AIGC实战——自回归模型
-
- 0. 前言
- 1. 长短期记忆网络基本原理
- 2. Recipes 数据集
- 3. 处理文本数据
-
- 3.1 文本与图像数据处理的差异
- 3.2 文本数据处理步骤
- 4. 构建 LSTM 模型
-
- 4.1 模型架构
- 4.2 LSTM 计算流程
- 4.3 训练 LSTM
- 5. LSTM 模型分析
- 小结
- 系列链接
0. 前言
自回归模型 (Autoregressive Model) 通过将生成问题视为一个序列过程来简化生成模型。自回归模型将预测条件建立在序列中的先前值上,而不是一个以随机潜变量为条件。因此,自回归模型尝试对数据生成分布进行显式建模,而不是尝试近似数据分布。在本节中,将介绍一类经典的自回归模型,长短期记忆网络 (Long Short-Term Memory Network, LSTM),并将 LSTM 应用于生成文本数据。
1. 长短期记忆网络基本原理
长短期记忆网络 (Long Short-Term Memory Network, LSTM) 是一种特殊类型的循环神经网络 (Recurrent Neural Network, RNN)。RNN 包含一个循环层(或单元),该层能够通过使其在特定时间步长的输出作为下一时间步长的输入的一部分来处理序列数据,LSTM 网络是拥有 LSTM 循环层的神经网络。
原始 RNN 中,循环层非常简单,仅由 tanh 操作组成,用于确保在时间步之间传递的信息被缩放至 -1 和 1 之间。然而,实践表明这种方法存在梯度消失问题,并且无法很好的处理长序列数据。
LSTM 单元不会像普通 RNN 那样出现梯度消失问题,并且能够在数百个时间步长的序列进行训练。为了提高网络性能,LSTM 架构随后被进一步改进,如门控循环单元 (Gated Recurrent Units, GRU) 等。
LSTM 能够应用于解决涉及序列数据的各种问题,包括时间序列预测、情感分析和音频分类等。在本节中,我们将使用 LSTM 处理文本生成问题。
2. Recipes 数据集
为了训练 LSTM,生成文本数据,我们将使用 Epicurious Recipes 数据集,这是一组包含超过 20,000 个菜谱配方的数据集,并附带有营养信息和成分清单等相关元数据,该数据集可以在 Kaggle 网站上下载。下载数据集后,将菜谱配方及其相关元数据保存在 ./data 文件夹中。
加载并过滤数据,以便只保留具有标题和描述的菜谱配方:
# 加载并过滤数据
with open("./data/full_format_recipes.json") as json_data:
recipe_data = json.load(json_data)
filtered_data = [
"Recipe for " + x["title"] + " | " + " ".join(x["directions"])
for x in recipe_data
if "title" in x
and x["title"] is not None
and "directions" in x
and x["directions"] is not None
]
数据集中示例样本如下所示:

在使用 Keras 构建 LSTM 网络之前,我们首先需要了解文本数据的结构以及它与图像数据的不同之处。
3. 处理文本数据
3.1 文本与图像数据处理的差异
文本和图像数据之间的差异性导致许多适用于图像数据的方法并不适用于文本数据:
- 文本数据由离散的字符或单词组成,而图像中的像素是连续色谱中的点。我们可以轻易地将绿色像素变得偏向蓝色,但是却无法使单词 “
cat” 更像单词 “dog”。这意味着我们可以轻易地将反向传播应用于图像数据生成,因为我们可以计算出损失函数相对于单个像素的梯度,以确定像素颜色应该如何改变以最小化损失。而对于离散的文本数据,我们不能以同样的方式应用反向传播,所以为了生成文本,首先需要解决这一问题 - 文本数据具有时间维度但没有空间维度,而图像数据具有空间维度但没有时间维度。单词的顺序性在文本数据中非常重要,逆序后的文本通常没有任何意义,而图像通常在翻转后并不会改变其类别。此外,单词之间通常存在着长期的顺序依赖关系,模型需要捕获这些依赖关系:例如,回答问题通常需要联系问题的上下文,而对于图像数据,所有像素都可以同时处理
- 文本数据对单个单元(单词或字符)的微小变化非常敏感。图像数据对单个像素单位的变化通常不太敏感——即使一些像素发生了改变,一个房子的图片仍然能够被认出为一个房子。但是对于文本数据,即使改变几个单词,也可能会严重改变段落的语义,甚至使其表达相反的含义。由于每个单词对于整个文本而言都十分重要,因此训练模型生成连贯文本非常困难
- 文本数据具有基于规则的语法结构,而图像数据不遵循关于像素值应如何分配的固定规则。例如,在任何情况下以下句子都毫无语法意义,“一个人火箭跳舞沙漠”
接下来,我们介绍需要采取哪些步骤以使文本数据适合训练 LSTM 网络。
3.2 文本数据处理步骤
3.2.1 分词
第一步是清理文本,并将文本转化为符号 (token),分词 (Tokenization) 就是将文本分割成单独的符号(例如单词或字符)的过程。
如何对文本进行分词取决于文本生成模型需要实现的目标。使用单词符号和字符符号都各有利弊,不同的选择选择会影响建模之前所需的文本清理方式以及模型输出。
如果使用单词符号:
- 所有文本可以转换为小写,以确保句子开头的大写单词与句子中间出现的相同单词能够转换成同一个符号。然而,在某些情况下,这可能并不是理想的方式。例如,一些专有名词(如姓名或地点)应当保留大写形式,以便它们可以被转换成单独的符号
- 文本词汇表 (
vocabulary, 训练集中不同单词的集合)可能非常大,有些单词可能出现的频率很小,甚至只出现一次。与其将它们作为单独的符号,更合理的做法是将这些单词转换为 “unknown” 的符号,以减少神经网络需要学习的权重数量 - 单词可以进行词干处理 (
stemmed),即将它们简化为最简单的形式,以便将一个动词的不同时态转换为同一个符号。例如,browse、browsing、browses和browsed的词干均为brows - 标点符号可以转换为符号,也可以全部删除
- 使用单词标记化意味着模型永远无法预测训练词汇表之外的单词
如果使用字符符号:
- 模型可以生成训练词汇表之外的字符序列,构成新单词,在某些情况下这种做法可能非常有效,但在有些情况下则不然
- 大写字母可以转换为小写字母,也可以保留为单独的符号
- 使用字符符号时,词汇表通常要小得多,这可以提高模型的训练速度,因为最终输出层中需要学习的权重较少。
在本节中,我们使用小写单词分词,且不进行词干提取。我们还将标点符号转换为符号,因为我们希望模型能够预测句子的结束或使用逗号等标点符号:
# Pad the punctuation, to treat them as separate 'words'
def pad_punctuation(s):
s = re.sub(f"([{string.punctuation}])", r" \1 ", s)
s = re.sub(" +", " ", s)
return s
# 在标点符号周围添加填充,将其视为单独的词
text_data = [pad_punctuation(x) for x in filtered_data]
# Display an example of a recipe
example_data = text_data[9]
print(example_data)
# 转换为 TensorFlow 数据集
text_ds = (
tf.data.Dataset.from_tensor_slices(text_data)
.batch(BATCH_SIZE)
.shuffle(1000)
)
# 创建 Keras TextVectorization 层,将文本转换为小写,将最常见的 10,000 个单词转换为相应的整数符号,并将序列长度裁剪或填充为 201 个符号
vectorize_layer = layers.TextVectorization(
standardize="lower",
max_tokens=VOCAB_SIZE,
output_mode="int",
output_sequence_length=MAX_LEN + 1,
)
# 将 TextVectorization 层应用于训练数据
vectorize_layer.adapt(text_ds)
# vocab 变量用于存储单词符号的列表
vocab = vectorize_layer.get_vocabulary()
在训练模型时使用的序列长度是训练过程的超参数,在本节中,我们选择使用长度为 200 的序列,因此需要对食谱进行填充或剪裁,使其长度为 201,以便创建目标变量。分词后的食谱样本如下所示,为了得到期望长度,向量的末尾使用 0 进行填充:符号 0 称为停止标记 (Stop Tokens),表示文本字符串已经结束。

在下图中,可以看到一部分符号的列表,并将它们映射到各自的索引,在本节中,填充符号同样使用 0 符号(即停止标记),并将不在词汇表(频率最高的前 10,000 个单词)中的未知单词标记为符号 1。其他单词按频率顺序分配符号,词汇表中包含的单词数量也是训练过程的一个超参数,词汇表中包含的单词越多,文本中出现的未知符号越少,但模型规模也将更大以容纳更大规模的词汇表。

3.2.2 创建训练集
LSTM 网络经过训练后,可以根据给定的单词序列预测序列中的下一个单词。例如,我们可以将 “grilled chicken with boiled” 的对应的符号输入模型,模型应当能够输出恰当的下一个单词(例如 potatoes,而不是 bananas)。
因此,我们只需将整个序列向后移动一个符号,就可以创建目标变量:
def prepare_inputs(text):
text = tf.expand_dims(text, -1)
tokenized_sentences = vectorize_layer(text)
x = tokenized_sentences[:, :-1]
y = tokenized_sentences[:, 1:]
return x, y
# 创建训练集,其包含食谱符号(输入)和向后移动一个符号的相同食谱符号(目标变量)
train_ds = text_ds.map(prepare_inputs)
4. 构建 LSTM 模型
4.1 模型架构
LSTM 模型的整体架构下图所示,模型的输入是整数符号序列,输出是词汇表中每个单词出现在序列下一个位置的概率。为了详细了解其工作原理,我们需要介绍两种新的层类型,Embedding 和 LSTM。

需要注意的是,输入层不需要提前指定序列长度。批大小和序列长度都是灵活的(因此形状为 (None,None)),这是因为所有下游层与传递的序列长度是无关的。
嵌入层
嵌入层 (Embedding Layer) 本质上是一个查找表,将每个符号转换为长度为 embedding_size 的向量,如下图所示。查找向量由模型作为权重进行学习。因此,该层学习的权重数量等于词汇表大小乘以嵌入向量的维度(即 10,000 × 100 = 1,000,000)。
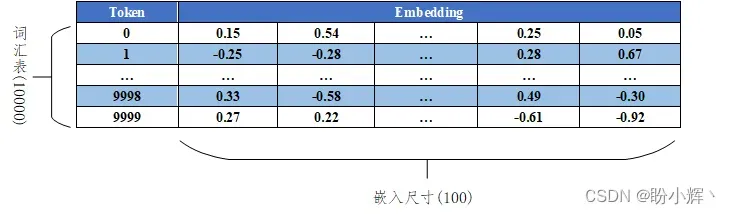
我们将每个符号嵌入到连续的向量中,使得模型能够学习每个单词的表示,且这个表示可以通过反向传播进行更新。我们也可以只对每个输入标记进行独热编码,但使用嵌入层效果更好,因为嵌入本身可训练,从而使模型更具灵活性。
因此,输入层将形状为 [batch_size,seq_length] 的整数序列张量传递给嵌入层,嵌入层输出形状为 [batch_size,seq_length,embedding_size] 的张量,然后将其传递给 LSTM 层。
LSTM 层
为了理解 LSTM 层,我们首先需要了解一般循环层的工作原理。
循环层具有一个特殊的性质,能够处理序列输入数据 。它由一个单元格 (
cell) 组成,每个序列元素 逐个通过单元传递时,该单元格就会更新其隐藏状态
(
hidden state),该操作每个时间步进行一次。
隐藏状态是一个长度与单元格中的单元 (unit) 数相等的向量,可以把它视为单元格对序列的当前理解。在时间步 ,单元格使用先前隐藏状态
以及当前时间步
的数据来生成更新后的隐藏状态向量
。此循环过程一直持续到序列结束,序列处理结束后,该层输出单元格的最终隐藏状态
,然后将其传递到网络的下一层。
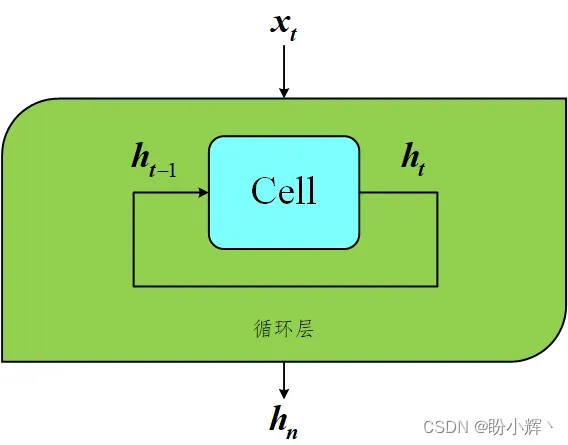
为了详细说明,我们继续深入此过程。观察序列通过该层的过程。
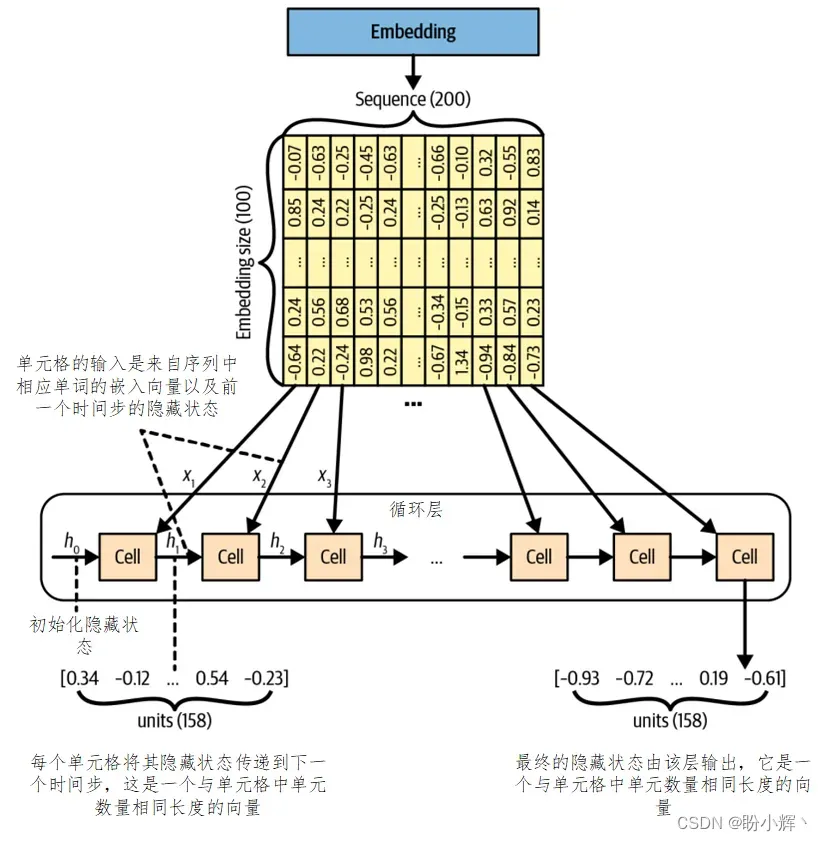
在这个循环过程中,我们绘制了每个时间步的单元格,并显示了隐藏层在流经单元格时不断更新的过程。我们可以清楚地看到前一个隐藏状态与当前的序列数据点(即当前的嵌入词向量)混合后生成下一隐藏状态。当输入序列中的每个单词都处理完成后,该层将输出单元格的最终隐藏状态。需要注意的是,上图中的所有单元格都使用同一个权重,因为实际上它们是同一个单元格,以上两个图没有任何区别,只是我们使用不同的方式描绘了循环层的内部机制。
该单元格的输出称为隐藏状态 (hidden state),实际上只是一种命名惯例,它实际上并不是真的隐藏了。事实上,最后的隐藏状态是该层的输出,我们可以在每个单个时间步访问这个隐藏状态。
LSTM 单元格
我们已经了解了通用循环层的工作原理,接下来,我们深入了解 LSTM 单元格的工作原理。
LSTM 单元格的作用是根据其先前的隐藏状态 和当前的词嵌入向量
,输出新的隐藏状态
。
的长度等于
LSTM 中的单元数,这是在定义该层时设置的一个超参数,与序列的长度无关。
需要注意的时,不要混淆单元 (unit) 与单元格 (cell)。LSTM 层中有一个单元格,由其包含的单元数来定义,我们通常将循环层绘制成一系列展开的单元格,这种可视化方式可以了解隐藏状态在每个时间步的更新情况。
一个 LSTM 单元格负责维护一个单元格状态 ,可以看作是单元格对序列当前状态的内部理解。这与隐藏状态
不同,隐藏状态
是单元格在最后一个时间步上的输出。单元格状态的长度与隐藏状态相同(单元格中的单元数)。
接下来,我们继续了解 LSTM 中的单元格及其如何更新隐藏状态。
4.2 LSTM 计算流程
隐藏状态通过以下六个步骤进行更新:
- 将前一个时间步的隐藏状态
和当前的词嵌入
连接在一起,并通过遗忘门 (
forget gate) 传递。遗忘门只是一个具有权重矩阵、偏置
和
sigmoid激活函数的函数。所得向量的长度等于单元格中的单元数,其值介于
0和1之间,表示前一个单元格状态单元状态应该保留多少
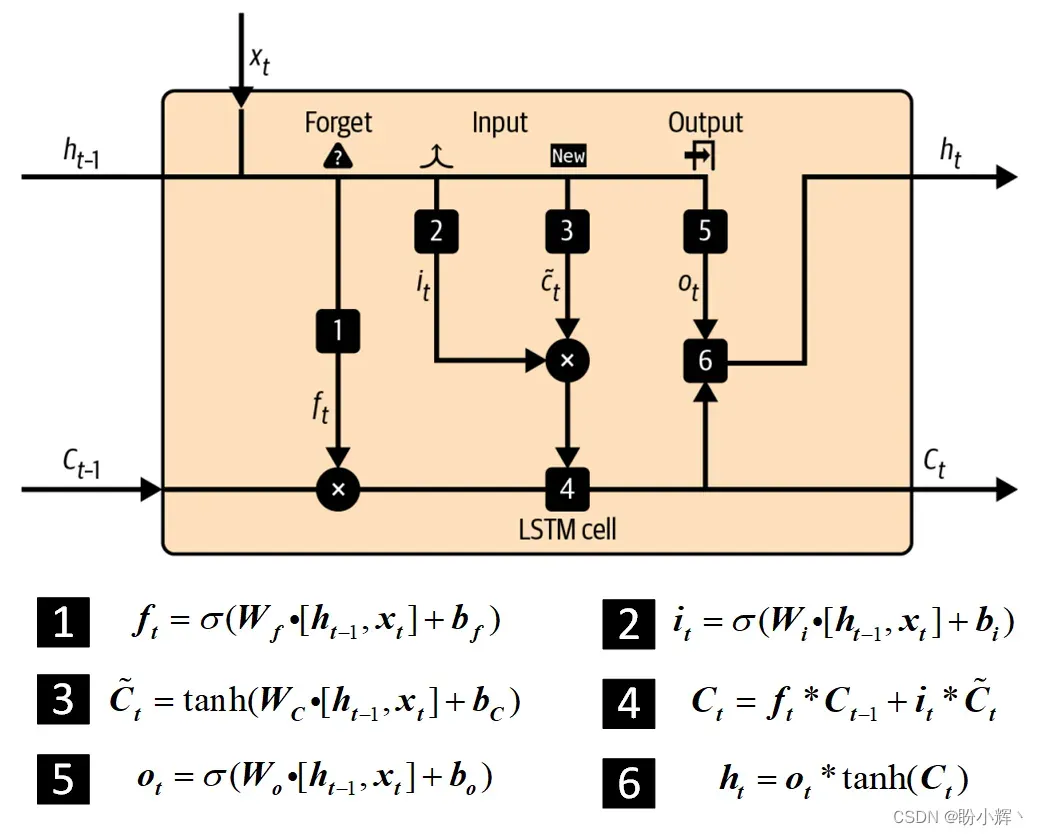
- 连接向量也通过一个输入门 (
input gate) 传递,与遗忘门一样,它是也一个带有权重矩阵、偏置
和
sigmoid激活函数的函数。该门的输出的长度与单元格中的单元数相同,其值介于
0和1之间,用于确定应该将多少新信息添加到前一单元格状态 - 连接向量经过一个带有权重矩阵
、偏置
和
sigmoid激活函数的函数,生成一个向量,表示单元格可能会保留的新信息。它的长度与单元格中的单元数相同,值介于
-1和1之间 - 原始的连接向量也会通过一个输出门,这同样是一个带有权重矩阵
、偏置
和
sigmoid激活函数的函数。得到的向量的长度与单元格中的单元数相同,存储着介于
0和1之间的值,用于确定从单元格中输出多少更新后的单元格状态 - 在对
应用
tanh激活函数之后,
4.3 训练 LSTM
构建、编译并训练 LSTM:
# 输入层不需要预先指定序列长度,因此我们使用 None 作为占位符
inputs = layers.Input(shape=(None,), dtype="int32")
# 嵌入层需要两个参数,词汇表的大小( 10,000 个标记)和嵌入向量的维度 (100)
x = layers.Embedding(VOCAB_SIZE, EMBEDDING_DIM)(inputs)
# LSTM 层需要指定隐藏向量的维度 (128),我们还要返回完整的隐藏状态序列,而不仅仅是最后一个时刻的隐藏状态
x = layers.LSTM(N_UNITS, return_sequences=True)(x)
# 使用全连接层将每个时间步的隐藏状态转换为下一个符号的概率向量
outputs = layers.Dense(VOCAB_SIZE, activation="softmax")(x)
# 整个模型根据输入符号序列预测下一个符号,对序列中的每个符号都执行此操作
lstm = models.Model(inputs, outputs)
print(lstm.summary())
loss_fn = losses.SparseCategoricalCrossentropy()
# 使用 SparseCategoricalCrossentropy 损失函数编译模型,分类交叉熵相同,但其在标签为整数而不是独热编码向量时使用
lstm.compile("adam", loss_fn)
# Tokenize starting prompt
text_generator = TextGenerator(vocab)
# 在训练数据集上拟合模型
lstm.fit(train_ds, epochs=EPOCHS,)
在下图中,可以看到 LSTM 训练过程中随着损失的下降,模型的输出将变得更加合理。

5. LSTM 模型分析
编译并训练 LSTM 模型后,可以使用该模型生成长文本字符串:
- 将一个已有的单词序列输入到网络中,并要求它预测下一个单词
- 将预测的单词添加到已有的序列中,并重复上述步骤。
神经网络会输出一组可供采样的每个单词的概率分布,并从中进行采样。因此,此文本生成过程是随机性的,而不是确定性。此外,我们还可以引入一个温度参数来调整采样过程的确定性程度。
温度参数
当温度参数接近 0 时,采样过程更加确定性(即最高概率的单词最有可能被选择),而温度参数为 1 意味着每个单词都按模型输出的概率进行选择。
创建一个回调函数,以用于在每个训练 epoch 结束时生成文本:
# Create a TextGenerator checkpoint
class TextGenerator(callbacks.Callback):
def __init__(self, index_to_word, top_k=10):
self.index_to_word = index_to_word
# 创建一个逆词汇映射(从单词到符号的映射)
self.word_to_index = {word: index for index, word in enumerate(index_to_word)}
def sample_from(self, probs, temperature):
# 函数使用一个温度参数缩放因子来更新概率
probs = probs ** (1 / temperature)
probs = probs / np.sum(probs)
return np.random.choice(len(probs), p=probs), probs
def generate(self, start_prompt, max_tokens, temperature):
# 种子文本是提供给模型开始生成过程的单词字符串,用于启动生成过程。这些单词首先被转换为一个符号列表
start_tokens = [
self.word_to_index.get(x, 1) for x in start_prompt.split()
]
sample_token = None
info = []
# 序列生成直到达到最大符号长度或者生成一个停止标记 (0) 为止
while len(start_tokens) < max_tokens and sample_token != 0: # <4>
x = np.array([start_tokens])
# 模型输出输入序列中下一个单词的概率
y = self.model.predict(x, verbose=0)
# 概率通过采样器传递,根据温度参数 temperature 输出下一个单词
sample_token, probs = self.sample_from(y[0][-1], temperature)
info.append({"prompt": start_prompt, "word_probs": probs})
# 将新单词追加到种子文本末尾中,准备进行生成过程的下一次迭代
start_tokens.append(sample_token)
start_prompt = start_prompt + " " + self.index_to_word[sample_token]
print(f"\ngenerated text:\n{start_prompt}\n")
return info
def on_epoch_end(self, epoch, logs=None):
self.generate("recipe for", max_tokens=100, temperature=1.0)
接下来,使用两个不同的温度参数查看生成的实际运行情况。

关于这两个段落需要注意以下几点。首先,它们在风格上都与原始训练集中的食谱相似。它们都以一个食谱标题开头,并包含正确的语法结构。区别在于,在温度参数为 1.0 的情况下生成的文本更加大胆,因此比温度参数为 0.2 的生成结果准确性较差。使用温度参数为 1.0 生成多个样本会生成多个不同结果,因为模型是从具有更大方差的概率分布中进行采样。
为了证明这一点,下图展示了对于各种序列来说,下一个出现概率最高的前 5 个单词。

该模型能够在多个上下文中生成下一个最可能出现的单词的分布。例如,即使我们从未告知模型有关名词、动词、形容词和介词等词性的信息,通常它也能够将单词按照词性分类,而且还能按照正确的语法使用这些单词。
此外,模型能够根据给定标题选择一个合适的动词作为食谱说明的开头。对于烤蔬菜,它最有可能选择的动词可能是预热、准备、加热、放置或混合,而对于冰淇淋,它最有可能选择的动词可能是添加、混合、搅拌和混合。这表明模型具有一定能力的上下文理解能力,能够根据配料区分食谱之间的差异。
同时还需要注意,在温度参数为 0.2 的生成示例中,更倾向于选择概率较高的单词,这就是为什么当温度参数较低时,生成的多样性通常较小的原因。
虽然基本 LSTM 模型在生成逼真文本方面有较好性能,但显然它仍然难以理解所生成词汇的一些语义含义。例如,引入了不太可能搭配在一起的配料(例如,酸味的日式土豆、核桃屑和水果冰)。在某些情况下,这可能是有趣的,例如,希望 LST M生成有趣而独特的词语组合,但在大多数情况下,我们需要模型对单词的分组方式有更深入的理解。
小结
在本节中,我们使用 Keras 构建了自回归模型——长短期记忆网络 (Long Short-Term Memory Network, LSTM),用于生成逼真的食谱文本,并了解如何通过调整采样过程的温度参数来增加或减少输出的随机性。
系列链接
AIGC实战——生成模型简介
AIGC实战——深度学习 (Deep Learning, DL)
AIGC实战——卷积神经网络(Convolutional Neural Network, CNN)
AIGC实战——自编码器(Autoencoder)
AIGC实战——变分自编码器(Variational Autoencoder, VAE)
AIGC实战——使用变分自编码器生成面部图像
AIGC实战——生成对抗网络(Generative Adversarial Network, GAN)
AIGC实战——WGAN(Wasserstein GAN)
AIGC实战——条件生成对抗网络(Conditional Generative Adversarial Net, CGAN)
版权声明:本文为博主作者:盼小辉丶原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/LOVEmy134611/article/details/135395814