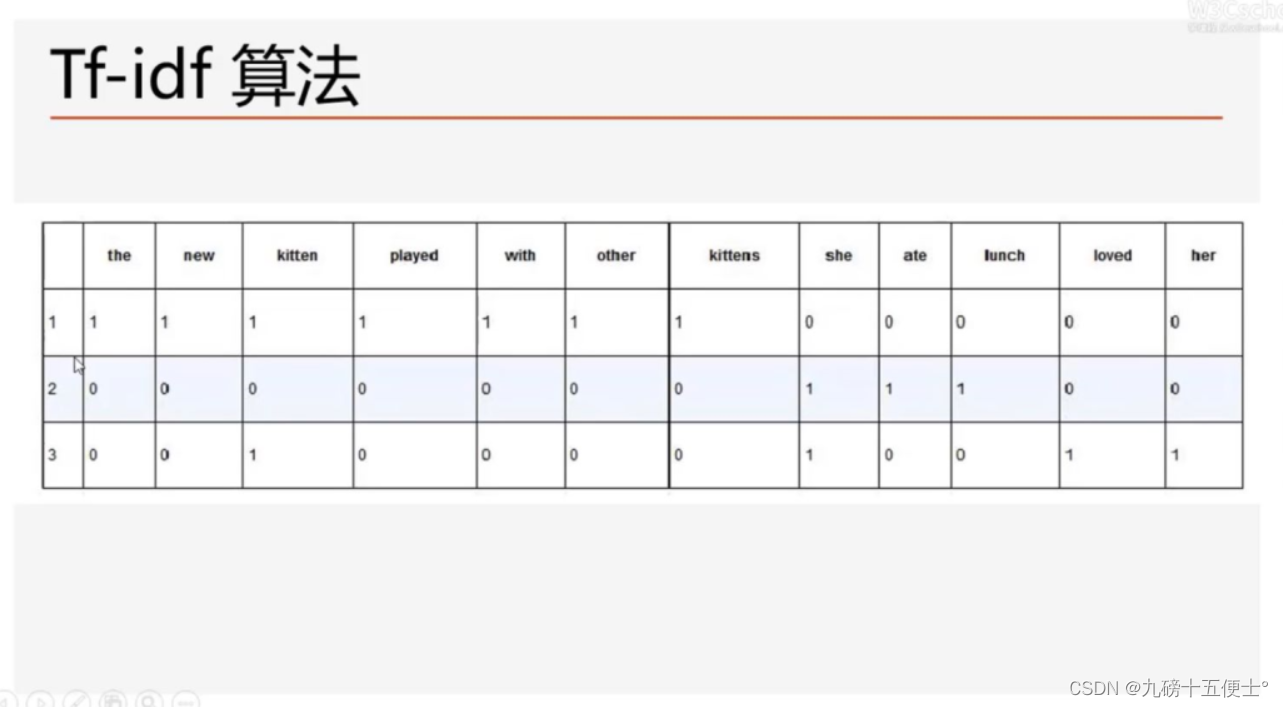
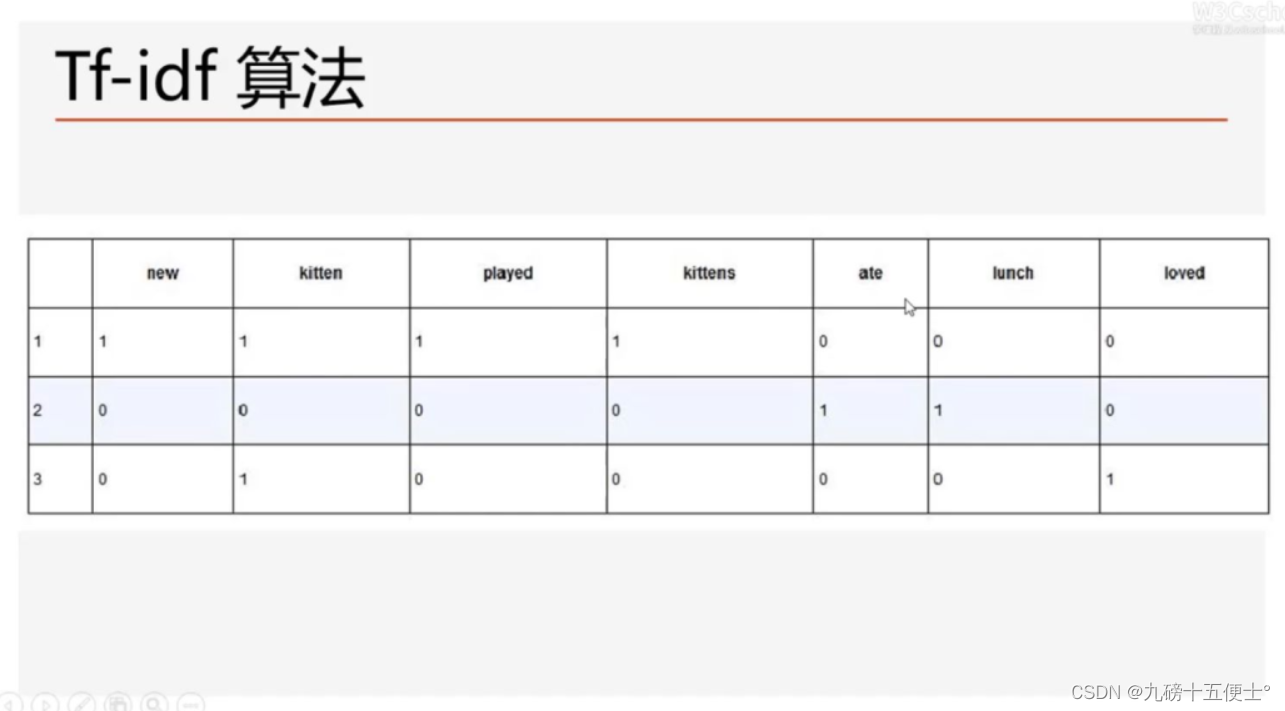
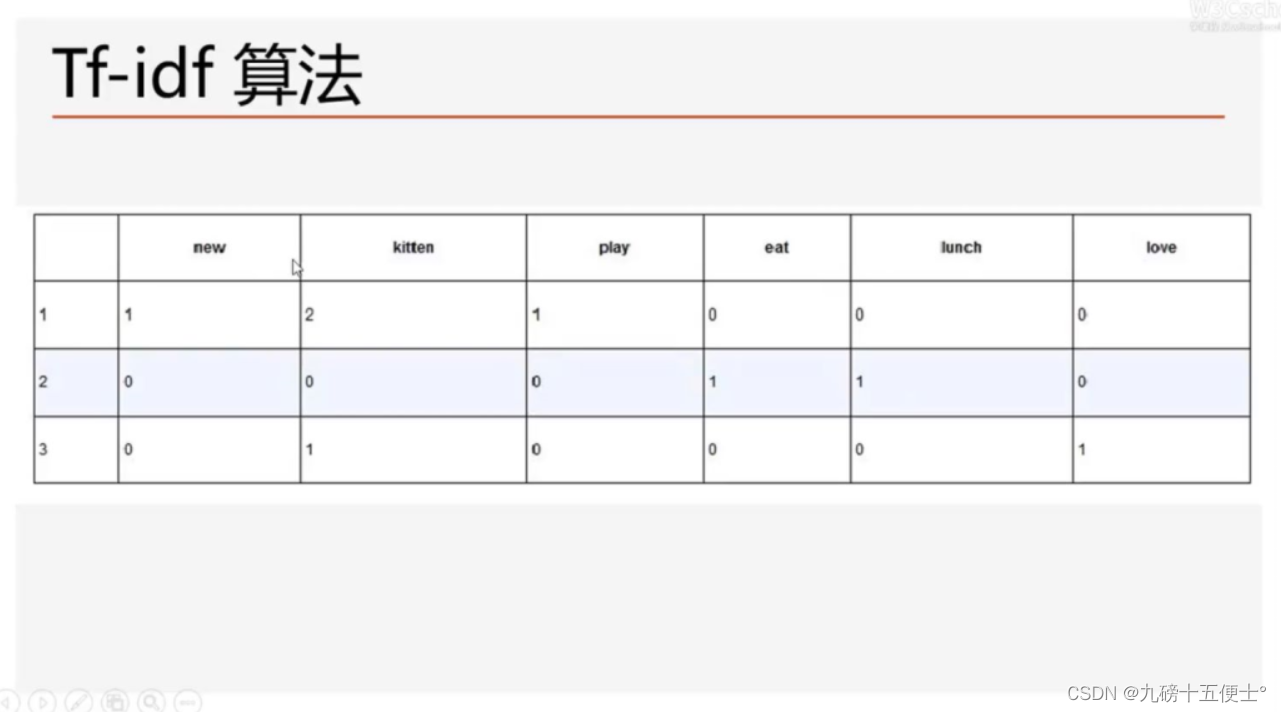
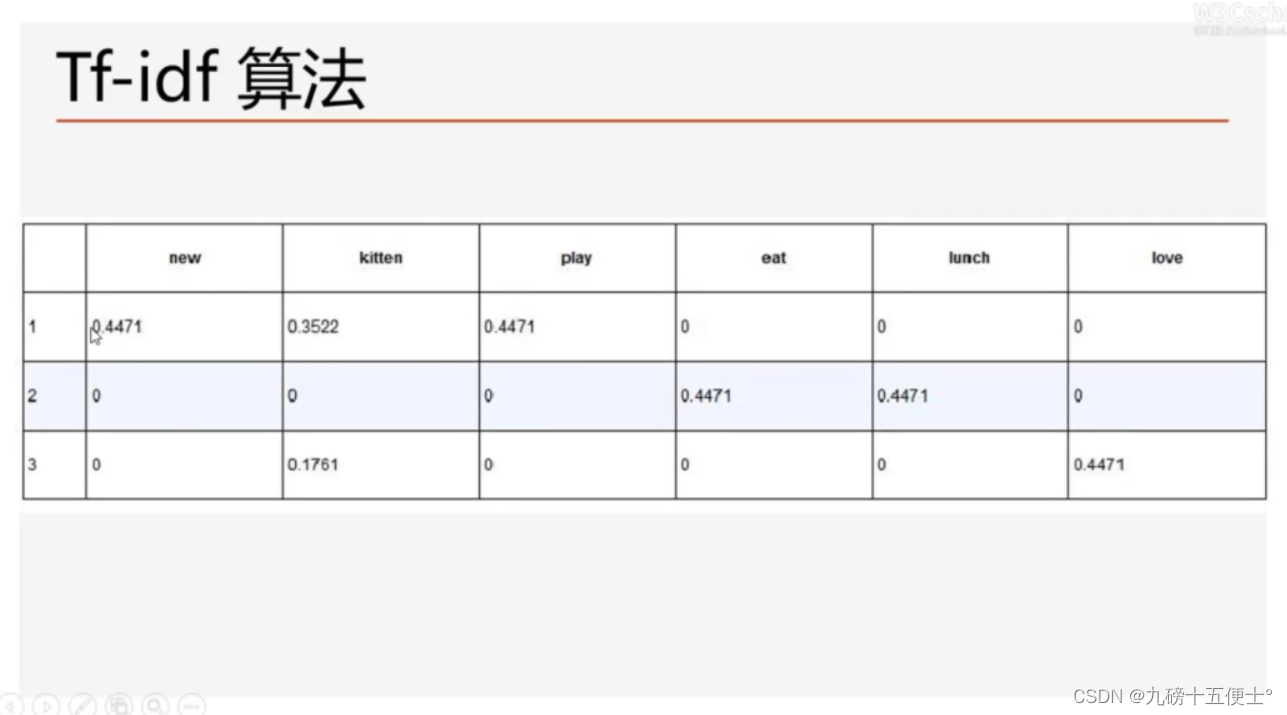
1.Tf-idf算法简介














2.随机森林多分类回顾——鸢尾花数据集
_author_ = '张起凡'
import pandas as pd
import sklearn
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
# 1.tf-idf算法简介
# 2.随机森林多分类回顾
data = pd.read_csv('./数据集/iris.data', header=None,
names=['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'cla'])
# pd.set_option('display.max_columns', 100)
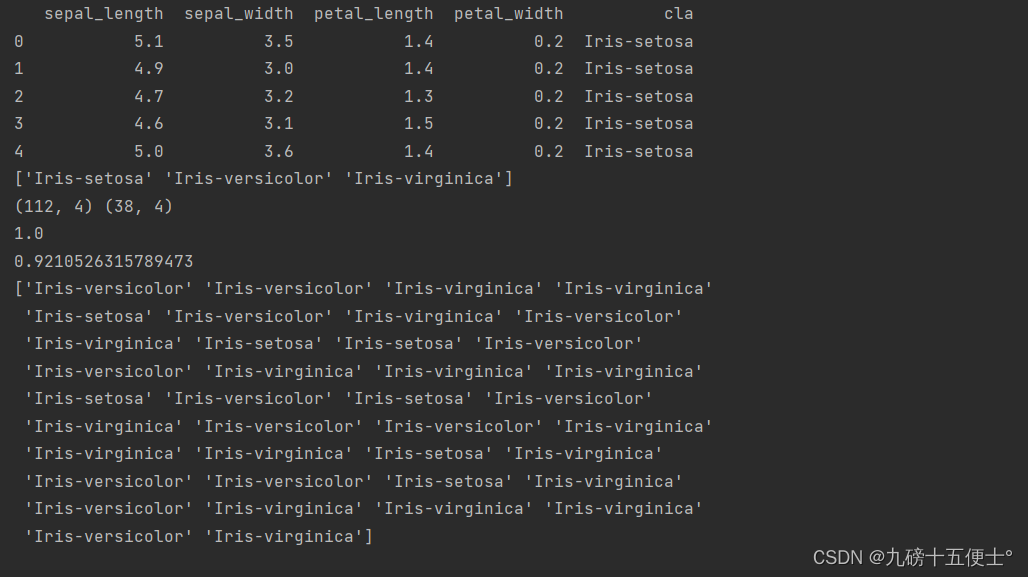
print(data.head())
print(data.cla.unique()) # 共有三类
x = data.iloc[:, :-1] # 取所有行,前四列
y = data.iloc[:, -1] # 取最后一列
x_train, x_test, y_train, y_test = train_test_split(x, y)
print(x_train.shape, x_test.shape)
model = RandomForestClassifier()
model.fit(x_train, y_train)
print(model.score(x_train, y_train)) # 训练集上的正确率
print(model.score(x_test, y_test)) # 测试集上的正确率
print(model.predict(x_test))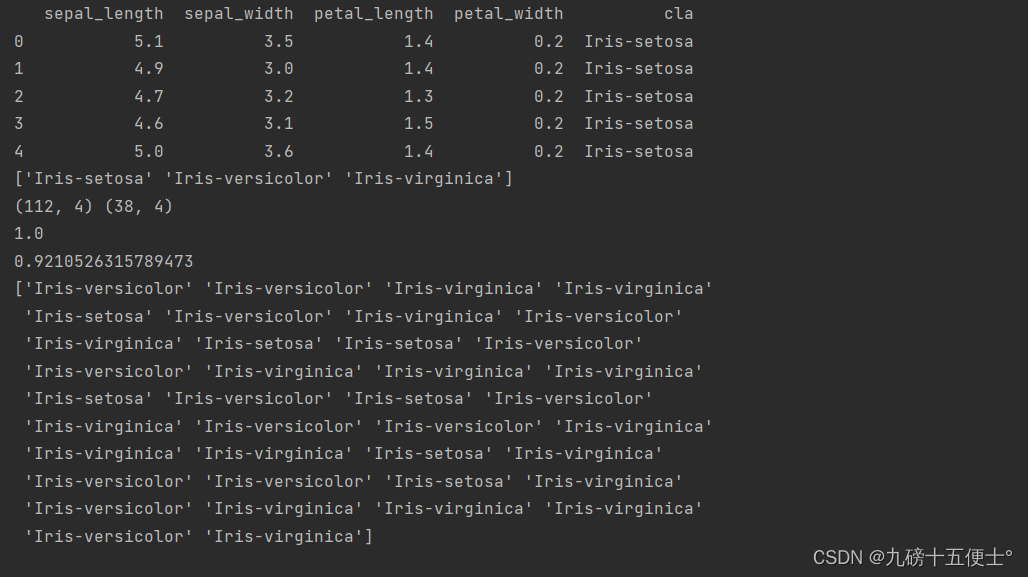
3.航空公司评论数据预处理
# 3.航空公司评论数据预处理
data=pd.read_csv('./数据集/Tweets.csv')
# 核心代码,设置显示的最大列、宽等参数,消掉打印不完全中间的省略号
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth', 1000)
print(data.head())
data=data[['airline_sentiment','text']]
print(data)
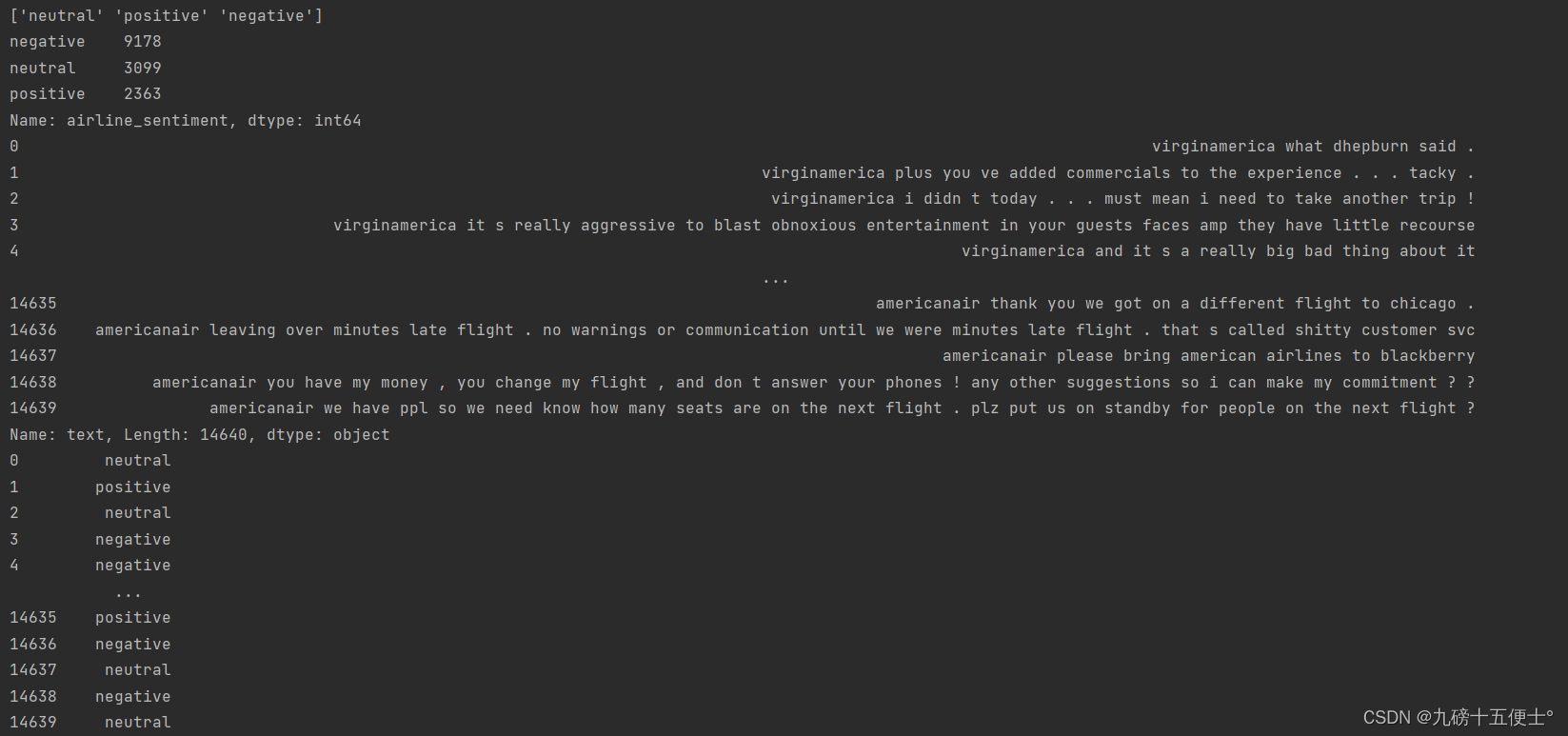
print(data.airline_sentiment.unique()) # 查看评价情绪的种类
print(data.airline_sentiment.value_counts()) # 查看每种评价的计数内容
# 文本规范化
import re # 引入正则表达式
token=re.compile(r'[A-Za-z]+|[!?.:,()]')
def extract_text(text):
new_text=token.findall(text)
new_text=' '.join([x.lower() for x in new_text])
return new_text
# 在某一列上应用函数
x=data.text.apply(extract_text)
print(x)
y=data.airline_sentiment
print(y)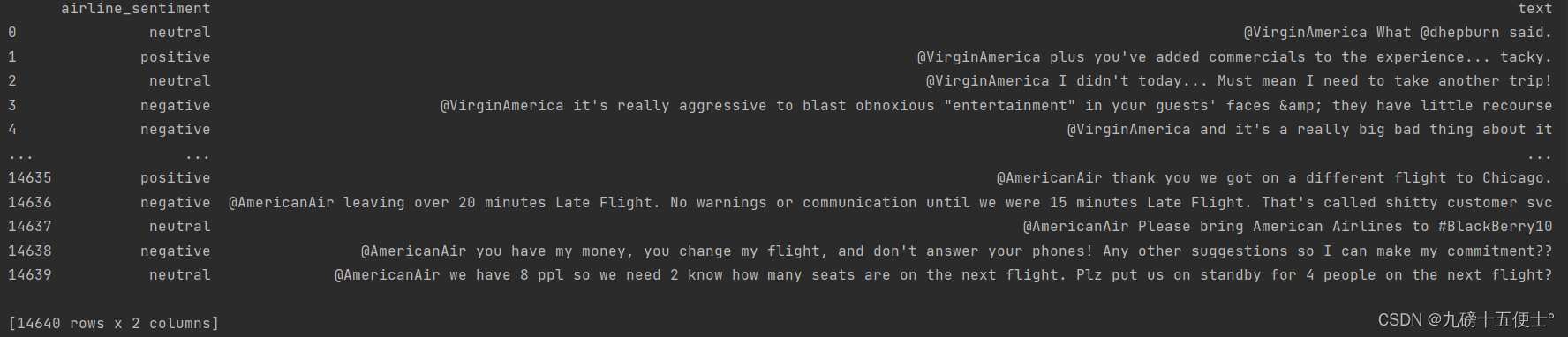
4.航空公司评论数据预处理:
# 4.航空公司评论数据预处理2
# 划分训练数据和测试数据
'''
先划分再向量化
'''
x_train,x_test,y_train,y_test=train_test_split(x,y)
# 文本向量化处理
from sklearn.feature_extraction.text import TfidfVectorizer
vect=TfidfVectorizer(ngram_range=(1,3),stop_words='english',min_df=3)
# 转换数据
x_train_vect=vect.fit_transform(x_train)
print(type(x_train_vect))
x_test_vect=vect.transform(x_test)![]()
5.文本分类的模型实现
# 5.文本分类的模型实现
model=RandomForestClassifier()
model.fit(x_train_vect,y_train)
print(model.score(x_train_vect,y_train))
print(model.score(x_test_vect,y_test))
# 优化目标,抑制过拟合
model2=RandomForestClassifier(n_estimators=500)
model2.fit(x_train_vect,y_train)
print(model2.score(x_train_vect,y_train))
print(model.score(x_test_vect,y_test))
from sklearn.model_selection import GridSearchCV
param={
'max_depth':range(1,500,10),
'criterion':['gini','entropy']
}
grid_s=GridSearchCV(RandomForestClassifier(n_jobs=8),param_grid=param,cv=5)
x_vect=vect.transform(x)
grid_s.fit(x_vect,y)
print(grid_s.best_score_)
print(grid_s.best_params_)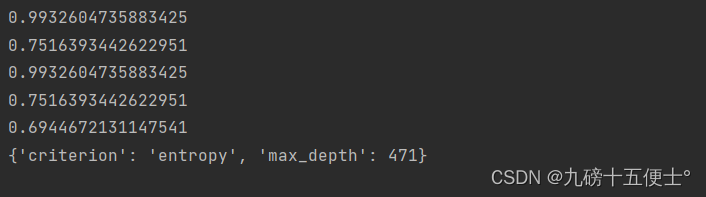
6.朴素贝叶斯算法原理:













7.朴素贝叶斯算法解决文本分类实例
# 6.朴素贝叶斯算法解决文本分类实现
print('——————————————————————————以下为朴素贝叶斯算法——————————————————————————————')
from sklearn.naive_bayes import MultinomialNB
model=MultinomialNB(alpha=0.0001)
model.fit(x_train_vect,y_train)
print('在训练集上得分')
print(model.score(x_train_vect,y_train))
print('在测试集上得分')
print(model.score(x_test_vect,y_test))
# 利用循环找到较好的参数取值
test_score=[]
alpht_=np.linspace(0.00001,0.01,100)
for a in alpht_:
model=MultinomialNB(alpha=a)
model.fit(x_train_vect,y_train)
test_score.append(model.score(x_test_vect,y_test))
max_score=max(test_score)
print('最高得分为:',max_score)
index=test_score.index(max_score)
print('下标为:',index)
print('最佳参数为:',alpht_[index])
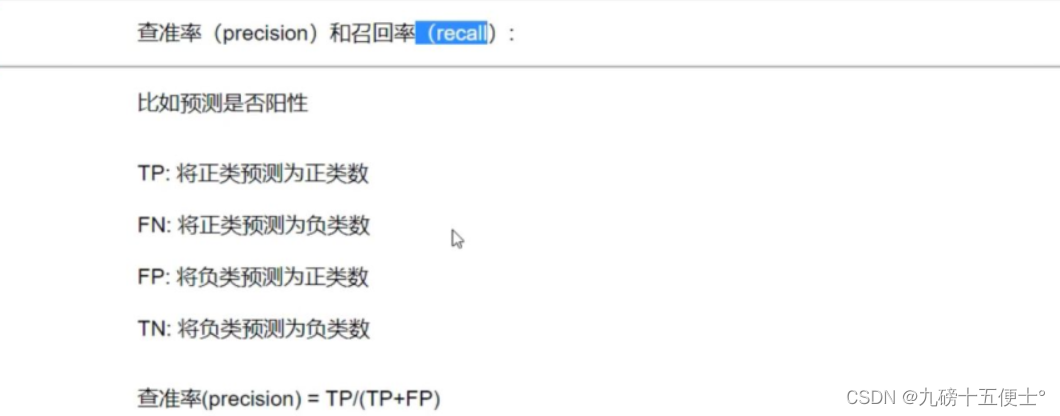
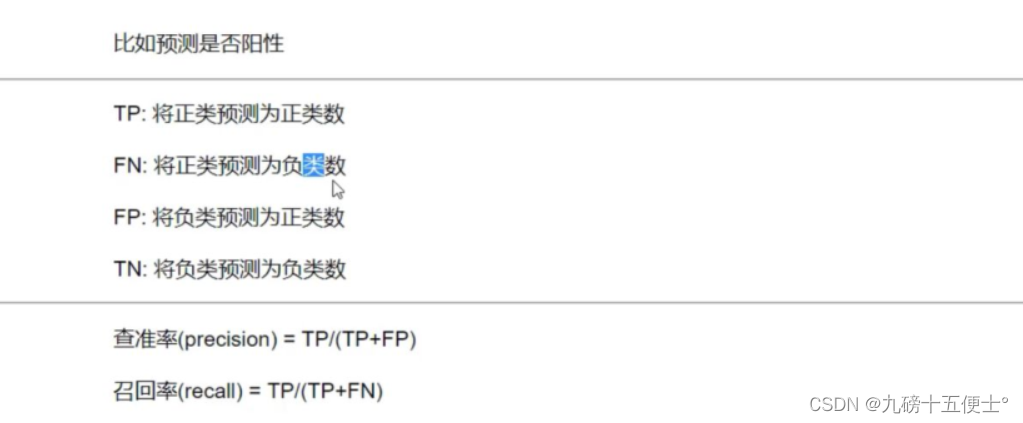
8.模型的评价:查准率,召回率,F1-score及混淆矩阵
from sklearn.metrics import classification_report
best_alpha=alpht_[index]
model=MultinomialNB(alpha=best_alpha)
model.fit(x_train_vect,y_train)
pred=model.predict(x_test_vect) # 进行预测
# print(pred)
import pprint
print(classification_report(y_test,pred))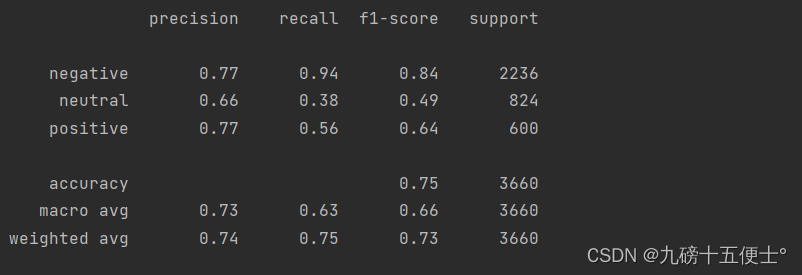

混淆矩阵:

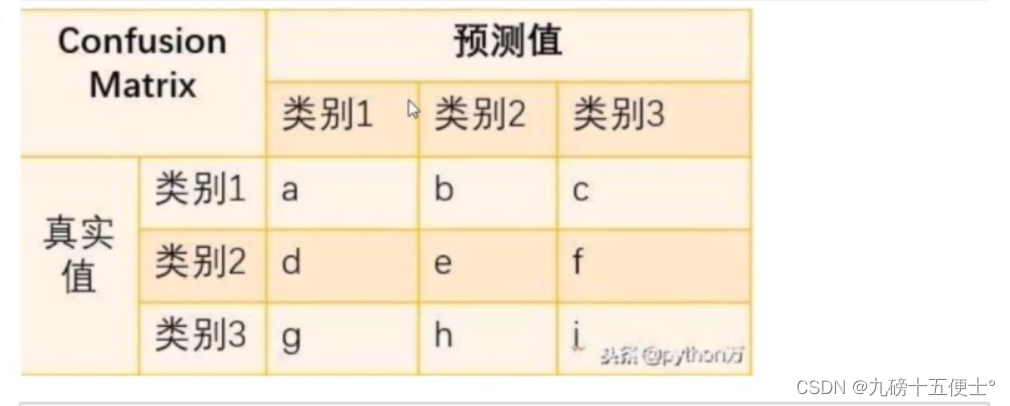
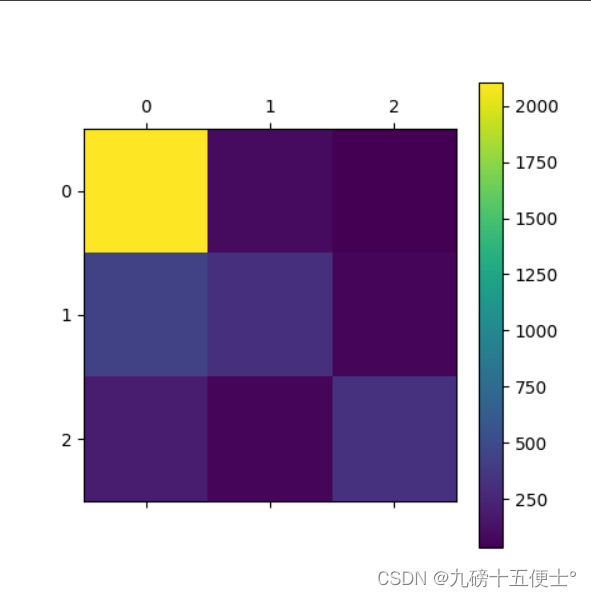
# 还可以使用混淆矩阵
from sklearn.metrics import confusion_matrix
cm=confusion_matrix(y_test,pred)
print(cm)
import matplotlib.pyplot as plt
plt.matshow(cm)
plt.colorbar()
plt.show() 
9.完整代码:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
_author_ = '张起凡'
import numpy as np
import pandas as pd
import sklearn
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
# 1.tf-idf算法简介
# 2.随机森林多分类回顾
data = pd.read_csv('./数据集/iris.data', header=None,
names=['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'cla'])
# pd.set_option('display.max_columns', 100)
print(data.head())
print(data.cla.unique()) # 共有三类
x = data.iloc[:, :-1] # 取所有行,前四列
y = data.iloc[:, -1] # 取最后一列
x_train, x_test, y_train, y_test = train_test_split(x, y)
print(x_train.shape, x_test.shape)
model = RandomForestClassifier()
model.fit(x_train, y_train)
print(model.score(x_train, y_train)) # 训练集上的正确率
print(model.score(x_test, y_test)) # 测试集上的正确率
print(model.predict(x_test))
# 3.航空公司评论数据预处理
data = pd.read_csv('./数据集/Tweets.csv')
# 核心代码,设置显示的最大列、宽等参数,消掉打印不完全中间的省略号
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth', 1000)
print(data.head())
data = data[['airline_sentiment', 'text']]
print(data)
print(data.airline_sentiment.unique()) # 查看评价情绪的种类
print(data.airline_sentiment.value_counts()) # 查看每种评价的计数内容
# 文本规范化
import re # 引入正则表达式
token = re.compile(r'[A-Za-z]+|[!?.:,()]')
def extract_text(text):
new_text = token.findall(text)
new_text = ' '.join([x.lower() for x in new_text])
return new_text
# 在某一列上应用函数
x = data.text.apply(extract_text)
print(x)
y = data.airline_sentiment
print(y)
# 4.航空公司评论数据预处理2
# 划分训练数据和测试数据
'''
先划分再向量化
'''
x_train, x_test, y_train, y_test = train_test_split(x, y)
# 文本向量化处理
from sklearn.feature_extraction.text import TfidfVectorizer
vect = TfidfVectorizer(ngram_range=(1, 3), stop_words='english', min_df=3)
# 转换数据
x_train_vect = vect.fit_transform(x_train)
print(type(x_train_vect))
x_test_vect = vect.transform(x_test)
# 5.文本分类的模型实现,模型训练太慢,注释掉了
# model=RandomForestClassifier()
# model.fit(x_train_vect,y_train)
# print(model.score(x_train_vect,y_train))
# print(model.score(x_test_vect,y_test))
# # 优化目标,抑制过拟合
# model2=RandomForestClassifier(n_estimators=500)
# model2.fit(x_train_vect,y_train)
# print(model2.score(x_train_vect,y_train))
# print(model.score(x_test_vect,y_test))
# from sklearn.model_selection import GridSearchCV
# param={
# 'max_depth':range(1,500,10),
# 'criterion':['gini','entropy']
# }
# grid_s=GridSearchCV(RandomForestClassifier(n_jobs=8),param_grid=param,cv=5)
# x_vect=vect.transform(x)
# grid_s.fit(x_vect,y)
# print(grid_s.best_score_)
# print(grid_s.best_params_)
# 6.朴素贝叶斯算法解决文本分类实现
print('——————————————————————————以下为朴素贝叶斯算法——————————————————————————————')
from sklearn.naive_bayes import MultinomialNB
model = MultinomialNB(alpha=0.0001)
model.fit(x_train_vect, y_train)
print('在训练集上得分')
print(model.score(x_train_vect, y_train))
print('在测试集上得分')
print(model.score(x_test_vect, y_test))
# 利用循环找到较好的参数取值
test_score = []
alpht_ = np.linspace(0.00001, 0.01, 100)
for a in alpht_:
model = MultinomialNB(alpha=a)
model.fit(x_train_vect, y_train)
test_score.append(model.score(x_test_vect, y_test))
max_score = max(test_score)
print('最高得分为:', max_score)
index = test_score.index(max_score)
print('下标为:', index)
print('最佳参数为:', alpht_[index])
# 7.模型的评价
from sklearn.metrics import classification_report
best_alpha = alpht_[index]
model = MultinomialNB(alpha=best_alpha)
model.fit(x_train_vect, y_train)
pred = model.predict(x_test_vect) # 进行预测
# print(pred)
import pprint
print(classification_report(y_test, pred))
# 还可以使用混淆矩阵
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, pred)
print(cm)
import matplotlib.pyplot as plt
plt.matshow(cm)
plt.colorbar()
plt.show()
文章出处登录后可见!
已经登录?立即刷新