手动顺序搭建resnet18
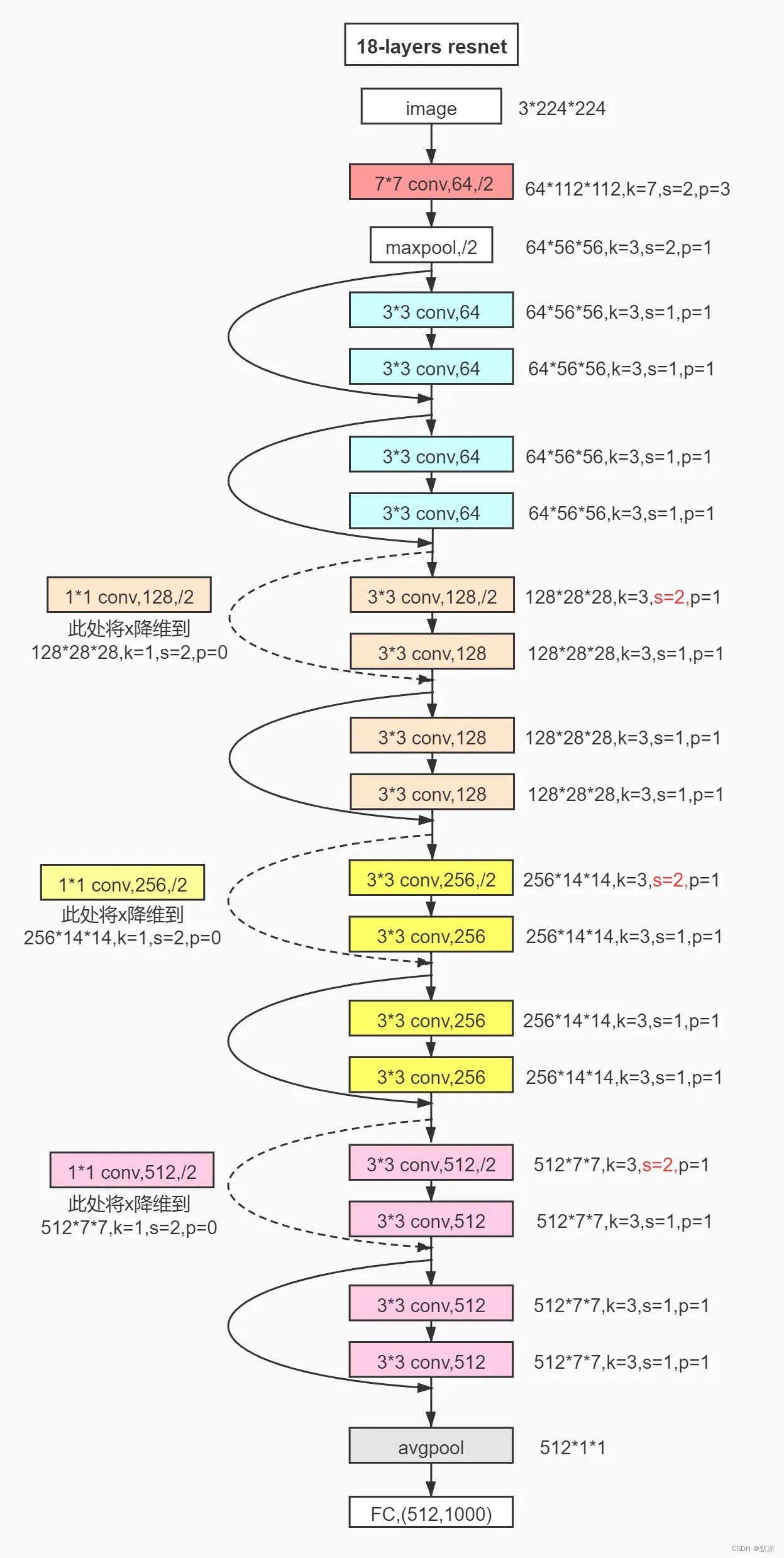
文件名:mode_resnet18
import torch
from torch import nn
# 导入记好了, 2维卷积,2维最大池化,展成1维,全连接层,构建网络结构辅助工具,2d网络归一化,激活函数,自适应平均池化
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential, BatchNorm2d, ReLU, AdaptiveAvgPool2d
from torchsummary import summary
class Resnet18(nn.Module):
def __init__(self, num_classes):
super(Resnet18, self).__init__()
self.model0 = Sequential(
# 0
# 输入3通道、输出64通道、卷积核大小、步长、补零、
Conv2d(in_channels=3, out_channels=64, kernel_size=(7, 7), stride=2, padding=3),
BatchNorm2d(64),
ReLU(),
MaxPool2d(kernel_size=(3, 3), stride=2, padding=1),
)
self.model1 = Sequential(
# 1.1
Conv2d(in_channels=64, out_channels=64, kernel_size=(3, 3), stride=1, padding=1),
BatchNorm2d(64),
ReLU(),
Conv2d(in_channels=64, out_channels=64, kernel_size=(3, 3), stride=1, padding=1),
BatchNorm2d(64),
ReLU(),
)
self.R1 = ReLU()
self.model2 = Sequential(
# 1.2
Conv2d(in_channels=64, out_channels=64, kernel_size=(3, 3), stride=1, padding=1),
BatchNorm2d(64),
ReLU(),
Conv2d(in_channels=64, out_channels=64, kernel_size=(3, 3), stride=1, padding=1),
BatchNorm2d(64),
ReLU(),
)
self.R2 = ReLU()
self.model3 = Sequential(
# 2.1
Conv2d(in_channels=64, out_channels=128, kernel_size=(3, 3), stride=2, padding=1),
BatchNorm2d(128),
ReLU(),
Conv2d(in_channels=128, out_channels=128, kernel_size=(3, 3), stride=1, padding=1),
BatchNorm2d(128),
ReLU(),
)
self.en1 = Sequential(
Conv2d(in_channels=64, out_channels=128, kernel_size=(1, 1), stride=2, padding=0),
BatchNorm2d(128),
ReLU(),
)
self.R3 = ReLU()
self.model4 = Sequential(
# 2.2
Conv2d(in_channels=128, out_channels=128, kernel_size=(3, 3), stride=1, padding=1),
BatchNorm2d(128),
ReLU(),
Conv2d(in_channels=128, out_channels=128, kernel_size=(3, 3), stride=1, padding=1),
BatchNorm2d(128),
ReLU(),
)
self.R4 = ReLU()
self.model5 = Sequential(
# 3.1
Conv2d(in_channels=128, out_channels=256, kernel_size=(3, 3), stride=2, padding=1),
BatchNorm2d(256),
ReLU(),
Conv2d(in_channels=256, out_channels=256, kernel_size=(3, 3), stride=1, padding=1),
BatchNorm2d(256),
ReLU(),
)
self.en2 = Sequential(
Conv2d(in_channels=128, out_channels=256, kernel_size=(1, 1), stride=2, padding=0),
BatchNorm2d(256),
ReLU(),
)
self.R5 = ReLU()
self.model6 = Sequential(
# 3.2
Conv2d(in_channels=256, out_channels=256, kernel_size=(3, 3), stride=1, padding=1),
BatchNorm2d(256),
ReLU(),
Conv2d(in_channels=256, out_channels=256, kernel_size=(3, 3), stride=1, padding=1),
BatchNorm2d(256),
ReLU(),
)
self.R6 = ReLU()
self.model7 = Sequential(
# 4.1
Conv2d(in_channels=256, out_channels=512, kernel_size=(3, 3), stride=2, padding=1),
BatchNorm2d(512),
ReLU(),
Conv2d(in_channels=512, out_channels=512, kernel_size=(3, 3), stride=1, padding=1),
BatchNorm2d(512),
ReLU(),
)
self.en3 = Sequential(
Conv2d(in_channels=256, out_channels=512, kernel_size=(1, 1), stride=2, padding=0),
BatchNorm2d(512),
ReLU(),
)
self.R7 = ReLU()
self.model8 = Sequential(
# 4.2
Conv2d(in_channels=512, out_channels=512, kernel_size=(3, 3), stride=1, padding=1),
BatchNorm2d(512),
ReLU(),
Conv2d(in_channels=512, out_channels=512, kernel_size=(3, 3), stride=1, padding=1),
BatchNorm2d(512),
ReLU(),
)
self.R8 = ReLU()
# AAP 自适应平均池化
self.aap = AdaptiveAvgPool2d((1, 1))
# flatten 维度展平
self.flatten = Flatten(start_dim=1)
# FC 全连接层
self.fc = Linear(512, num_classes)
def forward(self, x):
x = self.model0(x)
f1 = x
x = self.model1(x)
x = x + f1
x = self.R1(x)
f1_1 = x
x = self.model2(x)
x = x + f1_1
x = self.R2(x)
f2_1 = x
f2_1 = self.en1(f2_1)
x = self.model3(x)
x = x + f2_1
x = self.R3(x)
f2_2 = x
x = self.model4(x)
x = x + f2_2
x = self.R4(x)
f3_1 = x
f3_1 = self.en2(f3_1)
x = self.model5(x)
x = x + f3_1
x = self.R5(x)
f3_2 = x
x = self.model6(x)
x = x + f3_2
x = self.R6(x)
f4_1 = x
f4_1 = self.en3(f4_1)
x = self.model7(x)
x = x + f4_1
x = self.R7(x)
f4_2 = x
x = self.model8(x)
x = x + f4_2
x = self.R8(x)
# 最后3个
x = self.aap(x)
x = self.flatten(x)
x = self.fc(x)
return x
if __name__ == '__main__':
# 10分类
res18 = Resnet18(10).to('cuda:0')
summary(res18, (3, 224, 224))
10分类训练代码
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
# from torch.utils.tensorboard import SummaryWriter
from mode_resnet18 import Resnet18
# 使用GPU: 需要添加的地方-->模型--损失函数-- .to(device)
# 使用第 0 个GPU, 判断语句,能使用GPU则使用。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 加载数据
# 参数:下载保存路径、train=训练集(True)或者测试集(False)、download=在线(True) 或者 本地(False)、数据类型转换
train_data = torchvision.datasets.CIFAR10("./dataset",
train=True,
download=True,
transform=torchvision.transforms.ToTensor())
test_data = torchvision.datasets.CIFAR10("./dataset",
train=False,
download=True,
transform=torchvision.transforms.ToTensor())
train_len = len(train_data)
val_len = len(test_data)
print("训练数据集合{} = 50000".format(train_len))
print("测试数据集合{} = 10000".format(val_len))
# 格式打包
# 参数:数据、1组几个、下一轮轮是否打乱、进程个数、最后一组是否凑成一组
train_loader = DataLoader(dataset=train_data, batch_size=2, shuffle=True, num_workers=0, drop_last=True)
test_loader = DataLoader(dataset=test_data, batch_size=2, shuffle=True, num_workers=0, drop_last=True)
# 导入网络
tudui = Resnet18(10)
# 使用GPU
tudui = tudui.to(device)
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 使用GPU
loss_fn = loss_fn.to(device)
# 优化器
# 学习率
learning_rate = 1e-4
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
# 记录训练次数
train = 0
# 记录测试次数
val = 0
# 训练轮数
epoch = 1000
# writer = SummaryWriter("logs")
for i in range(epoch):
print()
print("第{}轮训练开始".format(i + 1))
# 训练开关-->针对与过拟合的操作层才有效,例如:Dropout,BatchNorm,etc等
tudui.train(mode=True)
# 准确率总和
acc_ = 0
# 训练
for data in train_loader:
imgs, targets = data
# 使用GPU
imgs = imgs.to(device)
targets = targets.to(device)
# 数据输入模型
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化模型 清零、反向传播、优化器开始优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 累计训练次数
train += 1
# loss现在看不出来,但应该加 loss.item() 这可让其直接显示数值
print("\r训练次数:{},Loss:{}".format(train, loss), end="")
# 准确率
accuracy = (outputs.argmax(1) == targets).sum()
acc_ += accuracy
if train % 4000 == 0:
print("训练次数:{},Loss:{}".format(train, loss))
# writer.add_scalar("train", loss, train)
print()
print("Loss:{}, 准确率:{}".format(loss, acc_/train_len))
# 测试开关
tudui.eval()
# 测试
total_test_loss = 0
acc_val = 0
with torch.no_grad():
for data in test_loader:
imgs, targets = data
# 使用GPU
imgs = imgs.to(device)
targets = targets.to(device)
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 准确率
accuracy_val = (outputs.argmax(1) == targets).sum()
acc_val += accuracy_val
total_test_loss += loss
print("\r测试集的Loss:{}".format(total_test_loss), end="")
print()
print("整体测试集的Loss:{}, 准确率{}".format(total_test_loss, acc_val/val_len))
# writer.add_scalar("val", loss, val)
val += 1
# 每轮保存模型
torch.save(tudui, "tudui_{}.pth".format(i))
print("模型已保存")
# writer.close()
测试代码
去网上随便下载一张图
import torchvision
from resnaet_18.a2 import Resnet18
import torch
from PIL import Image
# 读取图像
img = Image.open("9.jpg")
# 数据预处理
# 缩放
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()])
image = transform(img)
print(image.shape)
# 根据保存方式加载
model = torch.load("tudui_38.pth", map_location=torch.device('cpu'))
# 注意维度转换,单张图片
image1 = torch.reshape(image, (1, 3, 32, 32))
# 测试开关
model.eval()
# 节约性能
with torch.no_grad():
output = model(image1)
print(output)
# print(output.argmax(1))
# 定义类别对应字典
dist = {0: "飞机", 1: "汽车", 2: "鸟", 3: "猫", 4: "鹿", 5: "狗", 6: "青蛙", 7: "马", 8: "船", 9: "卡车"}
# 转numpy格式,列表内取第一个
a = dist[output.argmax(1).numpy()[0]]
img.show()
print(a)
文章出处登录后可见!
已经登录?立即刷新