使用 PCA 将神经网络中的参数数量减少 30 倍
同时仍然获得更好的性能! — 神经网络和深度学习课程:第 17 部分
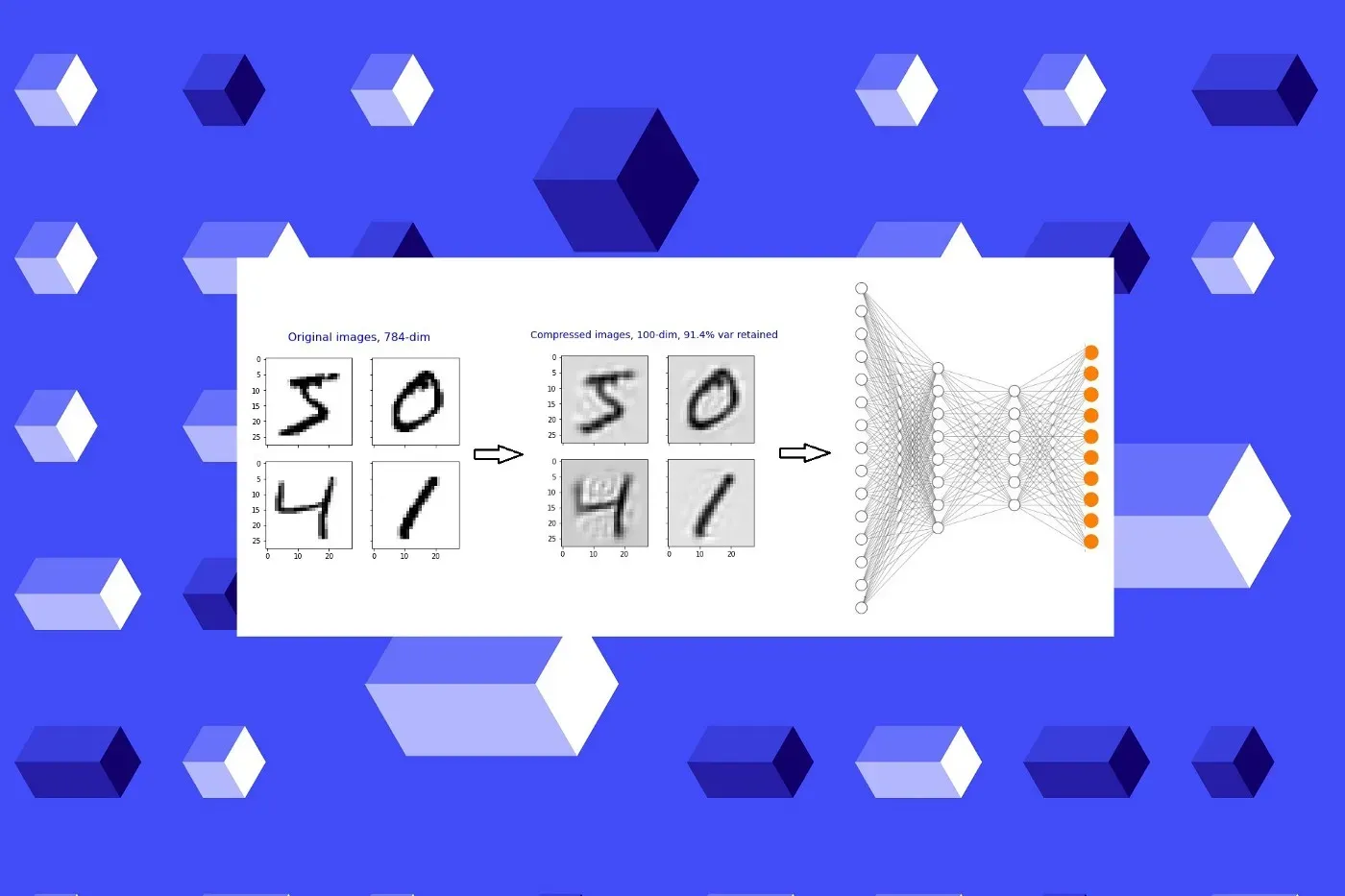
在上一篇文章中,我们创建了一个多层感知器 (MLP) 分类器模型来识别手写数字。[0]
我们为网络架构使用了两个具有 256 个神经元的隐藏层。即使使用这么小的网络,我们也得到了 269,322 个总参数(权重和偏差项)。网络获得如此大量参数的主要原因是输入层的大小。
因为 MLP 的输入层采用 1D 张量,所以我们需要将 2 维 MNIST 图像数据重塑为 1 维数据。此过程在技术上称为扁平化图像。
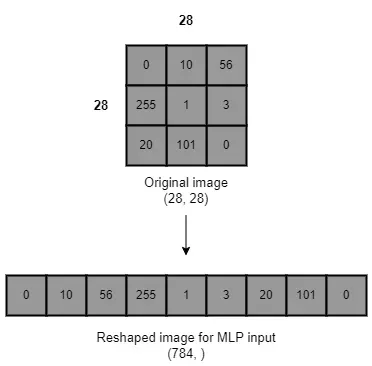
图像中的每个像素代表一个输入。如果图像中有 784 个像素,我们在 MLP 的输入层需要 784 个神经元。当输入层的大小增加时,我们会得到网络中大量的总参数。这就是 MLP 参数效率不高的原因。当我们使用高像素值的图像数据时,输入层的大小会显着增加,例如 500 x 500 像素的图像。
在网络中获取大量总参数的问题是我们需要大量的计算资源来训练神经网络,而且也很耗时。
MLP 不适用于图像数据。有一种更好的神经网络架构,称为卷积神经网络(CNN 或 ConvNets),旨在处理图像数据。它的输入层可以获取高维数据,因此我们不需要对图像进行展平。
如果有一种方法可以减少图像中的像素数量而不损失很多图像质量,我们仍然可以有效地使用 MLP 和图像数据。如果我们能做到这一点,输入层的大小将非常小,并且 MLP 模型将是参数有效的。
我们可以将主成分分析 (PCA) 应用于扁平图像,以显着减少像素数量,同时仍然获得几乎相同的图像质量,但现在像素更少!
一般的工作流程是:
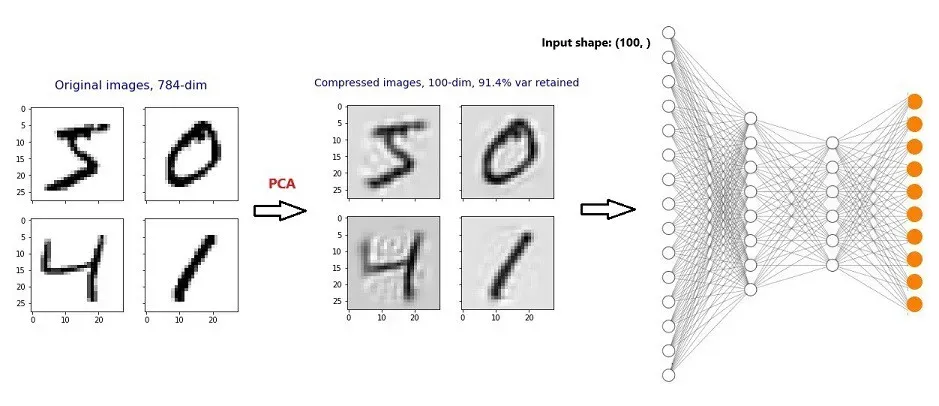
首先,我们将 PCA 应用于 MNIST 数字数据并将维度(像素数)降低 7.48 倍,同时保持 91.4% 的图像质量!然后,我们构建与第 16 部分相同的 MLP 模型。现在,输入形状是 (100, ),而不是 (784, )。这将显着减少网络中的总参数数量。此外,我们有机会减少隐藏层中的神经元数量,因为现在输入大小很小。这也将有助于显着减少网络中的总参数数量。[0]
将 PCA 应用于 MNIST 数据
如果您通过 Keras API 获取 MNSIT 数据,您将获得 60,000 张用于训练集的手写数字灰度图像和 10,000 张用于测试集的手写数字灰度图像。每个灰度图像都是二维的,宽度为 28 像素,高度为 28 像素。[0]
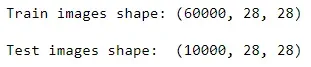
在应用 PCA 之前,我们需要将这些图像展平。展平后,我们得到:
我们可以将这个新的训练集图像数组视为一个简单的数据集,其中包含 60,000 行(图像数)和 784 列(图像中的像素数)。现在,我们可以照常应用 PCA。请注意,我们将 PCA 分别应用于训练集和测试集。
在考虑单个扁平图像时,像素数代表其维度。当我们减少维度时,我们减少了图像中的像素数。
# acquire MNIST data through Keras API
from tensorflow.keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# reshape (flatten) data before PCA
import numpy as np
train_images = np.reshape(train_images, (-1, 784))
test_images = np.reshape(test_images, (-1, 784))
# normalize data before PCA
train_images = train_images.astype('float32') / 255
test_images = test_images.astype('float32') / 255
# apply PCA once to
# select the best number of components
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
pca_784 = PCA(n_components=784)
pca_784.fit(train_images)
plt.grid()
plt.plot(np.cumsum(pca_784.explained_variance_ratio_ * 100))
plt.xlabel('Number of components')
plt.ylabel('Explained variance')运行上述代码后,我们得到以下输出。
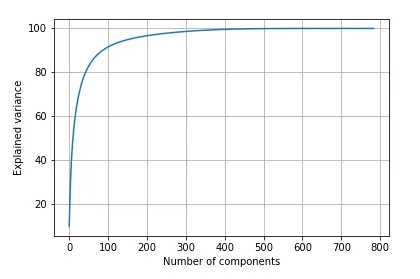
我们可以看到,前 100 个组件捕获了原始图像数据中大约 90% 的可变性。这足以保留原始图像的质量。因此,我们选择前 100 个组件,并使用该数量的选定组件再次应用 PCA。
# apply PCA again with 100 components
# about 90% of the variability retained
# transformation is applied to both
# train and test sets
pca_100 = PCA(n_components=100)
pca_100.fit(train_images)
train_images_reduced = pca_100.transform(train_images)
test_images_reduced = pca_100.transform(test_images)
# verify shape after PCA
print("Train images shape:", train_images_reduced.shape)
print("Test images shape: ", test_images_reduced.shape)
# get exact variability retained
print("\nVar retained (%):",
np.sum(pca_100.explained_variance_ratio_ * 100))
我们将原始图像数据的维度降低了 7.84 倍 (784/100),同时保持原始数据 91.43% 的可变性。
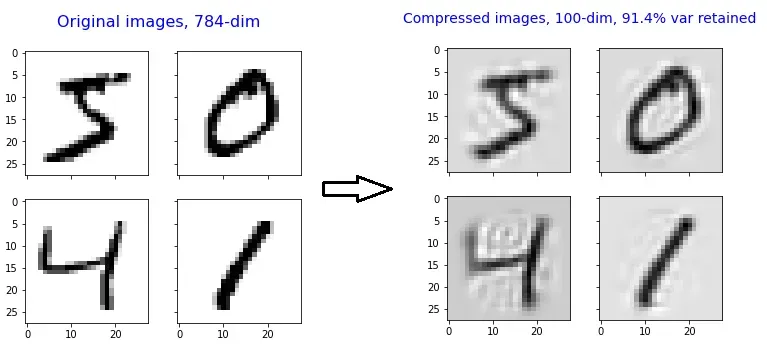
压缩后的图像仍然可以识别!
注意:我不会在这里解释更多关于 PCA 过程的信息。请参阅以下文章系列(由我撰写)以了解有关 PCA 和降维的所有信息。

使用压缩(缩减)图像数据构建 MLP 分类器
现在,我们构建了与第 16 部分中构建的相同的 MLP 分类器模型,但使用了压缩的图像数据(更少的维度和更少的像素)![0]
# convert labels to a one-hot vector
from tensorflow.keras.utils import to_categorical
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
# define network architecture
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import InputLayer
from tensorflow.keras.layers import Dense
MLP = Sequential()
MLP.add(InputLayer(input_shape=(100, ))) # input layer
MLP.add(Dense(64, activation='relu')) # hidden layer 1
MLP.add(Dense(32, activation='relu')) # hidden layer 2
MLP.add(Dense(10, activation='softmax')) # output layer
# optimization
MLP.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# train (fit)
history = MLP.fit(train_images_reduced, train_labels,
epochs=20, batch_size=128, verbose=0,
validation_split=0.15)
# evaluate performance on test data
test_loss, test_acc = MLP.evaluate(test_images_reduced, test_labels,
batch_size=128,
verbose=0)
print("Test loss:", test_loss)
print("Test accuracy:", test_acc)这次我们得到的准确度得分为 0.9745。以前(即在应用 PCA 之前),我们的准确度得分为 0.9804。我们只损失了非常少的准确度分数。那是 0.0059。
如果我们现在检查总参数的数量,我们得到:
MLP.summary()
以前(即在应用 PCA 之前),我们总共得到了 269,322 个参数。这次我们只得到了 8,874 个参数。因此,在应用 PCA 后,我们将总参数数量减少了 30 倍(269,322 / 8,874)!我们只损失了 0.0059 的模型精度。
通过应用 PCA,我们可以获得更好的结果。这次我说的是过拟合的问题。
我在训练期间测量了模型的性能。
# Plot training and validation accuracy scores
# against the number of epochs.
plt.plot(history.history['accuracy'], label='Train')
plt.plot(history.history['val_accuracy'], label='Validation')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.title('Model Accuracy - After PCA', pad=15)
plt.legend(loc='lower right')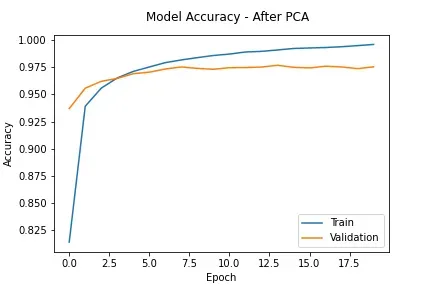
这可以与之前的相应案例进行比较:在应用 PCA 之前。
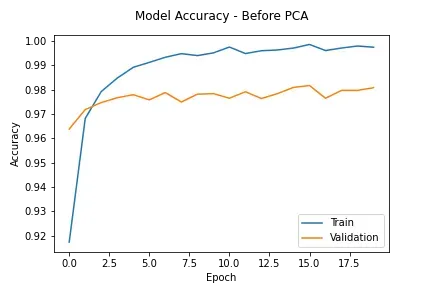
很明显,应用 PCA 后模型的过拟合程度降低了。该模型很好地概括了新的看不见的数据(测试数据)。原因是:
PCA 去除数据中的噪声,只保留数据集中最重要的特征。这将减轻数据的过度拟合并提高模型在未见数据上的性能。除此之外,当数据中有许多特征时,模型可能会变得更加复杂。复杂的模型往往会过度拟合数据。 PCA 通过减少数据中的特征(维数)数量来处理模型复杂性——来源:如何通过降维来缓解过度拟合(我自己的文章)[0]
Summary
- 我们将 PCA 应用于 MNIST 数据,并成功地将原始图像数据的维数降低了 7.84 倍。因此,我们可以显着减小 MLP 输入层的大小。我们在原始数据中保留了 91.43% 的可变性。因此,图像仍然是可识别的。
- 应用 PCA 后,我们只损失了很小的准确性。
- 我们可以将 MLP 模型中的总参数数量减少 30 倍!这是因为我们显着减小了 MLP 输入层的大小和隐藏层中的神经元数量。因为现在输入大小很小,我们有机会减少隐藏层中的神经元数量。通过增加隐藏层中的神经元数量,您不会获得太多的性能提升。但是,最好通过设置不同的值来进行一些实验,然后测量性能。
- 应用 PCA 后,模型的过拟合程度降低。我解释了这样做的原因。另外,请注意模型仍然过拟合,因为我们还没有对模型应用任何正则化技术。
- 将 PCA 应用于 MNIST 图像数据很容易,因为图像是灰度的,表示为二维 (2D) 张量。 PCA 过程对于表示为三维 (3D) 的 RGB 图像很复杂。阅读本文以了解如何将 PCA 应用于 RGB 图像。要了解 RGB 和灰度图像之间的区别,请阅读本文。[0][1]
今天的文章到此结束。
如果您有任何问题或反馈,请告诉我。
我希望你喜欢阅读这篇文章。如果您想支持我作为一名作家,请考虑注册成为会员以无限制地访问 Medium。每月只需 5 美元,我将收到您的会员费的一部分。[0]
非常感谢您一直以来的支持!下一篇文章见。祝大家学习愉快!
加入我的神经网络和深度学习课程
Rukshan Pramoditha
2022–06–12[0]
文章出处登录后可见!