶颈:
It is difficult to manually label all of the large scale instances. Limited labeled instances may only provide limited information(有限的标签实例只能提供有限的信息). So how to make full use of these labeled instances and other unlabeled instance has become a key problem of short text classification.
2、传统方法的缺点
大部分的传统分类方法(比如:SVM、朴素贝叶斯、KNN算法)是基于术语频率的相似度,同时忽视了短文本的特征,这些传统的方法可能并不能够解决短文本分类。
比方说朴素朴素贝叶斯算法就不能够保证较高的精确度,如果标签的信息不完整的话,
除此之外,一些基于SVM的分类方法可以使用语义信息来提高分类器的性能。
3、短文本分类
文本文档的自动分类在许多应用程序及时、正确地分类和提供适当文档的能力方面发挥着至关重要的作用。
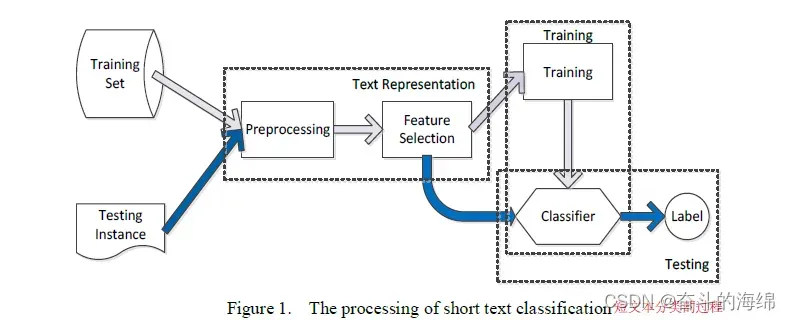
文本分类的过程:
首先,给出一个文档集合D和一个标签集合C,同时定义一个函数F,F将会从C中分配相应的标签给到D中的每一个文档。
例如,在短文本分类中,D可能包含报纸上所有分类广告的集合,因此C可能是同一份报纸上分类部分的标题集合。
许多学习方法,如k近邻(k- nn), 朴素贝叶斯,最大熵模型,支持向量机 (SVMs),已应用于许多具有不同基准集的分类问题,并取得了满意的结果。但是呢,由于短文本分类的特征以及难点导致传统的分类方法并不擅长于进行短文本分类。
4、短文本分类的难题
如何合理表示和选择特征项,有效降低空间维数和噪声,提高分类精度成为短文本分类的难题。
基于语义分析的短文本分类
1、引入语义分析
目前降低特征空间维度的方法是 “基于语义特征以及语义分析”
because the processing of text classification is generally in Vector Space Model (VSM) ,
which has the basic assumption that the relationships of words are independent, neglected the correlation between texts.
(由于文本分类的过程通常是基于“向量空间模型”的,它有一个基本的假设,就是每个词之间都是相互独立的,同时忽略各个文本之间的联系)
short text has weaker capacity of semantic expression, which is needed this correlationship.
(但是短文本的语义表达能力较弱,因此,对于短文本来讲,它就需要上述的这种文本之间的联系)
While traditional classification cannot distinguish language fuzziness of natural language, cognates and synonyms, all of which are abundant in short text.
(而传统的分类无法区分自然语言、同源词和同义词的语言模糊性,而这些词在短文本中都非常丰富。)
因此传统的分类方法通常不能够实现对于短文本所预想的精确性
2、阐述语义分析的关注点、引出LSA(潜在语义分析)的概念
语义分析更注重概念、内部结构、语义层次以及语篇之间的相关性,从而获得更具表现力和客观性的逻辑结构
潜在语义分析利用统计方法提取潜在语义结构,消除同义影响,降低特征维数和噪声。
Short Text Classification Using Latent Semantic Analysis (LSA)——潜在语义分析
首先文章指出了潜在语义分析所基于的假设:
在文本数据中有潜在的语义结构,并且词和文档之间的联系可以在这个语义结构中被重新描述。
LSA可以将向量空间转化为语义空间。
LSA的操作流程如下:
LSA可以通过统计方法,来提取并且量化语义空间,减少词之间的关联性。同时LSA可以减少高维向量矩阵从而构建一个高效描述词与文档之间关系的子空间。
LSA中提出许多降维的方法,比如:“奇异值分解(SVD)”、“半离散分解”、“非负矩阵”。本文中介绍了SVD方法。
基于SVD的LSA的处理方法如下:
1、每一个短文本都被当做为一个向量,因此,词-文档矩阵Aij中的每一项aij 表示词在相应的文档中是否缺失或者在没有缺失的情况下,权重是多少。其中,每一行代表一个词,每一列代表一个短文本。
2、矩阵A通常很稀疏,这个矩阵通常非常稀疏,因为大多数文档只包含整个文档集合中看到的术语总数的一小部分。
3、计算aij 的方法如下:
为了关注每个term(或document)的贡献,我们应该计算aij的权重。
传统的方法是:
其中,LWij 表示局部权重,对术语i在文档j中出现的频率取log
GWij 表示全局权重,于词在整个数据集中的熵,熵基于这个术语在每个文档中出现的次数。
4、对于矩阵A的奇异值分解,从上述的有关论述来看,A矩阵是十分稀疏的。
5、除此之外,在这个较大的空间之中,一些文档似乎通过共享共同的单词而更加紧密。下面又提到,但是这些文档可能彼此之间在语义上却并不相关;与此同时,许多因为没有共享任何术语而显得很疏远的文档,实际上关系可能会更紧密。因为相同的概念可能由许多不同的单词来表示,而这些单词是有歧义的。
6、LSA则减小了这个较大的空间,并且有希望捕捉到文本之间的关系。为了实现这个效果,LSA进行对词-文档矩阵的奇异值分解,矩阵的奇异值分解是下面三个矩阵运算的产物
其中u和v表示左右奇异矩阵。σ表示为奇异值的对角矩阵,σ中的对角元素按照大小进行排序。因此,这些矩阵可以通过在σ中设置一个最小值k为0来对这些矩阵进行简化。与σ值对应的T和D列被设置为0,将被删除。
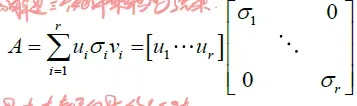
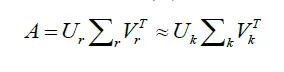
基于LSA的分类,根据SVD算法,减小空间的模型相似于原始矩阵的模型。因此,所有适用于向量空间模型的分类算法也能够适用于LSA分类模型。许多整合了LSA与传统算法分类方法,比如序列分类算法、朴素贝叶斯、KNN、支持向量机,被提出来提升短文本分类的精确度。
LSA的优点
1、减少特征的分散以及噪声。根据LSA,提取K维的语义空间。那么这写语义空间不仅保留了原始向量矩阵大部分信息,同时减少了维度。LDA通过摒弃一些无用的特征来消除噪声。
2、由上述可得,LSA可以有效的处理大规模的短文本数据集。
3、增强语义联系。在具有较高语义表达的相对低维的空间中,分类的性能将通过相似性分析得到提高。
vectors can describe the semantic relationship between terms and documents
5、灵活性。
LSA的缺点
1、由于减小维度而丢失了结构信息。
2、SVD没有严格的数学意义。此外,在高维空间中进行计算的时间和空间复杂度更高
3、文档的意义由向量的线性求和表示,在信息提取阶段忽略了单词的语法信息。
4、LSA只能处理可见变量。然而,隐喻、类比等含义是无法计算的
文章出处登录后可见!