双目视觉深度——GC-Net算法详解 / Cost Volume模块详解
在之前的工作中有接触过Stereo Depth这个方向,在读书期间也有用过ZED这样的传感器,但是一直没有对这个方向进行过系统的学习,因此我打算这段时间花点时间学习下这方面的知识,之前有写过一篇相关的文档双目视觉深度——SGM中的动态规划,SGM主要思想是基于动态优化,NN发展后逐渐衍生出了基于Feature进行Match的方法,再后来就是Cost Volume方法的提出,以及最近这两年比较火的基于Transformer的方法。
本篇博客主要是以GC-Net为例,解释什么是Cost Volume以及为什么要用3D卷积来进行推理。GC-Net发表于2017年CVPR,原论文名为《End-to-End Learning of Geometry and Context for Deep Stereo Regression》,是最开始提出Cost Volume的方法之一。基于GC-Net的优化方法,例如PSM-Net、GA-Net、AA-Net等会在另外一篇博客总结。
1. 网络结构
GC-Net网络结构如下图所示:
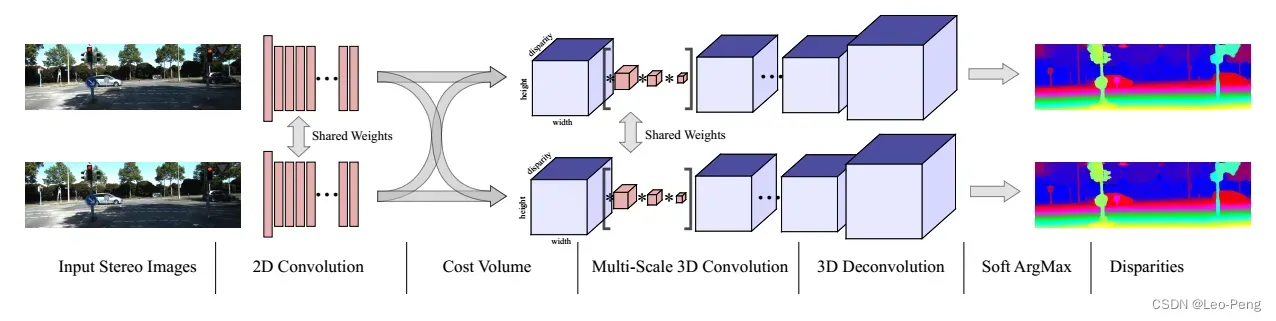
具体的参数如下表:

网络主要分为三部分:用于提取Feature的2D卷积、Cost Volume的构造以及3D卷积,下面我们结合代码来开拿下具体是如何实现的(代码参考的是zyf12389/GC-Net,因为是复现的代码,代码实现和原论文可能稍微有些细微差别):
特征提取部分第一层首先对输入图片进行一个下采样,然后接了一个ResNet的Backbone,从ResNet输出的特征大小为
,代码如下:
imgl0=F.relu(self.bn0(self.conv0(imgLeft)))
imgr0=F.relu(self.bn0(self.conv0(imgRight)))
imgl_block=self.res_block(imgl0)
imgr_block=self.res_block(imgr0)
imgl1=self.conv1(imgl_block)
imgr1=self.conv1(imgr_block)
然后就是利用特征构建Cost Volume,构建Cost Volume的目的是为了将视差这一概念表达在网络结构中,这其实很好理解,如下图所示,如果我们仅仅将两张图的图像特征简单地叠到一起,网络怎么知道A处和B处有特征有对应关系呢,可想而知是很困难的,而我们如果能够根据视差将A处和B处的的特征进行对齐,然后再进行卷积,网络学习到A处和B处的对应关系就会简单很多,而Cost Volume就是将所有可能的视差遍历一遍,让网络更容易学习到不同视差下的特征的对应关系:
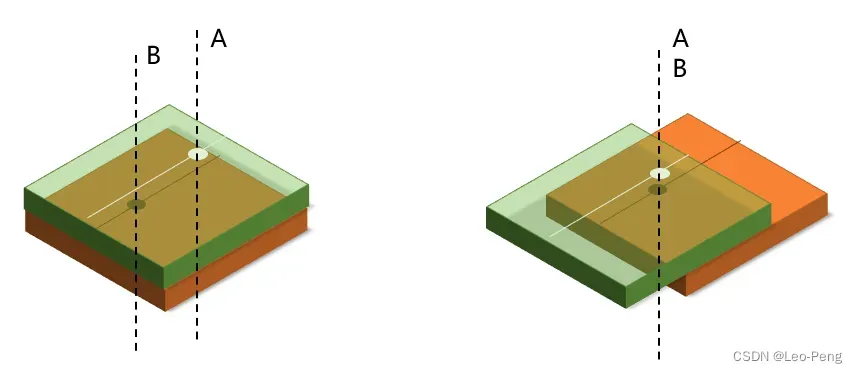
cost_volum = self.cost_volume(imgl1,imgr1)
def cost_volume(self,imgl,imgr):
xx_list = []
pad_opr1 = nn.ZeroPad2d((0, self.maxdisp, 0, 0))
xleft = pad_opr1(imgl)
for d in range(self.maxdisp): # maxdisp+1 ?
pad_opr2 = nn.ZeroPad2d((d, self.maxdisp - d, 0, 0))
xright = pad_opr2(imgr)
xx_temp = torch.cat((xleft, xright), 1)
xx_list.append(xx_temp)
xx = torch.cat(xx_list, 1)
xx = xx.view(self.batch, self.maxdisp, 64, int(self.height / 2), int(self.width / 2) + self.maxdisp)
xx0=xx.permute(0,2,1,3,4)
xx0 = xx0[:, :, :, :, :int(self.width / 2)]
return xx0
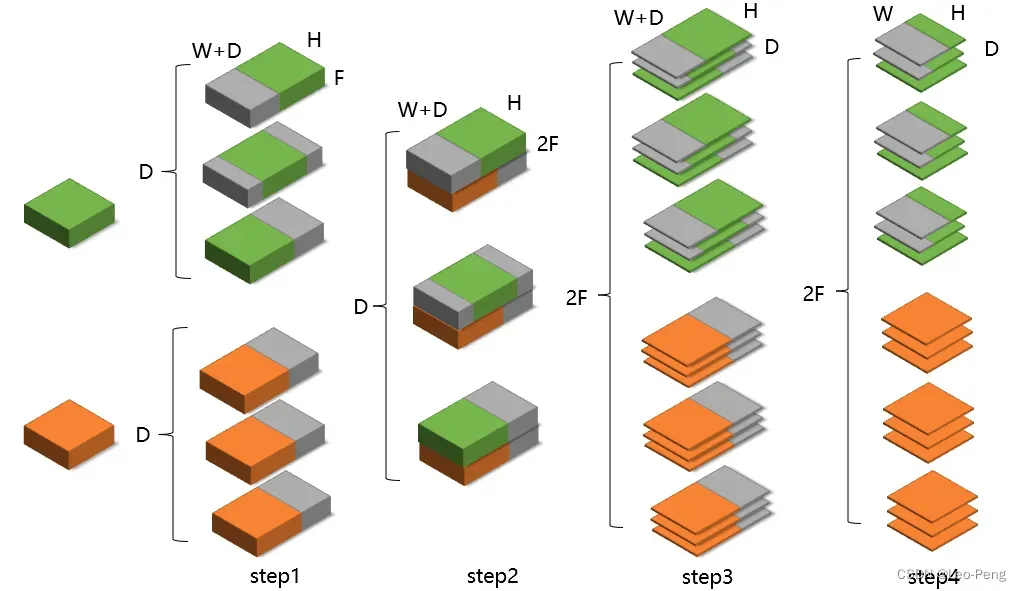
我们可以看到实际的构建流程是:
(1)先利用ZeroPad2d将左图特征从大小填充为
大小,其中
为入参定义的最大视差;
(2)然后将右图特征也填充为大小,与左图特征不同的是,左图特征是将填充集中在原始特征的右侧,而右图则是按照视差从小达到的变化逐渐调整原始特征左右的填充列数;
(3)接着将左右特征按行方向Concat到一起;
(4)最后拼接成的特征图调整为大小,具体流程如下图所示:
cost = Variable(torch.FloatTensor(refimg_fea.size()[0], refimg_fea.size()[1]*2, self.maxdisp/4, refimg_fea.size()[2], refimg_fea.size()[3]).zero_(), volatile= not self.training).cuda()
for i in range(self.maxdisp/4):
if i > 0 :
cost[:, :refimg_fea.size()[1], i, :,i:] = refimg_fea[:,:,:,i:]
cost[:, refimg_fea.size()[1]:, i, :,i:] = targetimg_fea[:,:,:,:-i]
else:
cost[:, :refimg_fea.size()[1], i, :,:] = refimg_fea
cost[:, refimg_fea.size()[1]:, i, :,:] = targetimg_fea
cost = cost.contiguous()
仔细对比可以发现其实构建的Cost Volume是大同小异的,如下图所示:
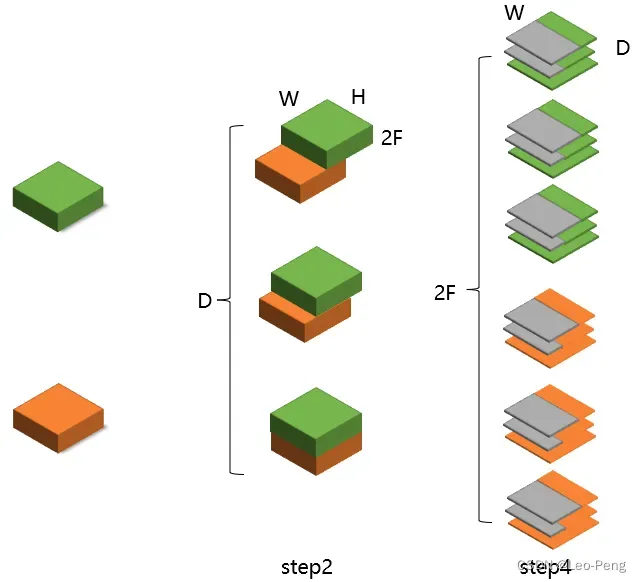
通过上述Cost Volume,我们得到的是个
大小的3D特征图,紧接着我们就是在上述3D特征图进行3D卷积,如下所示:
conv3d_out=F.relu(self.bn3d_1(self.conv3d_1(cost_volum)))
conv3d_out=F.relu(self.bn3d_2(self.conv3d_2(conv3d_out)))
conv3d_block_1=self.block_3d_1(cost_volum)
conv3d_21=F.relu(self.bn3d_3(self.conv3d_3(cost_volum)))
conv3d_block_2=self.block_3d_2(conv3d_21)
conv3d_24=F.relu(self.bn3d_4(self.conv3d_4(conv3d_21)))
conv3d_block_3=self.block_3d_3(conv3d_24)
conv3d_27=F.relu(self.bn3d_5(self.conv3d_5(conv3d_24)))
conv3d_block_4=self.block_3d_4(conv3d_27)
deconv3d=F.relu(self.debn1(self.deconv1(conv3d_block_4))+conv3d_block_3)
deconv3d=F.relu(self.debn2(self.deconv2(deconv3d))+conv3d_block_2)
deconv3d=F.relu(self.debn3(self.deconv3(deconv3d))+conv3d_block_1)
deconv3d=F.relu(self.debn4(self.deconv4(deconv3d))+conv3d_out)
为了减小计算量,3D卷积的过程是一个类似U-Net的结构,先对特征图进行Down Sample,然后通过再通过转置卷积进行Up Sample,对于转置卷积不了解的同学可以参考下计算机视觉算法——图像分割网络总结,其中我对2D转置卷积的原理和计算过程进行了详细的分析,这里就不再赘述(其中ConvTranspose3d的output_padding设置为1是为了保证输入输出特征图大小一致)。
最后就是从输出特征中获取视差,论文中还特地提到了他们建立的是一种Soft Argmin获取视差,3D卷积最后的输出特征图大小为,我们很直接想到的一种方式是在输出特征的视差维度上取Argmin或者Argmax,但是论文中提到,这种方式无法获得亚像素级的视差以且不可微,因此论文通过Soft Argmin获取视差,其实就是在视差维度进行Softmax后然后进行加权平均:
其中,
为视差,
为Softmax操作,
为输出的特征,具体代码如下:
loss_mul_list = []
for d in range(maxdisp):
loss_mul_temp = Variable(torch.Tensor(np.ones([batch, 1, h, w]) * d)).cuda()
loss_mul_list.append(loss_mul_temp)
loss_mul = torch.cat(loss_mul_list, 1)
x = net(left_image, right_image)
result = torch.sum(x.mul(loss_mul), 1)
获得视差后最后构建损失,至此就完成了整个网络结构的介绍。
2. KITTI数据集实验
因为疫情原因端午节被关在家里,闲着没事我用一个下午的时间使用KITTI2015 Stereo的数据集训了一把GC-Net,但是仅仅只是打通一下流程,方便后面尝试其他网络,并没有训得很仔细,所以读者不用很在意结果,但有几点要说明的是:
(1)KITTI2015 Stereo的数据集的Ground是通过激光采集的,因此训练过程中需要注意的一点是需要在Loss上加一个Mask;
(2)由于训练集上天空部分没有监督,因此测试集上天空深度势必会比较糟糕;
(3)KITTI2015 Stereo的数据集训练集只有200张图片(感觉好少);
我按照参考代码的设置训了90个Epoch后在测试集上可视化结果如下所示:

gc_net.py
import torch
import torch.nn as nn
import torch.nn.functional as F
class BasicBlock(nn.Module): #basic block for Conv2d
def __init__(self,in_planes,planes,stride=1):
super(BasicBlock,self).__init__()
self.conv1=nn.Conv2d(in_planes,planes,kernel_size=3,stride=stride,padding=1)
self.bn1=nn.BatchNorm2d(planes)
self.conv2=nn.Conv2d(planes,planes,kernel_size=3,stride=1,padding=1)
self.bn2=nn.BatchNorm2d(planes)
self.shortcut=nn.Sequential()
def forward(self, x):
out=F.relu(self.bn1(self.conv1(x)))
out=self.bn2(self.conv2(out))
out+=self.shortcut(x) # residual part
out=F.relu(out)
return out
class ThreeDConv(nn.Module):
def __init__(self,in_planes,planes,stride=1):
super(ThreeDConv, self).__init__()
self.conv1 = nn.Conv3d(in_planes, planes, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm3d(planes)
self.conv2 = nn.Conv3d(planes, planes, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm3d(planes)
self.conv3=nn.Conv3d(planes,planes,kernel_size=3,stride=1,padding=1)
self.bn3=nn.BatchNorm3d(planes)
def forward(self, x):
out=F.relu(self.bn1(self.conv1(x)))
out=F.relu(self.bn2(self.conv2(out)))
out=F.relu(self.bn3(self.conv3(out)))
return out
class GC_NET(nn.Module):
def __init__(self,block,block_3d,num_block,height,width,maxdisp,batch):
super(GC_NET, self).__init__()
self.height=height
self.width=width
self.maxdisp=int(maxdisp/2)
self.batch = batch
self.in_planes=32
#first two conv2d
self.conv0=nn.Conv2d(3,32,5,2,2) # in=3, out=32, kernel_size=5, stride=2, padding=2, (N + 2*2 - 5) / 2 + 1
self.bn0=nn.BatchNorm2d(32)
#res block
self.res_block=self._make_layer(block,self.in_planes,32,num_block[0],stride=1)
#last conv2d
self.conv1=nn.Conv2d(32,32,3,1,1)
#self.bn1=nn.BatchNorm2d(32) #not sure this layer needs bn or relu
#conv3d
self.conv3d_1=nn.Conv3d(64,32,3,1,1) # in=64, out=32, kernel_size=3x3x3, stride=1, padding=1
self.bn3d_1=nn.BatchNorm3d(32)
self.conv3d_2=nn.Conv3d(32,32,3,1,1)
self.bn3d_2=nn.BatchNorm3d(32)
self.conv3d_3=nn.Conv3d(64,64,3,2,1)
self.bn3d_3=nn.BatchNorm3d(64)
self.conv3d_4=nn.Conv3d(64,64,3,2,1)
self.bn3d_4=nn.BatchNorm3d(64)
self.conv3d_5=nn.Conv3d(64,64,3,2,1)
self.bn3d_5=nn.BatchNorm3d(64)
#conv3d sub_sample block
self.block_3d_1 = self._make_layer(block_3d, 64, 64, num_block[1], stride=2) # in=64, out=64, kernel_size=3x3x3, stride=2, padding=1
self.block_3d_2 = self._make_layer(block_3d, 64, 64, num_block[1], stride=2)
self.block_3d_3 = self._make_layer(block_3d, 64, 64, num_block[1], stride=2)
self.block_3d_4 = self._make_layer(block_3d, 64, 128, num_block[1], stride=2)
#deconv3d
self.deconv1=nn.ConvTranspose3d(128, 64, 3, 2, 1, 1) # in=64, out=32, kernel_size=3x3x3, padding=1, stride=1, output_padding=1
self.debn1=nn.BatchNorm3d(64)
self.deconv2 = nn.ConvTranspose3d(64, 64, 3, 2, 1, 1)
self.debn2 = nn.BatchNorm3d(64)
self.deconv3 = nn.ConvTranspose3d(64, 64, 3, 2, 1, 1)
self.debn3 = nn.BatchNorm3d(64)
self.deconv4 = nn.ConvTranspose3d(64, 32, 3, 2, 1, 1)
self.debn4 = nn.BatchNorm3d(32)
#last deconv3d
self.deconv5 = nn.ConvTranspose3d(32, 1, 3, 2, 1, 1)
#self.debn5=nn.BatchNorm3d(1) #not sure
def forward(self, imgLeft,imgRight):
imgl0=F.relu(self.bn0(self.conv0(imgLeft)))
imgr0=F.relu(self.bn0(self.conv0(imgRight)))
imgl_block=self.res_block(imgl0)
imgr_block=self.res_block(imgr0)
imgl1=self.conv1(imgl_block)
imgr1=self.conv1(imgr_block)
# cost volume
cost_volum = self.cost_volume(imgl1,imgr1)
conv3d_out=F.relu(self.bn3d_1(self.conv3d_1(cost_volum)))
conv3d_out=F.relu(self.bn3d_2(self.conv3d_2(conv3d_out)))
#conv3d block
conv3d_block_1=self.block_3d_1(cost_volum)
conv3d_21=F.relu(self.bn3d_3(self.conv3d_3(cost_volum)))
conv3d_block_2=self.block_3d_2(conv3d_21)
conv3d_24=F.relu(self.bn3d_4(self.conv3d_4(conv3d_21)))
conv3d_block_3=self.block_3d_3(conv3d_24)
conv3d_27=F.relu(self.bn3d_5(self.conv3d_5(conv3d_24)))
conv3d_block_4=self.block_3d_4(conv3d_27)
#deconv
deconv3d=F.relu(self.debn1(self.deconv1(conv3d_block_4))+conv3d_block_3)
deconv3d=F.relu(self.debn2(self.deconv2(deconv3d))+conv3d_block_2)
deconv3d=F.relu(self.debn3(self.deconv3(deconv3d))+conv3d_block_1)
deconv3d=F.relu(self.debn4(self.deconv4(deconv3d))+conv3d_out)
#last deconv3d
deconv3d=self.deconv5(deconv3d)
out=deconv3d.view(self.batch, self.maxdisp*2, self.height, self.width)
prob=F.softmax(-out,1)
return prob
def _make_layer(self,block,in_planes,planes,num_block,stride): # num_block=8, stride=1
strides=[stride]+[1]*(num_block-1)
layers=[]
for step in strides:
layers.append(block(in_planes,planes,step))
return nn.Sequential(*layers)
def cost_volume(self,imgl,imgr):
xx_list = []
pad_opr1 = nn.ZeroPad2d((0, self.maxdisp, 0, 0))
xleft = pad_opr1(imgl)
for d in range(self.maxdisp): # maxdisp+1 ?
pad_opr2 = nn.ZeroPad2d((d, self.maxdisp - d, 0, 0))
xright = pad_opr2(imgr)
xx_temp = torch.cat((xleft, xright), 1)
xx_list.append(xx_temp)
xx = torch.cat(xx_list, 1)
xx = xx.view(self.batch, self.maxdisp, 64, int(self.height / 2), int(self.width / 2) + self.maxdisp)
xx0=xx.permute(0,2,1,3,4)
xx0 = xx0[:, :, :, :, :int(self.width / 2)]
return xx0
def loss(xx,loss_mul,gt):
loss=torch.sum(torch.sqrt(torch.pow(torch.sum(xx.mul(loss_mul),1)-gt,2)+0.00000001)/256/(256+128))
return loss
def GcNet(height,width,maxdisp,batch):
return GC_NET(BasicBlock,ThreeDConv,[8,1],height,width,maxdisp,batch)
kitti_dataset.py
import cv2
import numpy as np
from torch.utils.data import Dataset
class KittiDataset(Dataset):
def __init__(self, root_dir, is_train=False):
super().__init__()
self.root_dir = root_dir
self.is_train = is_train
self.left_disp_dir = os.path.join(root_dir, 'disp_occ_0')
self.left_image_dir = os.path.join(root_dir, 'image_2')
self.right_image_dir = os.path.join(root_dir, 'image_3')
self.left_disp_path_list = []
self.left_image_path_list = []
self.right_image_path_list = []
for file in os.listdir(self.left_image_dir):
if self.is_train:
if file in os.listdir(self.left_disp_dir):
self.left_disp_path_list.append(os.path.join(self.left_disp_dir, file))
self.left_image_path_list.append(os.path.join(self.left_image_dir, file))
self.right_image_path_list.append(os.path.join(self.right_image_dir, file))
else:
self.left_image_path_list.append(os.path.join(self.left_image_dir, file))
self.right_image_path_list.append(os.path.join(self.right_image_dir, file))
def __len__(self):
return len(self.left_image_path_list)
def __getitem__(self, idx):
left_image = cv2.imread(self.left_image_path_list[idx], cv2.IMREAD_UNCHANGED)
left_image = cv2.resize(left_image, (1242, 375))
right_image = cv2.imread(self.right_image_path_list[idx], cv2.IMREAD_UNCHANGED)
right_image = cv2.resize(right_image, (1242, 375))
sample = {
'left_image': left_image,
'right_image': right_image,
}
if self.is_train:
left_disp = cv2.imread(self.left_disp_path_list[idx], cv2.IMREAD_UNCHANGED).astype(np.int32) / 256
left_disp = cv2.resize(left_disp, (1242, 375))
sample['left_disp'] = left_disp
return sample
main.py
import cv2
import torch
import torch.nn as nn
import torch.nn.init as init
import numpy as np
from torch.autograd import Variable
from kitti_dataset import KittiDataset
from gc_net import GcNet
# some parameters about net
h=256
w=256
maxdisp=160
batch=1
net = GcNet(h, w, maxdisp, batch)
net.cuda()
def init_params(net):
for m in net.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.Conv3d):
init.kaiming_normal_(m.weight, mode='fan_out')
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d) or isinstance(m, nn.BatchNorm3d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=1e-3)
init.constant_(m.bias, 0)
def train(load_state):
loss_mul_list = []
for d in range(maxdisp):
loss_mul_temp = Variable(torch.Tensor(np.ones([batch, 1, h, w]) * d)).cuda()
loss_mul_list.append(loss_mul_temp)
loss_mul = torch.cat(loss_mul_list, 1)
optimizer = torch.optim.RMSprop(net.parameters(), lr=0.001, alpha=0.9)
loss_fn=torch.nn.L1Loss()
dataset = KittiDataset('/home/leo/Desktop/Data/data_scene_flow/training', is_train=True)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch, shuffle=True, num_workers=1)
epoch_total = 100
if load_state==True:
checkpoint = torch.load('./checkpoint/ckpt.t7')
net.load_state_dict(checkpoint['net'])
start_epoch = checkpoint['epoch']
else:
init_params(net)
start_epoch = 0
for epoch in range(start_epoch, epoch_total):
net.train()
data_iter = iter(dataloader)
for step in range(len(dataloader)-1):
print('----epoch:%d------step:%d------' %(epoch, step))
data = next(data_iter)
left_image = data['left_image'].permute((0, 3, 1, 2))
right_image = data['right_image'].permute((0, 3, 1, 2))
left_disp = data['left_disp']
m = np.random.randint(0, left_image.shape[2]-h)
n = np.random.randint(0, left_image.shape[3]-w)
left_image = left_image[:, :, m:(m+h), n: (n+w)].type(torch.FloatTensor).cuda()
right_image = right_image[:, :, m:(m+h), n: (n+w)].type(torch.FloatTensor).cuda()
left_disp = left_disp[:, m: (m+h), n: (n+w)].type(torch.FloatTensor).cuda()
net.zero_grad()
optimizer.zero_grad()
x = net(left_image, right_image)
result = torch.sum(x.mul(loss_mul), 1)
loss = loss_fn(result[left_disp != 0], left_disp[left_disp != 0])
loss.backward()
optimizer.step()
result = result.view(batch, h, w)
diff = torch.abs(result.data.cpu() - left_disp.data.cpu())[left_disp != 0]
accuracy = torch.sum(diff<3)/float(torch.sum(left_disp != 0))
print(f'loss: {loss.data}, accuracy: {accuracy}')
if (step>1 and step%200==0) or step==len(dataloader)-2:
print('=======>saving model......')
state={'net':net.state_dict(),'step':step,'epoch':epoch}
torch.save(state,'checkpoint/ckpt.t7')
image = result[0, :, :].data.cpu().numpy().astype('uint8')
cv2.imwrite(f'./debug/train_result_{epoch}_{step}.png', image)
gt = left_disp[0, :, :].data.cpu().numpy().astype('uint8')
cv2.imwrite(f'./debug/train_gt_{epoch}_{step}.png', gt)
def test():
loss_mul_list = []
for d in range(maxdisp):
loss_mul_temp = Variable(torch.Tensor(np.ones([batch, 1, h, w]) * d)).cuda()
loss_mul_list.append(loss_mul_temp)
loss_mul = torch.cat(loss_mul_list, 1)
dataset = KittiDataset('/home/leo/Desktop/Data/data_scene_flow/testing', is_train=False)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch, shuffle=True, num_workers=1)
checkpoint = torch.load('./checkpoint/ckpt.t7')
net.load_state_dict(checkpoint['net'])
net.eval()
data_iter = iter(dataloader)
for step in range(len(dataloader)-1):
print('-----step:%d------' %(step))
data = next(data_iter)
left_image = data['left_image'].permute((0, 3, 1, 2))
right_image = data['right_image'].permute((0, 3, 1, 2))
m = np.random.randint(0, left_image.shape[2]-h)
n = np.random.randint(0, left_image.shape[3]-w)
left_image = left_image[:, :, m:(m+h), n: (n+w)].type(torch.FloatTensor).cuda()
right_image = right_image[:, :, m:(m+h), n: (n+w)].type(torch.FloatTensor).cuda()
x = net(left_image, right_image)
result = torch.sum(x.mul(loss_mul), 1)
result = result.view(batch, h, w)
output_disp = result[0, :, :].data.cpu().numpy().astype('uint8')
output_disp_color = cv2.applyColorMap(output_disp, cv2.COLORMAP_JET)
input_image = np.transpose(left_image[0, :, :, :].data.cpu().numpy().astype('uint8'), (1, 2, 0))
image = cv2.hconcat([input_image, output_disp_color])
cv2.imwrite(f'./test/left_image_{step}.png', image)
def main():
# train(load_state=True)
test()
if __name__ =='__main__':
main()
文章出处登录后可见!