
摘要: 由于动态交通参与者(如行人和车辆等)和静态道路环境(如车道,交通灯等)的复杂表示以及之间的交互关系,在动态的,多交通参与者的场景下的行为预测是自动驾驶领域的一个重要问题。这篇文章提出了一个分层的图神经网络VectorNet,首先分别用向量表示不同局部空间的道路组成成员(包括动态交通参与者和静态道路环境),然后对所有的成员之间的高阶交互关系进行建模。与将动态交通参与者的运动轨迹和道路环境信息直接渲染在鸟瞰图像上并通过卷积神经网络对其进行编码的方法不同,我们的方法直接在矢量化的高精度地图上操作,避免了渲染损失以及计算密集的卷积神经网络编码步骤。为了进一步激发VectorNet学习特征的能力,我们提出一个通过其他道路组成成员特征还原随机掩盖的成员特征的新的辅助任务。我们在最近开源的Argoverse预测数据集和我们内部的行为预测数据集上评估了VectorNet的性能。在两个数据集上,我们的方法都达到了与采用渲染鸟瞰图像实现预测的方法相当甚至更好的性能,同时减少了超过70%的模型参数以及一个数量级的运算量。VectorNet在Argoverse数据集上的预测性能优于目前的最好水平。
1. 前言
这篇文章聚焦于复杂的,多交通参与者的场景下的行为预测。研究的核心在于找到整合通过感知系统获得的动态交通参与者和以高精度地图的形式给出的场景信息的统一表示。我们的目标是搭建一个系统学习去预测车辆的意图,并以运动轨迹的形式表示。
传统的行为预测方法是规则的,基于道路结构的约束生成多个行为假设。最近,很多基于学习的预测方法被提出[5,6,10,15]。他们提出了对于不同行为假设的进行概率解释的好处,但是需要重构一个新的表示来编码地图和轨迹信息。有趣的是,虽然高精度地图是高度结构化的,但是目前大多数预测方法选择将高精度地图渲染成颜色编码的属性(如图1的左图所示),并且采用感受野有限的卷积神经网络对场景信息进行编码。这就带来了一个疑问:我们能否直接从结构化的高精度地图中学习到有意义的场景信息表示?
我们提出直接从它们的矢量形式中学习一个动态交通参与者和结构化场景的统一的表示(如图1的右图所示)。道路特征的地理延伸可以是一个点,多边形或是曲线。例如,车道边界包含可以构成样条曲线的多个控制点;人行横道是由几个点定义的多边形;停止标识通过一个点来表示。所有的地理实体都可以被近似为多个控制点定义的折线。同时,动态交通参与者也可以通过他们的运动轨迹被近似为折线。所有的这些折线都可以表示为矢量的集合。
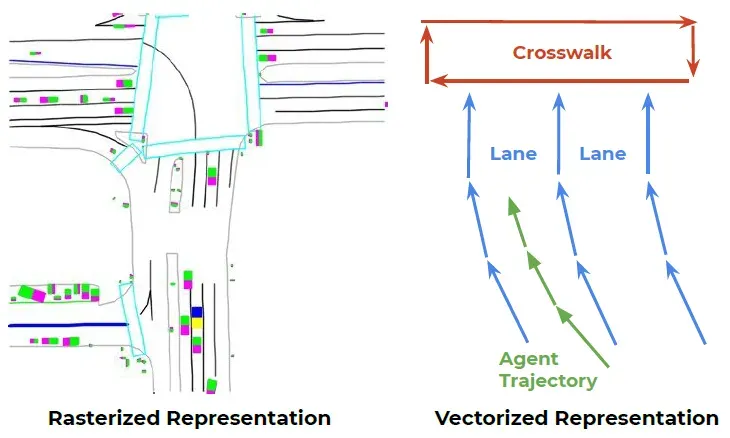
图1. 栅格化渲染方法(左)和矢量化方法(右)表示高精度地图与交通参与者运动轨迹
我们使用图神经网络来合并这些向量的集合。我们将每个向量视为图中的一个节点,并且定义节点的特征包含每个向量的起始位置和结束位置,以及其它属性,包括折线ID和语义标签。通过图神经网络,高精度地图的环境信息和其他交通参与者的运动轨迹被整合到目标交通参与者节点上。然后我们可以解码目标交通参与者输出的节点特征来预测它未来的运动轨迹。
特别地,为了学习图神经网络的竞争性表示,我们发现基于节点的空间和语义邻近性来约束图的连通性是很重要的。因此,我们提出了一个分层的图网络结构,首先把具有相同折线ID,并且具有相同语义标签的向量整合成折线特征,然后所有不同的折线特征互相连通交换信息。我们通过多层感知机实现局部图,通过自注意力机制[30]实现全局图。我们的方法如图2所示。
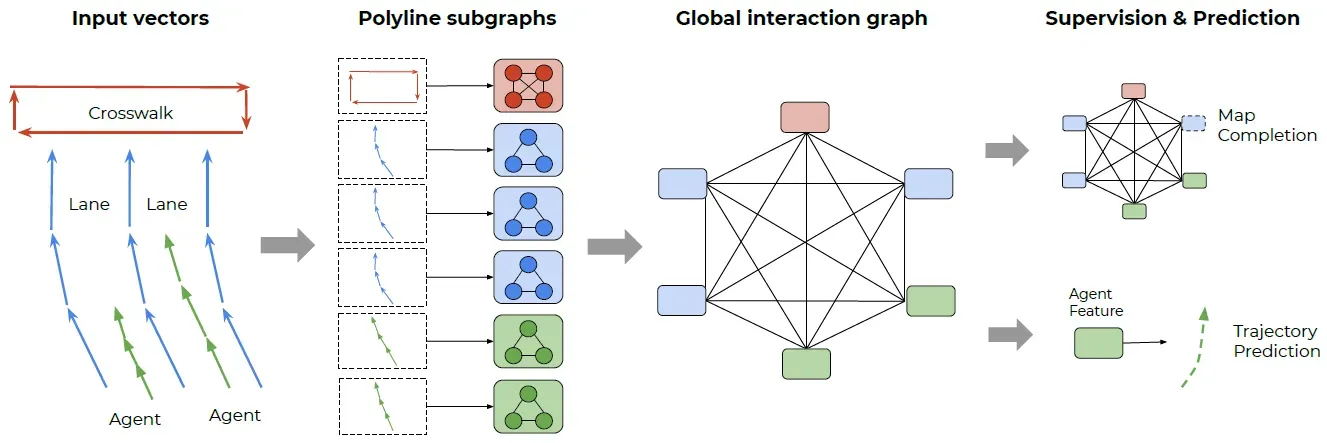
图2. 我们提出的VectorNet框架。观察到的交通参与者运动轨迹和地图特征被表示为矢量序列,然后传入局部图网络中获得折线级的特征。这些特征然后被传入一个全连接图网络中来建模高阶的交互。我们计算两类损失:从目标交通参与者对应的节点特征中预测其未来轨迹,以及预测图网络中被掩盖的节点特征。
最后,受到来自连续语音[11]和视觉数据[27]中采用自监督学习方法的有效性的启发,在行为预测目标之外我们提出一个辅助的图像补全目标。具体来说就是,我们随机掩盖属于静态场景或是动态轨迹的节点特征,然后让模型重构被掩盖的特征。我们直觉上认为这样可以鼓励图网络结构更好地捕捉动态交通参与者和静态环境之间的交互。总而言之,我们的贡献主要是:
-
我们是最先证明如何直接整合矢量化的场景信息和动态交通参与者信息来实现行为预测。
-
我们提出了双层图网络结构VectorNet和节点补全辅助任务。
-
我们在我们内部的行为预测数据集和Argoverse数据集上评估了提出的方法,结果表明我们的方法在减少了超过70%的模型参数以及一个数量级的运算量的情况下达到了与采用渲染鸟瞰图实现预测的方法相当甚至更好的性能。同时,我们的方法在Argoverse数据集上达到了目前最优的水平。
2. 相关工作
自动驾驶中的行为预测。在自动驾驶领域中,对动态的交通参与者的行为预测变得越来越重要[7,9,19],并且高精度地图也被广泛应用来提供环境信息。例如,IntentNet[5]通过LiDAR点云和渲染的高精度地图进行车辆检测并预测它们的运动轨迹。[15]假设已经得到车辆的检测结果并聚焦于通过卷积神经网络编码交互关系来实现行为预测。MultiPath[6]也采用卷积神经网络作为编码器并通过预先定义的候选轨迹来回归多个可能的未来轨迹。PRECOG[23]尝试通过基于流的生成模型捕捉未来的随机性。与[6,15,23]相似,我们也假设已经通过感知模块得到了检测结果。但是,不像那些采用卷积神经网络来编码渲染的道路地图的方法,我们提出直接编码矢量化的场景信息和动态交通参与者。
预测多个交通参与者之间的交互。在自动驾驶领域之外,更普遍的兴趣是预测交互对象之间的意图。例如对行人[2,13,24],人类活动[28]或是对体育运动员[12,26,32,33]。Social LSTM[2]采用单独的LSTM网络建模不同交通参与者的运动轨迹,并且聚合空间邻近的交通参与者的LSTM隐藏层来建模他们之间的交互关系。Social GAN[13]简化了交互建模并且提出采用生成对抗网络来预测多条可能的未来轨迹。[26]结合图神经网络[4]和变分循环神经网络[8]来建模交互关系。社会交互关系也可以从数据中推理出来,[18]将这些交互关系视为潜在变量。图注意网络[16,31]应用自注意力机制来给预定义的图中的边赋予权重。我们更进一步地提出了一个统一的分层的图网络结构来同时建模多个交通参与者之间的交互关系,以及他们和道路环境之间的交互关系。
自监督场景建模。最近,在自然语言处理领域的很多工作提出了自监督建模方法[11,22]。当学习成果被转移到下游任务时,取得了显著的效果提升。受到这些方法的启发,我们提出了一个图表示的辅助损失,它通过其他节点的特征来预测缺失的节点特征。其目标是激励模型更好地捕捉节点之间的交互。
文章出处登录后可见!