目录
A.写在前面
从各种渠道都有听说视觉大模型,于是想着深入了解下,趁着周末搜集些材料。
主要从论文支撑、基础理论和产业现状三方面展开调研。
完成这篇博客后,我有一个很直观的感受:大模型可能不是最优的方案,但它会是在有限的资源与环境下解决现阶段问题的一个比较合理的方法,并且这种实现方法是可以通过扩展资源去优化的。我觉得这是众多实力雄厚的公司选择大模型这条赛道的主要原因。
权当记录,如有纰漏,欢迎指正。
B.论文支撑与基础理论
1.大模型基本概念的诞生
如果是刚刚接触一个新的领域,想要对其宏观概貌有个初步了解,自然是先读该领域的综述论文。
2021年8月份,李飞飞和100多位学者联名发表一份200多页的研究报告《On the Opportunities and Risks of Foundation Models》(报告地址:https://arxiv.org/abs/2108.07258),深度地综述了当前大规模预训练模型面临的机遇和挑战。
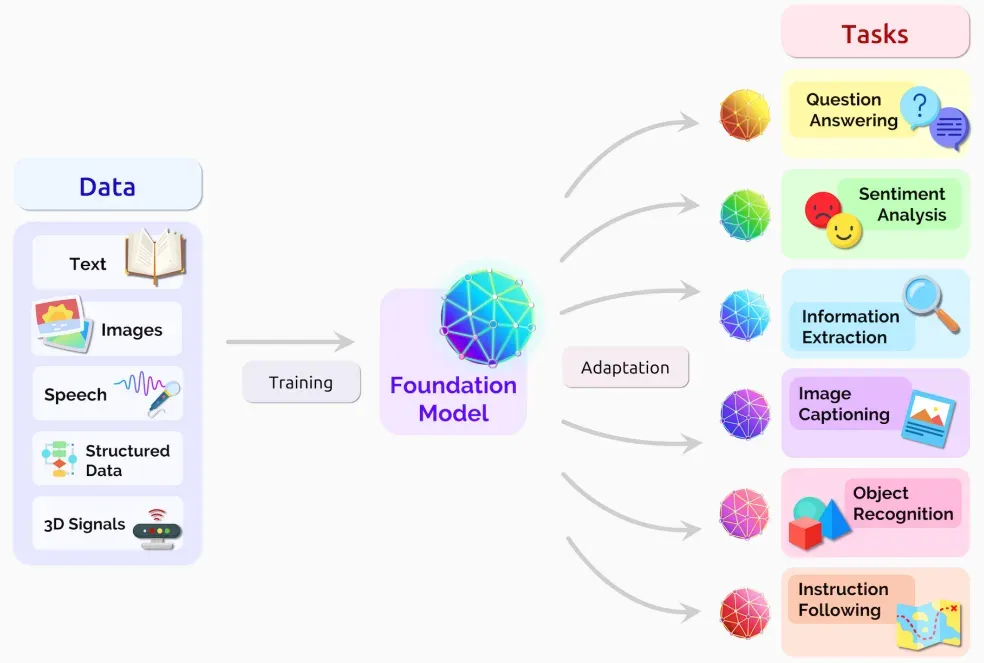
在文章中,AI专家们将大模型统一命名为Foundation Models,可以翻译为基础模型或者是基石模型,论文肯定了Foundation Models对智能体基本认知能力的推动作用,同时也指出大模型呈现出涌现与同质化的特性。
所谓涌现,代表一个系统的行为是隐性推动的,而不是显式构建的;同质化是指基础模型的能力是智能的中心与核心,大模型的任何一点改进会迅速覆盖整个社区,但其缺陷也会被所有下游模型所继承。
2.大模型产业化落地的理论支撑
大模型的应用过程中,是先实现了一定的落地成功案例,然后才产生了许多的大规模应用理论支撑。或许这是深度学习及其相关技术的“宿命”。
2021年10月份,Google的Jeff Dean发表了一篇blog《Introducing Pathways: A next-generation AI architecture》(博客地址:Introducing Pathways: A next-generation AI architecture),提到了下一代AI架构Pathways 。
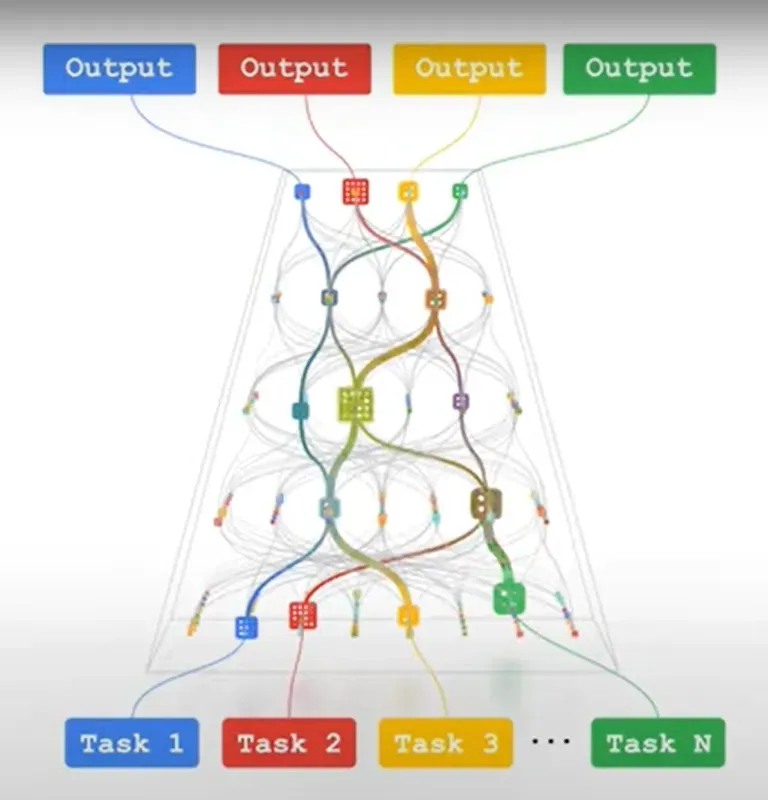
Pathways 在 AI 和模型上的定义是一个新的AI架构:(1)能同时执行众多(AI)任务。(2)快速学习新任务。(3)拥有对(真实)世界的更好理解。
业界对这种大一统的模型探索从来都没有停止,一个更加泛化,多模态输入,多任务的模型是追求的目标。
个人认为这篇论文可以为大模型的产业化落地提供理论支撑。原因在之后的实际部署章节会具体讲解。
3.视觉模型架构的形成-Transformer到ViT再到MAE
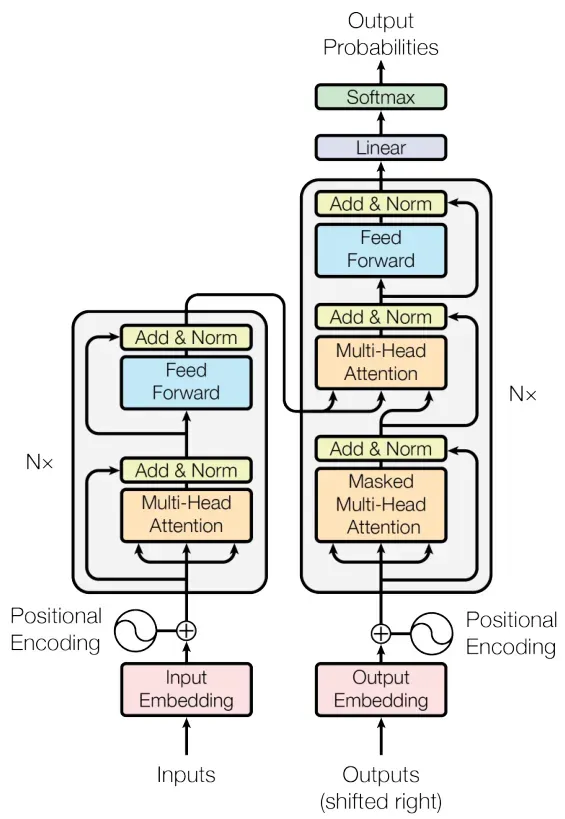
个人以Transformer的提出时间为分界线,在Transformer提出之后,大模型的基础模型架构基本形成。原因有二:一是注意力机制代替卷积神经网络称为主流基础模型组件,这有利于模型向更大的参数量扩展。而是Transformer有这兼容多模态信息的天生优势特性,这有力地丰富了大模型的应用场景。论文地址https://arxiv.org/abs/1706.03762
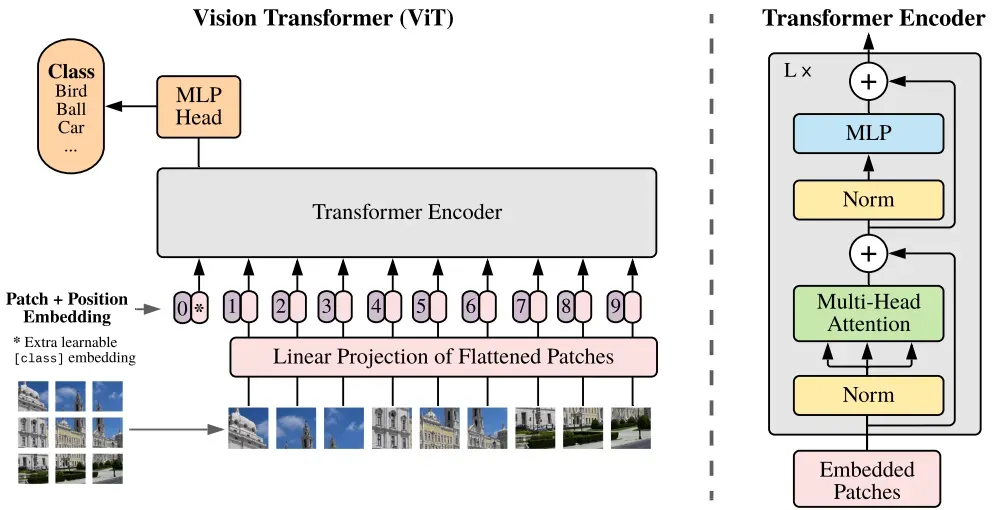
ViT是Transformer在计算机视觉(CV)领域的拓展。在ViT之后,人们看到了使用统一模型处理多模态信息的有效解决方案。上面也提到了,多模态信息的处理保证了大模型的应用场景丰富性。论文地址:https://arxiv.org/abs/2010.11929
MAE是一种ViT的训练方式,它的本质是一种自监督学习方法。MAE的意义是提出了ViT这种需要海量数据投喂的大规模网络模型如何有效率地、在模型继续增长的前提下数据需求也会增长这些情况下能可行地完成训练任务。论文地址:https://arxiv.org/pdf/2111.06377.pdf
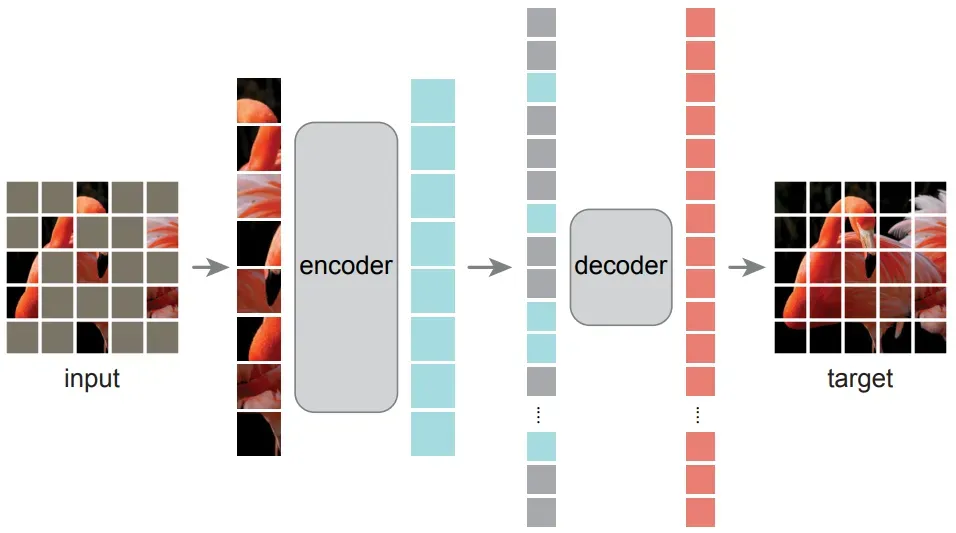
从Transformer到ViT再到MAE的提出过程,代表的视觉大模型基本框架的形成过程。
关于这部分我会另写一篇博客详细地讲解Transformer、ViT、MAE三者。
C.产业落地化现状
1.百度文心 UFO 2.0
整体概述
近年来预训练大模型一次次刷新记录,展现出惊人的效果,但对于产业界而言,势必要面对如何应用落地的问题。当前预训练模型的落地流程可被归纳为:针对只有少量标注数据的特定任务,使用任务数据 fine-tune 预训练模型并部署上线。然而,当预训练模型参数量不断增大后,该流程面临两个严峻的挑战。首先,随着模型参数量的急剧增加,大模型 fine-tuning 所需要的计算资源将变得非常巨大,普通开发者通常无法负担。其次,随着 AIoT 的发展,越来越多 AI 应用从云端往边缘设备、端设备迁移,而大模型却无法直接部署在这些存储和算力都极其有限的硬件上。
针对预训练大模型落地所面临的问题,百度提出统一特征表示优化技术(UFO:Unified Feature Optimization),在充分利用大数据和大模型的同时,兼顾大模型落地成本及部署效率。VIMER-UFO 2.0 技术方案的主要内容包括:
- All in One:行业最大 170 亿参数视觉多任务模型,覆盖人脸、人体、车辆、商品、食物细粒度分类等 20+ CV 基础任务,单模型 28 个公开测试集效果 SOTA。
- One for All:首创针对视觉多任务的超网络与训练方案,支持各类任务、各类硬件的灵活部署,解决大模型参数量大,推理性能差的问题。
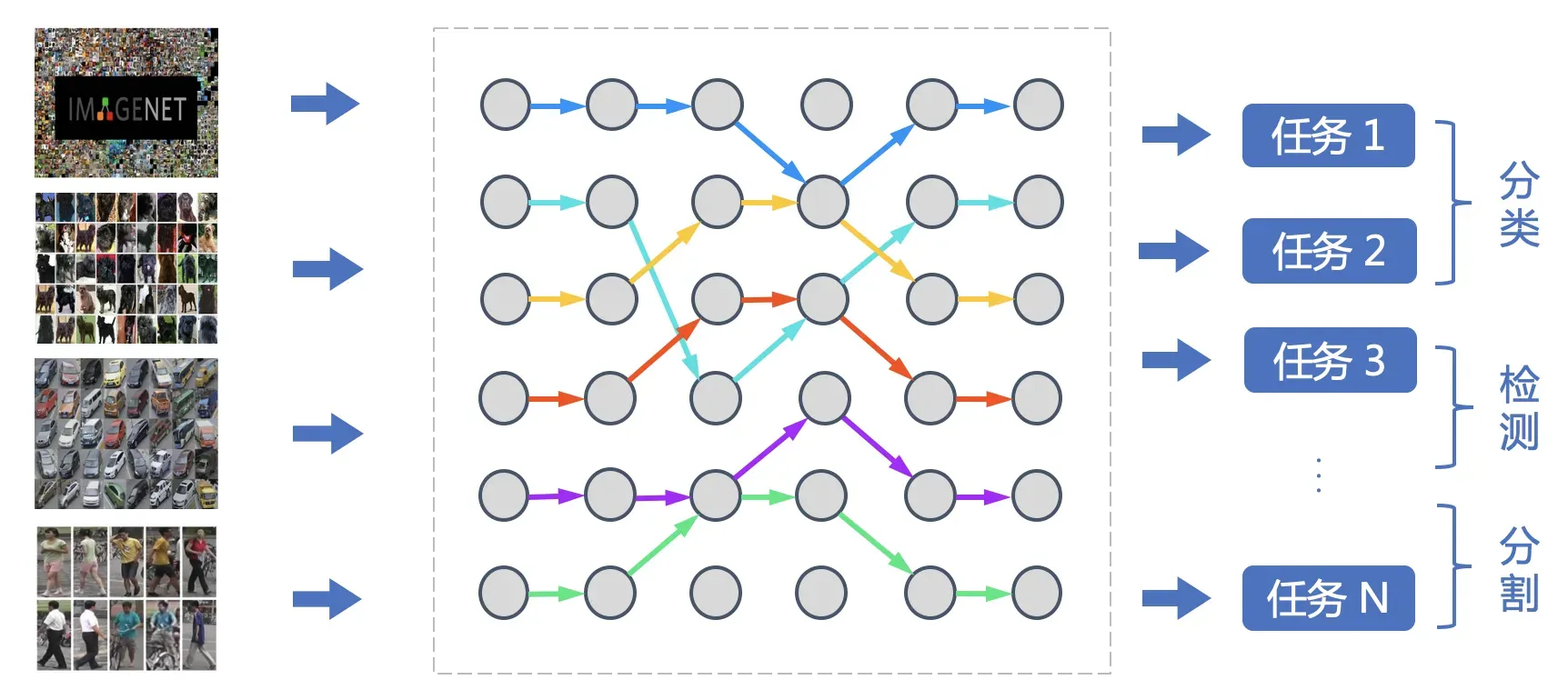
原理介绍
All in One: 功能更强大、更通用的视觉模型
之前主流的视觉模型生产流程,通常采用单任务 “train from scratch” 方案。每个任务都从零开始训练,各个任务之间也无法相互借鉴。由于单任务数据不足带来偏置问题,实际效果过分依赖任务数据分布,场景泛化效果往往不佳。近两年蓬勃发展的大数据预训练技术,通过使用大量数据学到更多的通用知识,然后迁移到下游任务当中,本质上是不同任务之间相互借鉴了各自学到的知识。基于海量数据获得的预训练模型具有较好的知识完备性,在下游任务中基于少量数据 fine-tuning 依然可以获得较好的效果。不过基于预训练+下游任务 fine-tuning 的模型生产流程,需要针对各个任务分别训练模型,存在较大的研发资源消耗。
百度提出的 VIMER-UFO All in One 多任务训练方案,通过使用多个任务的数据训练一个功能强大的通用模型,可被直接应用于处理多个任务。不仅通过跨任务的信息提升了单个任务的效果,并且免去了下游任务 fine-tuning 过程。VIMER-UFO All in One 研发模式可被广泛应用于各类多任务 AI 系统,以智慧城市场景为例,VIMER-UFO 可以用单模型实现人脸识别、人体和车辆ReID等多个任务的 SOTA 效果,同时多任务模型可获得显著优于单任务模型的效果,证明了多任务之间信息借鉴机制的有效性。
One for All: 灵活、可伸缩的弹性部署方案
受算力和存储的限制,大模型无法直接部署在边缘设备上。一个针对云端设备开发的模型要部署到边缘设备或端设备时往往要进行模型压缩,或完全重新设计,而预训练大模型的压缩本身需要耗费大量的资源。
另外,不同任务对模型的功能和性能要求也不同,例如人脸识别门禁系统只需具备人脸识别功能即可,智慧社区的管控系统则需要同时具备人脸识别和人体分析的能力,部分场景还需要同时具备车型识别及车牌识别能力。即便是同样的人脸识别任务,门禁系统和金融支付系统对模型的精度和性能要求也不同。目前针对这些任务往往需要定制化开发多个单任务模型,加之需要适配不同的硬件平台,AI模型开发的工作量显著增长。
针对大模型的开发和部署问题,VIMER-UFO 给出了 One for All 的解决方案,通过引入超网络的概念,超网络由众多稀疏的子网络构成,每个子网络是超网络中的一条路径,将不同参数量、不同任务功能和不同精度的模型训练过程变为训练一个超网络模型。训练完成的 VIMER-UFO One for All 超网络大模型即可针对不同的任务和设备低成本生成相应的可即插即用的小模型,实现 One for All Tasks 和 One for All Chips 的能力。
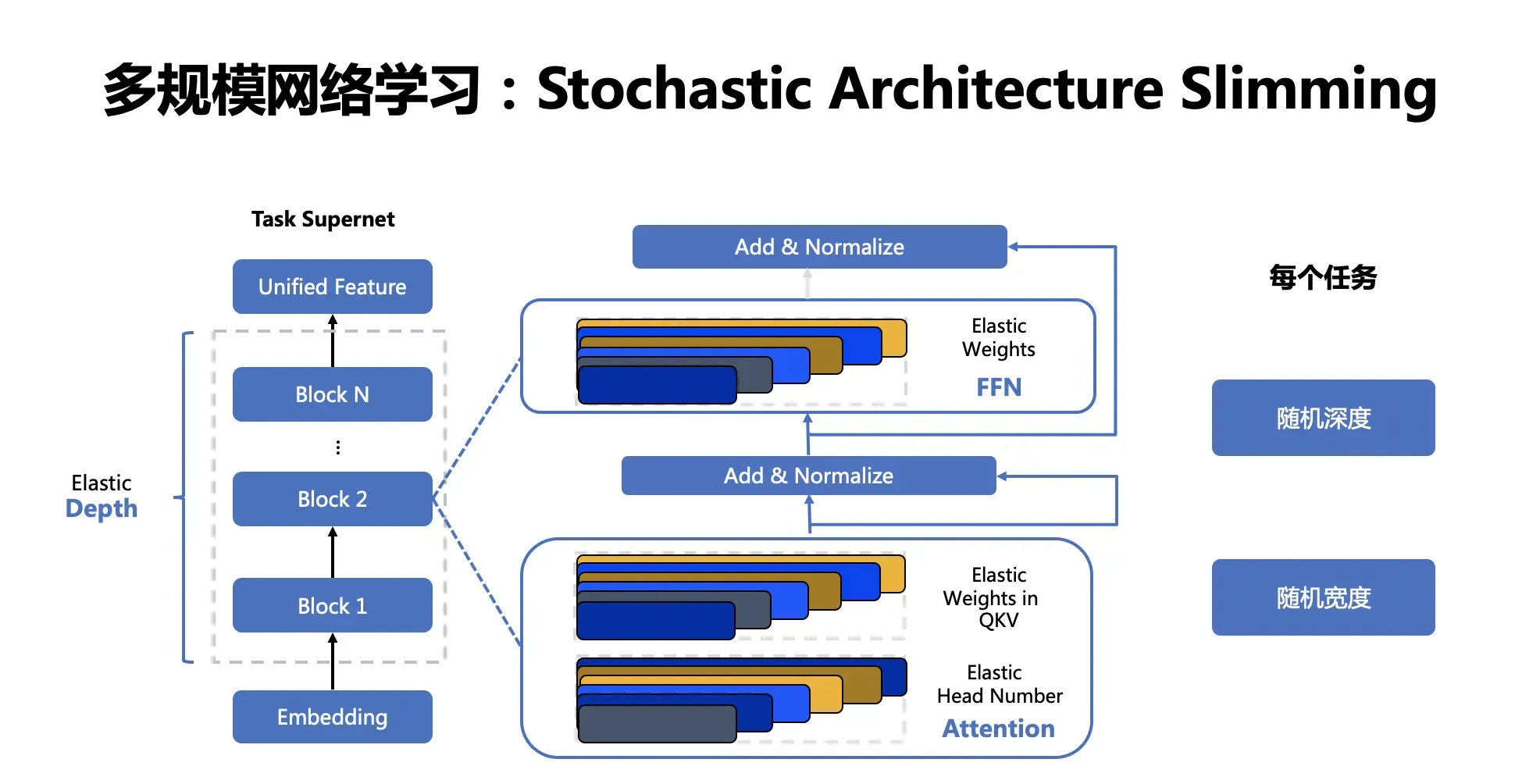
超网络设计与训练方案
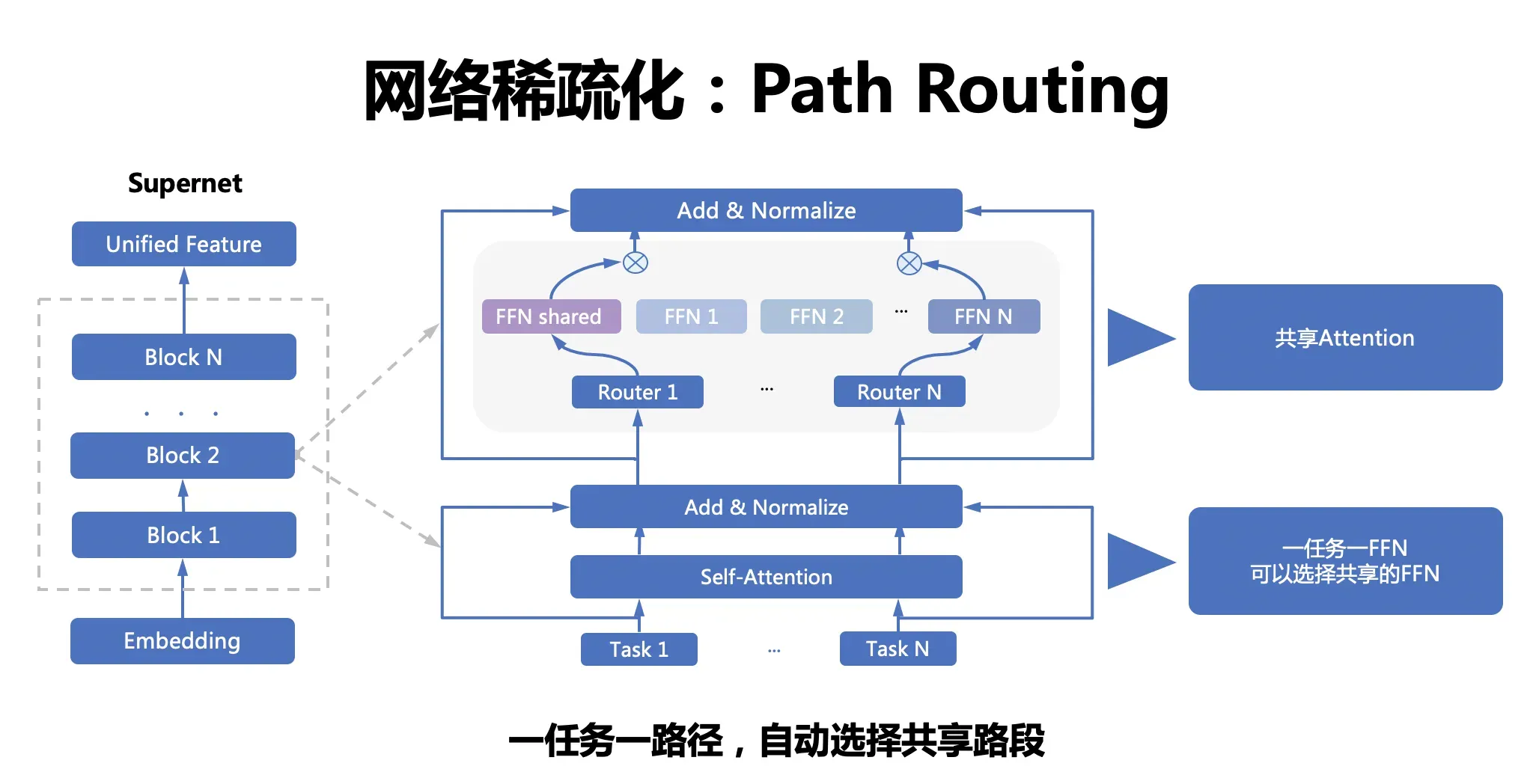
VIMER-UFO 2.0 基于 Vision Transformer 结构设计了多任务多路径超网络。与谷歌 Switch Transformer 以图片为粒度选择路径不同,VIMER-UFO 2.0 以任务为粒度进行路径选择,这样当超网络训练好以后,可以根据不同任务独立抽取对应的子网络进行部署,而不用部署整个大模型。VIMER-UFO 2.0 的超网中不同的路径除了可以选择不同 FFN 单元,Attention 模块和 FFN 模块内部也支持弹性伸缩,实现网络的搜索空间扩展,为硬件部署提供更多可选的子网络,并提升精度。
VIMER-UFO 2.0 超网络分为多路径 FFN 超网和与可伸缩 Attention 超网两部分。首先针对多路径 FFN 超网模块,每个任务都有两种不同的路径选择,即选择共享 FFN(FFN-shared)或者专属 FFN(FFN-taskX),当选定好 FFN 以后,还可根据放缩系数弹性选择FFN中参数规模;因此FFN超网络中共有(T * ratio)^L 种不同的 FFN 路径,其中 T 为 task 的数量,L 为网络的层数, ratio 为放缩系数的数量。而对于 self-attention 超网,每个子网络可以选择不同的 Head 数量 QKV 矩阵参数量。
VIMER-UFO 2.0 训练时将模型按层级结构划分为任务超网和芯片超网两个级别。并分别使用不同的训练方案进行优化。
One For All Tasks
任务超网络训练时,需要同时优化网络参数(FFN)和路由参数(Router)。前面提到,网络参数包含共享 FFN(FFN-shared)和专属 FFN(FFN-taskX),所有任务都会更新共享 FFN 的参数,特定任务只会更新专属的 FFN 参数。而路由参数由于离散不可导,训练时通过 Gumbel Softmax 进行优化。由于在训练超网的过程中多个任务的同时进行优化,同时引入了路由机制,可以让相关的任务共享更多的参数,而不相关的任务之间尽量减少干扰,从而获得针对不同任务最优的子网络模型。在业务应用时,只需要根据不同子网络在特定任务的效果,抽取出对应的任务子网,即可直接部署,无需重复训练。
One For All Chips
在任务超网训练完成以后,针对每个任务抽取的子网络进行芯片子网络的训练。经过上述训练以后便得到了每个任务的芯片超网。在业务应用时,针对不同平台存储容量和算力不同,可以抽取不同深度和宽度的子网络进行部署,进一步压缩模型的参数和计算量。由于超网络中子网络的数据众多,每个子网逐一测试精度和延时并不现实,因此在 VIMER-UFO 2.0 中,使用了 GP-NAS中的基于高斯过程的超参数超参估计技术,只需采样超网络中少了子网络进行评估,即可准确预测出其他网络的精度和速度。
模型效果
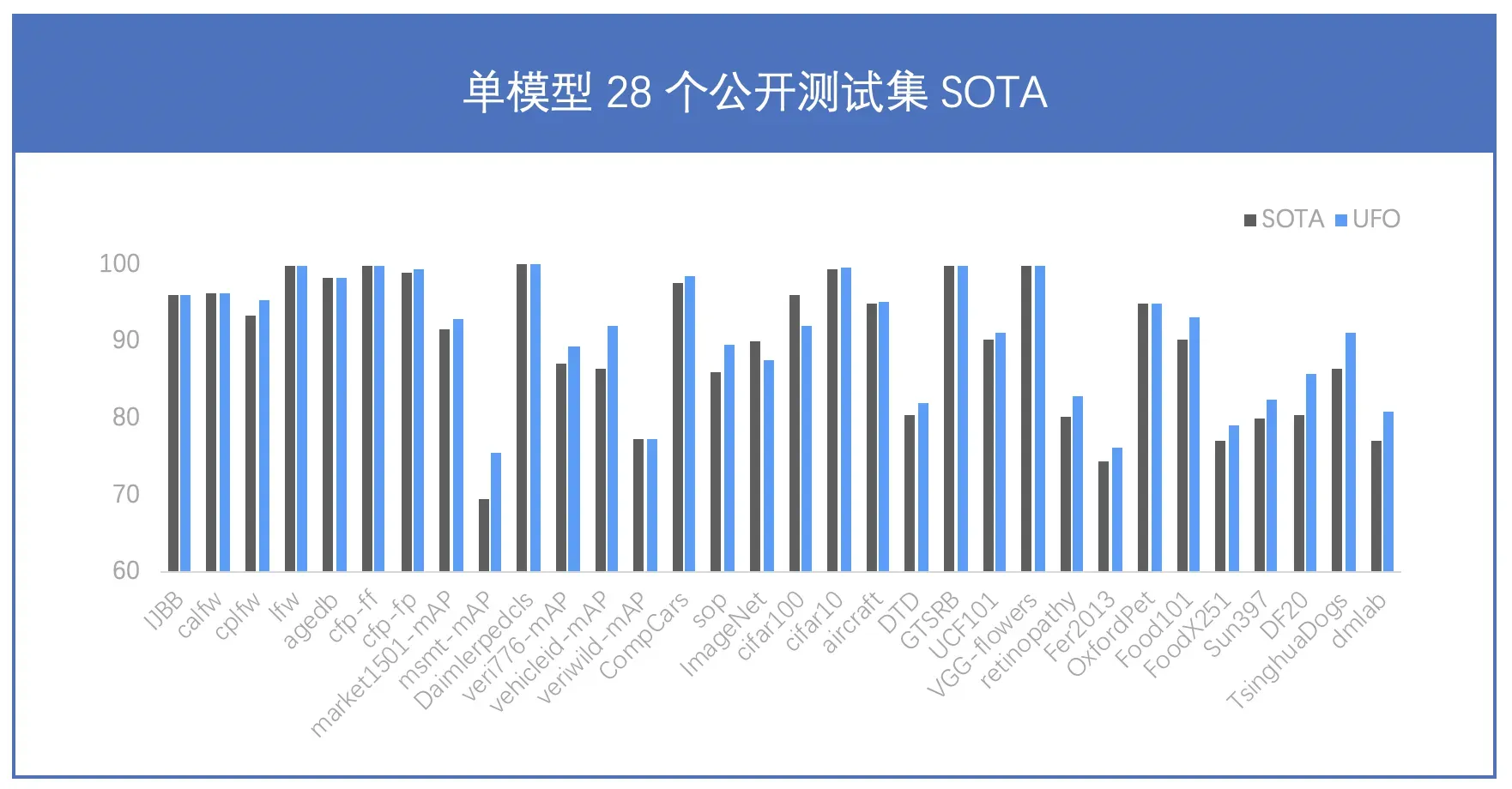
170 亿参数,行业最大 CV 大模型,单模型 28 项公开数据集 SOTA
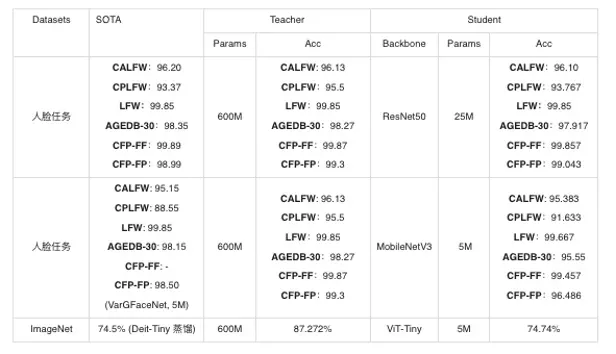
VIMER-UFO 2.0 单个模型一套参数,在不进行下游finetuning的情况下,在 28 个主流的 CV 公开数据集上取得了 SOTA 的结果。同时,尽管 VIMER-UFO 2.0 大模型参数量达到了170 亿,得益于 Task-MoE 稀疏结构,每个任务推理时只需激活部分参数,计算量相当于 6 亿参数模型规模,加速比接近 30 倍。


应用场景与方案
VIMER-UFO 2.0 大模型可被广泛应用于智慧城市、无人驾驶、工业生产等各类多任务 AI 系统。同时 VIMER-UFO 2.0 支持多种应用模式配合,兼顾效率和效果。
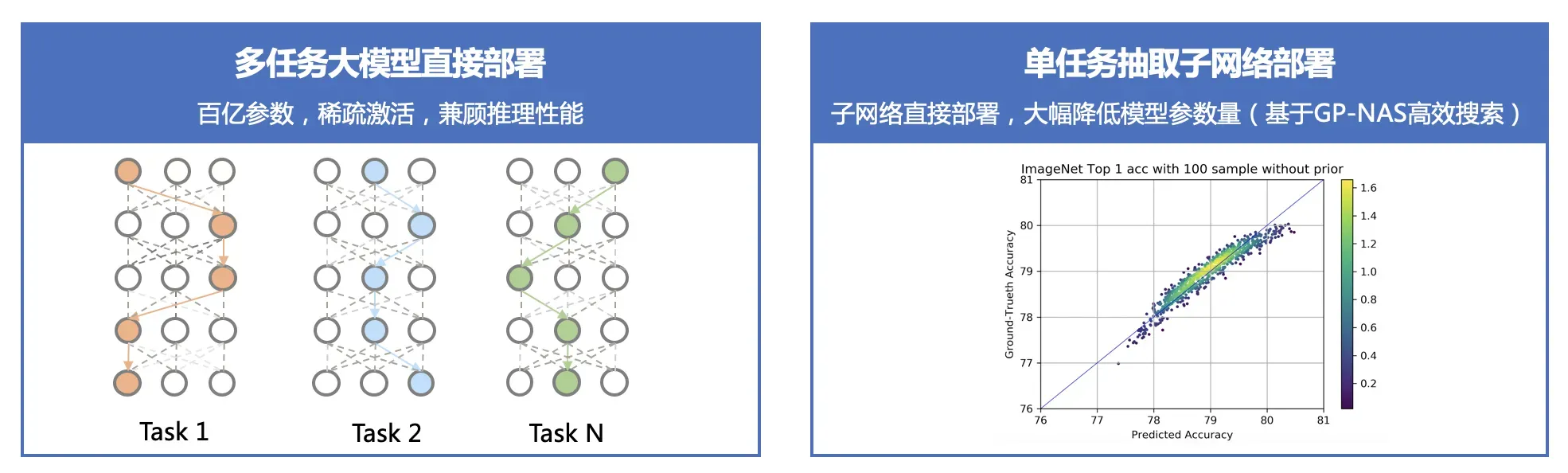
多任务大模型直接部署
针对有多任务处理需求的 AI 系统,VIMER-UFO 2.0 大模型具备处理多个任务的能力,例如同时进行人脸、人体和车辆等目标的检测和识别。同时得益于 VIMER-UFO 2.0大模型使用的Task-MoE稀疏结构,其在运行时,根据任务的不同自动选择激活最优的区域,每个任务只激活模型的部分参数,计算量显著降低,推理效率接近主流的单任务小模型。这类似于人脸的大脑,人类的大脑经过数百万年的进化,形成了分区的结构,不同区域负责特定功能,同时又是相互协作的一个整体。
单任务抽取子网络部署
针对只需要单个或个别处理能力的AI服务,可根据任务需求直接从 VIMER-UFO 2.0 大模型中抽取部分参数,得到针对特定任务的模型进行部署,可大幅减少模型的参数量,例如 VIMER-UFO 2.0 大模型具备 170 亿参数规模,而抽取的单任务模型只包含 6 亿参数,基于单任务模型抽取的芯片级模型参数量可进一步降低到 1 亿规模,压缩比达到 100+ 倍。并且不同任务之间可自由组合,大大提升了 AI 服务的开发和部署效率。
新任务快速扩展
针对 VIMER-UFO 2.0 模型不支持的新任务,VIMER-UFO 2.0 支持在只更新部分参数的情况下,仅使用少量数据 finetune,实现任务的快速扩展。根据前面原理部分可知,VIMER-UFO 2.0 的超网络中有一个 share 的分支(Attention 与 FFN-Shared),该分支在 VIMER-UFO 2.0 大模型的训练过程中使用全部任务数据进行优化,因此具备了强大的任务泛化性,对于不支持的新任务,只需要抽取该分支的参数使用少量数据进行 fine-tuning,便可在新任务上达到优异的性能。同时由于只需要更新部分参数,下游 finetune 的成本大大降低,解决了目前主流大模型落地应用的难题。 新任务扩展结果:
| Datasets | SOTA | 10%FT | 100%FT |
|---|---|---|---|
| dmlab | 77 | 74.8 | 80.93 |
| retinopathy | 80.10 | 60.90 | 82.90 |
| aircraft | 94.90 | 70.84 | 95.02 |
| cifar10 | 99.40 | 99.32 | 99.48 |
| gtsrb | 99.71 | 99.83 | 99.90 |
子网络下游蒸馏
为了更好的支持在移动和边缘设备上进行部署,VIMER-UFO 2.0 还支持抽取子网络模型进行模型蒸馏,结合百度研发的异构蒸馏技术,将 Transformer 结构中的知识迁移到 CNN 中,模型参数量从亿级别进一步压缩到兆级别的规模,整体实现 1000+ 倍的压缩。
2.华为 盘古CV视觉大模型
2021年4月份华为发布盘古系列大模型,首次实现模型按需抽取的业界最大CV大模型,首次实现兼顾判别与生成能力
基于模型大小和运行速度需求,自适应抽取不同规模模型,AI应用开发快速落地。使用层次化语义对齐和语义调整算法,在浅层特征上获得了更好的可分离性,使小样本学习的能力获得了显著提升,达到业界第一。做到了
- 当时业界最大CV模型
- 判别与生成联合预训练
- 100+ 场景验证
- 小样本学习性能领先
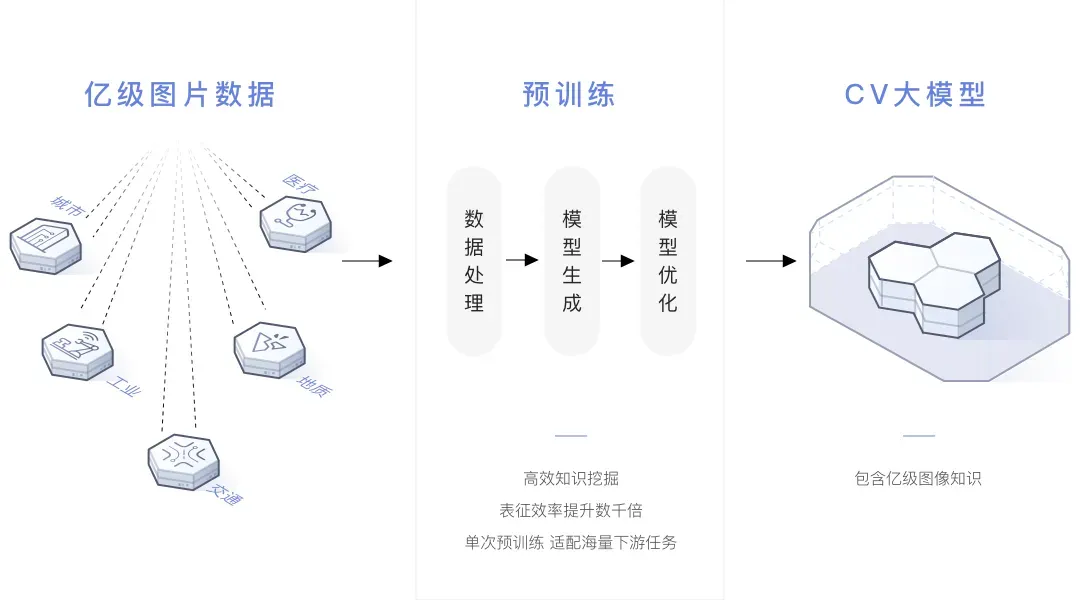
模型预训练
大规模数据的收集和索引:模型预训练主要分为两个阶段,一个阶段是通用数据集的预训练,另外一个阶段是特定数据集的预训练。 第一阶段:使用超过 100TB 的通用图像数据,大部分来自网络,包含少量有标签数据(ImageNet)。这些数据以分布式的形式存储在华为云的服务器端,支持高效的访问与存储。使用亿级通用图像数据,结合团队研发的预训练技术,训练得到盘古通用预训练大模型;第二阶段:在盘古通用预训练模型基础上,结合下游任务大量无标注数据,进行自监督预训练,开发出特定行业适配的盘古预训练大模型。比如在无人机巡检案例中,使用数十万输电领域数据,电科院提供输电领域的大量有标注与无标注数据。
模型部署与模型迭代
由于大模型部署成本较高,无法在端侧或者边缘侧直接部署,盘古模型则是通过模型抽取与知识蒸馏的技术部署小模型。使用下游任务小数据集对大模型进行微调,使用重采样等小样本技术提升大模型在小数据集上的表现。 同时为了提升大模型的表现,模型是需要不断迭代的,盘古大模型具备数据挖掘、增量训练和模型进化功能,为开发者提供长期、稳定的后续服务,使得模型能够在更长的时间内发挥更大的价值。对于特定的下游任务数据集,需要不断提升下游任务数据集质量,比如电力巡检案例,盘古预训练大模型通过从海量电力无标注样本数据中挖掘数量少、性能差的故障样本,返回人工修正后加入模型训练以提升识别性能,提升模型的持续优化。
3.商汤 INTERN 大模型
上海人工智能实验室联合商汤科技、香港中文大学、上海交通大学,共同发布新一代通用视觉技术体系“书生”(INTERN),该体系旨在系统化解决当下人工智能视觉领域中存在的任务通用、场景泛化和数据效率等一系列瓶颈问题。全新的通用视觉技术体系命名为“书生”,意在体现其如同书生一般的特质,可通过持续学习,举一反三,逐步实现通用视觉领域的融会贯通,最终实现灵活高效的模型部署。“书生”通用视觉技术将实现以一个模型完成成百上千种任务,体系化解决人工智能发展中数据、泛化、认知和安全等诸多瓶颈问题。
一个基模型覆盖4大视觉任务,26个场景
人工智能系统正在从完成单一任务向复杂的多任务协同演进,其覆盖的场景也越来越多样化。借助“书生”(INTERN)通用视觉技术体系,业界可凭借极低的下游数据采集成本,快速验证多个新场景,对于解锁实现人工智能长尾应用具有重要意义。一个“书生”基模型即可全面覆盖分类、目标检测、语义分割、深度估计四大视觉核心任务。在 ImageNet 等26个最具代表性的下游场景中,书生模型广泛展现了极强的通用性,显著提升了这些视觉场景中长尾小样本设定下的性能。相较于当前最强开源模型(OpenAI 于2021年发布的 CLIP),“书生”在准确率和数据使用效率上均取得大幅提升。
具体而言,基于同样的下游场景数据,“书生”在分类、目标检测、语义分割及深度估计四大任务26个数据集上,平均错误率分别降低了40.2%、47.3%、34.8%和9.4%。“书生”在数据效率方面的提升尤为令人瞩目:只需要1/10的下游数据,就能超过CLIP基于完整下游数据的准确度。例如,在花卉种类识别 FLOWER 任务上,每一类只需两个训练样本,就能实现99.7%的准确率。
七大模块:打造全新技术路径
通用视觉技术体系“书生”(INTERN)由七大模块组成,包括通用视觉数据系统、通用视觉网络结构、通用视觉评测基准三个基础设施模块,以及区分上下游的四个训练阶段模块。“书生”的推出能够让业界以更低的成本,获得拥有处理多种下游任务能力的AI模型,并以其强大的泛化能力支撑智慧城市、智慧医疗、自动驾驶等场景中大量小数据、零数据等样本缺失的细分和长尾场景需求。
在“书生”的四个训练阶段中,前三个阶段位于该技术链条的上游,在模型的表征通用性上发力;第四个阶段位于下游,可用于解决各种不同的下游任务。 第一阶段,着力于培养“基础能力”,即让其学到广泛的基础常识,为后续学习阶段打好基础。 第二阶段,培养“专家能力”,即多个专家模型各自学习某一领域的专业知识,让每一个专家模型高度掌握该领域技能,成为专家。 第三阶段,培养“通用能力”,随着多种能力的融会贯通,“书生”在各个技能领域都展现优异水平,并具备快速学会新技能的能力。 在循序渐进的前三个训练阶段模块,“书生”在阶梯式的学习过程中具备了高度的通用性。 当进化到第四阶段时,系统将具备“迁移能力”,此时“书生”学到的通用知识可以应用在某一个特定领域的不同任务中,如智慧城市、智慧医疗、自动驾驶等,实现广泛赋能。
产学研协同:开源共创通用AI生态
作为AI技术的下一个重大里程碑,通用人工智能技术将带来颠覆性创新,实现这一目标需要学术界和产业界的紧密协作。上海人工智能实验室、商汤科技、香港中文大学以及上海交通大学,未来将依托通用视觉技术体系“书生”(INTERN),发挥产学研一体化优势,为学术研究提供平台支持,并全面赋能技术创新与产业应用。
待续……
文章出处登录后可见!