一直都是在做一些目标检测的研究工作,近期开始看一些有关姿态检测的内容,其中最经典的就是openpose这个框架,后面很多动作识别、姿态检测也大多是在该网络上进行改进,比如Real-time 2D Multi-Person Pose Estimation on CPU 这篇论文,在原OpenPose基础上进行了轻量处理,我也用这代码跑了一下,效果也不错。
本篇文章就是在学习openpose这篇论文的一些个人理解,我会拿一些目标检测的做法去思考,有问题可以一起讨论。
首先目标检测不论是二阶段还是单阶段,都涉及两个问题,及分类问题和位置回归问题,分类回归其实是比较好解决的,通过CNN进行特征提取,最后一般用softmax进行输出可以知道是哪个类,但位置回归是比较复杂的,需要对真实框和预测框之间的偏移量不断的进行矫正、匹配,尤其是对一些小目标是不太友好的。那么在姿态检测中呢?在openpose中提到了heatmap(热力图)还有PAFs(部分亲和场),对应到目标检测中,前者其实就是特征提取,后者就是位置回归(只不过这个回归是向量),用PAFs获得人体部分关系。
openpose是一种自底向上的检测算法,先检测关键点,再检测人。自顶向下的算法,在人的数量较少,特别是对于单个的人,表现还可以,但如果人多了,那么效果就差了,而且速度也会慢,特别是人员有重叠或者没有检测到人,那就无法进一步检测关键点,
Openpose网络框架有两个分支,先将图像进行特征提取,然后送入第一个分支进行confidence map过程,热力图过程,类似目标检测中的分类问题。然后第二分支是获得2D向量集合,最后将两个部分进行结合得到最终的关键点。
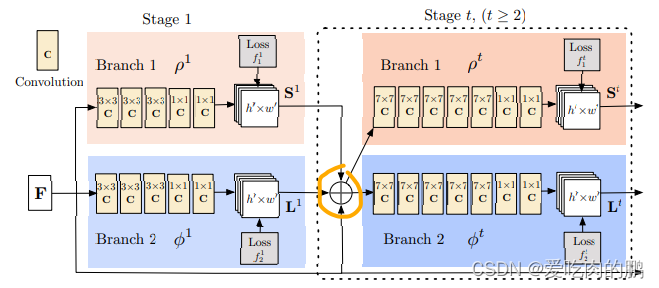
图中的F是通过VGG19网络进行提取的,提取出来的特征送入Branch1和Branch2两个分支,可以看到每个分支又有很多的Stage,每个Stage也是用不同的卷积进行提取特征。在Stage1中,两个分支输出的特征信息将会和VGG19输出的特征进行拼接(注意:这里是拼接,不是特征像素点的相加,如果你看源码,会看到用的cat函数,维度是1,表示通道维度上的拼接,再提一句,特征拼接需要特征尺寸相同)。所以在stage后面是三种特征的拼接
如下图就是论文中提到的,不同的分支提取不同的特征,然后两个分支进行关联就可以得到最终的结果。那么这个过程怎么做的,接下来将进一步讨论。
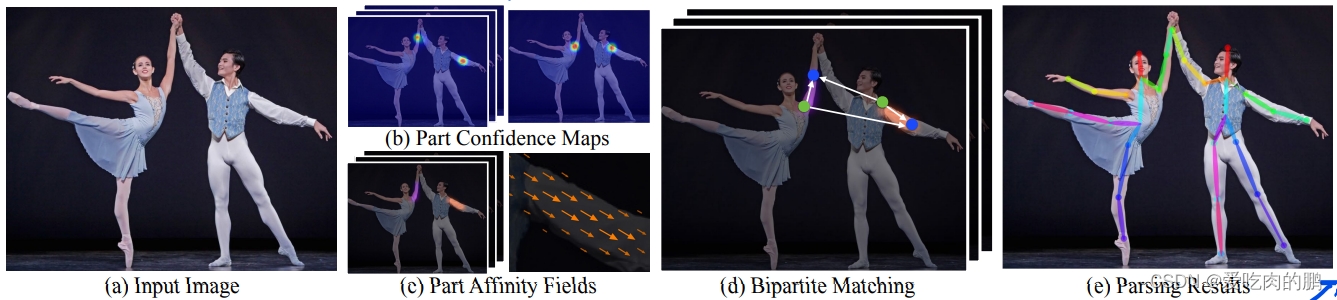
论文中说到:采用VGG19的前10层进行特征提取,得到一个特征集合F,将其作为每个分支的输入,得到集合和集合PAFs
,其实说的这个集合中的每个元素就是每个通道而已,每个通道得到了不同的信息。然后每个Stage过程如下面两个公式,即当前Stage是上一层的两个Stage输出的S和L再与VGG19输出特征拼接后再卷积。S可以理解为分类,L就是位置预测。
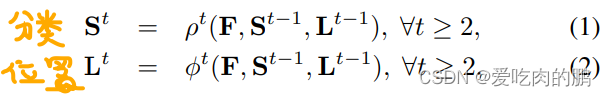
关于损失函数方面,论文中提到了采用L2 损失函数:
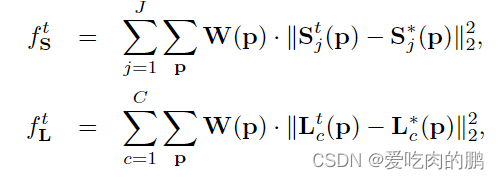
L2 损失函数,包括L1损失函数,通常是用来度量两个特征之间的相似情况或者说是距离,预测值和真实值相差越远,损失函数就会越大,反之则会越小。上来的两个公式中,同理上面一个是分类,下面是位置损失。和
表示的都是真实值,j指的是第几个关键点。而前面的W是一个mask,当没有P的时候令W为0,反之为1.这样也可以加快损失函数的收敛速度。
上面的两个式子是再每个阶段都有,然后再最终阶段进行的时候,会将所有Stage的loss进行求和
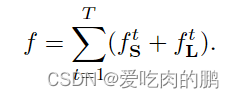
关于confidence map检测部分:
对于每个人而言,预测点的位置应该是有一个峰值(就是heatmap看到的那一点),而且是每个关键点处都有(在代码中就是每个通道一个峰值)。每个关键点得到S可以用以下式子表示,其中的x是我们的真实位置,j,k表示第k个人第j个点,如果我们的P值和x值越接近,那么两者的L2距离越小,越接近于0,那么此时S的值就会越接近于1,峰值则会越大。
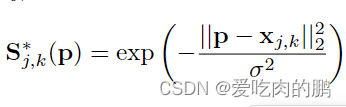
根据这些关键点的峰值,会选出一个最大的作为该关键点的confidence map(就像目标检测中,对于一个物体的预测会产生很多置信度,我们一般是选择最大的那一个作为我们的分类结果),然后通过NMS(非极大值抑制,采用IOU)获得身体的候选部分(什么叫候选部分呢,在目标检测的二阶段算法中,有个RPN即候选区域,表示进过特征提取后在某一区域预测到了物体,但不会管这个区域中到底是猫还是狗,反正就是这个区域中有预测到目标)
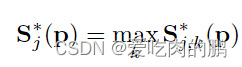
得到我们想要的关键点是很容易的,只需要进过一些列的特征提取即可,接下来的问题是,得到这些关键点,如何判断这些关键点是属于一个人的呢?尤其是有多个人的时候,这些关键点怎么样不会分配错。这个匹配问题,需要大家先去看一个二分图匹配问题。

(a)图就是一个二分图匹配问题,蓝色点和红色点各在一个集合中,从(a)图可以看到,这种二分图,错连接概率大,每个蓝点都和红点连接了,不太好把不同人分开;所以引入了图(b),在每两个点(红和蓝色)中间加入黄色点,第一个人和第二个人不容易连接错,但第一个人和第三个容易连接错,因为中间那人的黄点处于两边人对角线距离(绿色线部分),而图(c)是用论文中提出的PAFs方法了。
为了将各部分的进行一个关联,采用了2D向量
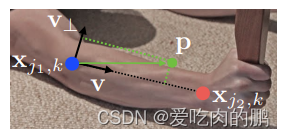
还是拿论文中的图为例,比如在胳膊上有两个点,蓝色和红色点,然后任意取一点P,如果这个P还在胳膊上(当然也可能不在),如果在,那么就令两个关键点之间为单位向量V(这样做是两点共线?表示关联性大),如果不在就为0,说明两个点不共线。
然后对于上面的个人理解:在看下面这张图。我是这样理解的,对于第一个人来说,我检测到了两个点,然后我如何判断这两个点属于同一个人呢?那么我会随便取一个点P,如果这个P还在这个人身上,那么蓝色和红色点之间就为一个单位向量,表示两个点共线,反之,如果这个P不在这个人身上,比如取第一个人的蓝色点,取第二个人的红色点,然后取了一个P,这个P在第二个身上,所以直接让这两点直接为0就行,表示不共线,这样就区分开了。所以这就是亲和域吧,亲和应该指两点的关系程度,域指的是一个区域内,表示一个区域内的两点关联程度。

文章出处登录后可见!