什么是多模态?
什么是多模态?多模态指的是多种模态的信息,包括:文本、图像、视频、音频等。顾名思义,多模态研究的就是这些不同类型的数据的融合的问题。
目前大多数工作中,只处理图像和文本形式的数据,即把视频数据转为图像,把音频数据转为文本格式。这就涉及到图像和文本领域的内容。
多模态的任务和数据集有哪些?
多模态研究的是视觉语言问题,其任务是关于图像和文字的分类、问答、匹配、排序、定位等问题。
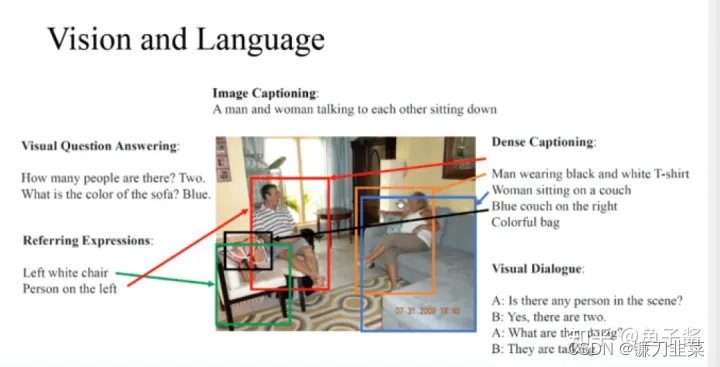
例如给定一张图片,可以完成以下任务:
- VQA(Visual Question Answering)视觉问答
输入:一张图片、一个自然语言描述的问题
输出:答案(单词或短语) - Image Caption 图像字幕
输入:一张图片
输出:图片的自然语言描述(一个句子) - Referring Expression Comprehension 指代表达
输入:一张图片、一个自然语言描述的句子
输出:判断句子描述的内容(正确或错误) - Visual Dialogue 视觉对话
输入:一张图片
输出:两个角色进行多次交互、对话 - VCR (Visual Commonsense Reasoning) 视觉常识推理
输入:1个问题,4个备选答案,4个理由
输出:正确答案,和理由
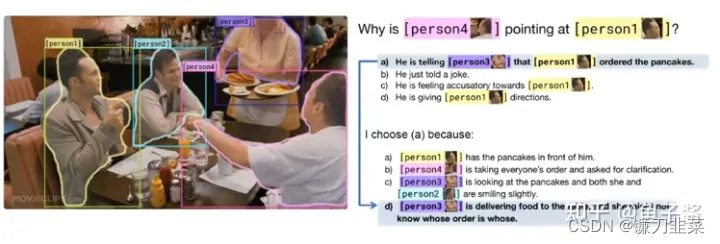
- NLVR(Natural Language for Visual Reasoning)自然语言视觉推理
输入:2张图片,一个分布
输出:true或false

- Visual Entailment 视觉蕴含
输入:图像、文本
输出:3种label的概率。(entailment、neutral、contradiction)蕴含、中性、矛盾

- Image-Text Retrieval 图文检索
有3种方式。
1)以图搜文。输入图片,输出文本
2)以文搜图。输入文本,输出图片
3)以图搜图,输入图片,输出图片
多种模态融合的方式有哪些?
通过NLP的预训练模型,可以得到文本的嵌入表示;再结合图像和视觉领域的预训练模型,可以得到图像的嵌入表示;那么,如何将两者融合起来,来完成以上的各种任务呢?常用的多模态交叉的方式有两种:
- 点乘或者直接追加
此种方式将文本和图像分别进行Embedding,之后将各自的向量进行追加或者点乘。好处是简单方便,计算成本也比较低。
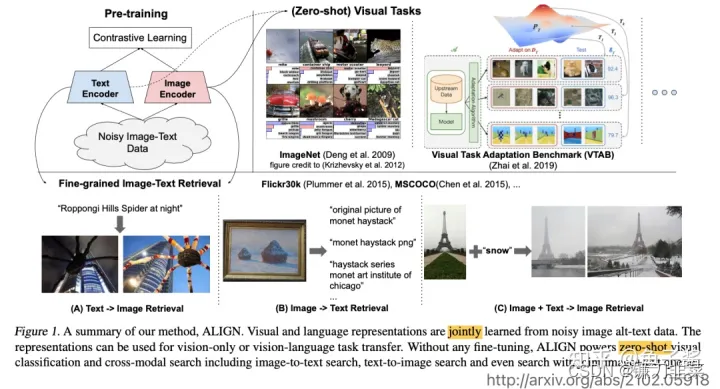
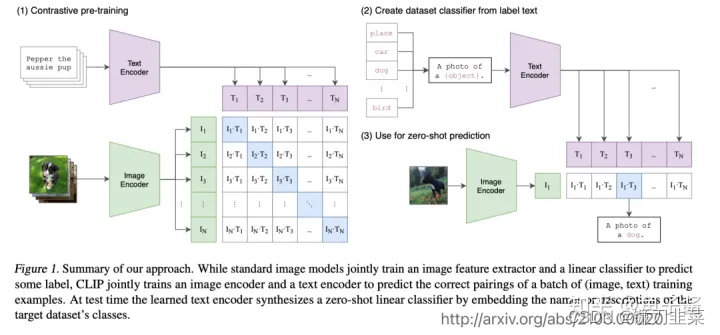
- 另外一种模态交叉的方式是最近用得比较多的Transformer。
其好处是利用了Transformer架构,能够更好地进行图像特征和文本特征的表示。缺点是占用空间大,计算成本较高。
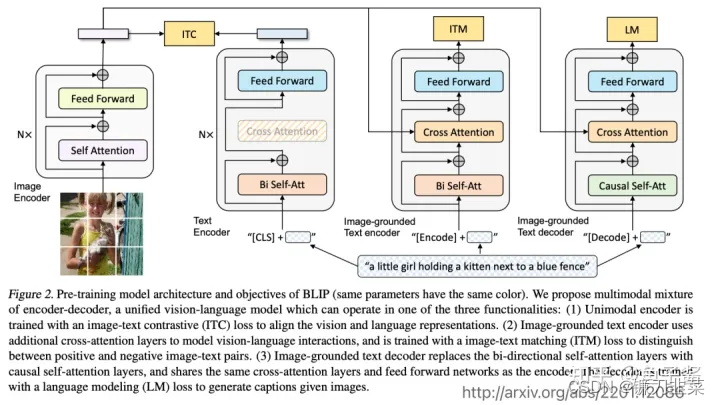
多模态任务的研究方向有哪些?
- 多模态的表示学习(multimodal representation):利用多模态的互补性和冗余的方式来表示和总结多模态数据。
- 联合表示:将不同的单模态投影到一个共享的子空间来对特征进行融合。
- 协同表示:每个模态都可以学习单独的表示,但是通过约束进行协调。约束可以通过对抗性的训练,模态编码特征的相似性约束来获取。
- 编解码:在多模态任务转换中,将一种模态映射为另一种模态的。编码器将原模态映射到中间向量,然后通过中间向量生成新模态下的表达。
- 模态映射(translation):将数据从一种模态转换到另一种模态。
- example-based:基于检索的模型是多模态翻译的最简单形式。它们在字典中找到最接近的样本,并将其作为翻译结果。检索可以在单模态空间或中间语义空间进行。
- generative :
- 基于语法的:通过使用语法来限制目标领域来简化任务。它们首先从源模态中检测高层语义,例如图像中的对象和视频中的动作。然后,这些检测结果与基于预定义语法的生成过程合并在一起,以产生目标模态。
- 编码器解码器:将源模态编码为潜在表示,然后由解码器来生成目标模态。即首先将源模态编码成矢量表示,然后使用解码器模块生成目标模态,所有这些都在一个单通道管道中完成。
- 连续生成模型:基于源模态输入流连续生成目标模态,它往往用于序列翻译,并以在线方式在每个时间步上产生输出。这些模型在将序列转换为序列(如从文本转换为语音、从语音转换为文本、从视频转换为文本)时非常有用。
- 模态对齐(alignment)
- 隐式对齐(implicit alignment):隐对齐作为另一个任务的中间(通常是潜在的)步骤,例如,基于文本描述的图像检索可以包括单词和图像区域之间的对齐步骤。
- 显式对齐(explicit alignment): 显式对齐主要通过相似性度量来实现,大多数方法依赖于测量不同形式的子组件之间的相似性作为基本的构建块。
- 多模态融合(multimodal fusion):两种分类方法
- 基于集成的融合方法(aggregation-based):基于聚集的方法通过一定的操作(如平均、连接、自注意力)将多模态子网络组合成单个网络。
- 基于对齐的融合方法(alignment-based):基于对齐的融合方法则采用了一个正则化损失来对齐所有子网络的特征嵌入,同时保持每个子网络进行单独的参数传播。
- Early:早期融合可以学习利用每个模态的低层特征之间的相关性和相互作用。例如在文献3中采用的多项式特征融合递归地将局部关联传输到全局关联来对特征进行融合。
- Late:后期融合使用单峰决策值,并使用一种融合机制进行融合,如平均、投票、基于信道噪声和信号方差的加权,或学习模型。
- Hybrid:混合融合尝试在一个共同的框架中利用上述两种方法的优点。它已成功地用于多模态说话人识别和多媒体事件检测。
- 协同学习(co-learning)
协同学习有助于解决某种模态下资源匮乏型的模型训练,提取一种模态数据的信息来协助另一种模态数据的训练。针对不同的数据资源类型可以将协同学习分为以下3中。
- 并行数据(parallel-based):训练数据集中其中一种模态的观测结果直接与其他模态的观测结果相关联。即当多模态观测来自相同的实例时。
- 非平行数据(non-parallel):不要求来自不同模式的观察之间有直接联系。这些方法通常通过使用数据类别重叠来实现共同学习。
- 混合数据(hybrid):在混合数据设置中,两个非平行模态通过共享模态或数据集进行连接。
参考资料
[1] https://zhuanlan.zhihu.com/p/473760099
[2] https://zhuanlan.zhihu.com/p/351048130
文章出处登录后可见!
已经登录?立即刷新