论文链接:Overcoming Catastrophic Forgetting in Neural Network
1.论文基础思路
EWC这个算法降低重要权重的学习率,重要权重的决定权是以前任务中的重要性。
作者尝试在人工神经网络中识别对旧任务而言较为重要的神经元,并降低其权重在之后的任务训练中的改变程度,识别出较为重要的神经元后,需要更进一步的给出各个神经元对于旧任务而言的重要性排序
论文通过给权重添加正则,从而控制权重优化方向,从而达到持续学习效果的方法。其方法简单来讲分为以下三个步骤:
1. 选择出对于旧任务(old task)比较重要的权重
2. 对权重的重要程度进行排序
3. 在优化的时候,越重要的权重改变越小,保证其在小范围内改变,不会对旧任务产生较大的影响
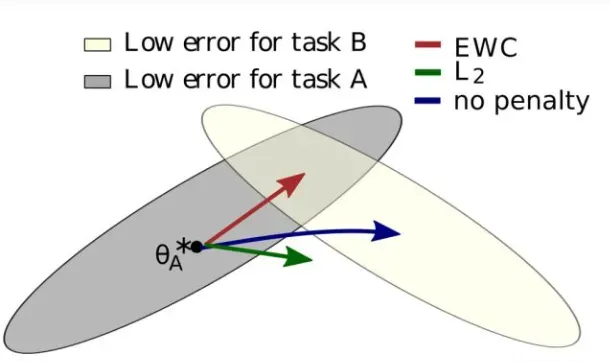
论文示意图,灰色区域是先前任务A的参数空间(旧任务的低误差区域),米黄色区域是当前任务B的参数空间(新任务的低误差区域);
如果我们什么都不做,用旧任务(Task A)的权重初始化网络,用新任务(Task B)的数据进行训练的话,在学习完Task A之后紧接着学习Task B,相当于Fine-tune(图中蓝色箭头),优化的方向如蓝色箭头所示,离开了灰色区域,最优参数将从原先A直接移向B中心,代表着其网络失去了在旧任务上的性能;
如果加上L2正则化就如绿色箭头所示;
如果用论文中的正则化方法EWC(红色箭头),参数将会移向Task A和Task B的公共区域(在学习任务B之后不至于完全忘记A)便代表其在旧任务与新任务上都有良好的性能。
具体方法为:将模型的后验概率拟合为一个高斯分布,其中均值为旧任务的权重,方差为 Fisher 信息矩阵(Fisher Information Matrix)的对角元素的倒数。方差就代表了每个权重的重要程度。
2.基础知识
2.1贝叶斯法则
=
=
即
=
所以可以得到
==
3.Elastic Weight Consolidation
3.1 参数定义
:网络的参数
:对于任务A,网络训练得到的最优参数
:全体数据集
:任务 A 的数据集
:任务 B 的数据集
:Fisher 信息矩阵
:Hessian 矩阵
3.2 EWC 方法推导
给定数据集D,我们的目的是寻找一个最优的参数,即目标为
—————————————————————-(1.0)
此类目标和我们常用的极大似然估计不一致,其实这么理解也是可行的,对1.0进行变化,则有
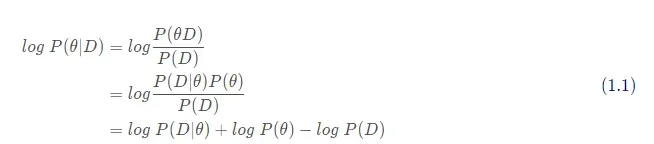
两边取对数,得到论文中的优化目标:
=
+
−
在给定整个数据集,我们需要得到一个 使得概率最大,那么也就是分别优化上式的右边三项。
第一项是任务
的似然,很明显可以理解为任务B的损失函数,将其命名为
,第三项
对于
来讲是一个常数,
是任务
上的后验,我们要最大化
,那么网络的优化目标便是:

即
=
)
右边提取负号,最大化一个负数
)
,相当于最小化负号后面的正数,即
最小化Task B上的损失函数,这很容易求,但后验概率很难求,我们只有上一次Task A训练完的模型参数
,,现在工作重点将转换为如何优化后验概率
,作者采用了
拉普拉斯近似的方法进行量化。
3.3 拉普拉斯近似
由于后验概率并不容易进行衡量,所以我们将其先验$\log P(D_A|\theta)$ 拟合为一个高斯分布
3.3.1 高斯分布拟合
令先验 服从高斯分布
∼
那么由高斯分布的公式可以得到:
取对数 =
那么,可以得到
=
令=
在 =
处进行泰勒展开,
=
是最优解,可以得到
=0
所以
=
那么可以得到
≈
其中 与
都是常数,可以得到
因此,可以得到
=
所以,可以得到
根据贝叶斯准则,
=
其中,符合均匀分布,
为常数,所以后验概率
也同先验概率服从同样的高斯分布
此时,优化函数
可以变换为
将权重展开来说,即为
其中该如何求解?
相当于之前Task A模型参数的Hessian矩阵
,直接求这个n*n的海森的话计算量太大了,作者提出用Fisher信息对角矩阵
替代,最终的损失函数变成:
引入超参 衡量两项的重要程度,可以得到最终的损失
上式即为论文中的公式(3)
Fisher信息矩阵本质上是海森矩阵的负期望,求需要求二阶导,而
只需要求一阶导,所以速度更快,
有如下性质:
1. 相当于损失函数极小值附近的二阶导数
2. 能够单独计算一阶导数(对于大模型而言方便计算)
3. 半正定矩阵
总结一句话:EWC的核心思想就是利用模型在Task A上训练的参数 来
估计后验,其中
估计的方法采用的是拉普拉斯近似,最后用Fisher对角矩阵代替Hessian计算以提高效率。
当移动到第三个任务(任务C)时,EWC将尝试保持网络参数接近任务a和B的学习参数。这可以通过两个单独的惩罚来实现,或者通过注意两个二次惩罚的总和本身就是一个二次惩罚来实现。
4.标题讨论
文章提出了一种新的算法,弹性权重整合(elastic weight consolidation),解决了神经网络持续学习的重要问题。EWC允许在新的学习过程中保护以前任务的知识,从而避免灾难性地忘记旧的能力。它通过选择性地降低体重的可塑性来实现,因此与突触巩固的神经生物学模型相似。
EWC算法可以基于贝叶斯学习方法。从形式上讲,当有新任务需要学习时,网络参数由先验值进行调整,先验值是前一任务中给定参数的后验分布。这使得受先前任务约束较差的参数的学习速度更快,而对那些至关重要的参数的学习速度较慢。
4.2 Fisher Information Matrix
4.2.1 Fisher Information Matrix 的含义
Fisher information 是概率分布梯度的协方差。为了更好的说明Fisher Information matrix 的含义,这里定义一个得分函数
则
[
]=
=
=
=
=
==0
那么 Fisher Information matrix
为
[(
)(
]
对于每一个batch的数据
,则其定义为
4.2.2 Fisher 信息矩阵与 Hessian 矩阵
参考1:高斯分布的积分期望E(X)方差V(X)的理论推导
参考2:《Overcoming Catastrophic Forgetting in Neural Network》增量学习论文解读
参考3:深度学习论文笔记(增量学习)——Overcoming catastrophic forgetting in neural networks
参考4:Elastic Weight Consolidation
参考5:(Fisher矩阵)持续学习:(Elastic Weight Consolidation, EWC)Overcoming Catastrophic Forgetting in Neural Network
文章出处登录后可见!