集成学习的大致思路
- 弱分类器:模型比较简单,效果很差的分类器,本次代码里面用到的弱分类器是决策树桩分类器。
- 集成学习就是把很多个弱分类器集中到一起,共同进行决策。
每个弱分类器的权重是不同的,每个分类器的权值由本身的效果决定,效果好的分类器对应的权值应设置大一些。
在今天的adaboosting算法中,每个树桩分类器确定以后会计算出它的翻车率tempError,利用tempError来确定当前分类器的权值:
图像长这样:
- 在adaboosting算法中基分类器之间是串行关系,下一个分类器的模型由上一个分类器的结果决定。我们把上一个分类器结果中分类错误的数据的权值提高,分类正确的数据权值调低。
这么做是为什么呢?
1、由于每个分类器算法是一样的,如果不对数据集进行调整,那么每个分类器训练出来的模型都是一模一样,集成就没有意义了。
2、把分错的权值提高、分对的权值降低后,形成“新的”数据集,下一个分类器在对新数据集训练时就会偏向于拟合上一个错误的数据
个人感觉后面的分类器可以给前面纠错,所以训练数据权值的调整也和前面的分类器结果有关联。
树桩分类器
其实就是一颗特殊的决策树,只做一次决策便可得出结果。很显然这就是一个弱分类器。
首先决策属性是随机的,之后会对该属性的所有值进行排序,接下来会选择一个插入点将排序后的数据一分为二,小于插入点的数据集合成为左孩子,大于插入点的数据集合成为右孩子。最后对孩子节点打标签的时候只需要统计出每个节点中哪种标签的权值最高,与之标签一致即可。
插入点的选择是暴力遍历的。
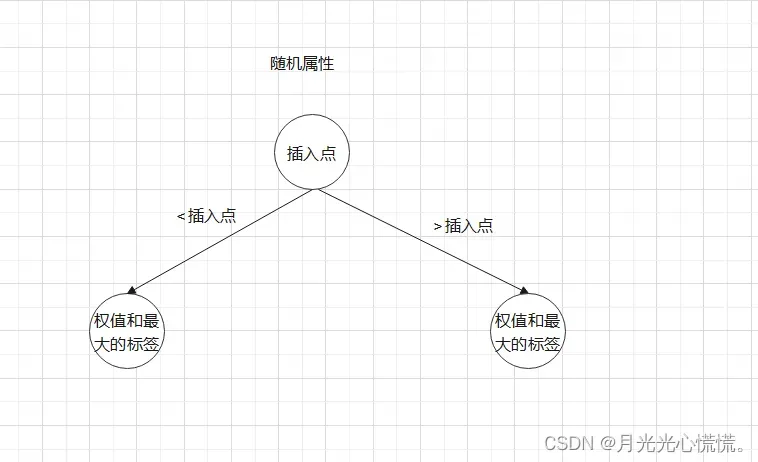
每个树桩分类器大概长上面这样,然后就是随机属性也需要保存在每个对象中,这样才能再后面分类时知道每个分类器需要什么属性。
模型集成
把多个树桩分类器训练好之后装到一个数组中成为模型数组,整体的模型即为模型数组与之对应的权值数组线性加和。使用的时候测试用例会遍历模型数组,每个模型会给出自己的答案,最后权值最高的答案获得胜利。
整体代码
主要分成4个类
- 封装数据集的WeightedInstances类
添加了一个调整权重的方法
package com.adaboosting;
import java.io.FileReader;
import java.util.Arrays;
import weka.core.Instances;
public class WeightedInstances extends Instances {
/**
* Weights.
*/
private double[] weights;
/**
******************
* The first constructor.
*
* @param paraFileReader
* The given reader to read data from file.
******************
*/
public WeightedInstances(FileReader paraFileReader) throws Exception {
super(paraFileReader);
setClassIndex(numAttributes() - 1);
weights = new double[numInstances()];
double tempAverage = 1.0 / numInstances();
for (int i = 0; i < weights.length; i++) {
weights[i] = tempAverage;
} // Of for i
System.out.println("Instances weights are: " + Arrays.toString(weights));
} // Of the first constructor
/**
******************
* The second constructor.
*
* @param paraInstances
* The given instance.
******************
*/
public WeightedInstances(Instances paraInstances) {
super(paraInstances);
setClassIndex(numAttributes() - 1);
weights = new double[numInstances()];
double tempAverage = 1.0 / numInstances();
for (int i = 0; i < weights.length; i++) {
weights[i] = tempAverage;
} // Of for i
//System.out.println("Instances weights are: " + Arrays.toString(weights));
} // Of the second constructor
/**
******************
* Getter.
*
* @param paraIndex
* The given index.
* @return The weight of the given index.
******************
*/
public double getWeight(int paraIndex) {
return weights[paraIndex];
} // Of getWeight
/**
******************
* Adjust the weights.
*
* @param paraCorrectArray
* Indicate which instances have been correctly classified.
* @param paraAlpha
* The weight of the last classifier.
******************
*/
public void adjustWeights(boolean[] paraCorrectArray, double paraAlpha) {
double tempIncrease = Math.exp(paraAlpha);
double tempWeightsSum = 0;
for (int i = 0; i < weights.length; i++) {
if (paraCorrectArray[i]) {
weights[i] /= tempIncrease;
} else {
weights[i] *= tempIncrease;
} // Of if
tempWeightsSum += weights[i];
} // Of for i
for (int i = 0; i < weights.length; i++) {
weights[i] /= tempWeightsSum;
} // Of for i
System.out.println("After adjusting, instances weights are: " + Arrays.toString(weights));
} // Of adjustWeights
} // Of WeightedInstances
- 分类器
里面声明了train()方法与classify()方法暂时不实现,方便以后使用不同的分类器来继承,只用重新实现这两方法即可。
剩下的就是一些辅助功能,计算错误率,返回判断数组。
package com.adaboosting;
import java.util.Random;
import weka.core.Instance;
/**
* The super class of any simple classifier.
*/
public abstract class SimpleClassifier {
/**
* The index of the current attribute.
*/
int selectedAttribute;
/**
* Weighted data.
*/
WeightedInstances weightedInstances;
/**
* The accuracy on the training set.
*/
double trainingAccuracy;
/**
* The number of classes. For binary classification it is 2.
*/
int numClasses;
/**
* The number of instances.
*/
int numInstances;
/**
* The number of conditional attributes.
*/
int numConditions;
/**
* For random number generation.
*/
Random random = new Random();
/**
******************
* The first constructor.
*
* @param paraWeightedInstances
* The given instances.
******************
*/
public SimpleClassifier(WeightedInstances paraWeightedInstances) {
weightedInstances = paraWeightedInstances;
numConditions = weightedInstances.numAttributes() - 1;
numInstances = weightedInstances.numInstances();
numClasses = weightedInstances.classAttribute().numValues();
}// Of the first constructor
/**
******************
* Train the classifier.
******************
*/
public abstract void train();
/**
******************
* Classify an instance.
*
* @param paraInstance
* The given instance.
* @return Predicted label.
******************
*/
public abstract int classify(Instance paraInstance);
/**
******************
* Which instances in the training set are correctly classified.
*
* @return The correctness array.
******************
*/
public boolean[] computeCorrectnessArray() {
boolean[] resultCorrectnessArray = new boolean[weightedInstances.numInstances()];
for (int i = 0; i < resultCorrectnessArray.length; i++) {
Instance tempInstance = weightedInstances.instance(i);
if ((int) (tempInstance.classValue()) == classify(tempInstance)) {
resultCorrectnessArray[i] = true;
} // Of if
} // Of for i
return resultCorrectnessArray;
}// Of computeCorrectnessArray
/**
******************
* Compute the accuracy on the training set.
*
* @return The training accuracy.
******************
*/
public double computeTrainingAccuracy() {
double tempCorrect = 0;
boolean[] tempCorrectnessArray = computeCorrectnessArray();
for (int i = 0; i < tempCorrectnessArray.length; i++) {
if (tempCorrectnessArray[i]) {
tempCorrect++;
} // Of if
} // Of for i
double resultAccuracy = tempCorrect / tempCorrectnessArray.length;
return resultAccuracy;
}// Of computeTrainingAccuracy
/**
******************
* Compute the weighted error on the training set. It is at least 1e-6 to
* avoid NaN.
*
* @return The weighted error.
******************
*/
public double computeWeightedError() {
double resultError = 0;
boolean[] tempCorrectnessArray = computeCorrectnessArray();
for (int i = 0; i < tempCorrectnessArray.length; i++) {
if (!tempCorrectnessArray[i]) {
resultError += weightedInstances.getWeight(i);
} // Of if
} // Of for i
if (resultError < 1e-6) {
resultError = 1e-6;
} // Of if
return resultError;
}// Of computeWeightedError
} // Of class SimpleClassifier
- 树桩分类器的实现
这个前面已经说过了一共4步:
1、随机选属性
2、属性值排序
3、暴力遍历找最优切入点
4、统计权重和并打标签
package com.adaboosting;
import weka.core.Instance;
import java.io.FileReader;
import java.util.*;
/**
* The stump classifier.
*
*/
public class StumpClassifier extends SimpleClassifier {
/**
* The best cut for the current attribute on weightedInstances.
*/
double bestCut;
/**
* The class label for attribute value less than bestCut.
*/
int leftLeafLabel;
/**
* The class label for attribute value no less than bestCut.
*/
int rightLeafLabel;
/**
******************
* The only constructor.
*
* @param paraWeightedInstances
* The given instances.
******************
*/
public StumpClassifier(WeightedInstances paraWeightedInstances) {
super(paraWeightedInstances);
}// Of the only constructor
/**
******************
* Train the classifier.
******************
*/
public void train() {
selectedAttribute = random.nextInt(numConditions);
double[] tempValuesArray = new double[numInstances];
for (int i = 0; i < tempValuesArray.length; i++) {
tempValuesArray[i] = weightedInstances.instance(i).value(selectedAttribute);
} // Of for i
Arrays.sort(tempValuesArray);
int tempNumLabels = numClasses;
double[] tempLabelCountArray = new double[tempNumLabels];
int tempCurrentLabel;
for (int i = 0; i < numInstances; i++) {
tempCurrentLabel = (int) weightedInstances.instance(i).classValue();
tempLabelCountArray[tempCurrentLabel] += weightedInstances.getWeight(i);
} // Of for i
double tempMaxCorrect = 0;
int tempBestLabel = -1;
for (int i = 0; i < tempLabelCountArray.length; i++) {
if (tempMaxCorrect < tempLabelCountArray[i]) {
tempMaxCorrect = tempLabelCountArray[i];
tempBestLabel = i;
} // Of if
} // Of for i
bestCut = tempValuesArray[0] - 0.1;
leftLeafLabel = tempBestLabel;
rightLeafLabel = tempBestLabel;
double tempCut;
double[][] tempLabelCountMatrix = new double[2][tempNumLabels];
for (int i = 0; i < tempValuesArray.length - 1; i++) {
if (tempValuesArray[i] == tempValuesArray[i + 1]) {
continue;
} // Of if
tempCut = (tempValuesArray[i] + tempValuesArray[i + 1]) / 2;
for (int j = 0; j < 2; j++) {
for (int k = 0; k < tempNumLabels; k++) {
tempLabelCountMatrix[j][k] = 0;
} // Of for k
} // Of for j
for (int j = 0; j < numInstances; j++) {
tempCurrentLabel = (int) weightedInstances.instance(j).classValue();
if (weightedInstances.instance(j).value(selectedAttribute) < tempCut) {
tempLabelCountMatrix[0][tempCurrentLabel] += weightedInstances.getWeight(j);
} else {
tempLabelCountMatrix[1][tempCurrentLabel] += weightedInstances.getWeight(j);
} // Of if
} // Of for i
double tempLeftMaxCorrect = 0;
int tempLeftBestLabel = 0;
for (int j = 0; j < tempLabelCountMatrix[0].length; j++) {
if (tempLeftMaxCorrect < tempLabelCountMatrix[0][j]) {
tempLeftMaxCorrect = tempLabelCountMatrix[0][j];
tempLeftBestLabel = j;
} // Of if
} // Of for i
double tempRightMaxCorrect = 0;
int tempRightBestLabel = 0;
for (int j = 0; j < tempLabelCountMatrix[1].length; j++) {
if (tempRightMaxCorrect < tempLabelCountMatrix[1][j]) {
tempRightMaxCorrect = tempLabelCountMatrix[1][j];
tempRightBestLabel = j;
} // Of if
} // Of for i
if (tempMaxCorrect < tempLeftMaxCorrect + tempRightMaxCorrect) {
tempMaxCorrect = tempLeftMaxCorrect + tempRightMaxCorrect;
bestCut = tempCut;
leftLeafLabel = tempLeftBestLabel;
rightLeafLabel = tempRightBestLabel;
} // Of if
} // Of for i
System.out.println("Attribute = " + selectedAttribute + ", cut = " + bestCut + ", leftLeafLabel = "
+ leftLeafLabel + ", rightLeafLabel = " + rightLeafLabel);
}// Of train
/**
******************
* Classify an instance.
*
* @param paraInstance
* The given instance.
* @return Predicted label.
******************
*/
public int classify(Instance paraInstance) {
int resultLabel = -1;
if (paraInstance.value(selectedAttribute) < bestCut) {
resultLabel = leftLeafLabel;
} else {
resultLabel = rightLeafLabel;
} // Of if
return resultLabel;
}// Of classify
}// Of StumpClassifier
- 集成分类与主函数
package com.adaboosting;
import java.io.FileReader;
import weka.core.Instance;
import weka.core.Instances;
/**
* The booster which ensembles base classifiers.
*/
public class Booster {
/**
* Classifiers.
*/
SimpleClassifier[] classifiers;
/**
* Number of classifiers.
*/
int numClassifiers;
/**
* Whether or not stop after the training error is 0.
*/
boolean stopAfterConverge = false;
/**
* The weights of classifiers.
*/
double[] classifierWeights;
/**
* The training data.
*/
Instances trainingData;
/**
* The testing data.
*/
Instances testingData;
/**
******************
* The first constructor. The testing set is the same as the training set.
*
* @param paraTrainingFilename
* The data filename.
******************
*/
public Booster(String paraTrainingFilename) {
try {
FileReader tempFileReader = new FileReader(paraTrainingFilename);
trainingData = new Instances(tempFileReader);
tempFileReader.close();
} catch (Exception ee) {
System.out.println("Cannot read the file: " + paraTrainingFilename + "\r\n" + ee);
System.exit(0);
} // Of try
trainingData.setClassIndex(trainingData.numAttributes() - 1);
testingData = trainingData;
stopAfterConverge = true;
System.out.println("****************Data**********\r\n" + trainingData);
}// Of the first constructor
/**
******************
* Set the number of base classifier, and allocate space for them.
*
* @param paraNumBaseClassifiers
* The number of base classifier.
******************
*/
public void setNumBaseClassifiers(int paraNumBaseClassifiers) {
numClassifiers = paraNumBaseClassifiers;
classifiers = new SimpleClassifier[numClassifiers];
classifierWeights = new double[numClassifiers];
}// Of setNumBaseClassifiers
/**
******************
* Train the booster.
******************
*/
public void train() {
// Step 1. Initialize.
WeightedInstances tempWeightedInstances = null;
double tempError;
numClassifiers = 0;
for (int i = 0; i < classifiers.length; i++) {
if (i == 0) {
tempWeightedInstances = new WeightedInstances(trainingData);
} else {
tempWeightedInstances.adjustWeights(classifiers[i - 1].computeCorrectnessArray(),
classifierWeights[i - 1]);
} // Of if
classifiers[i] = new StumpClassifier(tempWeightedInstances);
classifiers[i].train();
tempError = classifiers[i].computeWeightedError();
classifierWeights[i] = 0.5 * Math.log(1 / tempError - 1);
if (classifierWeights[i] < 1e-6) {
classifierWeights[i] = 0;
} // Of if
System.out.println("Classifier #" + i + " , weighted error = " + tempError + ", weight = "
+ classifierWeights[i] + "\r\n");
numClassifiers++;
if (stopAfterConverge) {
double tempTrainingAccuracy = computeTrainingAccuray();
System.out.println("The accuracy of the booster is: " + tempTrainingAccuracy + "\r\n");
if (tempTrainingAccuracy > 0.999999) {
System.out.println("Stop at the round: " + i + " due to converge.\r\n");
break;
} // Of if
} // Of if
} // Of for i
}// Of train
/**
******************
* Classify an instance.
*
* @param paraInstance
* The given instance.
* @return The predicted label.
******************
*/
public int classify(Instance paraInstance) {
double[] tempLabelsCountArray = new double[trainingData.classAttribute().numValues()];
for (int i = 0; i < numClassifiers; i++) {
int tempLabel = classifiers[i].classify(paraInstance);
tempLabelsCountArray[tempLabel] += classifierWeights[i];
} // Of for i
int resultLabel = -1;
double tempMax = -1;
for (int i = 0; i < tempLabelsCountArray.length; i++) {
if (tempMax < tempLabelsCountArray[i]) {
tempMax = tempLabelsCountArray[i];
resultLabel = i;
} // Of if
} // Of for
return resultLabel;
}// Of classify
/**
******************
* Test the booster on the training data.
*
* @return The classification accuracy.
******************
*/
public double test() {
System.out.println("Testing on " + testingData.numInstances() + " instances.\r\n");
return test(testingData);
}// Of test
/**
******************
* Test the booster.
*
* @param paraInstances
* The testing set.
* @return The classification accuracy.
******************
*/
public double test(Instances paraInstances) {
double tempCorrect = 0;
paraInstances.setClassIndex(paraInstances.numAttributes() - 1);
for (int i = 0; i < paraInstances.numInstances(); i++) {
Instance tempInstance = paraInstances.instance(i);
if (classify(tempInstance) == (int) tempInstance.classValue()) {
tempCorrect++;
} // Of if
} // Of for i
double resultAccuracy = tempCorrect / paraInstances.numInstances();
System.out.println("The accuracy is: " + resultAccuracy);
return resultAccuracy;
} // Of test
/**
******************
* Compute the training accuracy of the booster. It is not weighted.
*
* @return The training accuracy.
******************
*/
public double computeTrainingAccuray() {
double tempCorrect = 0;
for (int i = 0; i < trainingData.numInstances(); i++) {
if (classify(trainingData.instance(i)) == (int) trainingData.instance(i).classValue()) {
tempCorrect++;
} // Of if
} // Of for i
double tempAccuracy = tempCorrect / trainingData.numInstances();
return tempAccuracy;
}// Of computeTrainingAccuray
/**
******************
* For integration test.
*
* @param args
* Not provided.
******************
*/
public static void main(String args[]) {
System.out.println("Starting AdaBoosting...");
Booster tempBooster = new Booster("C:/Users/胡来的魔术师/Desktop/sampledata-main/iris.arff");
tempBooster.setNumBaseClassifiers(100);
tempBooster.train();
System.out.println("The training accuracy is: " + tempBooster.computeTrainingAccuray());
tempBooster.test();
}// Of main
}// Of class Booster
运行结果:

总结:这个太神奇了,每次运行模型都不一样,因为属性是随机的,然而结果相当稳定还很高,并且我们的基分类器只有两个标签,而数据集是有三个标签,即使是这样最后效果任然不错。
文章出处登录后可见!
已经登录?立即刷新