—0515
知识图谱可视化比正常数据可视化区别
搜索后的个人看法:
1、实体对象
知识图谱更general,倾向于异质网络;传统可视化更倾向于同质化网络的分析。
2、联系
知识图谱的图结构可以支持数据可视化
3、“知识”处理
知识图谱倾向于知识本身,并且倾向于把知识做向量化表示;正常数据可视化倾向于对数据做分析——将数据抽象为图的形式,采用图分析算法,可视化后进行分析。
4、应用
另外知识图谱本身的应用领域为问答系统,智能推荐之类的。(接下来可以多读读应用类综述。);可视化个人感觉,更倾向于做关联分析之类的。
—-0612读完论文,又找到很多感兴趣的东西~不错诶
下面刷题啦~
798差分矩阵
1、解决问题:在一个矩阵内频繁加减c
2、attention:
(1)写add函数时思路要清晰
(2)print时,直接打print()即可换行;打print(“\n”)后悔多加一个空行??
(3)不要忘记还有q行的插入操作
3、代码:
n,m,q = map(int, input().split())
a = [[0]*(m+2) for _ in range(n+2)]
b = [[0]*(m+2) for _ in range(n+2)]
for i in range(1,n+1):
a[i][1:] = list(map(int, input().split()))
def add(x1,y1,x2,y2,c):
b[x1][y1]+=c
b[x1][y2+1]-=c
b[x2+1][y1]-=c
b[x2+1][y2+1]+=c
for i in range(1,n+1):
for j in range(1,m+1):
add(i,j,i,j,a[i][j])
for _ in range(q):
x1,y1,x2,y2,c = map(int,input().split())
add(x1,y1,x2,y2,c)
for i in range(1,1+n):
for j in range(1,1+m):
b[i][j] += b[i-1][j]+b[i][j-1]-b[i-1][j-1]
print(b[i][j], end=' ')
print()
《人类语言处理》07
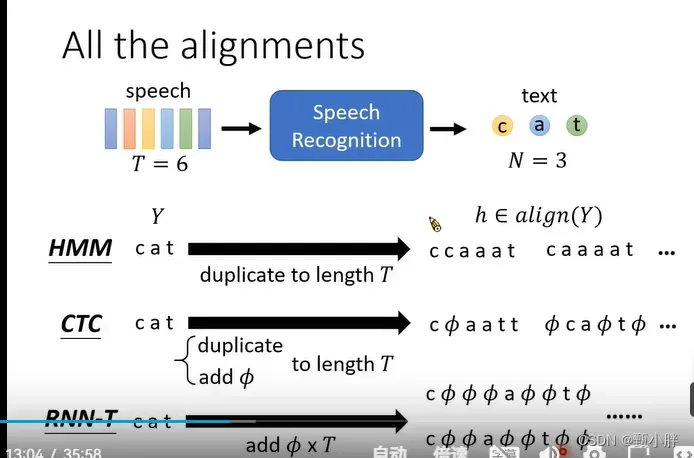
HMM:将state 重复进行align
CTC:可以重复或者插入nuo
RNN-T:插入nuo,直到认为结束
RNN-T损失函数
损失函数不一定是真的损失,即正确值与预测值的差距,也可以是一个概率值,即求-概率的最小值。所以,损失函数就是我们要优化的一个对象,既可以是概率,也可以是两个东西之间的差值。

https://www.modb.pro/db/176105
CNN为什么train不动或不稳定
感觉训练的trick有很多,我这里改小lr到0.0001就可以了,真的很小了。
发现了几篇不错的训练trick文章,有机会看。
(强推)https://blog.csdn.net/ytusdc/article/details/107738749
https://blog.csdn.net/hustqb/article/details/78648556
https://zhuanlan.zhihu.com/p/36369878
为什么测试集效果好于验证集
说明泛化能力真的很好???
太多padding会对训练造成什么影响
—-2213跑完步看完翻译和日语准备睡啦~
文章出处登录后可见!