0. 简介
相信最近大家已经被Transformer给洗脑了,作者也在《多传感器融合综述—FOV与BEV》中提到了深度学习相关的技术。这就随之带动的就是如何使用基于纯相机的鸟瞰图(BEV)感知技术来替代昂贵的激光雷达传感器,并使其能够应用在自动驾驶上,这目前是急需解决的问题,由于现在Transformer的计算仍然需要大量资源来执行车载推理,无法满足实时性。为此我们来看一下这一篇《Fast-BEV: Towards Real-time On-vehicle Bird’s-Eye View Perception》文章,文中发现发现BEV表示可以在不使用昂贵的视图变换或深度表示的情况下就可以拥有较好的性能,文中将 作为Baseline,然后进一步引入(1)用于图像和BEV空间的强大数据增强策略以避免过度拟合(2)多帧特征融合机制以利用时间信息(3)优化的部署友好视图变换以加速推理。文中提到M1 模型(R18@256 × 704)在 Tesla T4 平台上可以以 50 FPS 的速度运行。代码也已经在Github上开源了。
1. 主要贡献
精确的3D感知系统对自动驾驶来说是至关重要的。而使用纯视觉的BEV方法能够替代传统昂贵的激光雷达。本文基于思想,文中认为图像到BEV视图变换过程中,沿着相机光线的深度分布是均匀的。并提出了更强、更快的全卷积BEV感知框架,无需使用昂贵的视图变换器或深度表示。主要贡献如下:
-
我们在
上验证了两种技术的有效性:强数据增强和多帧时间融合,使Fast-BEV达到最先进的性能。
-
我们提出了两种加速设计:预先计算投影索引并将其投影到相同的体素特征,使Fast-BEV可以在车载芯片上轻松部署,并具有快速的推理速度。
-
本文所提出的Fast-BEV是针对实时车载BEV感知的首个部署导向工作。希望我们的工作能够对工业级、实时、车载BEV感知提供启示。
2. 详细内容
下图是整个框架的示意图,我们可以看到其模型框架基本是依据完成的,但是本文针对
的问题进行了改进,下面我们详细来看一下
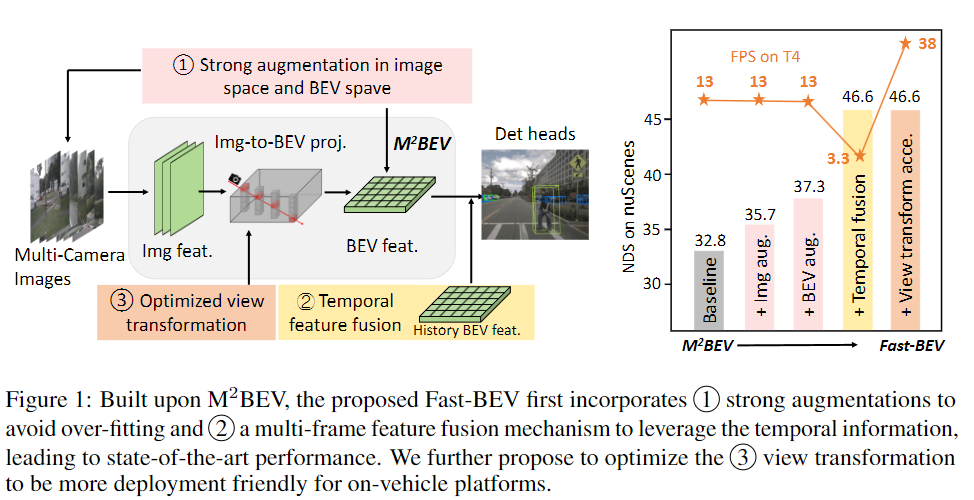
图1:Fast-BEV是基于
2.1 重新回顾
是解决多相机多任务感知的统一BEV表示的首批工作之一。它也更适用于车载平台,因为它不需要昂贵的视图变换器或深度表示。如下图顶部所示,
的输入是多相机RGB图像,输出是预测的3D边界框(包括速度)和地图分割结果。
有四个关键模块:(1)2D图像编码器,主要提取多相机图像的图像特征;(2)图像到BEV(2D→3D)视图变换模块,用于将2D图像特征映射到3D BEV空间;(3)3D BEV编码器,用于处理3D特征;(4)任务特定的头部执行感知任务,例如3D检测。
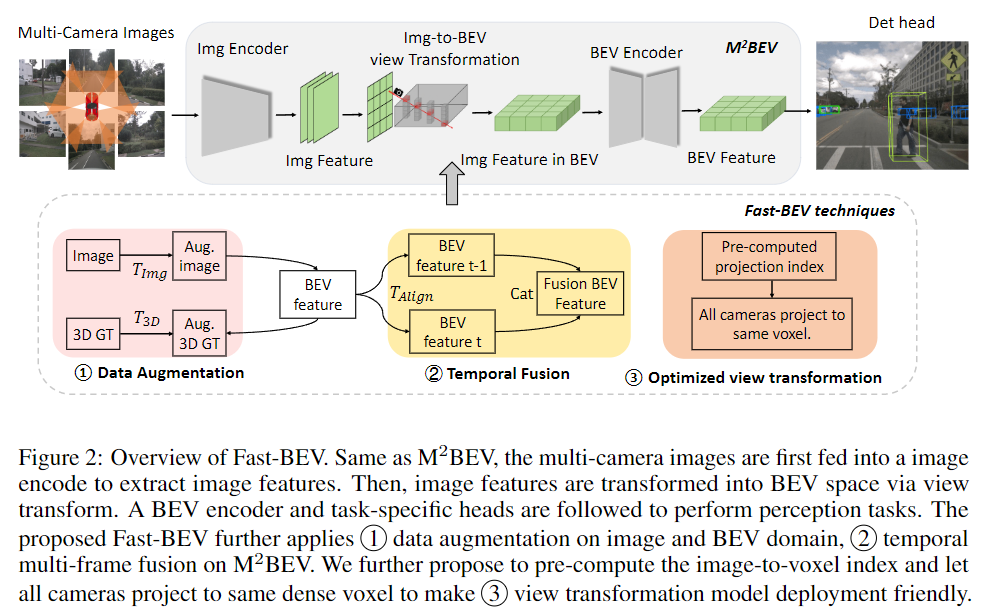
图2:Fast-BEV 概述。与
2.2 Fast-BEV的整体框架
虽然可以取得有竞争力的结果,但我们发现它的性能和效率可以进一步提高。如上图的下面部分所示,我们在
中整合了三种技术,从而形成了我们更强大更快的Fast-BEV。
- 数据增强。我们凭经验发现,在
- 时间融合。在实际的自主驾驶场景中,输入是时间连续的,具有巨大的互补信息。例如,在当前帧中部分被遮挡的一个行人可能在过去的几帧中完全可见。因此,我们通过引入时间特征融合模块,将
- 优化视图转换:我们发现从图像空间到体素空间的投影对延迟起着主导作用。我们提出了从两个角度优化投影:(1) 我们预先计算固定的投影索引并将其存储为静态查询表,这在推理期间非常高效。(2) 我们让所有摄像机投影到同一个体素,以避免昂贵的体素聚合。我们的方法不基于 Lift-Splat-Shoot 的改进视图转换方案[37,18,1],因为它不需要使用复杂且困难的DSP/GPU并行计算,而是足够快的仅使用CPU计算,非常方便部署。更多细节请参见第3.5节。
我们想澄清的是,1和2受到了文章[31,20]的启发,我们不打算将这两部分视为新颖的设计。这些改进使我们提出的流水线,Fast-BEV,成为一种 SOTA 方法,同时保持其在车载平台上的简单性。
2.3 数据增强
我们在图像空间和 BEV 空间中添加了数据增强,主要参考了 BEVDet [18]。
图像增强:3D 物体检测中的数据增强比 2D 检测更具挑战性,因为 3D 场景中的图像与 3D 相机坐标有直接关系。因此,如果我们在图像上应用数据增强,则需要更改相机内参矩阵 [18]。对于增强操作,我们基本遵循通用操作,例如翻转、裁剪和旋转。在 Fig. 3 的左部分,我们展示了一些图像增强的例子。
BEV 增强。与图像增强类似,可以对 BEV 空间应用类似的操作,例如翻转、缩放和旋转。请注意,增强变换应该同时应用于 BEV 特征图和3D 地面实际框,以保持一致性。可以通过相应地修改相机外向矩阵来控制 BEV 增强变换。图3的右部展示了随机旋转增强,是 BEV 增强的一种类型。
…详情请参照古月居
文章出处登录后可见!