文章目录
- TOPSIS简介
- 方法和原理
- 数学定义
- 数学语言描述
- 现实案例
- 正负理想解
- 定义
- 实例
- 量纲
- TOPSIS法的算法步骤
- 1.用向量规范化的方法求得规范决策矩阵
- 2.构成加权规范阵C=(c~ij~)~m*n~
- 3.确定正负理想解的距离
- 4.计算各方案到正理想解与负理想解的距离
- 5.计算各方案的综合评价指数
- 6.排列方案的优劣次序
- 实战应用
- 例题
- 解答步骤
- **数据的预处理**
- **属性值线性规划归一化**
- MATLAB代码(建议对照上方 “TOPSIS法的算法步骤” 查看)
- 完整代码
TOPSIS简介
客观评价方法中的一种,亦称为理想解法,是一种有效的多指标评价方法。这种方法通过构造评价问题的正理想解和负理想解,即各指标的最优解和最劣解,通过计算每个方案到理想方案的相对贴近度,即靠近止理想解和远离负理想解的程度,来对方案进行排序,从而选出最优方案。
方法和原理
数学定义
数学语言描述
设多属性决策方案集为D={d1,d2,…,dm},衡量方案优劣的属性变量为x1,…,xn,,这时方案集D中的每个方案di( i= 1,…,m )的n个属性值构成的向量是[Ai1,…,Ain],它作为n维空间中的一个点,能唯一地表征方案di。
现实案例
例如评价经济的发展水平
d1代表山东,d2代表江苏,d3代表北京……就是一共有m个待评价方案。
x1是绿化面积,x2是人均GDP,x3是经济总量……共有n个属性值。
其中能够展现山东的经济发展水平有绿化面积、人均GDP、经济总量等n个指标。而Ai1就是山东绿化的总面积、Ai2为山东GDP总量……
正负理想解
定义
正理想解C是一个方案集D中并不存在的虚拟的最佳方案,它的每个属性值都是决策矩阵中该属性的最好值;而负理想解C0则是虚拟的最差方案,它的每个属性值都是决策矩阵中该属性的最差值。在n维空间中,将方案集D中的各备选方案di与正理想解C和负理想解C0的距离进行比较,既靠近正理想解又远离负理想解的方案就是方案集D中的最佳方案;并可以据此排定方案集D中各备选方案的优先序。
实例
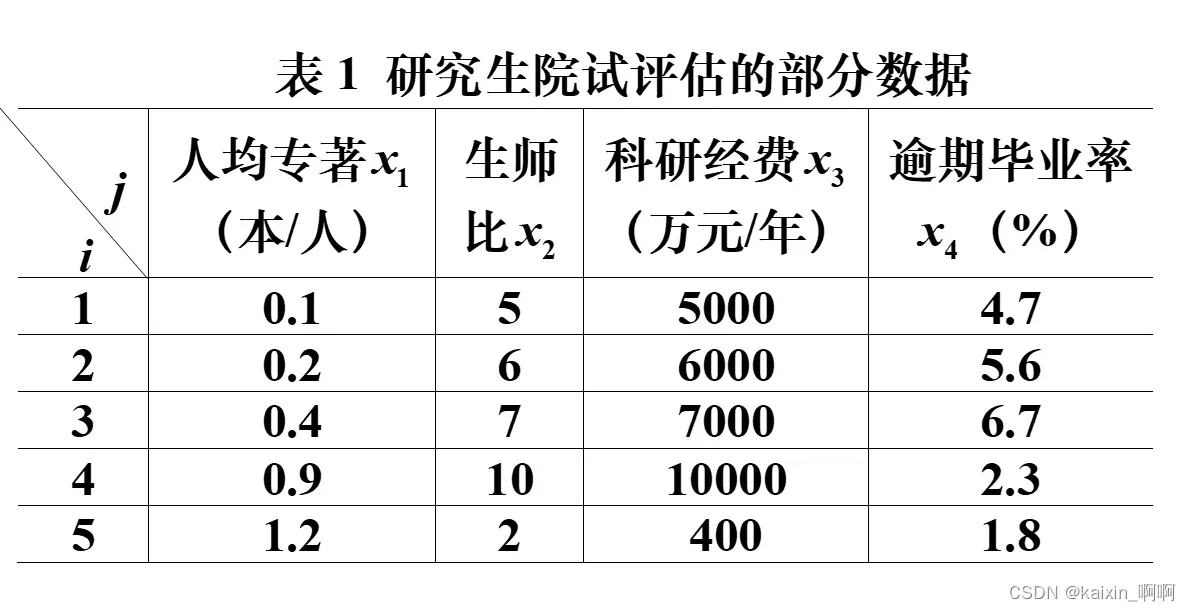
评价表中哪五个研究生院更好,可以虚构一个最好的研究生院标准,该虚构的研究生院的数据全为最优值,例如:
虚构研究生院6,其中它的人均专著x61为1.2,生师比x62为5(生师比为学生和老师的比值,它的值必须保持适度,适当的生师比可以促进老师和学生良好的互动,该值过高过低都不好),科研经费x63为10000,预期毕业率x64为1.8。此时,研究生院6就是正理想解C*,同理构建虚拟的最差方案负理想解C0。
| – | x1 | x2 | x3 | x4 |
|---|---|---|---|---|
| C*(正理想解) | 1.2 | 5 | 10000 | 1.8 |
| C0(负理想解) | 0.1 | 10 | 400 | 6.7 |
量纲
确定好正负理想解后,就可以以此来判断判断不同研究生院的优劣。下面开始描述每个研究生院与正负理想解的距离。
那么距离应该怎么算呢?当量纲不同时,方案不同数据的波动会很大,因此在计算距离时首先要排除量纲的影响,进行非量纲化。
非量纲化定义
多属性决策与评估的困难之一是属性间的不可公度性,即在属性值表中的每一列数具有不同的单位(量纲)。即使对同一属性,采用不同的计量单位,表中的数值也就不同。在用各种多属性决策方法进行分析评价时,需要排除量纲的选用对决策或评估结果的影响,这就是非量纲化。
TOPSIS法的算法步骤
1.用向量规范化的方法求得规范决策矩阵
设多属性决策问题的决策矩阵A=(aij )m*n,规范化决策矩阵B=(bij)m*n,其中
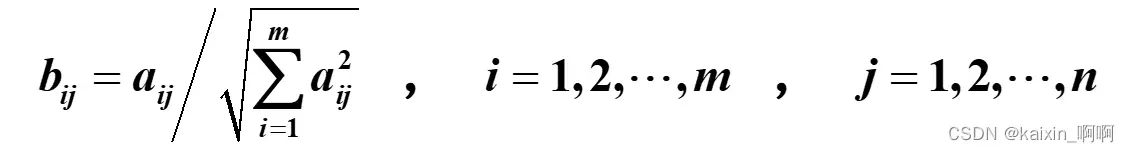
2.构成加权规范阵C=(cij)m*n
设由决策人给定各属性的权重向量为 w=[w1,w2,…,wn] ,
则 cij = wj*bij
其中 i=1,2,…,m, j =1,2,…,n.
在评价过程中,每项评价标准占比不同,让重要的指标影响大一点,不重要的指标影响小一点。
类似于成绩的计算,比较重要的语数英总分数高一些,其他副科的总分数低一些。
3.确定正负理想解的距离
理想解属性大致可以分为效益型、成本型和区间型三种,其中
正理想解:

效益最大值和成本最小值,当属性为区间型的时候要判断在哪个区间最佳。
负理想解:

效益最小值和成本最大值
4.计算各方案到正理想解与负理想解的距离
备选方案di到正理想解的距离为:
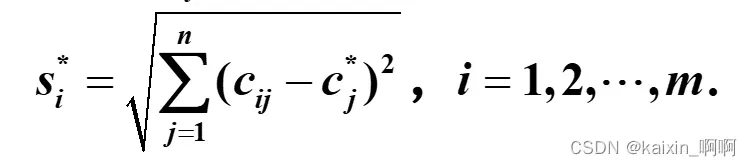
备选方案di到负理想解的距离为:
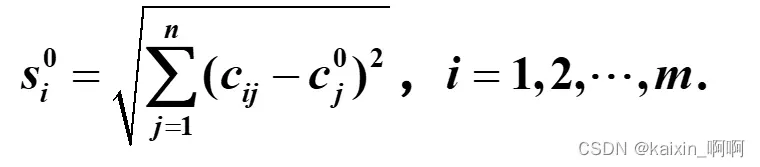
可类比两点间距离公式,该距离为n维空间内的距离
5.计算各方案的综合评价指数
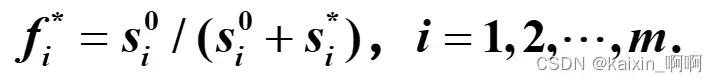
计算综合评价指数公式的分子为方案到负理想解的距离,分母为为方案到负理想解的距离与方案到正理想解的距离之和,所以综合评价指数越大越好。
6.排列方案的优劣次序
按综合评价指数由大到小排列方案的优劣次序即可
实战应用
例题
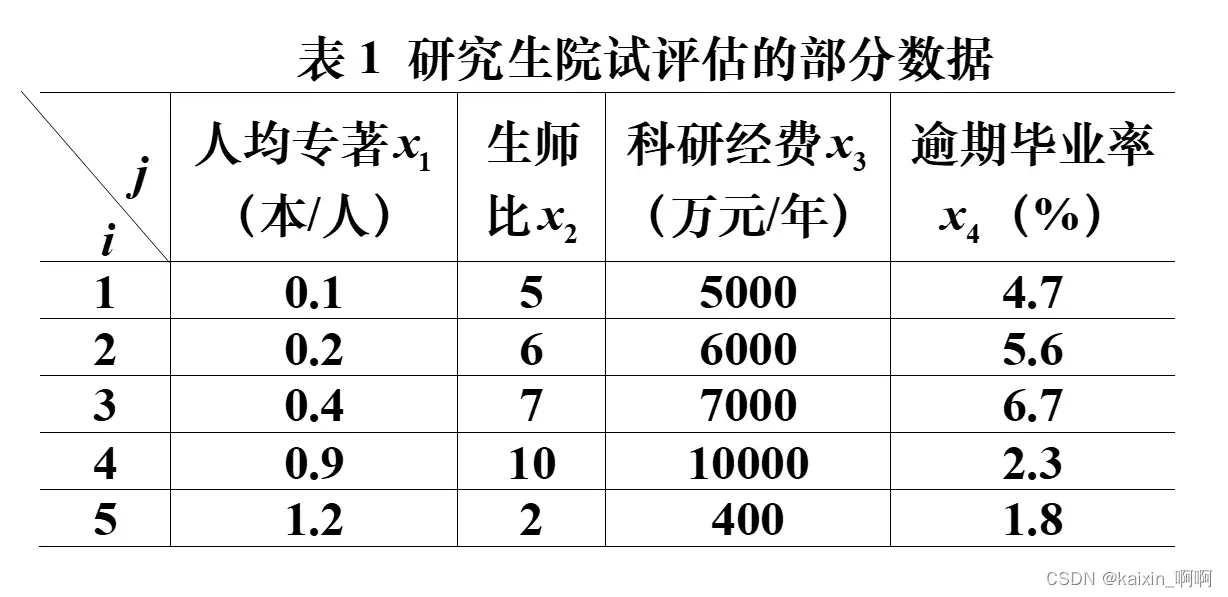
研究生院试评估
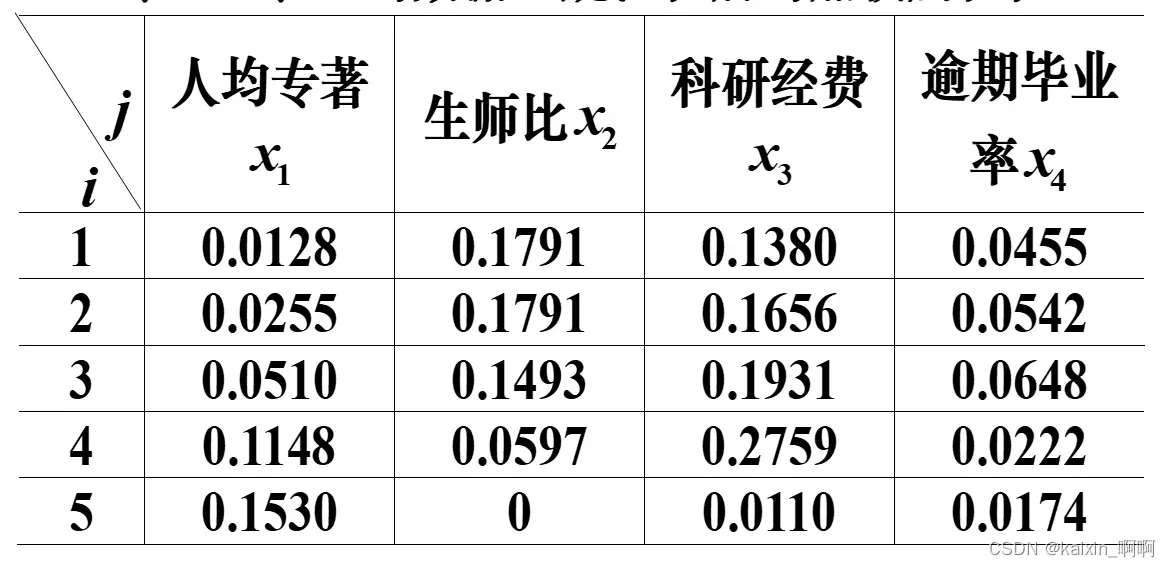
为了客观地评价我国研究生教育的实际状况和各研究生院的教学质量,国务院学位委员会办公室组织过一次研究生院的评估。为了取得经验,先选5所研究生院,收集有关数据资料进行了试评估,表1是所给出的部分数据。
解答步骤
数据的预处理
数据的预处理又称属性值的规范化
属性值具有多种类型,包括效益型、成本型和区间型等。这三种属性,效益型属性越大越好,成本型属性越小越好,区间型属性是在某个区间最佳。
判断每个属性的数据是越大越好还是越小越好,当属性为区间型的时候判断在哪个区间最佳。
判断完成以后将它们进行规范化处理。
数据规范化处理的作用
1.属性值有多种类型,上述三种属性放在同一个表中不便于直接从数值大小判断方案的优劣,因此需要对数据进行预处理,使得表中任一属性下性能越优的方案变换后的属性值越大。
2.非量纲化,多属性决策与评估的困难之一是属性间的不可公度性,即在属性值表中的每一列数具有不同的单位(量纲)。即使对同一属性,采用不同的计量单位,表中的数值也就不同。在用各种多属性决策方法进行分析评价时,需要排除量纲的选用对决策或评估结果的影响,这就是非量纲化。
3.归一化,属性值表中不同指标的属性值的数值人小差别很大,为了直观,更为了便于采用各种多属性决策与评估方法进行评价,需要把属性值表中的数值归一化,即把表中数值均变换到[0,1]区间上。
即将上述三种属性全部转化为效益型,这个数值分布在[0,1]区间上,该值越大越好。
属性值线性规划归一化
为了使每个属性变换后的最优值为1且最差值为0,可以进行标准0-1变换。
**1.对效益型属性xj,令
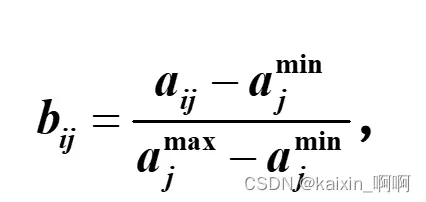
当aij为最小值时,bij为0,当aij为最大值时,bij为1。**
2.对成本型属性xj,
计算公式可套用效益型的公式,在求正负理想解的时候记得要颠倒一下。
**3.对区间型属性xj,设给定的最优属性区间为[
,
],
为无
法容忍下限,为无法容忍上限,则
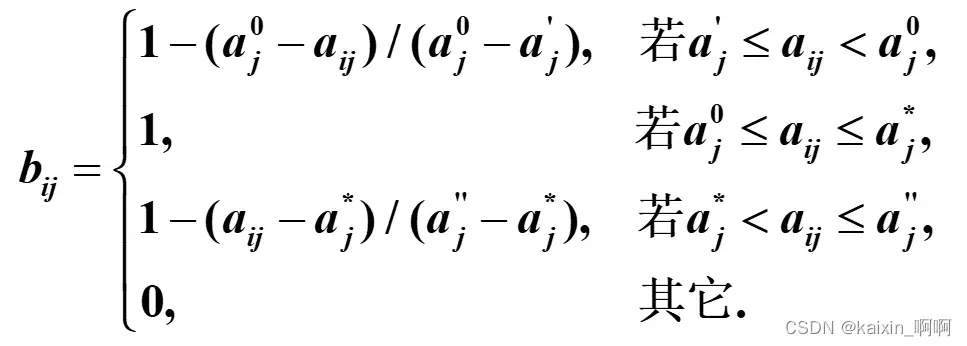
例如例题中的生师比,它最好的区间应为[5,6],最差应不低于2,高于12,当该属性值在最有区间时为1,当超过或等于能容忍上下限时为0。**
MATLAB代码(建议对照上方 “TOPSIS法的算法步骤” 查看)
注:以下并非C语言
clc,clear
% clc:清除命令窗口的内容,对工作环境中的全部变量无任何影响
% clear:清除工作空间的所有变量
a=[0.1 5 5000 4.7
0.2 6 6000 5.6
0.4 7 7000 6.7
0.9 10 10000 2.3
1.2 2 400 1.8];
% 输入数据
[m,n]=size(a);
%这行代码的作用是获取矩阵a的维度信息,其中m表示a的行数,n表示a的列数。其中,size函数返回的是一个含有两个元素的向量,第一个元素表示矩阵的行数,第二个元素表示矩阵的列数。因此,在这个代码中,m和n就被赋值为了矩阵a的行数和列数。在后续的代码中,可以使用这两个变量来控制循环等操作。
% @是用于定义函数句柄的操作符。函数句柄既是一种变量,可以用于传参和赋值;也是可以当做函数名一样使用,该步骤类似于C语言中的构造函数。
x2=@(qujian,lb,ub,x)(1-(qujian(1)-x)./(qujian(1)-lb)).*(x>=lb&x<qujian(1))+...
(x>=qujian(1)&x<=qujian(2))+(1-(x-qujian(2))./(ub-qujian(2))).*...
(x>qujian(2)&x<=ub);
qujian=[5,6];lb=2;ub=12;
a(:,2)=x2(qujian,lb,ub,a(:,2));
%该函数可以实现将区间型属性转换为效益型属性的,实现下图所示公式
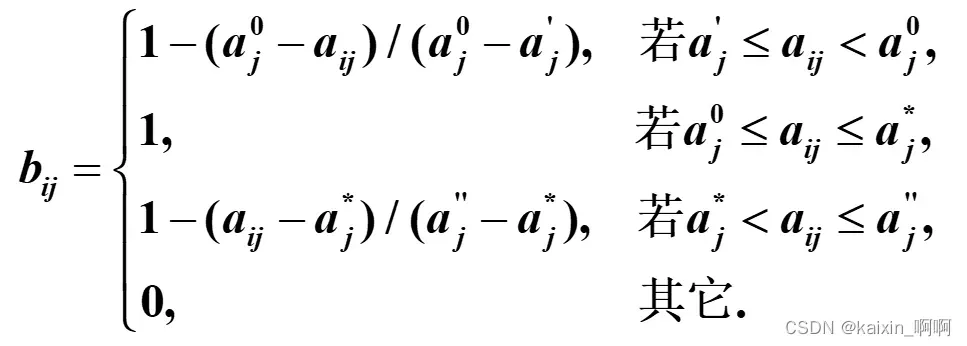
注:如果 (x>=qujian(1)&x<=qujian(2)) 成立,结果为真,值为1;如果 x 的值没有出现在上述区间,结果为假,值为0。
加权处理
for j=1:n
b(:,j)=a(:,j)/norm(a(:,j));%向量规范化
end
实现该式:
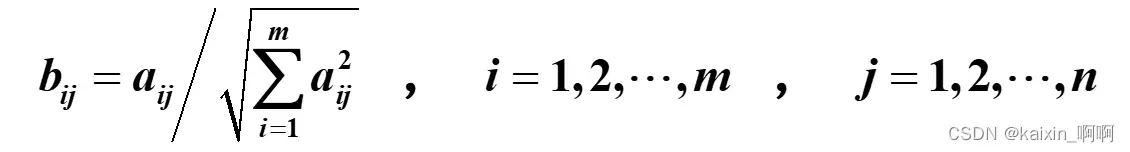
%设权向量为w=[0.2,0.3,0.4,0.1]
w=[0.2 0.3 0.4 0.1];
c=b.*repmat(w,m,1);%求出加权规范阵
至此步骤2完成,得出加权的向量规范化属性矩阵
正负理想解
cstar=max(c);%求正理想解
cstar(4)=min(c(:,4))%属性4为成本型,与效益型相反
c0=min(c);%求负理想解
c0(4)=max(c(:,4))%属性4为成本型,与效益型相反
for i=1:m
sstar(i)=norm(c(i,:)-cstar);%求到正理想解的距离
s0(i)=norm(c(i,:)-c0);%求到负理想解的距离
end
按顺序依次实现
求到正理想解的距离:
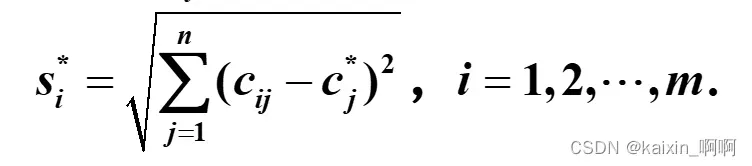
求到负理想解的距离:
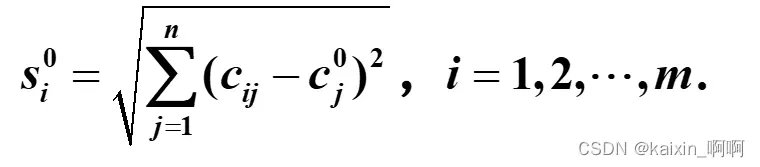
f=s0./(sstar+s0);
[sf,ind]=sort(f,'descend') %求排序结果
% "ascend"时,进行升序排序,为"descend "时,进行降序排序
计算各方案的综合评价指数:
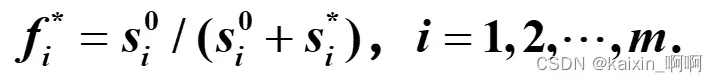
得出结果
各方案的从优到劣的次序为4,3,2,1,5
完整代码
clc,clear
% clc:清除命令窗口的内容,对工作环境中的全部变量无任何影响
% clear:清除工作空间的所有变量
a=[0.1 5 5000 4.7
0.2 6 6000 5.6
0.4 7 7000 6.7
0.9 10 10000 2.3
1.2 2 400 1.8];
% 输入数据
[m,n]=size(a);
x2=@(qujian,lb,ub,x)(1-(qujian(1)-x)./(qujian(1)-lb)).*(x>=lb&x<qujian(1))+...
(x>=qujian(1)&x<=qujian(2))+(1-(x-qujian(2))./(ub-qujian(2))).*...
(x>qujian(2)&x<=ub);
qujian=[5,6];lb=2;ub=12;
a(:,2)=x2(qujian,lb,ub,a(:,2));%对属性2进行变换
for j=1:n
b(:,j)=a(:,j)/norm(a(:,j));%向量规范化
end
w=[0.2 0.3 0.4 0.1];
c=b.*repmat(w,m,1);%求加权矩阵
cstar=max(c);%求正理想解
cstar(4)=min(c(:,4))%属性4为成本型
c0=min(c);%求负理想解
c0(4)=max(c(:,4))%属性4为成本型的
for i=1:m
sstar(i)=norm(c(i,:)-cstar);%求到正理想解的距离
s0(i)=norm(c(i,:)-c0);%求到负理想解的距离
end
f=s0./(sstar+s0);
[sf,ind]=sort(f,'descend') %求排序结果
% "ascend"时,进行升序排序,为"descend "时,进行降序排序
负理想解
c0(4)=max(c(:,4))%属性4为成本型的
for i=1:m
sstar(i)=norm(c(i,:)-cstar);%求到正理想解的距离
s0(i)=norm(c(i,:)-c0);%求到负理想解的距离
end
f=s0./(sstar+s0);
[sf,ind]=sort(f,'descend') %求排序结果
% "ascend"时,进行升序排序,为"descend "时,进行降序排序
文章出处登录后可见!