实验目的:
随着 Hadoop 与 Spark 产生的影响越来越深,各种基于 Hadoop 与 Spark 平台的数据分析系统也随之出现。本次实验要求各位同学利用之前实验以及所学知识实现一个基于 Hadoop、Spark 或其他大数据平台的数据分析系统,理解其中的实现细节以及各种算法的原理。
实验软件和硬件环境:
- 操作系统:Linux(实验室版本为 Ubuntu17.04,集群环境为 centos6.5);
- Hadoop 版本:2.9.0;
- JDK 版本:1.8;
- Java IDE:Eclipse 3.8。
- Spark 版本:实验室版本为 2.1.0,集群环境为 2.3.0;
- Maven
实验要求:
基本要求:实现的数据分析系统要有对数据分析结果以及各种功能的图形化、图表化展示界面。
高级要求:在数据分析系统中应用算法解决一些实际问题,例如采用某个推荐系统算法实现产品推荐,或某个挖掘算法产生数据的深度分析结果,算法都是基于大数据系统的并行化算法。
实验主题:基于关联规则挖掘的图书推荐
在我国的图书出版和发行行业,经过多年的发展,图书市场在种类规模和总体数量等方面发展和增长迅速。但与此同时也带来了图书过多、读者难以选择的问题。常规的明细分类使得读者可以针对每- – 种类型的图书进行选择,但是每个分类下依然有成千上万种书籍。因此,基于读者的用户评论分析来进行图书推荐是一个具有实际应用价值的研究。
基于 Apriori 关联规则挖掘算法进行图书推荐的应用算法设计和实现,将利用大量图书评论数据,使用 MapReduce 并行化处理技术来完成图书的 k-频繁项集挖掘和图书推荐置信度的计算,在此基础上完成图书的推荐应用,并整合图书评分统计系统。
实验原理:
频繁项集挖掘
关联规则用来描述事物之间的联系,用来挖掘事物之间的相关性。挖掘关联规则的核心是通过统计数据项获得频繁项集。
设 I={i,i, .,im} 是项的集合,设任务相关的数据 D 是数据库事务的集合,其中每个事务 T 是项的集合,每一个事务有一个标志符,称作 TID。设 A 和 B 是两个项集,A、B 均为 I 的非空子集。关联规则是形如 A->B 的蕴涵式,并且 A∩B=φ。关联规则挖掘涉及到以下几个关键概念。
1 置信度/可信度( Confidence)。 置信度即是“值得信赖性”。设 A, B 是项集,对于事务集 D, A∈D, B∈D, A∩B=φ,A->B 的置信度定义为:置信度(A->B)=包含 A 和 B 的元组数/包含 A 的元组数。
Confidence(A->B) = P(B|A) = P(AB)/P(A)
2 支持度(Support)。 支持度(A->B) =包含 A 和 B 的元组数/元组总数。支持度描述了 A 和 B 这两个项集在所有事务中同时出现的概率。
Support(A->B) = P(AB)
3 强关联规则。设 min_sup 是最小支持度阈值; min_conf 是最小置信度阈值。如果事务集合 D 中的关联规则 A->B 同时满足 Support(A->B)>=min_sup, Confidence(A->B)>=min_conf
Apriori 频繁项集挖掘算法简介
Apriori 算法是频繁项集挖掘中的经典算法。Apriori 算法通过多轮迭代的方法来逐步挖掘频繁项集。在第一轮迭代中,计算事务数据库中每一个项的支持度并找出所有频繁项。在之后的每一轮迭代中,将前一轮生成的频繁 k-项集作为本轮迭代的种子项集,以此来生成候选(k+1)-项集。这些候选项集在整个事务数据库中可能是频繁的,也可能是非频繁的。在本轮迭代中,需要计算每个候选(k+1)-项集在事务数据库中的实际支持度,以找出全部的(k+1)-频繁项集并将其作为下一轮的种子项集。这样的迭代过程将一直进行 下去,直到不能产生新的频繁项集为止。
根据频繁项集的定义,为了找出所有的频繁项集,需要对一条事务中的全部项穷尽各种组合(即组成项集),并计算每一种组合的支持度,以判定各组合是否为频繁项集。对于一条包含 m 个项的事务,其所有的组合最多可达 2 的 m 次方种。为了减小项集组合的搜索空间,Apriori 算法利用了以下两条性质:
性质 1:频繁项集的任何非空子集都是频繁的。
性质 2:非频繁项集的任何超集都是非频繁的。
实验数据:Book-Crossing Dataset
该数据集有 SQL 和 CSV 两种格式。
`BX-Books`记录了图书信息
CREATE TABLE `BX-Books` (
`ISBN` varchar(13) binary NOT NULL default '',
`Book-Title` varchar(255) default NULL,
`Book-Author` varchar(255) default NULL,
`Year-Of-Publication` int(10) unsigned default NULL,
`Publisher` varchar(255) default NULL,
`Image-URL-S` varchar(255) binary default NULL,
`Image-URL-M` varchar(255) binary default NULL,
`Image-URL-L` varchar(255) binary default NULL,
PRIMARY KEY (`ISBN`)
TYPE=MyISAM;
`BX-Book-Ratings`记录了图书评分信息
CREATE TABLE `BX-Book-Ratings` (
`User-ID` int(11) NOT NULL default '0',
`ISBN` varchar(13) NOT NULL default '',
`Book-Rating` int(11) NOT NULL default '0',
PRIMARY KEY (`User-ID`,`ISBN`)
TYPE=MyISAM;
`BX-Users`记录了用户信息
CREATE TABLE `BX-Users` (
`User-ID` int(11) NOT NULL default '0',
`Location` varchar(250) default NULL,
`Age` int(11) default NULL,
PRIMARY KEY (`User-ID`)
TYPE=MyISAM;
实验思路:
- 使用 hadoop 作为大数据处理框架,通过 apriori 进行频繁项集数据挖掘。
- 使用 Web 项目作为展示平台。
- 前端 bootstrap,实现响应式布局,适配多种设备。
- 后端 Java Web。用户交互页面有搜索页面和展示页面。使用 JSP+JavaBean+Servlet。该模式遵循了 MVC 设计模式,
- 使用 Maven 作为项目管理工具。
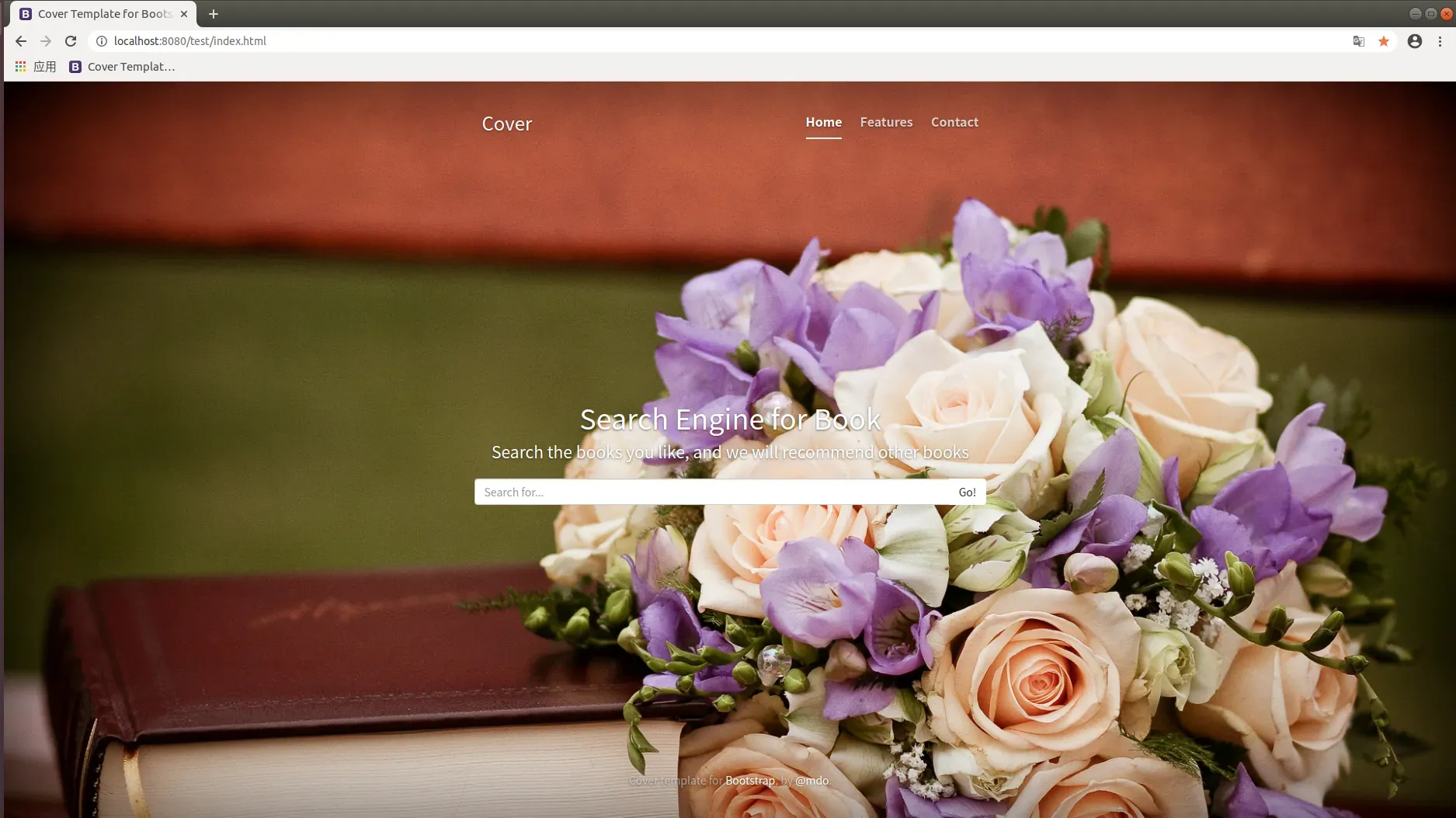
- 搜索页面,用户填入搜索书籍名
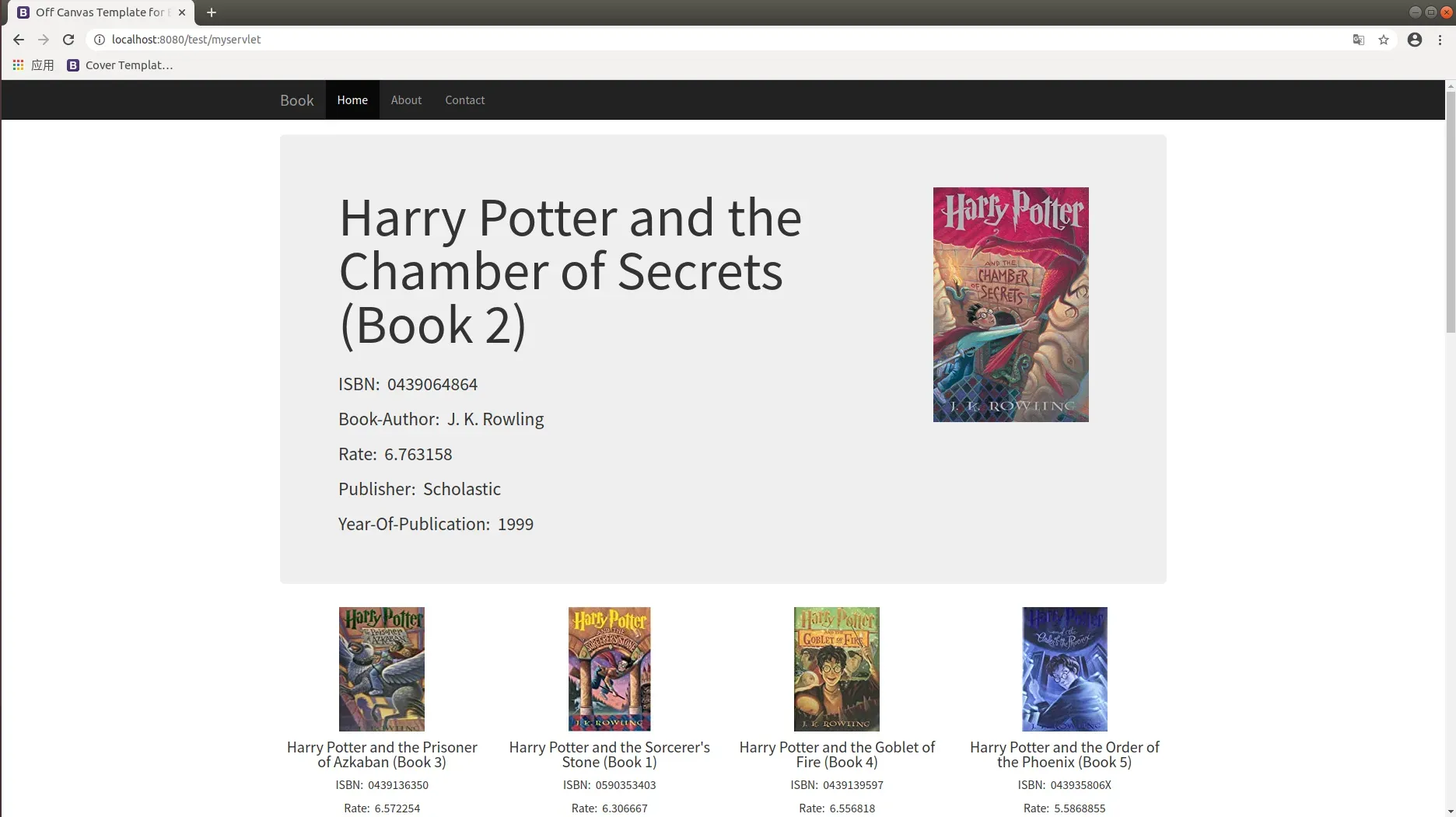
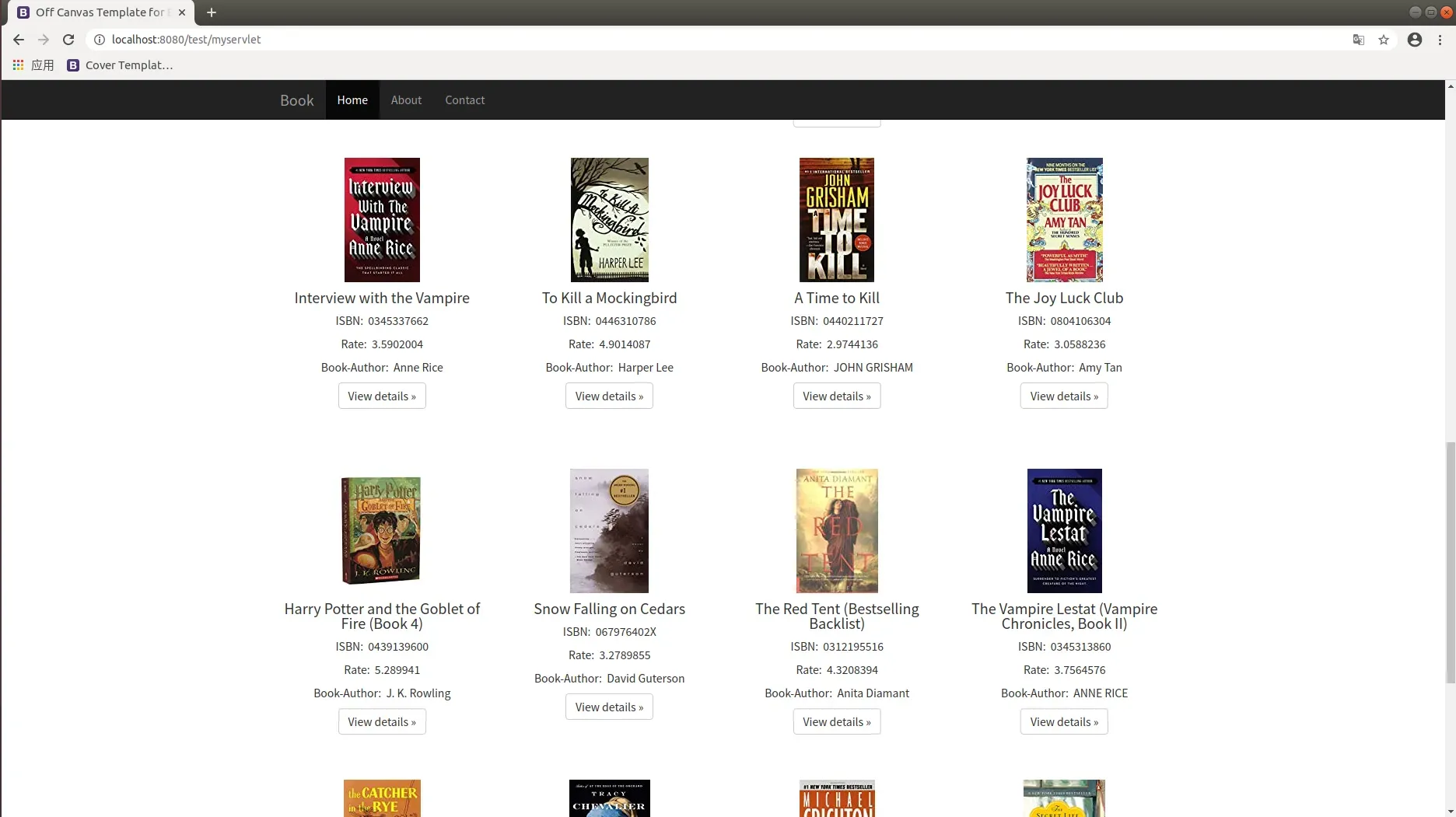
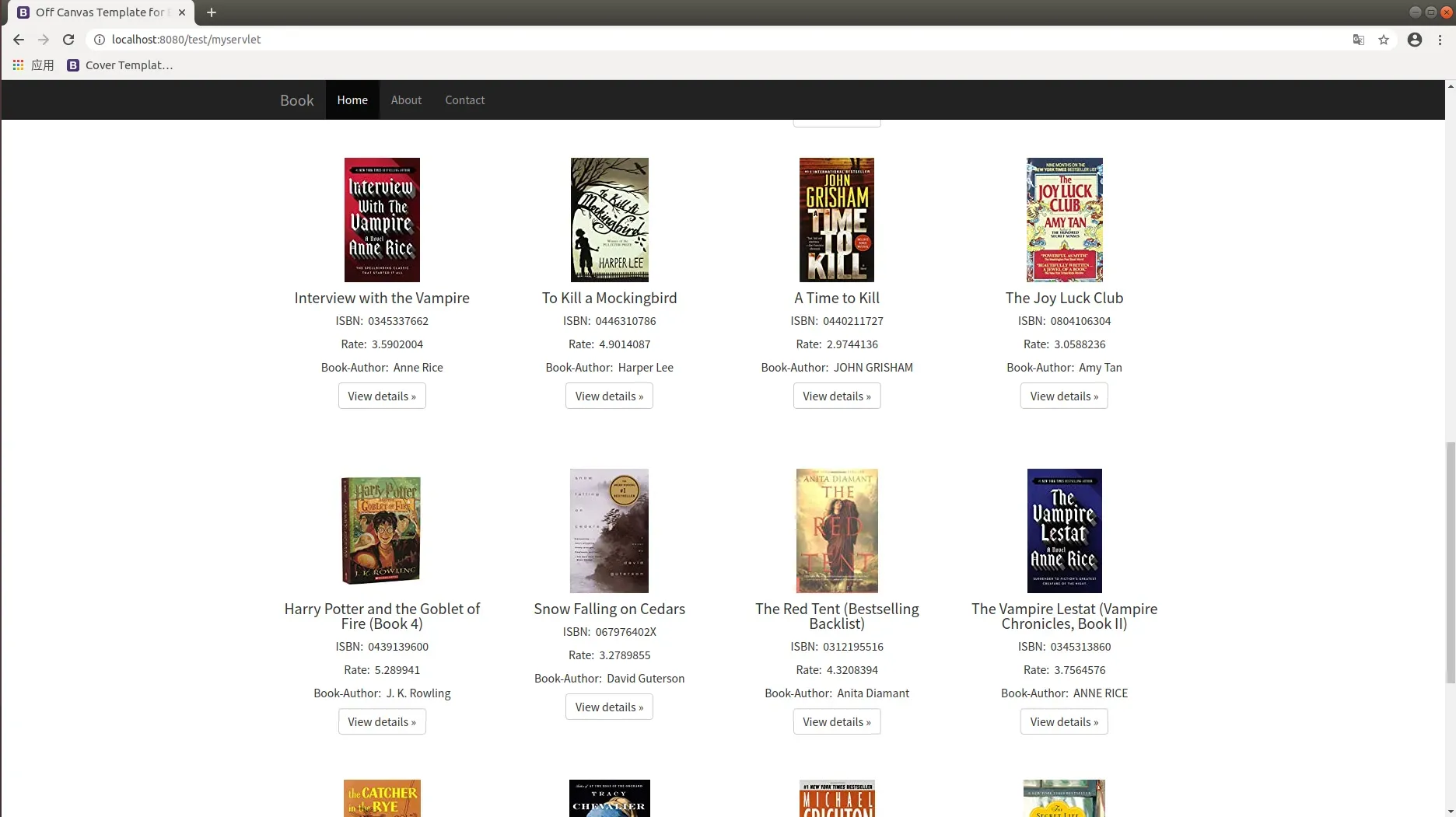
- 搜索后的结果展示,巨幕展示了所搜索书籍的完整信息,包括平均评分。巨幕下方展示了所推荐的图书,可以通过点击进入到该图书的详细页面。
数据处理:
1 数据预处理
由于数据中有少量不规则的数据,需要进行预处理,主要使用正则表达式。
数据输入形式:
User-ID;"ISBN";"Book-Rating",,
276725;"034545104X";"0",,
276726;"0155061224";"5",,
276727;"0446520802";"0",,
276729;"052165615X";"3",,
276729;"0521795028";"6",,
数据预处理后:
1.0140219854 0312954468 0312983263 0446523747 3498020862
2.068483068X 0743446593
3.0679735909 0744552192
4.0590396056
5.0671673688 0671888587 0771091583 0440211727 0771099975 0553277472 0671759310 0440295653 0671016652
6.0743225082
7.067087146X 0735611807 0764515489 0786881852 0789722097 0806931345 0915811898 1579120636 0688176933 0375702652
8.0375727345 0060937734
9.044021422X
10.0395617693 0395618185 0440405084 0673801012 014034294X 1856978842 0064400204 0743400526
11.9727595553
12.0440224675
13.0749399627 1857992083
数据预处理代码
1.public class PreJob {
2. public static class PreJobMapper extends Mapper<LongWritable, Text, Text, Text>
3. {
4. private String pattern = "[^\\w]";
5. private final static int low = 0;
6.
7. /*
8. * input: value:User-ID;"ISBN";"Book-Rating"
9. * output: key:User-ID value:ISBN
10. */
11. public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
12. String line = value.toString();
13.
14.
15. line = line.replaceAll(pattern, " ");
16.
17. String[] parts = line.trim().split("\\s+");
18.
19.
20. if(parts.length == 3 && parts[0].charAt(0) != 'U' && parts[1].length() == 10)
21. {
22. String user = parts[0];
23. String isbn = parts[1];
24.
25.
26. Double rate = Double.parseDouble(parts[2]);
27.
28. if(rate >= low)
29. context.write(new Text(user), new Text(isbn));
30. }
31. }
32. }
33.
34.
35. /*
36. * input: key:User-ID value:ISBN
37. * output: key:ISBN \t ISBN \t ISBN value:NULL
38. */
39. public static class PreJobReducer extends Reducer<Text, Text, Text, NullWritable> {
40. public void reduce(Text key,Iterable<Text> values,Context context) throws IOException, InterruptedException
41. {
42. String out = "";
43. int blank = 0;
44.
45. for(Text value:values)
46. {
47. if(blank++ != 0)
48. out += "\t";
49.
50. String isbn = value.toString();
51. out += isbn;
52. }
53.
54. context.write(new Text(out), NullWritable.get());
55. }
56. }
57.
58. public static void main(String[] args) throws Exception {
59. Configuration conf = new Configuration();
60.
61. FileSystem fs = FileSystem.get(conf);
62. if (fs.exists(new Path(args[1])))
63. fs.delete(new Path(args[1]), true);
64.
65. Job job = new Job(conf, "PreJob");
66. job.setJarByClass(PreJob.class);
67.
68. job.setMapOutputKeyClass(Text.class);
69. job.setMapOutputValueClass(Text.class);
70.
71. job.setOutputKeyClass(Text.class);
72. job.setOutputValueClass(NullWritable.class);
73.
74. job.setMapperClass(PreJobMapper.class);
75. job.setReducerClass(PreJobReducer.class);
76.
77. FileInputFormat.addInputPath(job, new Path(args[0]));
78. FileOutputFormat.setOutputPath(job, new Path(args[1]));
79.
80. job.waitForCompletion(true);
81. }
82.
}
2 计算支持度
Support(A->B) = P(AB)
2.1 计算频繁 1 项集
读入预处理结果,计算每本书被评分的次数
计算频繁 1 项集输入数据格式
14.0140219854 0312954468 0312983263 0446523747 3498020862
15.068483068X 0743446593
16.0679735909 0744552192
17.0590396056
18.0671673688 0671888587 0771091583 0440211727 0771099975 0553277472 0671759310 0440295653 0671016652
19.0743225082
20.067087146X 0735611807 0764515489 0786881852 0789722097 0806931345 0915811898 1579120636 0688176933 0375702652
21.0375727345 0060937734
22.044021422X
23.0395617693 0395618185 0440405084 0673801012 014034294X 1856978842 0064400204 0743400526
24.9727595553
25.0440224675
0749399627 1857992083
计算频繁 1 项集输出数据格式
1.0002000288 2
2.0002000369 1
3.0002000474 1
4.0002000547 1
5.0002005018 13
6.0002005050 3
7.0002005093 3
8.0002005115 7
计算频繁 1 项集代码
1.public class FreqItemSet {
2.
3. /*
4. * input: value:ISBN \t ISBN \t ISBN
5. * output: key:ISBN value:one
6. */
7. public static class FreqItemSetMapper extends Mapper<LongWritable, Text, Text, IntWritable>
8. {
9. private IntWritable one = new IntWritable(1);
10. public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
11. String line = value.toString();
12. String[] parts = line.split("\t");
13.
14. for(int i = 0;i < parts.length;i++)
15. context.write(new Text(parts[i]), one);
16. }
17. }
18.
19. public static class FreqItemSetCombiner extends Reducer<Text, IntWritable, Text, IntWritable> {
20. public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException, InterruptedException
21. {
22. int sum = 0;
23. for(IntWritable value:values)
24. sum += value.get();
25. context.write(key, new IntWritable(sum));
26. }
27. }
28.
29. /*
30. * input: key:ISBN value:one
31. * output: key:ISBN value:sum
32. */
33. public static class FreqItemSetReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
34. public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException, InterruptedException
35. {
36. int sum = 0;
37. for(IntWritable value:values)
38. sum += value.get();
39. if(sum >= 3)
40. context.write(key, new IntWritable(sum));
41. }
42. }
43.
44. public static void main(String[] args) throws Exception {
45. Configuration conf = new Configuration();
46.
47. FileSystem fs = FileSystem.get(conf);
48. if (fs.exists(new Path(args[1])))
49. fs.delete(new Path(args[1]), true);
50.
51. Job job = new Job(conf, "FreqItemSet");
52. job.setJarByClass(FreqItemSet.class);
53.
54. job.setOutputKeyClass(Text.class);
55. job.setOutputValueClass(IntWritable.class);
56.
57. job.setMapperClass(FreqItemSetMapper.class);
58. job.setCombinerClass(FreqItemSetCombiner.class);
59. job.setReducerClass(FreqItemSetReducer.class);
60.
61. FileInputFormat.addInputPath(job, new Path(args[0]));
62. FileOutputFormat.setOutputPath(job, new Path(args[1]));
63.
64. job.waitForCompletion(true);
65. }
66.}
2.2 计算频繁 2 项集
根据频繁项集的定义,为了找出所有的频繁项集,需要对一条事务中的全部项穷尽各种组合(即组成项集),并计算每-种组合的支持度,以判定各组合是否为频繁项集。对于一条包含 m 个项的事务,其所有的组合最多可达 2”种。为了减小项集组合的搜索空间,Apriori 算法利用了以下两条性质进行剪枝,减少运算量:
性质 1:频繁项集的任何非空子集都是频繁的。
性质 2:非频繁项集的任何超集都是非频繁的。
输入为读入预处理结果,还需要 setup()在每一个 map 节点读入 k-1 频繁项集的结果。
计算频繁 2 项集输入数据格式
27.0140219854 0312954468 0312983263 0446523747 3498020862
28.068483068X 0743446593
29.0679735909 0744552192
30.0590396056
31.0671673688 0671888587 0771091583 0440211727 0771099975 0553277472 0671759310 0440295653 0671016652
32.0743225082
33.067087146X 0735611807 0764515489 0786881852 0789722097 0806931345 0915811898 1579120636 0688176933 0375702652
34.0375727345 0060937734
35.044021422X
36.0395617693 0395618185 0440405084 0673801012 014034294X 1856978842 0064400204 0743400526
37.9727595553
38.0440224675
39.0749399627 1857992083
计算频繁 2 项集输出数据格式
hdfs dfs -cat /user/201700301147/apriori2/FreqItemSetOutput2/part-r-00000
1.0060976497;0802139256 5
2.0060976497;0802139914 3
3.0060976497;0804102988 3
4.0060976497;080410526X 12
5.0060976497;0804105820 5
6.0060976497;0804106304 14
7.0060976497;0804106436 5
计算频繁 2 项集代码
1.public class FreqItemSet2 {
2. public static class FreqItemSet2Mapper extends Mapper<LongWritable, Text, Text, IntWritable>
3. {
4. private IntWritable one = new IntWritable(1);
5. private HashSet<String> freq = new HashSet<String>();
6.
7.
8. /*
9. * get key:ISBN
10. */
11. public void setup(Context context) throws IOException
12. {
13. Configuration conf = context.getConfiguration();
14. Path path = new Path( "hdfs://localhost:9000/user/201700301147/apriori2/FreqItemSetOutput/part-r-00000");
15. FileSystem fs = FileSystem.get(conf);
16. FSDataInputStream in = fs.open(path);
17. BufferedReader d = new BufferedReader(new InputStreamReader(in));
18.
19. String line;
20. while ((line = d.readLine()) != null) {
21. freq.add(line.split("\t")[0]);
22. }
23.
24. d.close();
25. in.close();
26. }
27.
28. /*
29. * input: value:ISBN \t ISBN \t ISBN
30. * output: key:ISBN;ISBN value:one
31. */
32. public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
33. String line = value.toString();
34. String[] parts = line.split("\t");
35.
36. int length = parts.length;
37. for(int i = 0;i < length;i++)
38. for(int j = i + 1;j < length;j++)
39. {
40. if(freq.contains(parts[i]) && freq.contains(parts[j]))
41. {
42. context.write(new Text(parts[i] + ";" + parts[j]), one);
43. context.write(new Text(parts[j] + ";" + parts[i]), one);
44. }
45. }
46. }
47. }
48.
49. public static class FreqItemSet2Combiner extends Reducer<Text, IntWritable, Text, IntWritable> {
50. public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException, InterruptedException
51. {
52. int sum = 0;
53. for(IntWritable value:values)
54. sum += value.get();
55. context.write(key, new IntWritable(sum));
56. }
57. }
58.
59. /*
60. * input: key:ISBN;ISBN value:one
61. * output: key:ISBN;ISBN value:sum
62. */
63. public static class FreqItemSet2Reducer extends Reducer<Text, IntWritable, Text, IntWritable> {
64. public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException, InterruptedException
65. {
66. int sum = 0;
67. for(IntWritable value:values)
68. sum += value.get();
69. if(sum >= 3)
70. context.write(key, new IntWritable(sum));
71. }
72. }
73.
74. public static void main(String[] args) throws Exception {
75. Configuration conf = new Configuration();
76.
77. FileSystem fs = FileSystem.get(conf);
78. if (fs.exists(new Path(args[1])))
79. fs.delete(new Path(args[1]), true);
80.
81. Job job = new Job(conf, "FreqItemSet2");
82. job.setJarByClass(FreqItemSet2.class);
83.
84. job.setOutputKeyClass(Text.class);
85. job.setOutputValueClass(IntWritable.class);
86.
87. job.setMapperClass(FreqItemSet2Mapper.class);
88. job.setCombinerClass(FreqItemSet2Combiner.class);
89. job.setReducerClass(FreqItemSet2Reducer.class);
90.
91. FileInputFormat.addInputPath(job, new Path(args[0]));
92. FileOutputFormat.setOutputPath(job, new Path(args[1]));
93.
94. job.waitForCompletion(true);
95. }
96.
97.}
3 计算置信度
Confidence(A->B) = P(B|A) = P(AB)/P(A)
需要频繁 1 项集结果和频繁 2 项集结果作为输入,以计算条件概率的方式计算置信度。
计算置信度输入数据格式
9.0002000288 2
10.0002000369 1
11.0002000474 1
12.0002000547 1
13.0002005018 13
14.0002005050 3
15.0002005093 3
16.0002005115 7
8.0060976497;0802139256 5
9.0060976497;0802139914 3
10.0060976497;0804102988 3
11.0060976497;080410526X 12
12.0060976497;0804105820 5
13.0060976497;0804106304 14
14.0060976497;0804106436 5
计算置信度输出数据格式
1.0000000000 0441172695 0.2857142857142857
2.0000000000 0440211727 0.42857142857142855
3.0000000000 0432534220 0.2857142857142857
4.0000000000 0385505833 0.2857142857142857
5.0000000000 038529929X 0.2857142857142857
6.0000000000 034536676X 0.2857142857142857
7.0001047973 0971880107 1.0
8.0001047973 0446673544 1.0
9.0001047973 0345370775 1.0
计算置信度代码
1.public class CountCL {
2. public static class CountCLMapper extends Mapper<LongWritable, Text, Text, Text>
3. {
4.
5. /*
6. * input: value:ISBN \t sum
7. * output: key:ISBN value:sum
8. *
9. * input: value:ISBN;ISBN \t sum
10. * output: key:ISBN value:ISBN;ISBN \t sum
11. */
12. public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
13. String line = value.toString();
14. String[] parts = line.split("\t");
15. String[] tuple = parts[0].split(";");
16.
17. if(tuple.length == 2)
18. {
19. context.write(new Text(tuple[0]), value);
20. }
21. else if(tuple.length == 1)
22. {
23. context.write(new Text(parts[0]), new Text(parts[1]));
24. }
25. }
26. }
27.
28. /*
29. * input: key:ISBN value:sum
30. * key:ISBN value:ISBN;ISBN \t sum
31. * output: key:ISBN \t ISBN value:CL
32. */
33. public static class CountCLReducer extends Reducer<Text, Text, Text, DoubleWritable> {
34. public void reduce(Text key,Iterable<Text> values,Context context) throws IOException, InterruptedException{
35. List<String> itemSet = new ArrayList<String>();
36. double one = 0;
37. for(Text value:values)
38. {
39. String line = value.toString();
40. String[] parts = line.split("\t");
41. if(parts.length == 2)
42. {
43. itemSet.add(line);
44. }
45. else if(parts.length == 1)
46. {
47. one = Double.parseDouble(parts[0]);
48. }
49. }
50.
51. if(itemSet.size() >= 1)
52. {
53. for(String item:itemSet)
54. {
55. String[] parts = item.toString().split("\t");
56. double two = Double.parseDouble(parts[1]);
57. double res = two / one;
58.
59. if(res >= 0.10)
60. {
61. String[] tuple = parts[0].split(";");
62. context.write(new Text(tuple[0] + "\t" + tuple[1]), new DoubleWritable(res));
63. }
64. }
65. }
66. }
67. }
68.
69. public static void main(String[] args) throws Exception {
70. Configuration conf = new Configuration();
71.
72. FileSystem fs = FileSystem.get(conf);
73. if (fs.exists(new Path(args[2])))
74. fs.delete(new Path(args[2]), true);
75.
76. Job job = new Job(conf, "CountCL");
77. job.setJarByClass(CountCL.class);
78.
79. job.setMapOutputKeyClass(Text.class);
80. job.setMapOutputValueClass(Text.class);
81.
82. job.setOutputKeyClass(Text.class);
83. job.setOutputValueClass(DoubleWritable.class);
84.
85. job.setMapperClass(CountCLMapper.class);
86. job.setReducerClass(CountCLReducer.class);
87.
88. FileInputFormat.setInputPaths(job, new Path(args[0]),new Path(args[1]));
89. FileOutputFormat.setOutputPath(job, new Path(args[2]));
90.
91. job.waitForCompletion(true);
92. }
93.}
4 计算书籍平均评分
通过用户对书籍的评分信息,以及已经计算出来的每本书的频繁 1 项集,并行计算出每本书的平均评分
计算书籍平均评分输入数据格式
7.User-ID;"ISBN";"Book-Rating",,
8.276725;"034545104X";"0",,
9.276726;"0155061224";"5",,
10.276727;"0446520802";"0",,
11.276729;"052165615X";"3",,
12.276729;"0521795028";"6",,
计算书籍平均评分输出数据格式
1.000105337X 10.0
2.0001053736 5.0
3.0001053744 5.0
4.0001055607 8.0
5.0001055666 5.25
6.0001056107 8.0
计算书籍平均评分代码
1.public class CountRate {
2. public static class CountRateMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
3. private String pattern = "[^\\w]";
4.
5.
6. /*
7. * input: value:User-ID;"ISBN";"Book-Rating"
8. * output: key:ISBN value:Book-Rating
9. */
10. public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
11. String line = value.toString();
12.
13. line = line.replaceAll(pattern, " ");
14.
15. String[] parts = line.trim().split("\\s+");
16.
17.
18. if (parts.length == 3 && parts[0].charAt(0) != 'U' && parts[1].length() == 10) {
19. String user = parts[0];
20. String isbn = parts[1];
21.
22.
23. int rate = Integer.parseInt(parts[2]);
24.
25. context.write(new Text(isbn), new IntWritable(rate));
26. }
27. }
28. }
29.
30. public static class CountRateCombiner extends Reducer<Text, IntWritable, Text, IntWritable> {
31.
32. public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
33.
34. int sum = 0;
35.
36. for (IntWritable value : values) {
37. sum += value.get();
38. }
39.
40. context.write(key, new IntWritable(sum));
41. }
42. }
43.
44. public static class CountRateReducer extends Reducer<Text, IntWritable, Text, DoubleWritable> {
45.
46. private HashMap<String,Integer> freq = new HashMap<String,Integer>();
47.
48. /*
49. * get key:ISBN value:sum
50. */
51. public void setup(Context context) throws IOException {
52. Configuration conf = context.getConfiguration();
53. Path path = new Path("hdfs://localhost:9000/user/201700301147/apriori2/FreqItemSetOutput/part-r-00000");
54. FileSystem fs = FileSystem.get(conf);
55. FSDataInputStream in = fs.open(path);
56. BufferedReader d = new BufferedReader(new InputStreamReader(in));
57.
58. String line;
59. while ((line = d.readLine()) != null) {
60. String[] parts = line.split("\t");
61. freq.put(parts[0], Integer.parseInt(parts[1]));
62. }
63.
64. d.close();
65. in.close();
66. }
67.
68. /*
69. * input: key:ISBN value:Book-Rating
70. * output: key:ISBN value:avg-Rate
71. */
72. public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
73.
74. int sum = 0;
75.
76. for (IntWritable value : values) {
77. sum += value.get();
78. }
79.
80. double count = (double) freq.get(key.toString());
81.
82. double rate = (double)sum / count;
83.
84. context.write(key, new DoubleWritable(rate));
85.
86. }
87. }
88.
89. public static void main(String[] args) throws Exception {
90. Configuration conf = new Configuration();
91.
92. FileSystem fs = FileSystem.get(conf);
93. if (fs.exists(new Path(args[1])))
94. fs.delete(new Path(args[1]), true);
95.
96. Job job = new Job(conf, "CountRate");
97. job.setJarByClass(CountRate.class);
98.
99. job.setMapOutputKeyClass(Text.class);
100. job.setMapOutputValueClass(IntWritable.class);
101.
102. job.setOutputKeyClass(Text.class);
103. job.setOutputValueClass(DoubleWritable.class);
104.
105. job.setMapperClass(CountRateMapper.class);
106. job.setCombinerClass(CountRateCombiner.class);
107. job.setReducerClass(CountRateReducer.class);
108.
109. FileInputFormat.addInputPath(job, new Path(args[0]));
110. FileOutputFormat.setOutputPath(job, new Path(args[1]));
111.
112. job.waitForCompletion(true);
113. }
114.
115.}
5 主函数进行调用
依次调用预处理、计算频繁 1 项集、计算频繁 2 项集、计算置信度、计算平均评分
主函数代码
1.public class FreqItemSetMain {
2. public static void main(String[] args) throws Exception {
3. String[] forPreJob = {"hdfs://localhost:9000/user/201700301147/apriori2/BX-Book-Ratings.txt", "hdfs://localhost:9000/user/201700301147/apriori2/PreJobOutput"};
4. PreJob.main(forPreJob);
5.
6. String[] forFreqItemSet = {"hdfs://localhost:9000/user/201700301147/apriori2/PreJobOutput", "hdfs://localhost:9000/user/201700301147/apriori2/FreqItemSetOutput"};
7. FreqItemSet.main(forFreqItemSet);
8.
9. String[] forFreqItemSet2 = {"hdfs://localhost:9000/user/201700301147/apriori2/PreJobOutput", "hdfs://localhost:9000/user/201700301147/apriori2/FreqItemSetOutput2"};
10. FreqItemSet2.main(forFreqItemSet2);
11.
12. String[] forCountCL = {"hdfs://localhost:9000/user/201700301147/apriori2/FreqItemSetOutput", "hdfs://localhost:9000/user/201700301147/apriori2/FreqItemSetOutput2","hdfs://localhost:9000/user/201700301147/apriori2/CountCLOutput"};
13. CountCL.main(forCountCL);
14.
15. String[] forCountRate = {"hdfs://localhost:9000/user/201700301147/apriori2/BX-Book-Ratings.txt","hdfs://localhost:9000/user/201700301147/apriori2/CountRateOutput"};
16. CountRate.main(forCountRate);
17.}
数据展示:
- 使用 Web 项目作为展示平台。
- 前端 bootstrap,实现响应式布局,适配多种设备。
- 后端 Java Web。用户交互页面有搜索页面和展示页面。使用 JSP+JavaBean+Servlet。该模式遵循了 MVC 设计模式,
- 使用 Maven 作为项目管理工具。
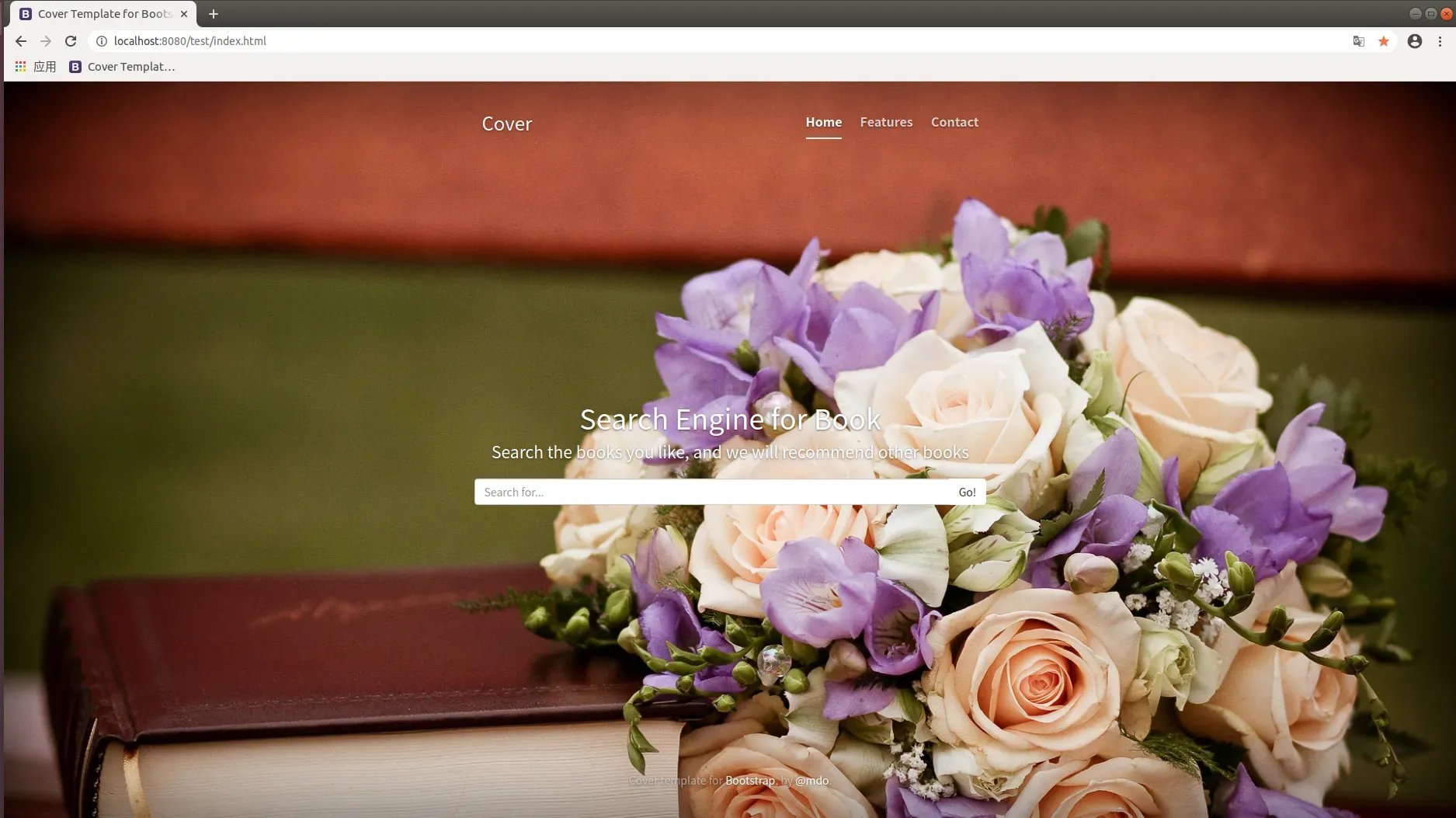
- 搜索页面,用户填入搜索书籍名
- 搜索后的结果展示,巨幕展示了所搜索书籍的完整信息,包括平均评分。巨幕下方展示了所推荐的图书,可以通过点击进入到该图书的详细页面。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ntFMoeih-1653895194171)(https://www.writebug.com/myres/static/uploads/2022/1/10/6a93d1d8bdc1ff14bd53668923d58e55.writebug)]
结论分析与体会:
-
要达到熟练掌握和运用 MapReduce 并行编程技术的目标,仅仅去了解并记住基本编程框架和 API 是远远不够的,更重要的是需要能熟练运用 MapReduce 计算模型和框架去分析所碰到的大数据处理问题,并设计、构建和实现有效的 MapReduce 并行化算法,最终完成大数据应用系统的开发。而要达到这个目标,介绍和展现大量的实际案例是一一个较为 有效的
-
很多大数据分析处理问题最终会落到机器学习和数据挖掘基础算法上来。然而,大数据给很多传统的机器学习和数据挖掘算法带来了很大的挑战。在数据集较小时很多单机机器学习和数据挖掘算法都可以有效工作,但当数据规模较大时,现有的单机算法将难以在可接受的时间开销内完成计算任务。因此,有必要设计实现面向大数据处理的并行化机器学习和数据挖掘算法。虽然 Hadoop 平台提供了一个包含各种机器学习和数据挖掘基础算法。
就实验过程中遇到和出现的问题,你是如何解决和处理的,自拟 1-3 道问答题:
mapreduce 编程总结
-
继承 RecordReader 抽象类需要重载 getCurrentKey() getCurrentValue() initialize() close() nextKeyValue() getProgress()函数。
-
继承 FileInputFormat<Text,Text> 需要重载 ReadRecorder。
-
hadoop默认输入格式TextInputFormat直接继承自[FileInputFormat]<[LongWritable],[Text]>。
-
hadoop默认输出格式TextOutFormat直接继承<K,V>,mapper输出和reducer输出格式不同,故需要通过setMapOutputKeyClass() setMapOutputValueClass() setOutputKeyClass() setOutputValueClass()配置泛型。
-
定制 Partitioner 需要重载 getPartition()函数。
mapreduce 中间结果所占存储过大,无法在本机运行
SSH 登入学校集群,使用学校的集群运行。
最终完成大数据应用系统的开发。而要达到这个目标,介绍和展现大量的实际案例是一一个较为 有效的
- 很多大数据分析处理问题最终会落到机器学习和数据挖掘基础算法上来。然而,大数据给很多传统的机器学习和数据挖掘算法带来了很大的挑战。在数据集较小时很多单机机器学习和数据挖掘算法都可以有效工作,但当数据规模较大时,现有的单机算法将难以在可接受的时间开销内完成计算任务。因此,有必要设计实现面向大数据处理的并行化机器学习和数据挖掘算法。虽然 Hadoop 平台提供了一个包含各种机器学习和数据挖掘基础算法。
就实验过程中遇到和出现的问题,你是如何解决和处理的,自拟 1-3 道问答题:
mapreduce 编程总结
-
继承 RecordReader 抽象类需要重载 getCurrentKey() getCurrentValue() initialize() close() nextKeyValue() getProgress()函数。
-
继承 FileInputFormat<Text,Text> 需要重载 ReadRecorder。
-
hadoop默认输入格式TextInputFormat直接继承自[FileInputFormat]<[LongWritable],[Text]>。
-
hadoop默认输出格式TextOutFormat直接继承<K,V>,mapper输出和reducer输出格式不同,故需要通过setMapOutputKeyClass() setMapOutputValueClass() setOutputKeyClass() setOutputValueClass()配置泛型。
-
定制 Partitioner 需要重载 getPartition()函数。
mapreduce 中间结果所占存储过大,无法在本机运行
SSH 登入学校集群,使用学校的集群运行。
文章出处登录后可见!