论文:
Extractive Dialogue Summarization Without
Annotation Based on Distantly Supervised Machine
Reading Comprehension in Customer Service
论文链接:
https://ieeexplore.ieee.org/document/9645319/authors#authors
主要动机和思路:
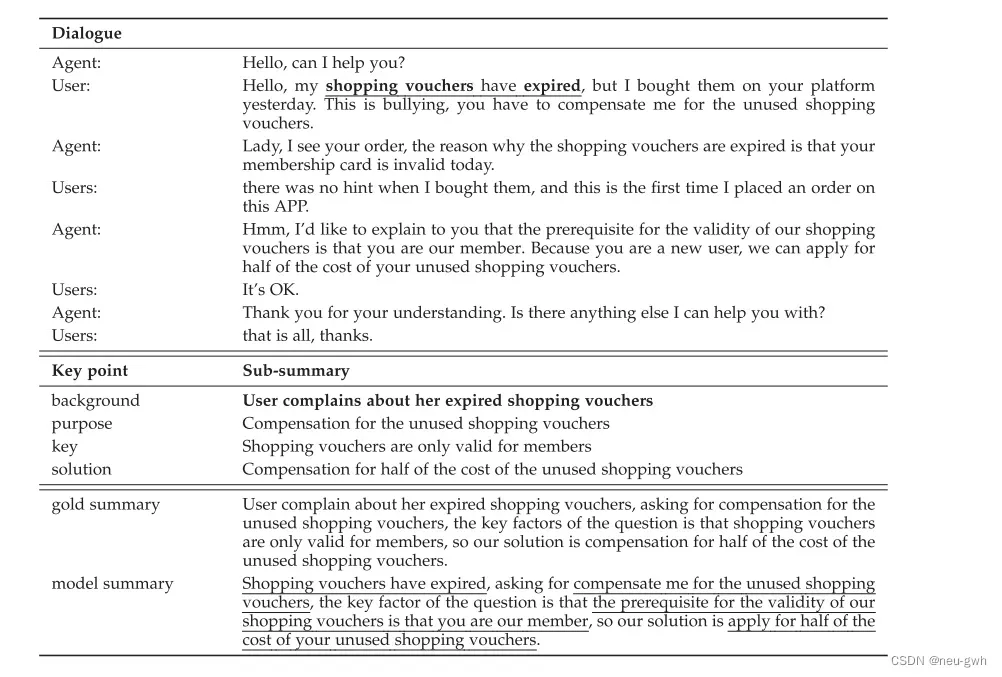
这篇文章关注抽取式对话摘要,客服对话摘要中可能存在很多的key points,比如下面的例子,这段对话摘要中有四个要点,现有的抽取摘要方法无法全面的捕获这些要点,同时现有的抽取式方法通常以句子为抽取单位,可能会引入很多的噪声。本文设计了一种基于对话阅读理解的抽取式摘要方法。这篇文章自己收集了一个中文的客服对话摘要的数据集,并标注出了对话中的key points,及每个key point对应的子摘要。对于每个key point,预定义一个问题,通过对话阅读理解模型给
对话中的每个token打分,然后再用一个基于密度的方法根据每个token的得分选出连续的片段作为这个key point的子摘要,将所有key point的子摘要拼接在一起得到最终的摘要。同时本文还额外引入了角色相关的信息,辅助客服对话摘要任务的生成。
方法:
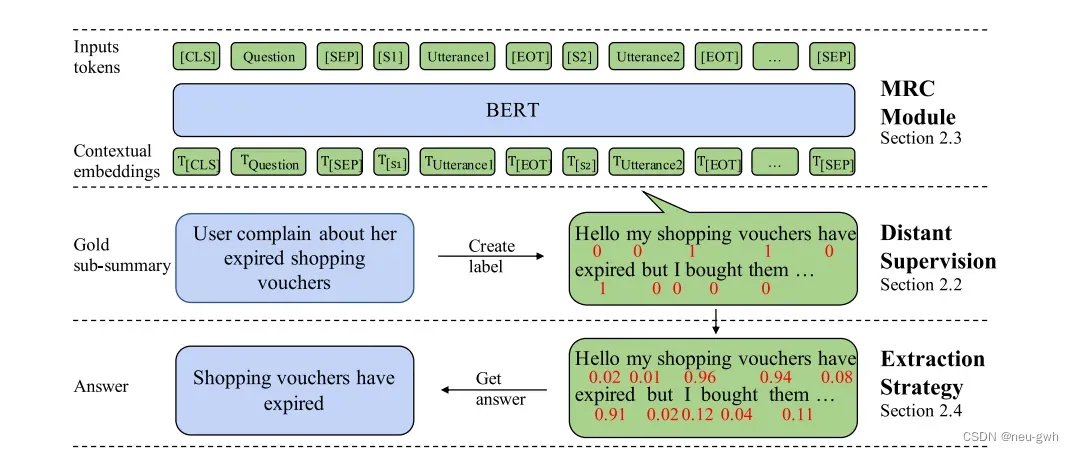
模型总体架构如图所示,对话阅读理解模块将预定义的key point相关的问题和对话拼接在一起,训练BERT模型,对每个token打分。
因为问题并不是直接来自于对话,所以很难直接将问题和对话中的对应token关联起来,这里利用了参考摘要。如果token出现在一个keypoint的参考子摘要中,定义为gold token,标签为1,否则标签为0。利用这样产生的标签训练对MRC模型,预测每个token出现在这个key point的对应子摘要中的概率。输入包含两部分,预定义的问题和对话,中间用特殊符号[SEP]拼接在一起,每句对话之间也用[EOT]特殊符号分隔开,每句对话前面也添加了一个角色标签[S],用来表示不同角色的交替。输入送入BERT模型中,再经过一个线性层,得到每个token的预测概率
除此之外,本文还设计了一个新的辅助任务,预测哪个角色是问题的solver,对应的公式如下。哪个一个说话人的句子中包含更多的gold token,这个说话人就是solver,,标签为1,否则标签为0
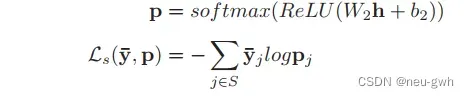
通过MRC模块得到了每个token的预测概率,但是最终希望得到的是一些连续的对话片段,而不是一些单纯的tokens,这里设计了一个基于密度的方法,对于每个可能的片段,计算下面的得分
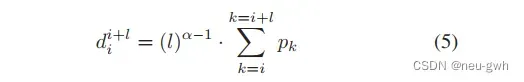
这里的l代表片段长度,a是超参数,在0到1之间。最后选择最大的片段作为对应key point的子摘要。对于所有的key point重复这一系列过程,得到了整个摘要。
文章出处登录后可见!