目录
一、基础知识
在理解各种损失函数的选择原理之前,先回顾一下损失函数、模型训练、训练方法的相关基本概念
损失函数(Loss Function):用来估量模型的预测值 f(x) 与真实值 y 的偏离程度,以下是选择损失函数的基本要求与高级要求:
- 基本要求:用来衡量模型输出分布和样本标签分布之间的接近程度,
- 高级要求:在样本分布不均匀地情况下,精确地描述模型输出分布和样本标签之间的接近程度
模型训练(Training):训练的过程实质是优化(最小化)损失函数,让 f(x) 与 y 尽量接近。实际上是模型参数拟合的过程(比如使用最小二乘法、梯度下降法求解回归模型中的参数),也可以理解为模型求解的过程(比如使用最大期望法求解概率模型中的参数)。和其他数学建模中的求解参数过程本质上没太大区别。
常用训练方法:梯度下降算法寻找函数最小值
一般的损失函数的都是直接计算 batch 的数据,因此返回的 loss 结果都是维度为 batch_size的向量, 值得注意的是, pytorch中很多的损失函数都有 size_average 和 reduce 两个布尔类型的参数,具体内容为:
- 如果 reduce = False,那么 size_average 参数失效,直接返回向量形式的 loss;
- 如果 reduce = True,那么 loss 返回的是标量
- 如果 size_average = True,返回 loss.mean();
- 如果 size_average = True,返回 loss.sum();
为了更好地理解损失函数的定义以下代码部分将这两个参数均设置为False
一般来说,工程实践中常用的损失函数大致可以分成两大应用情况:回归(Regression)和分类(Classification)
二、分类
(1)二分类交叉熵损失函数(binary_crossentropy)
inary_crossentropy损失函数的公式如下(一般搭配sigmoid激活函数使用):
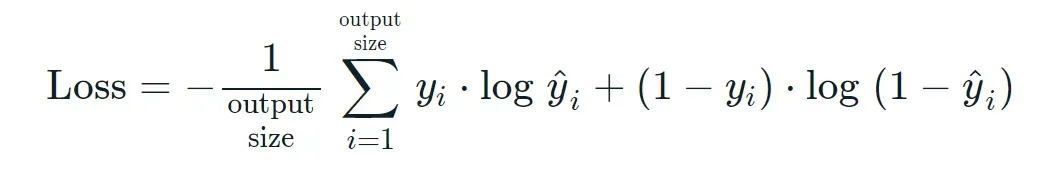
根据公式我们可以发现,i∈[1,output_size] 中每个i是相互独立的,互不干扰,因此它一般用于多标签分类(yolov3的分类损失函数就是用这个),比如说我们有标签 ‘人’,‘男人’, ‘女人’ ,如果使用categorical_crossentropy,由于它的数学公式含义,标签只能是其中一个,而binary_crossentropy各个i是相互独立的,意味着是有可能出现一下这种情况:(举例)
‘人’ 标签的概率是0.9, ‘男人’ 标签概率是0.6,‘女人’ 标签概率是0.3。
那么我们有足够的说服力断定他是 ‘人’,并且很可能是 ‘男人’。
(2)categorical_crossentropy损失函数
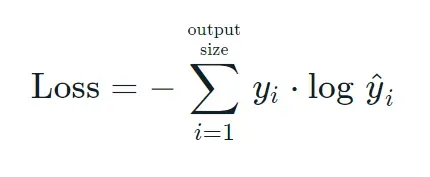
根据公式我们可以发现,因为yi,要么是0,要么是1。而当yi等于0时,结果就是0,当且仅当yi等于1时,才会有结果。也就是说categorical_crossentropy只专注与一个结果,因而它一般配合softmax做单标签分类。
如果是分类编码(one-hot编码),则使用categorical_crossentropy。one-hot编码就是在标签向量化的时候,每个标签都是一个N维的向量(N由自己确定),其中这个向量只有一个值为1,其余的都为0。也就是将整数索引i转换为长度为N的二进制向量,这个向量只有第i个元素是1,其余的都是0
(3)sparse_categorical_crossentropy
在开发文档中有例程
import tensorflow as tf
import numpy as np
y_true = tf.constant([1, 2])
y_pred = tf.constant([[0.05, 0.95, 0], [0.1, 0.8, 0.1]])
loss = tf.reduce_mean(tf.keras.losses.sparse_categorical_crossentropy(y_true, y_pred))
scce = tf.keras.losses.SparseCategoricalCrossentropy()
print(loss.numpy())
print(scce(y_true, y_pred).numpy())其中有两个基准值1,2说明一共有两类且分别为第一类,第二类,又有两个预测数组[0.05, 0.95, 0], [0.1, 0.8, 0.1]。表明在预测第一个的时候,属于第一类的概率为0.05,属于第二类的概率为0.95,既不属于第一类也不属于第二类的概率为0。同理,在预测第二个的时候,属于第一类的概率为0.1,属于第二类的概率为0.8,既不属于第一类也不属于第二类的概率为0.1。
所以在使用这个函数时,需要如下组织y_true和y_pred:
假如分类时存在三类:其中y_true为:
[1, 2,1,3]因为sparse_categorical_crossentropy接受的是离散值,且y_true出现了1,2,3 所以共三类,共四个需要预测。y_pred的组织应该如下:
[0.05, 0.95, 0,0],
[0.1, 0.8, 0.1,0],
[0.1, 0.8, 0.1,0],
[0.1, 0.8, 0.1,0]意思为,对于第1个预测:属于第一类,第二类,第三类的概率分别为0.05,0.95,0;不属于任何一类的概率为0。
对于第2,3,4个的预测依次类推。
其中这样的组织方式,适用于分类任务,也适用于语义分割任务。因为语义分割任务就是像素点所属类别的预测。
再比如:
y_true = tf.constant([1, 2, 3, 4])
y_pred = tf.constant([
[0.05, 0.95, 0, 0, 0],
[0.1, 0.8, 0.1, 0, 0],
[0.1, 0.8, 0.1, 0, 0],
[0.1, 0.8, 0.1, 0, 0]
})注意,假如y_true:[1, 2, 4, 4],还是看做三类:
y_pred:
[0.05, 0.95, 0,0],
[0.1, 0.8, 0.1,0],
[0.1, 0.8, 0.1,0],
[0.1, 0.8, 0.1,0]categorical_crossentropy与sparse_categorical_crossentropy的区别:
sparse_categorical_crossentropy跟categorical_crossentropy的区别是其标签不是one-hot,而是integer。比如在categorical_crossentropy是[1,0,0],在sparse_categorical_crossentropy中是3.
(4)平衡交叉熵函数(balanced cross entropy)
交叉熵损失函数:

样本不均衡问题:

其中m为正样本个数,n为负样本个数,N为样本总数,m+n=N。当样本分布失衡时,在损失函数L的分布也会发生倾斜,如m<<n时,负样本就会在损失函数占据主导地位。由于损失函数的倾斜,模型训练过程中会倾向于样本多的类别,造成模型对少样本类别的性能较差。

(5)focal loss
focal loss是最初由何恺明提出的,最初用于图像领域解决数据不平衡造成的模型性能问题。本文试图从交叉熵损失函数出发,分析数据不平衡问题,focal loss与交叉熵损失函数的对比,给出focal loss有效性的解释。

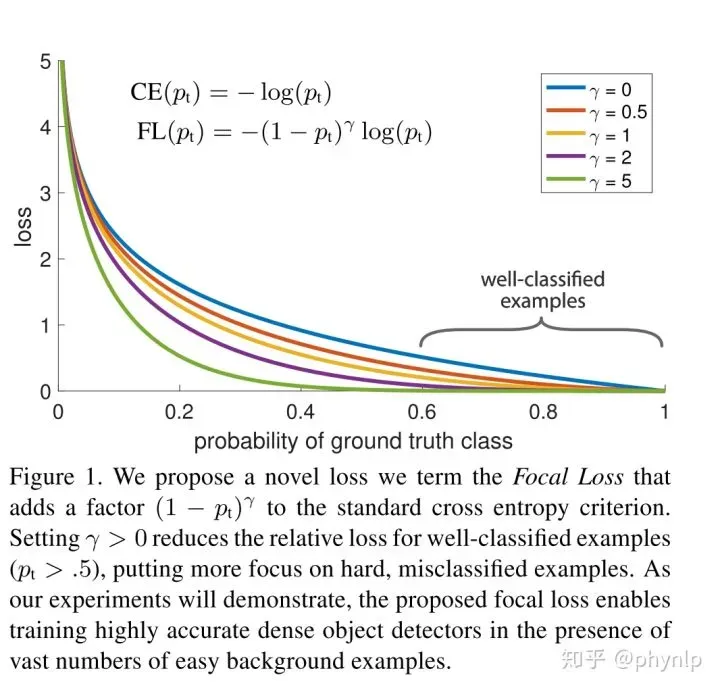
focal loss VS balanced cross entropy
focal loss相比balanced cross entropy而言,二者都是试图解决样本不平衡带来的模型训练问题,后者从样本分布角度对损失函数添加权重因子,前者从样本分类难易程度出发,使loss聚焦于难分样本。
focal loss 为什么有效
focal loss从样本难易分类角度出发,解决样本非平衡带来的模型训练问题。
相信很多人会在这里有一个疑问,样本难易分类角度怎么能够解决样本非平衡的问题,直觉上来讲样本非平衡造成的问题就是样本数少的类别分类难度较高。因此从样本难易分类角度出发,使得loss聚焦于难分样本,解决了样本少的类别分类准确率不高的问题,当然难分样本不限于样本少的类别,也就是focal loss不仅仅解决了样本非平衡的问题,同样有助于模型的整体性能提高。
要想使模型训练过程中聚焦难分类样本,仅仅使得Loss倾向于难分类样本还不够,因为训练过程中模型参数更新取决于Loss的梯度。

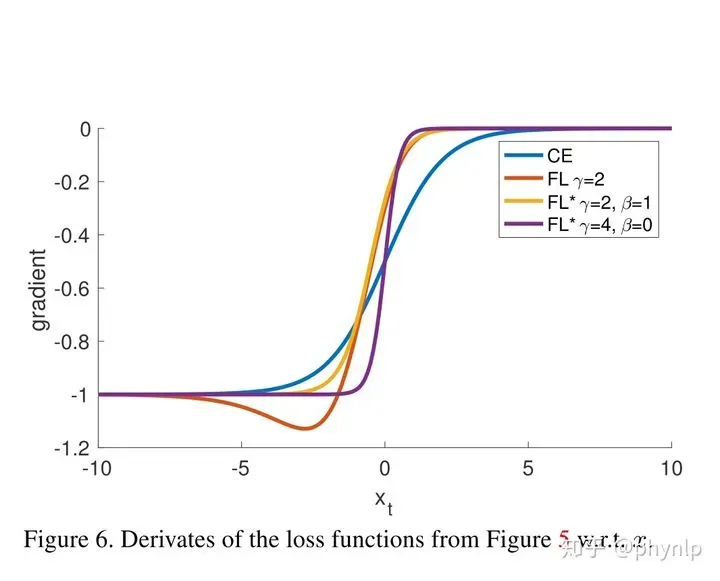
思考:

三、回归
(1)均方误差(MSE-Mean Square Error,L2 loss)
均方误差(MSE)是回归损失函数中最常用的误差,它是预测值与目标值之间差值的平方和,其公式如下所示:
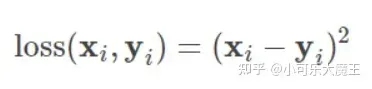
以 y-f(x) 为横坐标,MSE 为纵坐标,绘制其损失函数的图形:
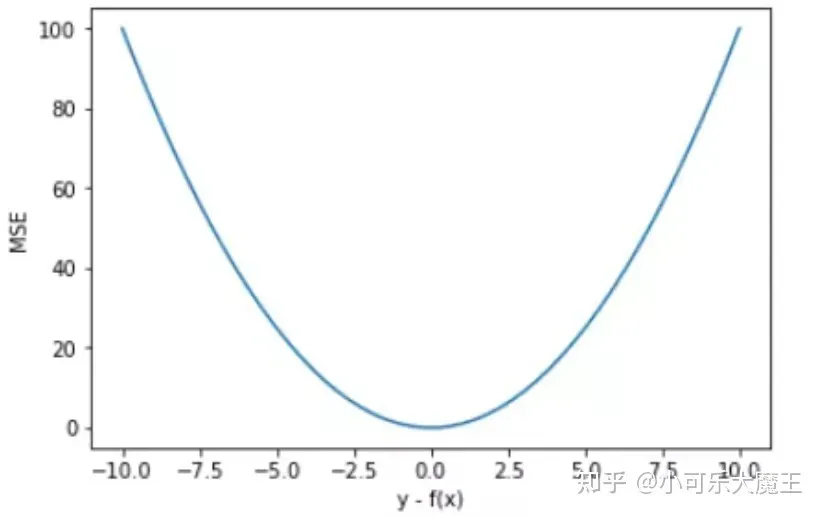
MSE 曲线的特点是光滑连续、可导,便于使用梯度下降算法。平方误差有个特性,就是当 yi 与 f(xi) 的差值大于 1 时,会增大其误差;当 yi 与 f(xi) 的差值小于 1 时,会减小其误差。这是由平方的特性决定的。也就是说, MSE 会对误差较大(>1)的情况给予更大的惩罚,对误差较小(<1)的情况给予更小的惩罚。比如说真实值为1,预测10次,有一次预测值为1000,其余次的预测值为1左右,显然loss值主要由1000决定。
优点:收敛速度快-MSE 随着误差的减小,梯度也在减小,这有利于函数的收敛,即使固定学习率,函数也能较快收敛到最小值。
缺点:离群点影响大从Training的角度来看,模型会更加偏向于惩罚较大的点,赋予其更大的权重,忽略掉较小的点的作用,无法避免离群点可能导致的梯度爆炸问题。如果样本中存在离群点,MSE 会给离群点赋予更高的权重,但是却是以牺牲其他正常数据点的预测效果为代价,因此会导致降低模型的整体性能。
(2)平均绝对误差(MAEMean Absolute Error,L1 loss)
平均绝对误差(MAE)是另一种常用的回归损失函数,它是目标值与预测值之差绝对值的和,表示了预测值的平均误差幅度,而不需要考虑误差的方向,范围是0到∞,其公式如下所示:
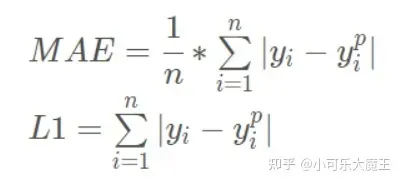
以 y-f(x) 为横坐标,MAE 为纵坐标,绘制其损失函数的图形:
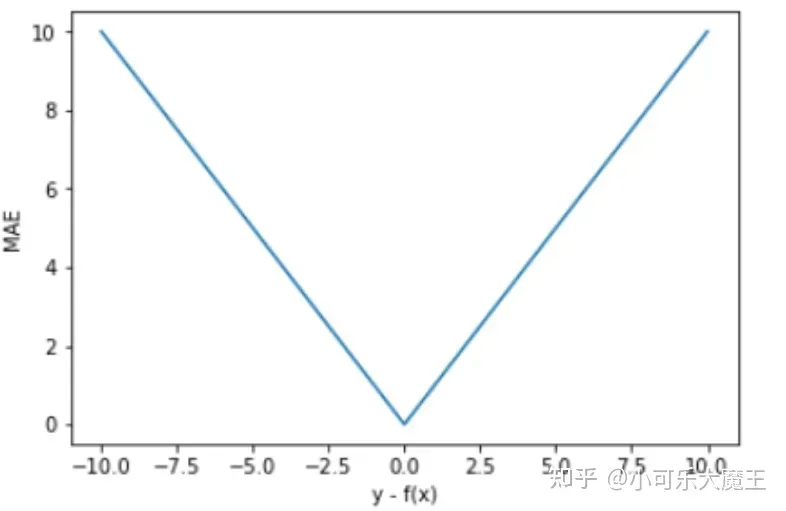
MAE 的曲线呈 V 字型,连续但在 y-f(x)=0 处不可导,计算机求导比较难。且 MAE 大部分情况下梯度相等,这意味着即使对于小的损失值,其梯度也是大的,不利于函数的收敛和模型的学习
优点:由于MAE 计算的是绝对误差,无论是 y-f(x)>1 还是 y-f(x)<1,没有平方项的作用,惩罚力度相同,因此MAE 相比 MSE 对离群点不过分敏感,拟合直线能够较好地表征正常数据的分布情况,其鲁棒性更好
缺点:MAE训练中梯度始终很大,且在0点连续但不可导,这意味着即使对于小的损失值,其梯度也是大的。这不利于函数的收敛和模型的学习,模型学习速度慢,同时也会导致使用梯度下降训练模型时,在结束时可能会遗漏全局最小值。
代码实现由torch.nn.L1Loss的参数reduction决定,当参数reduction
- 选择 ‘mean’ 或’none’时,即为MAE,
- 选择’sum’时即为L1 loss;
(3)SmoothL1 Loss(Huber损失函数)
顾名思义,smooth L1说的是光滑之后的L1,前面说过了L1损失的缺点就是有折点,不光滑,导致不稳定,那如何让其变得光滑呢?
Huber函数是对MAE和MSE二者的综合,其在函数值为0时,它也是可微分的。,其包含了一个超参数δ,δ 值决定了 Huber侧重于 MSE 还是 MAE 的优秀形式表现
- 当δ~ 0时,Huber损失会趋向于MSE;
- 当δ~ ∞(很大的数字),Huber损失会趋向于MAE
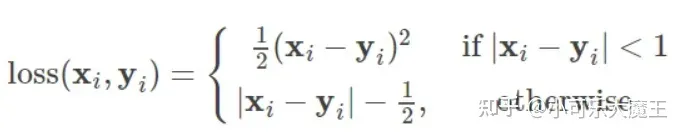
分别取 δ = 0.1、δ = 10,绘制相应的 Huber Loss损失函数的图形:
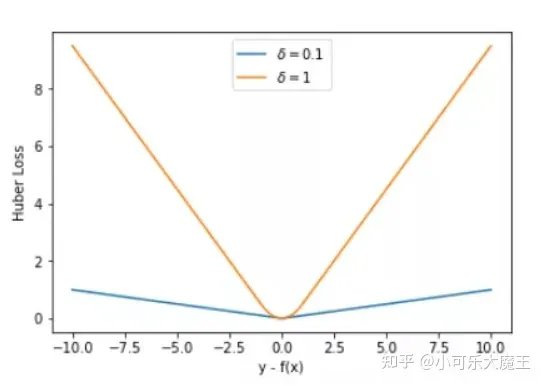
当 |y−f(x)| > δ 时,梯度一直近似为 δ,能够保证模型以一个较快的速度更新参数
当 |y−f(x)| ≤ δ 时,梯度逐渐减小,也能够保证模型更精确地得到全局最优值该函数实际上就是一个分段函数,在[-1,1]光滑,这样解决了MAE的不光滑问题,在[-∞,1)(1,+∞])区间解决了MSE可能导致的离群点梯度爆炸的问题,即:
Huber 函数它围绕的最小值会减小梯度,且相比MSE,它对异常值更具鲁棒性, Huber 函数同时具备了 MSE 和 MAE 的优点,既弱化了离群点的过度敏感问题,又实现了处处可导的功能
优点:同时具备了 MSE 和 MAE 的优点,既弱化了离群点的过度敏感问题,又实现了处处可导的功能,收敛速度也快于MAE
- 相比于MAE损失函数,可以收敛得更快;
- 相比于MSE损失函数,对离群点、异常值不敏感,梯度变化相对更小,训练时不容易抛出奇怪的结果
注意点:δ超参数需要在训练中选择,常常使用交叉验证法选取合适超参数δ ,超参数的选取直接影响训练的效果的好坏
(4)L1、L2、smooth L1总结-工业应用中如何选择合适的损失函数
- 从误差的角度来说:MSE可以用来评价数据变化的程度,MAE则能更好的反应预测值误差的实际情况
- 从离群点角度选择: 如果离群点仅仅只是在数据提取的过程中的损坏或者清洗中的错误采样,则无须给予过多关注,那么我们应该选择 MAE, 但如果离群点是实际的数据或者重要的数据需要被检测到的异常值,那我们应该选择 MSE
- 从收敛速度的角度来说:MSE>Huber>MAE
- 从求解梯度的复杂度来说:MSE 要优于 MAE,且梯度也是动态变化的,MSE能较快准确达到收敛。
- 从模型的角度选择:对于大多数CNN网络,我们一般是使用MSE而不是MAE,因为训练CNN网络很看重训练速度,对于边框预测回归问题,通常也可以选择平方损失函数,但平方损失函数缺点是当存在离群点(outliers)的时候,这些点会占loss的主要组成部分。对于目标检测FastR CNN采用稍微缓和一点绝对损失函数(smooth L1损失),它是随着误差线性增长,而不是平方增长。
文章出处登录后可见!