A Spatial-Temporal Attention-Based Method and a New Dataset for Remote Sensing Image Change Detection
论文地址:https://www.mdpi.com/2072-4292/12/10/1662
项目代码:https://gitcode.net/mirrors/justchenhao/STANet?utm_source=csdn_github_accelerator
发表时间:2020

遥感图像变化检测(CD)可以识别双时间图像之间的显著变化。给定在不同时间拍摄的两幅共配准图像,但是,光照变化和配准偏移(拍摄角度变化)超过了真实物体的变化。探索不同时空像素之间的关系可以提高CD方法的性能。在我们的工作中,我们提出了一种新的基于siamese-based的时空注意神经网络。与以往单独编码双时间图像的方法,而不涉及任何有用的时空依赖性的方法不同,我们设计了一种CD自我注意机制来模拟时空关系。我们在特征提取过程中集成了一个新的CD自注意模块。我们的自注意模块计算任意两个像素在不同时间和位置之间的注意权重,并使用它们来产生更有区别的特征。考虑到目标可能具有不同的尺度,我们将图像划分为多尺度的子区域,并在每个子区域中引入自注意。通过这种方式,我们可以捕获不同尺度上的时空依赖关系,从而生成更好的表示来适应不同大小的对象。我们还引入了一个CD数据集LEVIR-CD,它比该领域的其他公共数据集大两个数量级。LEVIR-CD由一组大型的双时间谷歌地球图像组成,其中有637对图像对(1024×1024)和超过31 k个独立标记的变化实例。我们提出的注意模块将我们的基线模型的f1的分数从83.9提高到87.3,并具有可接受的计算开销。在一个公共遥感图像CD数据集上的实验结果表明,我们的方法优于其他几种最先进的方法。
关键创新:设计了两种自我注意模块,基本的时空注意模块(BAM)和金字塔式的时空注意模块(PAM)。BAM学习捕捉任意两个位置之间的时空依赖性(注意权重),并通过在时空中所有位置上的特征的加权和来计算每个位置的响应。PAM将BAM嵌入到一个金字塔结构中,以生成多尺度的注意表征。
1、主要贡献
- 提出了一个新的框架;即基于遥感图像CD的时空注意神经网络(STANet)。以往的方法是独立对双时图像进行编码,而在我们的框架中,我们设计了一种CD自注意机制,充分利用时空关系获得光照不变和错配准鲁棒特征。
- 提出了两个注意模块:一个基本的时空注意模块(BAM)和一个金字塔式的时空注意模块(PAM)。BAM利用全局时空关系获得更好的鉴别特征。此外,PAM聚集了多尺度注意力表示以获得物体的细节。这些模块可以很容易地与现有的孪生网络进行集成
- 进行大量的实验证实了我们提出的注意模块的有效性。我们的注意模块可以很好地减轻双时间图像中由配准错误引起的误检测,并且对颜色和尺度变化具有鲁棒性。我们还可视化了注意图,以更好地理解自我注意机制。
- 引入了一个新的数据集LEVIR-CD(LEVIR构建变化检测数据集),它比现有的数据集大两个数量级。请注意,LEVIR是作者的实验室的名称。由于缺乏一个公共的、大规模的CD数据集,新的数据集应该会推动遥感图像CD的研究。数据集在 https://justchenhao.github.io/LEVIR/
2、网络结构与实现代码
网络整体结构如下图所示,包含:特征提取器、注意力模块、度量模块。
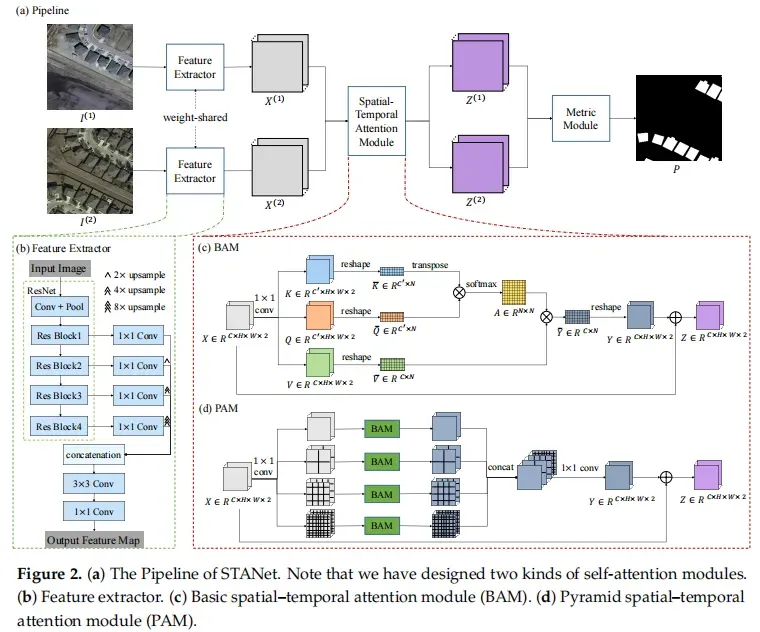
其实现代码如下,其中extract为特征提取器,attend为注意力模块,conv_out即为度量模块,完整代码可以参考https://gitee.com/Geoyee/PaddleRS/blob/develop/paddlers/rs_models/cd/stanet.py
class STANet(nn.Layer):
def __init__(self, in_channels, num_classes, att_type='BAM', ds_factor=1):
super(STANet, self).__init__()
WIDTH = 64
self.extract = build_feat_extractor(in_ch=in_channels, width=WIDTH)
self.attend = build_sta_module(
in_ch=WIDTH, att_type=att_type, ds=ds_factor)
self.conv_out = nn.Sequential(
Conv3x3(
WIDTH, WIDTH, norm=True, act=True),
Conv3x3(WIDTH, num_classes))
self.init_weight()
def forward(self, t1, t2):
f1 = self.extract(t1)
f2 = self.extract(t2)
f1, f2 = self.attend(f1, f2)
y = paddle.abs(f1 - f2)
y = F.interpolate(
y, size=paddle.shape(t1)[2:], mode='bilinear', align_corners=True)
pred = self.conv_out(y)
return [pred]
2.1 特征提取器
为常规的语义分割模型,与pspnet类似,这里是孪生部分。将高级语义信息和低级空间信息融合,生成更精细的表示;同时,为了使高级语义与低级特征之间的协调,在效率与准确率之间的平衡,将C1设置为96|C2设置为256|C3设置为64(使不同尺度下的feature map channel不一样)。
其实现代码如下,包含了Backbone和Decoder,主要是将输入图像编码到特征空间
class Backbone(nn.Layer, KaimingInitMixin):
def __init__(self, in_ch, arch, pretrained=True, strides=(2, 1, 2, 2, 2)):
super(Backbone, self).__init__()
if arch == 'resnet18':
self.resnet = resnet.resnet18(
pretrained=pretrained,
strides=strides,
norm_layer=get_norm_layer())
elif arch == 'resnet34':
self.resnet = resnet.resnet34(
pretrained=pretrained,
strides=strides,
norm_layer=get_norm_layer())
elif arch == 'resnet50':
self.resnet = resnet.resnet50(
pretrained=pretrained,
strides=strides,
norm_layer=get_norm_layer())
else:
raise ValueError
self._trim_resnet()
if in_ch != 3:
self.resnet.conv1 = nn.Conv2D(
in_ch,
64,
kernel_size=7,
stride=strides[0],
padding=3,
bias_attr=False)
if not pretrained:
self.init_weight()
def forward(self, x):
x = self.resnet.conv1(x)
x = self.resnet.bn1(x)
x = self.resnet.relu(x)
x = self.resnet.maxpool(x)
x1 = self.resnet.layer1(x)
x2 = self.resnet.layer2(x1)
x3 = self.resnet.layer3(x2)
x4 = self.resnet.layer4(x3)
return x1, x2, x3, x4
def _trim_resnet(self):
self.resnet.avgpool = Identity()
self.resnet.fc = Identity()
class Decoder(nn.Layer, KaimingInitMixin):
def __init__(self, f_ch):
super(Decoder, self).__init__()
self.dr1 = Conv1x1(64, 96, norm=True, act=True)
self.dr2 = Conv1x1(128, 96, norm=True, act=True)
self.dr3 = Conv1x1(256, 96, norm=True, act=True)
self.dr4 = Conv1x1(512, 96, norm=True, act=True)
self.conv_out = nn.Sequential(
Conv3x3(
384, 256, norm=True, act=True),
nn.Dropout(0.5),
Conv1x1(
256, f_ch, norm=True, act=True))
self.init_weight()
def forward(self, feats):
f1 = self.dr1(feats[0])
f2 = self.dr2(feats[1])
f3 = self.dr3(feats[2])
f4 = self.dr4(feats[3])
f2 = F.interpolate(
f2, size=paddle.shape(f1)[2:], mode='bilinear', align_corners=True)
f3 = F.interpolate(
f3, size=paddle.shape(f1)[2:], mode='bilinear', align_corners=True)
f4 = F.interpolate(
f4, size=paddle.shape(f1)[2:], mode='bilinear', align_corners=True)
x = paddle.concat([f1, f2, f3, f4], axis=1)
y = self.conv_out(x)
return y
2.2 时空注意力模块
为作者设计的BAM、PAM模块,用于提取两个影像的变化特性(影像变化的时空特征)。在代码层次上被封装为Attention对象,参数att即为PAM模块。可以看到,Attention不是孪生的其联立了特征,然后在输出阶段又进行了split操作。
class Attention(nn.Layer):
def __init__(self, att):
super(Attention, self).__init__()
self.att = att
def forward(self, x1, x2):
x = paddle.stack([x1, x2], axis=-1)
y = self.att(x)
return y[..., 0], y[..., 1]
Basic spatial–temporal attention module
BAM模块,为普通的spatial–attention实现,attention的输出是与原始特征图做加。这里或可修改为其他更加节省内存的attention机制,如Criss-Cross Attention(先进行height的self-attention,在进行width的self-attention,其中KV的输出是不修改的)、Interlaced Sparse Self-Attention(先计算长空间的相关性,在计算短空间的相关性,本质就是对数据进行reshape操)、Efficient Attention(调整QKV计算中KV的优先级,将矩阵whwh减为cc)、spatial-reduction attention(将WH中的部分信息已入chanel中,减小wh*wh的大小[QK的大小])
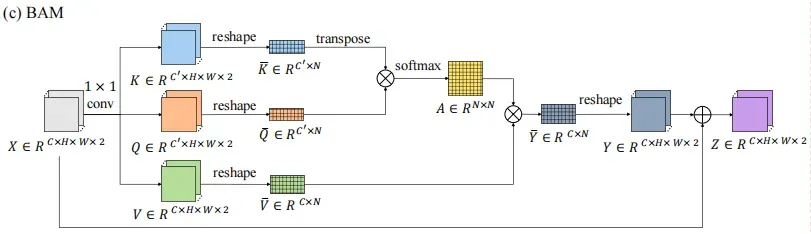
其实现代码如下
class BAM(nn.Layer):
def __init__(self, in_ch, ds):
super(BAM, self).__init__()
self.ds = ds
self.pool = nn.AvgPool2D(self.ds)
self.val_ch = in_ch
self.key_ch = in_ch // 8
self.conv_q = Conv1x1(in_ch, self.key_ch)
self.conv_k = Conv1x1(in_ch, self.key_ch)
self.conv_v = Conv1x1(in_ch, self.val_ch)
self.softmax = nn.Softmax(axis=-1)
def forward(self, x):
x = x.flatten(-2)
x_rs = self.pool(x)
b, c, h, w = paddle.shape(x_rs)
query = self.conv_q(x_rs).reshape((b, -1, h * w)).transpose((0, 2, 1))
key = self.conv_k(x_rs).reshape((b, -1, h * w))
energy = paddle.bmm(query, key)
energy = (self.key_ch**(-0.5)) * energy
attention = self.softmax(energy)
value = self.conv_v(x_rs).reshape((b, -1, w * h))
out = paddle.bmm(value, attention.transpose((0, 2, 1)))
out = out.reshape((b, c, h, w))
out = F.interpolate(out, scale_factor=self.ds)
out = out + x
return out.reshape(tuple(out.shape[:-1]) + (out.shape[-1] // 2, 2))
Pyramid spatial–temporal attention module:
PAM模块,stanet中对PSPNet的第二次借鉴,通过聚合多尺度的BAM模块来增强识别精细细节的能力。结合了不同尺度的时空注意语境,生成多尺度的注意特征。PAM有四个分支;每个分支将特征张量平均划分为一定尺度上的几个子区域。在每个分支中,PAM将BAM应用于每个子区域中的像素,以获得在该尺度上的局部注意力表示。然后,通过聚合四个分支的输出张量来生成多尺度注意表示。我们称这种结构为金字塔注意模块,因为图像空间中的每个像素都涉及到不同scale子区域的自注意机制
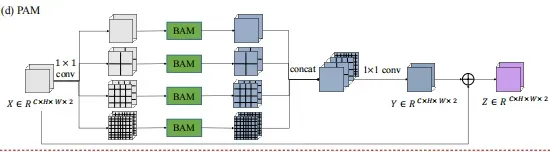
其实现代码如下,一个PAMBlock表示一个支路,PAM内实现了1, 2, 4, 8四种下采样的支路
class PAMBlock(nn.Layer):
def __init__(self, in_ch, scale=1, ds=1):
super(PAMBlock, self).__init__()
self.scale = scale
self.ds = ds
self.pool = nn.AvgPool2D(self.ds)
self.val_ch = in_ch
self.key_ch = in_ch // 8
self.conv_q = Conv1x1(in_ch, self.key_ch, norm=True)
self.conv_k = Conv1x1(in_ch, self.key_ch, norm=True)
self.conv_v = Conv1x1(in_ch, self.val_ch)
def forward(self, x):
x_rs = self.pool(x)
# Get query, key, and value.
query = self.conv_q(x_rs)
key = self.conv_k(x_rs)
value = self.conv_v(x_rs)
# Split the whole image into subregions.
b, c, h, w = x_rs.shape
query = self._split_subregions(query)
key = self._split_subregions(key)
value = self._split_subregions(value)
# Perform subregion-wise attention.
out = self._attend(query, key, value)
# Stack subregions to reconstruct the whole image.
out = self._recons_whole(out, b, c, h, w)
out = F.interpolate(out, scale_factor=self.ds)
return out
def _attend(self, query, key, value):
energy = paddle.bmm(query.transpose((0, 2, 1)),
key) # Batched matrix multiplication
energy = (self.key_ch**(-0.5)) * energy
attention = F.softmax(energy, axis=-1)
out = paddle.bmm(value, attention.transpose((0, 2, 1)))
return out
def _split_subregions(self, x):
b, c, h, w = x.shape
assert h % self.scale == 0 and w % self.scale == 0
x = x.reshape(
(b, c, self.scale, h // self.scale, self.scale, w // self.scale))
x = x.transpose((0, 2, 4, 1, 3, 5))
x = x.reshape((b * self.scale * self.scale, c, -1))
return x
def _recons_whole(self, x, b, c, h, w):
x = x.reshape(
(b, self.scale, self.scale, c, h // self.scale, w // self.scale))
x = x.transpose((0, 3, 1, 4, 2, 5)).reshape((b, c, h, w))
return x
class PAM(nn.Layer):
def __init__(self, in_ch, ds, scales=(1, 2, 4, 8)):
super(PAM, self).__init__()
self.stages = nn.LayerList(
[PAMBlock(
in_ch, scale=s, ds=ds) for s in scales])
self.conv_out = Conv1x1(in_ch * len(scales), in_ch, bias=False)
def forward(self, x):
x = x.flatten(-2)
res = [stage(x) for stage in self.stages]
out = self.conv_out(paddle.concat(res, axis=1))
return out.reshape(tuple(out.shape[:-1]) + (out.shape[-1] // 2, 2))
2.3 度量模块
采用了一个对比损失来鼓励使每个无变化像素对的距离变小,使每个嵌入空间中的有变化像素间的距离变大。
首先通过双线性插值将每个特征图的大小调整为与输入的双时图像相同的大小。然后,我们按像素级计算调整后的特征图之间的欧氏距离,生成距离图D∈RH0×W0,其中H0、W0分别为输入图像的高度和宽度。在训练阶段,采用对比损失来学习网络的参数,这样的邻居被拉在一起,非邻居被推开。
其代码部分如下
self.conv_out = nn.Sequential(
Conv3x3(
WIDTH, WIDTH, norm=True, act=True),
Conv3x3(WIDTH, num_classes))
3、 loss设计
为修改过的triplet loss,主要是考虑分类不平衡(在变化检测中变化像素只占很小的一部分),具体形式如下。其中为标签[1表示变化,0表示无变化],
为x1与x2的距离图。公式的第一部分为正样本loss,
为正样本loss系数,
为负样本loss系数,m被设置为2(意味着指定中负样本的最大距离为2)
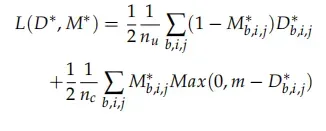
import torch.nn as nn
import torch
class BCL(nn.Module):
"""
batch-balanced contrastive loss
no-change,1
change,-1
"""
def __init__(self, margin=2.0):
super(BCL, self).__init__()
self.margin = margin
def forward(self, distance, label):
label[label==255] = 1
mask = (label != 255).float()
distance = distance * mask
pos_num = torch.sum((label==1).float())+0.0001
neg_num = torch.sum((label==-1).float())+0.0001
loss_1 = torch.sum((1+label) / 2 * torch.pow(distance, 2)) /pos_num
loss_2 = torch.sum((1-label) / 2 * mask *
torch.pow(torch.clamp(self.margin - distance, min=0.0), 2)
) / neg_num
loss = loss_1 + loss_2
return loss
4、LEVIR-CD数据集
4.1 数据集采集
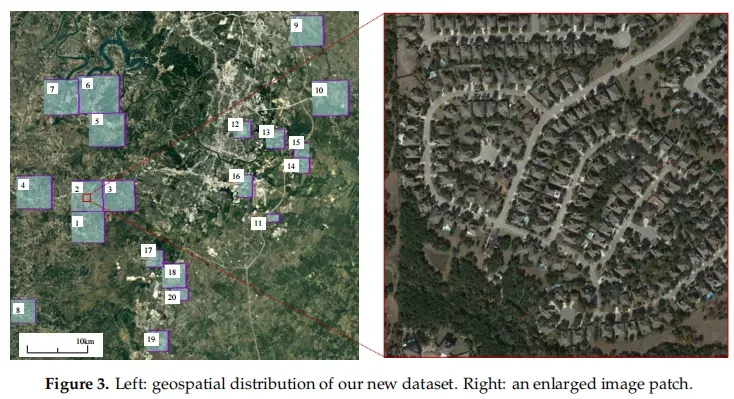
通过谷歌Earth API收集了637对非常高分辨率(VHR,0.5m/像素)的谷歌地球(Earth,GE)图像patch对,大小为1024×1024像素。这些图像来自美国德克萨斯州几个城市的20个不同地区,包括奥斯汀、莱克威、蜂洞、布达、凯尔、马诺、普拉格维莱克斯、滴水泉等。图3显示了我们的新数据集和一个放大的图像补丁的地理空间分布。每个区域都有不同的大小,并包含不同数量的图像补丁。每个样本都由一个标注员进行标注,然后由另一个标注员进行双重检查,以生成高质量的标注。
4.2 数据集变化信息
表1列出了每个区域的面积和补丁数量。我们的图像数据的捕获时间从2002年到2018年有所变化。不同区域的图像可以在不同的时间拍摄。我们希望在我们的新数据集中引入由季节变化和光照变化引起的变化,这可能有助于开发有效的方法,以减轻无关变化对真实变化的影响。表1列出了每个区域中每个图像的具体捕获时间。这些图像的时间跨度为5∼14年。
4.3 与其他数据集对比
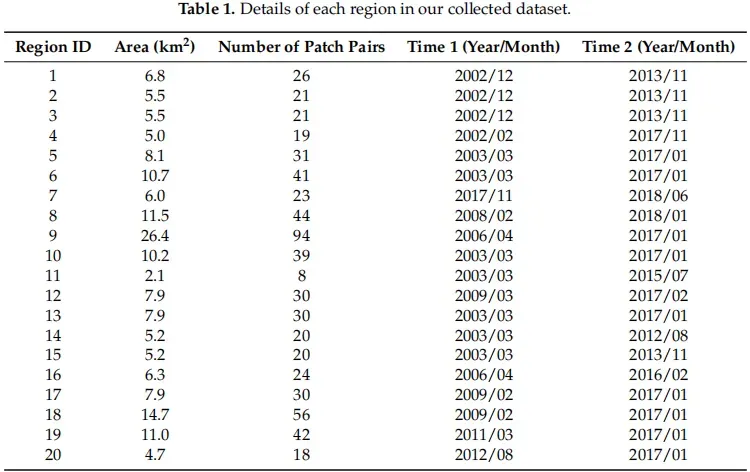
完整的LEVIR-CD共包含31,333个独立的变更建筑。平均而言,每对图像中大约有50个发生变化的建筑。值得注意的是,大多数的变化都是由于新建筑的建设。每个变化区域的平均大小约为987个像素。表2提供了我们的数据集的摘要。
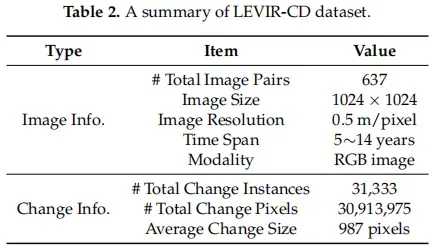
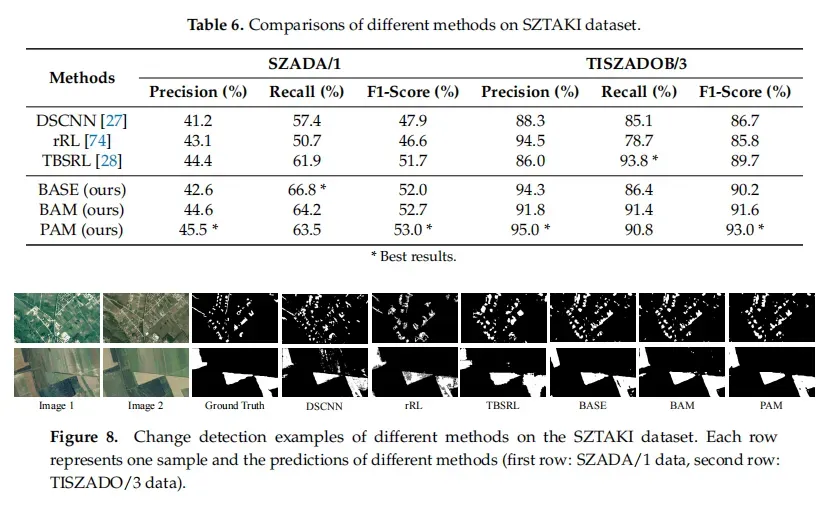
SZTAKI改变基准集(SZTAKI)[66]是一个二进制CD数据集,包含13对光学航空图像对;每个是952×640像素,分辨率约为1.5m/像素。数据集按区域分为三组;即Szada、Tiszadob和存档;它们分别包含7、5和1对图像对。该数据集考虑了以下变化:新的建筑建造区域、建筑操作、种植森林、新的耕地和建筑完成前的地基工作。
Onera卫星变化检测数据集(OSCD)[67]是为二元CD设计的,其中包含24对多光谱卫星图像对。每幅图像的大小约为600×600,分辨率为10米。该数据集主要关注城市地区的变化(如城市增长和城市衰退),而忽略了自然变化。
航空图像变化检测数据集(AICD)[68]是一个模拟生成的二进制CD数据集,包含100个模拟场景,每个场景从5个视点捕获,总共得到500张图像。每个图像都添加了一种人工改变目标(例如,建筑物、树木或浮雕)来生成图像对。因此,在每个图像对中都有一个更改实例。
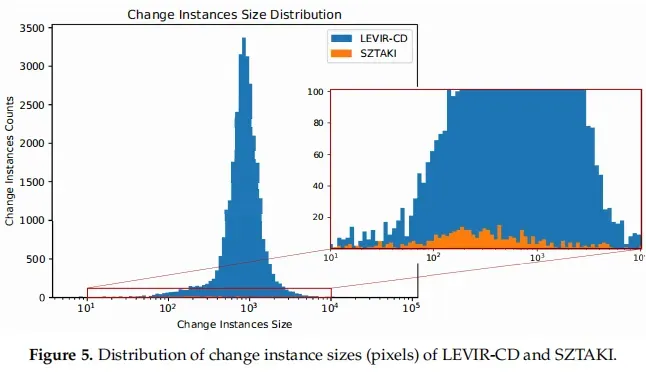
ZTAKI是应用最广泛的公共遥感图像CD数据集,帮助推动了[27,28,69]的许多进展。去年推出的OSCD也推动了一些关于[67,69]的研究。AICD还帮助开发了CD算法[70]。然而,这些现有的数据集有很多缺点。首先,所有这些数据集都没有足够的数据来支持大多数基于深度学习的CD算法,当数据量需要模型参数的数量时,CD算法容易出现过拟合问题。其次,这些CD数据集的图像分辨率较低,模糊了变化目标的轮廓,给已标注的图像带来了模糊性。我们计算了这些数据集的变化实例的数量和变化像素,这表明我们的数据集比现有的数据集大1∼2个数量级。如图5所示,我们创建了一个包含LEVIR-CD和SZTAKI的所有变化实例的大小的直方图。我们可以观察到,我们的数据集的变化实例大小的范围比SZTAKI更宽,并且LEVIR-CD包含的变化实例比SZTAKI多得多。
5、实验效果
5.1 评价指标
将精度(Pr)、召回率(Re)和F1分数(F1)作为评价指标,具体计算方式如下(这些指标计算出来的结果明显比iou要高一些,因为iou的分母是并集)
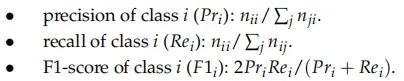
5.2 实施细节
LEVIR-CD dataset
70%的样本用于训练,10%用于验证,20%用于测试。由于GPU的内存限制,我们将每个样本裁剪为16个大小为256×256的小斑块。
SZTAKI dataset
使用与其他比较方法相同的训练-测试分割准则。该测试集由从每个样本的左上角裁剪出的784×448大小的补丁组成。每个样本的剩余部分被重叠地裁剪成113×113大小的小斑块作为训练数据。
模型在ImageNet预训练的ResNet-18 [36]模型上进行了微调,初始学习率为10−3。在前100个时代保持相同的学习速率,并在剩下的100个阶段将其线性衰减到0。我们使用Adam优化器,批量大小为4,β1为0.5,β2为0.99。我们应用随机翻转和随机旋转(−15◦∼15◦)来进行数据增强。
5.3 消融实验
对BAM、PAM模块的效果进行测试,相对于base网络(fcn网络)有所提升,PAM模块下提升最佳
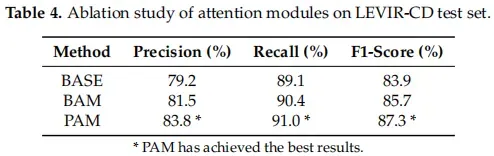
涨点分析
使用BAM后,可以看到对于细节上有所提升(在小面积误检漏检上有改进);而改用PAM后在宏观上有提升(对大面积误检漏检有改善,故涨点最多)

偏差消除
可以看到使用BAM或PAM模块后,对于像素偏差所导致的误检均有良好的消除效果。

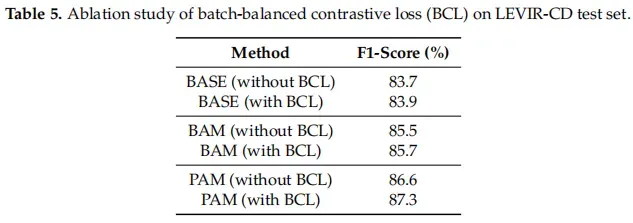
BCL loss对比,与原始loss相比使用BCL loss有一定提升效果。
 ,
,
5.4 对比实验
DSCNN,一个孪生的FCN模型,并以端到端方式对CD使用加权对比损失。FCN孪生部分由由五个卷积层组成,没有池化层和完全连接层。在测试阶段,他们利用k-nn改进由孪生FCN生成的初始变化图;
rRL,一个利用训练样本之间的邻域关系来增强变化特征的整体可分性。然而,提取的图像特征是手工制作的,缺乏鉴别能力;
TBSRL,使用Deeplabv2 [46]来提取鲁棒特征,并设计了一个triple loss来学习所选的三元组中的语义关系。然而,只有三元中的元素受到语义关系的约束,缺乏对全局空间信息的探索。
6、探索与结论
6.1 讨论
feature map分析
可以看到,通过孪生网络所提取的feature map,准确的识别出来图像中疑似建筑的区域(在某些比赛中,为了提升效果会显性的进行语义分割训练)。这表明,PAM模块有效的提取了时空特性(但单一时像标注下,识别出了不同时像输入数据中的建筑目标)

尺度分析
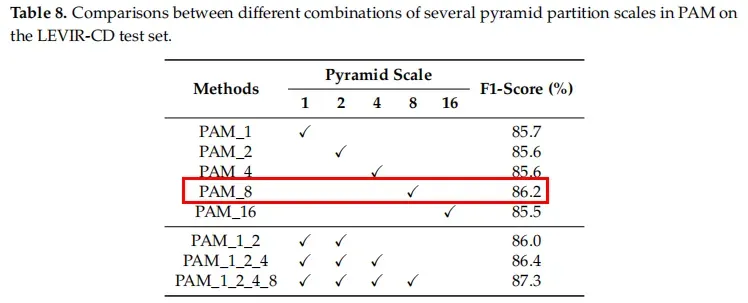
对于BAM模块,它只针对图像中的细节部分,可以看到分辨率越低效果越差(8倍尺度下效果好是因为当前尺度下的feature map输出响应中,一个网格对应着原图32×32的区域,刚好与大部分变化实例的size相同)
对于PAM模块,它结合图像的多尺度信息,可以针对宏观上的错误进行修正,可以看到表中PAM_1_2_4_8(尺度阅读效果越佳)
6.2 结论
1、消融实验证实了提出的时空注意模块(BAM和PAM)的有效性,该模块捕获了长期的时空依赖性,以学习更好的表征(可以在数据的变化标签中学习到原始建筑标签的特征);
2、所提出的注意力模块可以插入任何基于Siamese-FCN的CD算法,以引入性能改进;
3、BAM用于修复细节,PAM结合多尺度信息可以修复宏观上的误检信息(图像配准偏差所导致的误检);
文章出处登录后可见!