Paper name
Which Tasks Should Be Learned Together in Multi-task Learning?
Paper Reading Note
URL: https://arxiv.org/pdf/1905.07553.pdf
Official website: http://taskgrouping.stanford.edu/
TL;DR
- ICML 2020 文章,研究网络尺寸、数据集尺寸对于多任务训练的影响,研究不同任务间的影响,并提出了一种给网络分配任务的框架,用于在给定有限计算量的情况下达到最优预测精度
Introduction
-
很多领域都有 multi-task learning 的需求来降低 inference time,尤其是机器人和自动驾驶领域。将多个训练任务整合有提升准确性、提升数据效率、降低训练测试时间等优点,但是由于 negative transfer 现象多任务模型的预测质量一般会受到影响,这种现象的原因可能是不同任务需要不同的学习率、一个任务主导了训练、不同任务的梯度干扰导致基于总损失的模型优化更困难
-
本文研究如何在尽量降低 inference time 的条件下提升各任务的精度,包括如下尝试:
- 将竞争性任务分配到不同的网络,配合性任务分配到相同网络
- 在训练中增加一些测试阶段不用的辅助任务,用于增加其他任务的精度
-
比如在下图中基于 Taskonomy 数据集的实验中,在给定的 2.5 unit 的模型计算下,最佳的模型设计方式是基于 1 unit 模型 A 来预测 segmentation、depth、normal,另外一个 1 unit 模型 B 来预测 keypoint、edge、normal,然后最后 0.5 unit 模型 C 来单独预测 normal,其中 A、B 模型中的 normal 分支主要是为了提升其他任务的精度,最后 C 模型的 normal 精度才是最高的。这种设计方案的精度高于 five-in-one 的多任务结构且高于每个模型分别训练的精度
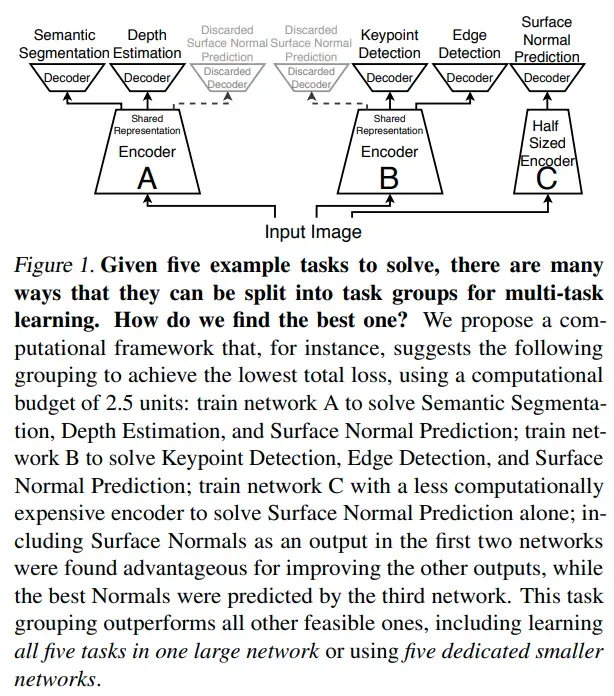
-
本文主要贡献
- 研究网络尺寸、数据集尺寸对于多任务训练的影响,研究不同任务间的影响
- 提出了一种给网络分配任务的框架,用于在给定有限计算量的情况下达到最优预测精度
Prior work
- 研究任务间的关系
- 多任务 loss weighting
- 对齐梯度
- 基于不确定度
- 平衡梯度影响
- 对比不同的 loss weighting 策略
- 多任务学习的网络架构
Dataset/Algorithm/Model/Experiment Detail
实现方式
数据集
- 使用 Taskonomy 数据集,600 个建筑 3d 扫描得到,4 million 样本数,3.9 million 训练集,50k val 数据集,50k test 数据集。训练集与测试集中的建筑不同源
任务设置
- task set1 包含五个任务
- 语义分割(semantic)
- 深度估计(3D)
- 表面法向量预测(3D)
- SURF 关键点检测(2D)
- Canny 边缘检测(2D)
- task set2 包含另外五个任务
- 自动编码机
- 表面法向量预测(3D)
- 遮挡边缘
- 重着色
- 主曲率
- 语义分割用 cross-entropy 损失,其他任务用 L1 损失
网络结构
-
使用基于 Xception 改造的 encoder-decoder 结构
-
16.5 million 参数量,6.4 billion 乘加计算量
-
256×256 输入尺寸
-
定义了一个小尺寸网络 Xception17,只有 17 层,middle flow layers 由 728 降低为 512 channel:4 million 参数量,2.28 billion 乘加计算量
-
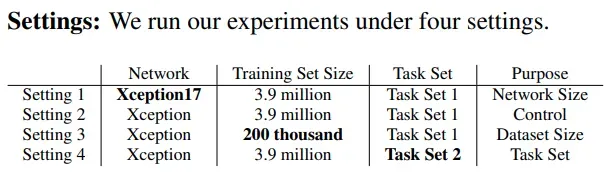
setting 1 用于测试网络尺寸的影响
-
setting 2 用于是 control 组
-
setting 3 用于测试数据集尺寸影响
-
setting 4 用于测试任务间的关系
训练细节
- pytorch、apex fp16 加速
- loss 使用 unweighted mean
- 初始学习率 0.1,training loss 停止下降了就降低一半;训练到 val 数据集上的 validation loss 停止降低
对比实验设计
- Standard Network Time (SNT) 代表标准的网络运行时间
- 训练 1-SNT 网络用于 5 个任务的
个可行的子任务组合
- 5 个单独任务网络 (0.5 SNT)
- 10 个 2 任务网络
- 10 个 3 任务网络
- 5 个 4 任务网络
- 1 个 5 任务网络
实验结果
多任务间关系(set1,小模型)
-
整体来看多任务模型因为大幅降低了模型计算量,所以在多任务集成到一个网络后掉点十分严重,但是如果是多任务模型计算量与单模型计算量总和一致(任务数为 n,多任务计算量为 SNT,单任务计算量为 SNT/n)的情况下,多任务模型其实是能涨点的
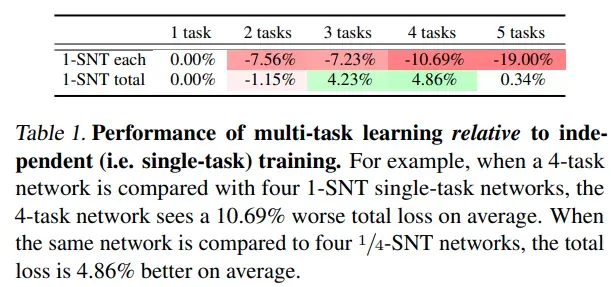
-
对比单任务训练(1/2 SNT)和 2 任务训练,可以发现 Normal 任务能帮助其他所有任务提升精度
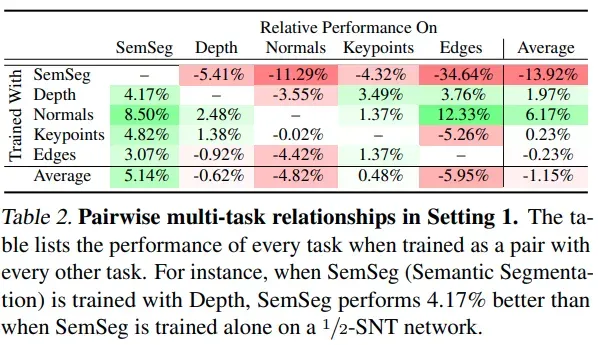
-
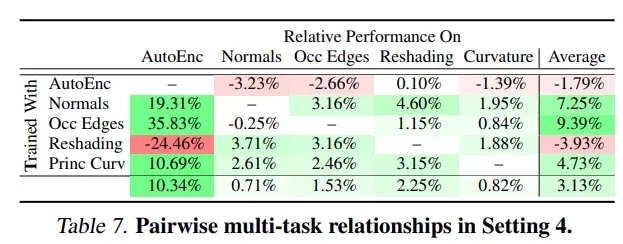
为了确定任务间关联,对于两个任务联合训练时的精度变化计算均值,得到下表:normal 和 edge 任务是配合性任务;比较意外的是 3d 的两个任务 depth 和 normal 并不是配合性任务;这个和 transfer learning 任务中的结论不一致
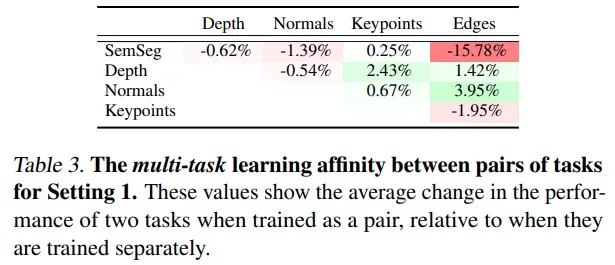
-
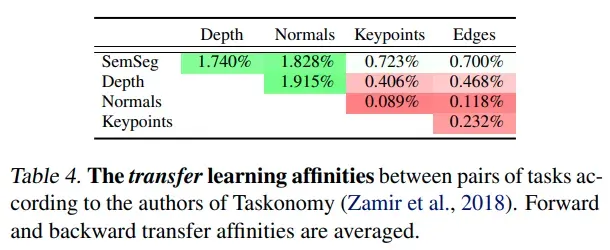
transfer learning 各任务间的关系,与多任务的任务间关系联系不大 (Pearson’s r is −0.12, p = 0.74)
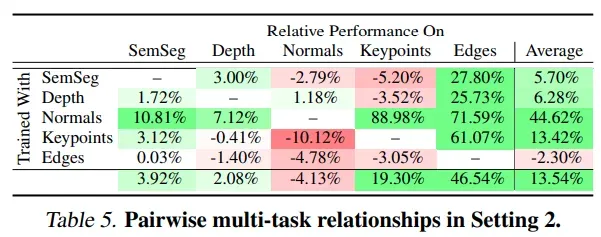
多任务间关系(set2,大模型)
- 基于更大的 xception 模型,使用更大的模型后更多的任务会在多任务学习中受益;但是仍然有任务会精度降低,并且这里的精度与使用更小的 xception17 模型的精度没有明显的相关性 (Pearson’s r = 0.08),这就需要一个自动的框架来挑选适合一起训练的任务
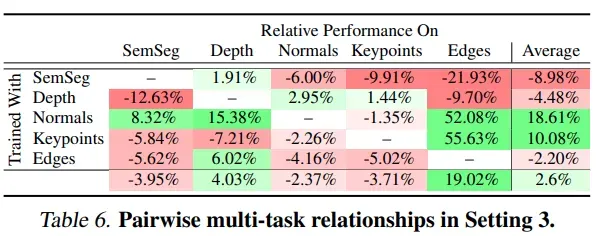
多任务间关系(set3,小数据集)
-
仅使用 5% 的训练数据。一种公认的假设是多任务训练能在少量数据场景有更优的结果,因为多任务学习能有效集中监督,但是这里的实验结果是多任务训练并不能解决小数据问题,换句话说就是多任务训练在数据量更大的情况下能相比于单任务训练得到更优的收敛
-
大模型和小模型的任务间关系没有联系,但是小数据集与小模型间是有正相关关系的 (Pearson’s r =+0.375, p = 0.10) ,小数据集与大模型间也是正相关关系 (Pearson’s r = +0.558, p = 0.01)
多任务间关系(set4,使用 task set 2)
- 除了 autoencoder 任务,其他的任务组合基本都是正向收益,主要这些任务都比较相似
Key Takeaways
- 不同任务间的关系和训练 setup 相关
- 数据量和模型容量都会影响任务间的关系
- 多任务训练和迁移学习中的各个任务的关系没有明显关系
- normal task 能提升其他任务精度,16 个模型中 15 个精度都提升了(这可能是因为法线在曲面上具有统一的值,并保留三维边),但是 norm task 自己的精度会降低
多任务组合框架 (Task Grouping Framework)
- 从前面的实验分析可以看出不同的任务需要分配到不同的模型中,并且这个分配关系随着模型容量和数据量等会有变化,所以需要在线搜索合适的分配方式;搜索的目标是在给定的计算量要求下,搜索到多任务总损失最小的网络分配方式
- 搜索空间设计
- 任务数:对于 n 个任务,一般有
- 模型容量:除了 1 unit 的标注容量模型,作者对每个单独的任务还加了 0.5 unit 的模型容量选项
- 所以对于论文中使用的 5 个任务,可选的组合数目是
- 使用 branch-and-bound like 方法搜索出总时间符合预期的模型
- 任务数:对于 n 个任务,一般有
- 降低训练时间的模型选取方法:
- early stopping approximation: 全部训练的模型和只基于 20% 数据训练模型的 loss 相关性很高 (Pearson’s r =0.49)
- Higher order approximation:比如 ab 任务、bc 任务、ac 任务的结果能否预测 abc 任务训练的结果,作者实验结果是可以的,通过这种方式就可以基于单任务、两两任务的组合的 loss 来预测多任务组合的 loss,比如两两任务组合的 loss 如下:
- ab:0.1 & 0.2
- bc:0.3 & 0.4
- ac:0.5 & 0.6
则 abc 任务的 loss 预测为:
a=(0.1+0.6) / 2
b=(0.2+0.3)/2
c=(0.4+0.6)/2
多任务组合实验(setting1)
-
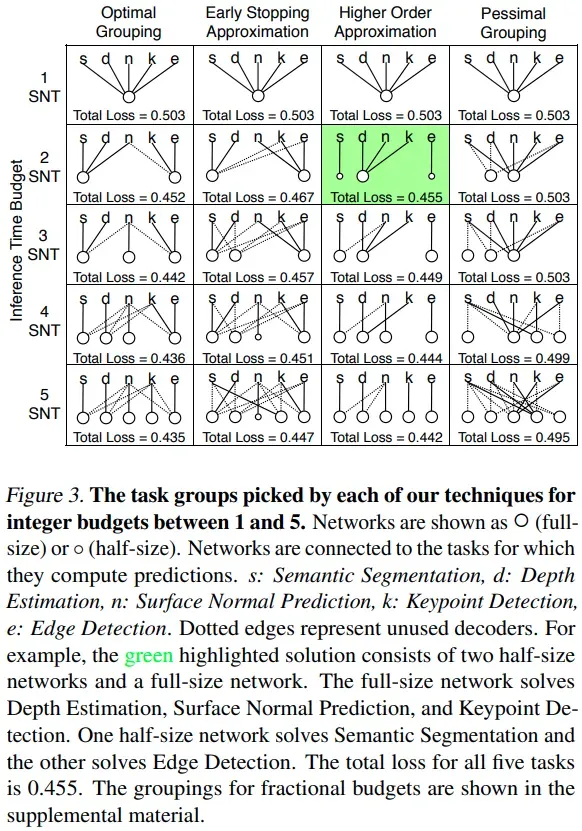
不同方法搜索的网络结构,其中 optimal grouping 是基于完全训练完的模型搜索得到,可以看出 Higher Order Approximation 的方式更接近完全训练完的结果,Higher Order Approximation 的搜索时间一般是节省 45%,Early Stopping Approximation 一般是节省 95%
-
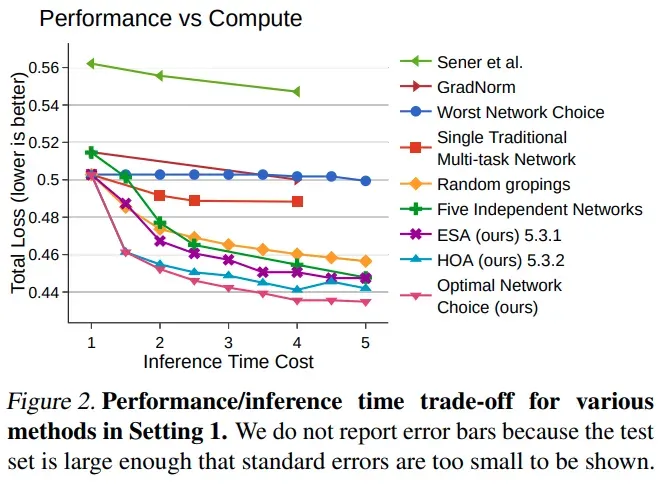
对比了 1SNT 到 5SNT 的不同 inference time setting 下本文提出的方法都是 sota,可以看出相比于仅使用一个整体的 backbone 还是提升很明显的
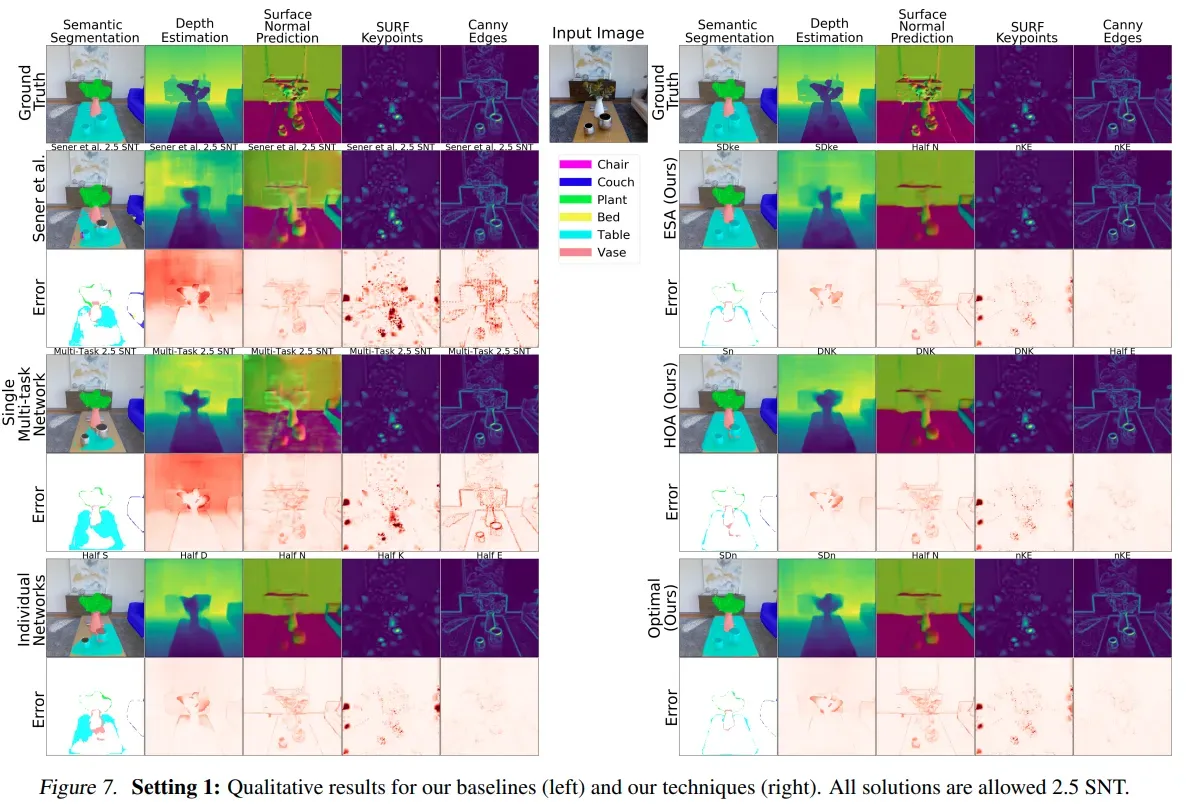
定性的可视化分析
- ESA 和 HOA 这两个节省搜索时间的方式的结果和最优搜索结果接近
Thoughts
- 随着模型容量、数据集大小等变化各个任务间的相关性也会变,看起来多任务的框架设计确实不容易;在线搜索任务的组合可能是比较可行的解决方案
- 找到合适的辅助任务对于多任务提点很关键
文章出处登录后可见!