目录
机器学习在生活中无处不在,你是否会疑问为什么你的某宝界面总是给你推荐一些商品,而这些商品还是你自己想要的东西,这就是电商平台利用大数据推荐算法,结合你的历史搜索记录和浏览记录,以及你的购买记录作为数据支撑,最终推荐给你心仪的商品。
某音视频也是如此,为什么每个人的视频刷的都不一样,小朋友的界面;年级人的界面;老年人的界面大不相同,那是因为会根据你的历史观看记录和关注人群做层次筛选,这样结合你的视频停留时间和用户发生的动作行为作为数据支撑,最终演化为一个符合人性化的推荐算法!

每一次当你使用微信朋友圈,微博的相片分类功能,它能识别出哪些是你好友的照片,这也是机器学习算法。
每次当你使用百度搜索引擎时,它能给出如此满意的结果,原因之一就是使用了机器学习算法。
机器学习还可以实现图像的像素增强以及图像补全,同时还可以在图像识别方面具有较好的可塑性和重用性。
简单来说,机器学习就是让计算机从大量的数据中学习到相关的规律和逻辑,然后利用学习来的规律来预测以后的未知事物
如果要说到机器学习,不得不推荐一个Python的库:sklearn,它具有大量的模型算法,而且都已经封装好了,只需要我们自己去调用即可,就像科研神器R语言一样,拥有大量的宏包,Python也是如此。
官方指导手册网址
scikit-learn: machine learning in Python — scikit-learn 1.0.2 documentation
train_x, train_y, test_x, test_y = getData()
model1 = somemodel()
model.fit(train_x,train_y)
predictions = model.predict(test_x)
score =score_function(test_y, predictions)
joblib.dump(knn, 'filename.pkl') 机器学习的步骤
机器学习初步可以分为:
数据导入,特征选取,数据分割,模型选择,模型训练,模型评分,模型调优
什么是特征选取呢?
什么又是特征工程?
这里只是简单的提一下,后续将会详细的介绍,特征工程就是将机器无法识别,无法运算的数据转换为数值类型的数据,用于模型的训练和测试。
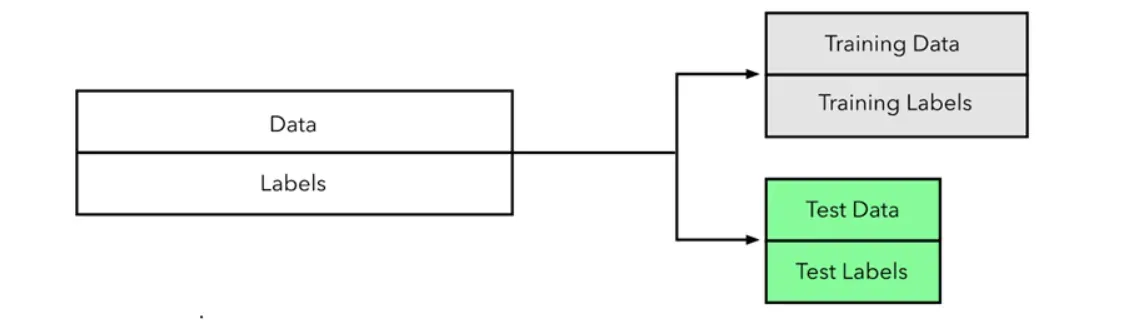
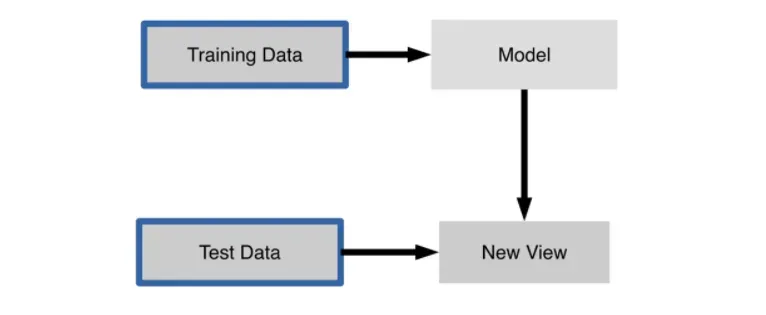
利用sklearn中分割函数train_test_split()函数去将数据分割为测试集和训练集
train_test_split函数的详解
在机器学习中,我们通常将原始数据按照比例分割为“测试集”和“训练集”
从 sklearn.model_selection 中调用train_test_split 函数
简单用法如下:
X_train,X_test, y_train, y_test =sklearn.model_selection.train_test_split
(train_data,train_target,test_size=0.4, random_state=0,stratify=y_train)train_data:所要划分的样本特征集
train_target:所要划分的样本结果
test_size:样本占比,如果是整数的话就是样本的数量
random_state:是随机数的种子
随机数种子:其实就是该组随机数的编号,在需要重复试验的时候,保证得到一组一样的随机数。比如你每次都填1,其他参数一样的情况下你得到的随机数组是一样的。但填0或不填,每次都会不一样。
stratify:是为了保持split前类的分布。比如有100个数据,80个属于A类,20个属于B类。
如果train_test_split(… test_size=0.25, stratify = y_all), 那么split之后数据如下:
training: 75个数据,其中60个属于A类,15个属于B类
testing: 25个数据,其中20个属于A类,5个属于B类。
用了stratify参数,training集和testing集的类的比例是 A:B= 4:1
等同于split前的比例(80:20)。通常在这种类分布不平衡的情况下会用到stratify。
将stratify=X就是按照X中的比例分配
将stratify=y就是按照y中的比例分配
整体总结起来各个参数的设置及其类型如下:
主要参数说明:
*arrays 可以是列表、numpy数组、scipy稀疏矩阵或pandas的数据框
test_size:可以为浮点、整数或None,默认为None
①若为浮点时,表示测试集占总样本的百分比
②若为整数时,表示测试样本样本数
③若为None时,test size自动设置成0.25
train_size:可以为浮点、整数或None,默认为None
①若为浮点时,表示训练集占总样本的百分比
②若为整数时,表示训练样本的样本数
③若为None时,train_size自动被设置成0.75
random_state:可以为整数、RandomState实例或None,默认为None
①若为None时,每次生成的数据都是随机,可能不一样
②若为整数时,每次生成的数据都相同
stratify:可以为类似数组或None
①若为None时,划分出来的测试集或训练集中,其类标签的比例也是随机的
②若不为None时,划分出来的测试集或训练集中,其类标签的比例同输入的数组中类标签的比例相同,可以用于处理不均衡的数据集

总之在遇到数据集不平衡的情况下可以使用该参数,来调节数据标签的不平衡的情况,我们可以该参数调节
机器学习评估指标
分类模型评估指标
分类常用指标:
准确率( accuracy):对于给定的测试数据集,分类器正确分类的样本数与总样本数之比
混淆矩阵
针对预测值和真实值之间的关系,我们可以将样本分为四个部分:
真正例(True Positive,TP):预测值和真实值都为1
假正例(False Positive,FP):预测值为1,真实值为0
真负例(True Negative,TN):预测值与真实值都为0
假负例(False Negative,FN):预测值为0,真实值为1
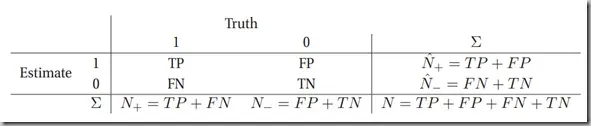
很明显的得知,真正例和真负例越多,说明模型的效果就越好
ROC曲线
那么有了混淆矩阵,这样一个规则之后,我们需要一个评估指标可以直接的反映该情况的好坏,此时就引入了:
真正例率
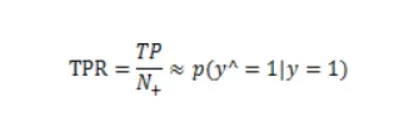
上述公式,如果值越大那么说明真正例越多
假正例率
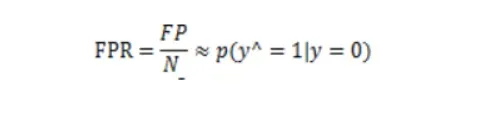
TPR也就是我们所说的召回率,通过TPR和FPR的相关性图,可以得到ROC曲线,如下图所示:
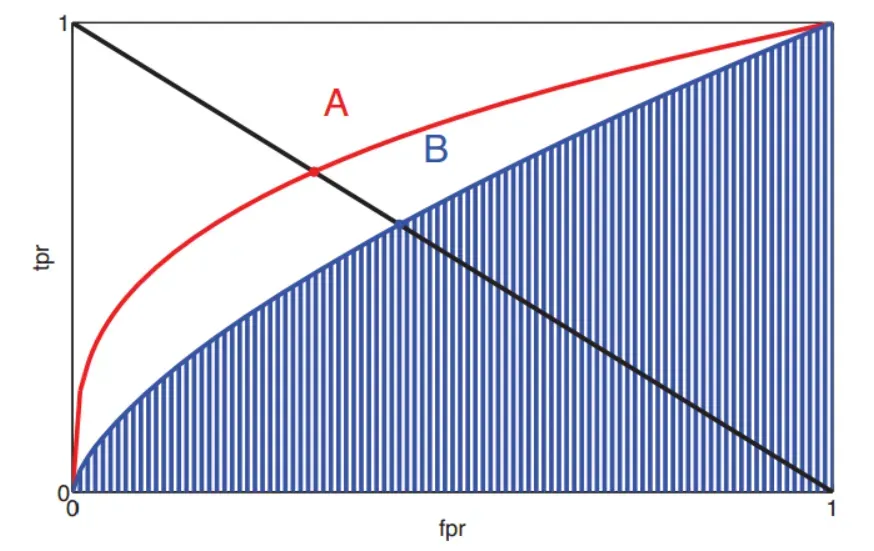
图中的红色曲线和蓝色曲线分别表示了两个不同的分类器的TPR-FPR曲线,曲线上的任意一点都对应了一个特定的数值,也就是说如何看ROC曲线,从它的构造本质来看,真正例越大,假正例就越少,也就是说我们画出该曲线的时候,应该如何去看,怎样的曲线效果才是最好的,请看下面的解说:
-
曲线越是“凸”向左上角,说明分类器效果越好
-
最完美的分类器(完全区分正负样例):(0,1)点,即没有FP,全是TP ,根本不存在,如果存在应该思考是否出现错误?
-
随机预测会得到(0,0)和(1,1)的直线上的一个点
-
曲线上离(0,1)越近的点分类效果越好,对应着越合理的
如此来看,上面的ROC曲线,红色的较好与蓝色的
利用ROC的其他评估标准
AUC:是一个概率值,当你随机挑选一个正样本以及一个负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值,而作为一个数值,对应AUC更大的分类器效果更好;
这里需要注意的是,ROC曲线和AUC面积一般用于分类中的二分类情况,ROC曲线用在多分类中是没有意义的。只有在二分类中Positive和Negative同等重要时候,适合用ROC曲线评价。如果确实需要在多分类问题中用ROC曲线的话,可以转化为多个“一对多”的问题。即把其中一个当作正例,其余当作负例来看待,画出多个ROC曲线。
EER:也就是FPR=FNR的值,由于FPR=1-TPR,可以画一条从(0,1)到(1,0)的直线,找到交点,图中的A、B两点。
如果roc曲线绘制出来是一个对角线,那么就属于随机猜测模型,意义不大
ROC曲线的意义及解释
-
ROC曲线能很容易的查出任意阈值对学习器的泛化性能影响。
-
有助于选择最佳的阈值。ROC曲线越靠近左上角,模型的查全率就越高。最靠近左上角的ROC曲线上的点是分类错误最少的最好阈值,其假正例和假反例总数最少。
-
可以对不同的学习器比较性能。将各个学习器的ROC曲线绘制到同一坐标中,直观地鉴别优劣,靠近左上角的ROC曲所代表的学习器准确性最高。
该方法简单、直观、通过图示可观察分析方法的准确性,并可用肉眼作出判断。ROC曲线将真正例率和假正例率以图示方法结合在一起,可准确反映某种学习器真正例率和假正例率的关系,是检测准确性的综合代表。
此外,可以把多个模型(二分类)的ROC曲线绘制在一个平面图中,至于如何比较这个时候,就需要用到AUC面积了,面积越大说明该模型或者该算法下的分类效果较好
Python 绘制ROC曲线求解AUC模板代码
# 预测正例的概率
y_pred_prob=model.predict_proba(X_test)[:,1]
# y_pred_prob ,返回两列,第一列代表类别0,第二列代表类别1的概率
#https://blog.csdn.net/dream6104/article/details/89218239
fpr, tpr, thresholds = metrics.roc_curve(y_test,y_pred_prob, pos_label=2)
#pos_label,代表真阳性标签,就是说是分类里面的好的标签,这个要看你的特征目标标签是0,1,还是1,2
roc_auc = metrics.auc(fpr, tpr) #auc为Roc曲线下的面积
# print(roc_auc)
plt.figure(figsize=(8,6))
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.plot(fpr, tpr, 'r',label='AUC = %0.2f'% roc_auc)
plt.legend(loc='lower right')
# plt.plot([0, 1], [0, 1], 'r--')
plt.xlim([0, 1.1])
plt.ylim([0, 1.1])
plt.xlabel('False Positive Rate') #横坐标是fpr
plt.ylabel('True Positive Rate') #纵坐标是tpr
plt.title('Receiver operating characteristic example')
plt.show()错误率
错误率(Error Rate):是分类错误的样本数占样本总数的比例。对样例集D,分类错误率计算公式如下所示:
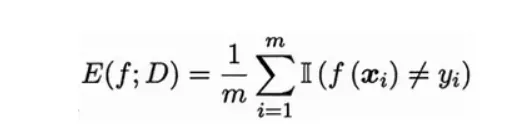
统计分类器预测出来的结果与真实结果不相同的个数,然后除以总的样例集D的个数。
精度
精度(Accuracy):是分类正确的样本数占样本总数的比例。对样例集D,精度计算公式
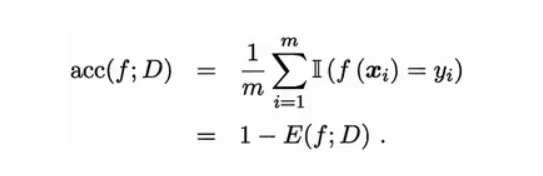
这里的分类正确的样本数指的不仅是正例分类正确的个数还有反例分类正确的个数。
查准率、查全率
这里的查准率其实就是上面的真正例:TP/TP+FP
查准率,它表示的是预测为正的样例中有多少是真正的正样例,相对于本来有样本有10个,正样本9个,负样本1个,预测出来TP:8.那么FP:0,所以查准率为100%。相对于是有一个本来是1的我们却预测为0,但是对于查准率来说,这是不会影响的。
精确度(Accuracy),缩写表示用A。精确度则是分类正确的样本数占样本总数的比例。Accuracy反应了分类器对整个样本的判定能力(即能将正的判定为正的,负的判定为负的)。
这里需要注意的就是精度和准确率是不一样的,准确率是查准率,这里的准是代表着正(1)的概率
查全率(Recall),又叫召回率,缩写表示用R。查全率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确。
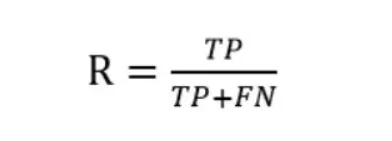
通过上述的介绍,我们发现查准率和查全率是有矛盾的
查准率和查全率是一对矛盾的度量。一般来说,查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。
为什么这么说呢?因为查准率是考虑的在预测结果为1的样本中,验证真正的为1的数量占比;而查全率是考虑的在本来就是1的样本中,有多少被预测为1的占比。
是不是有点绕了,这里举一个具体的例子,比如还是一共10个样本,其中有9个1,1个0;通过模型预测出来有8个1,2个0,那么它的查准率是100%,但是它的召回率,也就是9个里面只召回了8个。那么需要召回率高也就是说,就需要原本是1的都预测为1,不出现预测为0,但是都预测为1了,那么这个质量又无法保证,会出现本来是0的,却预测为1了。
这里需要仔细的思考一下,不然真的容易混淆!!!!
我们可以这样理解,在一个分类器中,你想要更高的查准率,那么你的阈值要设置的更高,只有这样才能有较高的把握确定我们预测是正例是真正例。
一旦我们把阈值设置高了,那我们预测出正例的样本数就少了,那真正例数就更少了,查不全所有的正样例。
举个例子来理解一下吧!例如,若希望将好瓜尽可能多地挑选出来,则可通过增加选瓜的数量来实现,如果将所有的西瓜都选上,那么所有的好瓜也必然都选上了,但这样查准率就会较低;若希望选出的瓜中好瓜比例尽可能高,则可只挑选最有把握的瓜,但这样就难免会漏掉不少好瓜,使得查全率较低。通常只有在一些简单任务中,才可能使查全率和查准率都很高。
P-R曲线
在很多情形下,我们可根据学习器的预测结果对样例进行排序,排在前面的是学习器认为“最可能”是正例的样本,排在最后的是学习器认为“最不可能”是正例的样本。按此顺序设置不同的阈值,逐个把样本作为正例进行预测,则每次可以计算出当前的查准率、查全率。
以查准率为纵轴、查全率为横轴作图,就得到了查准率-查全率曲线,简称“P-R曲线”,显示该曲线的图称为“P-R图”。图1给出了一个示意图。
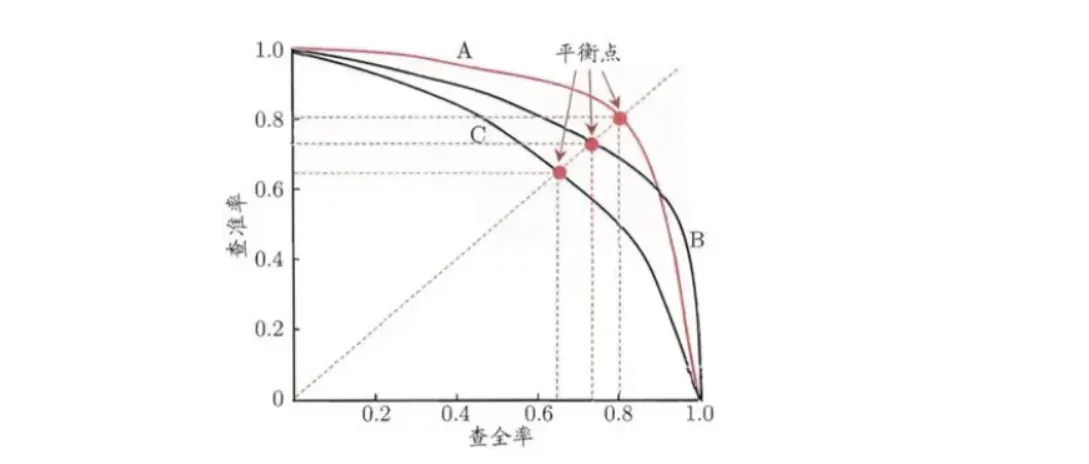
P-R图直观地显示出学习器在样本总体上的查全率、查准率。在进行比较时,若一个学习器的P-R曲线被另一个学习器的曲线完全“包住”,则可断言后者的性能优于前者。
例如图1中学习器A的性能优于学习器C;如果两个学习器的P-R曲线发生了交叉,例如图1中的A和B,则难以一般性地断言两者孰优孰劣,只能在具体的查准率或查全率条件下进行比较。然而,在很多情形下,人们往往仍然希望把学习器A与B比出个高低。
这时,一个比较合理的判断依据是比较P-R曲线下面积的大小,它在一定程度上表征了学习器在查准率和查全率上取得相对“双高”的比例。但这个值不太容易估算,因此,人们设计了一些综合考虑查准率、查全率的性能度量,比如BEP度量、F1度量。
Python绘制P-R曲线模板代码
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve
# 预测正例的概率
y_pred_prob=model.predict_proba(X_test)[:,1]
plt.figure(1) # 创建图表1
plt.title('Precision/Recall Curve')# give plot a title
plt.xlabel('Recall')# make axis labels
plt.ylabel('Precision')
#y_true和y_scores分别是gt label和predict score
y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
#fpr, tpr, thresholds = metrics.roc_curve(y_test,y_pred_prob, pos_label=2)
precision, recall, thresholds = metrics.roc_curve(y_test,y_pred_prob, pos_label=1)
plt.figure(1)
plt.plot(precision, recall)
plt.show()平衡点(BEP)
“平衡点”(Break-Even-Point,简称BEP)就是这样一个度量,它是“查准率=查全率”时的取值,例如图1中学习器C的BEP是0.64,而基于BEP的比较,可认为学习器A优于B。
F1度量
越大越好
BEP曲线还是过于简化了些,更常用的是F1度量。我们先来谈谈F1度量的由来是加权调和平均,计算公式如下所示。

import matplotlib
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve
# 预测正例的概率
y_pred_prob=model.predict_proba(X_test)[:,1]
plt.figure(1) # 创建图表1
plt.title('Precision/Recall Curve')# give plot a title
plt.xlabel('Recall')# make axis labels
plt.ylabel('Precision')
#y_true和y_scores分别是gt label和predict score
y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
#fpr, tpr, thresholds = metrics.roc_curve(y_test,y_pred_prob, pos_label=2)
precision, recall, thresholds = metrics.roc_curve(y_test,y_pred_prob, pos_label=1)
plt.figure(1)
plt.plot(precision, recall)
plt.show()在一些应用中,对查准率和查全率的重视程度有所不同。例如在商品推荐系统中,为了尽可能少打扰用户,更希望推荐内容确实是用户感兴趣的,此时查准率更重要;而在逃犯信息检索系统中,更希望尽可能少漏掉逃犯,此时查全率更重要。F1度量的一般形式是能让我们表达出对查准率/查全率的不同偏好,它定义为公式如下:
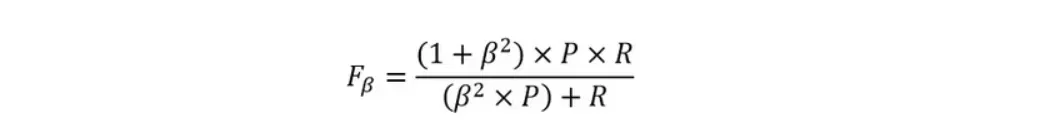
其中,β>0度量了查全率对查准率的相对重要性。β=1时,退化为标准的F1;β>1时查全率有更大影响;β<1时,查准率有更大影响
Python求解F1_score代码
from sklearn.metrics import f1_score
y_pred = [0, 1, 1, 1, 2, 2]
y_true = [0, 1, 0, 2, 1, 1]
#这里需要注意,如果是二分类问题则选择参数‘binary’(默认);如果考虑类别的不平衡性,需要计算类别的加权平均,则使用‘weighted’;如果不考虑类别的不平衡性,计算宏平均,则使用‘macro’。
print(f1_score(y_true, y_pred, average='macro'))
print(f1_score(y_true, y_pred, average='weighted')) 回归模型评估指标
均方误差
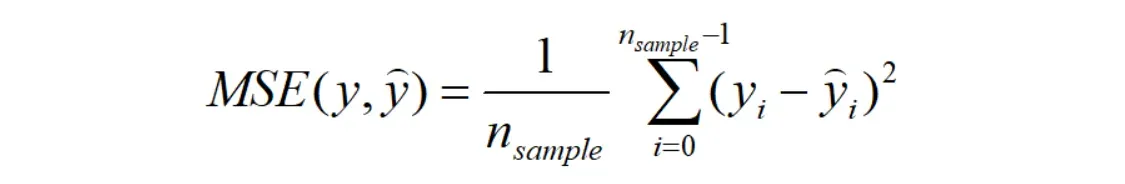
均方误差(mean_squared_error):是反映估计量与被估计量之间差异程度的一种度量
一般希望估计的均方误差,越小越好
机器学习库sklearn中,我们使用metrics方法实现:
import numpy as np
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3]
y_true = [0, 1, 2, 3]
accuracy_score(y_true, y_pred)MAE(平均绝对误差)
绝对误差的平均值,能反映预测值误差的实际情况。取值越小,模型准确度度越高。
from sklearn.metrics import mean_absolute_error
mean_absolute_error(y_test,y_pred)MAPE(平均绝对百分比误差)
是 MAE 的变形,它是一个百分比值。取值越小,模型准确度越高。
MAPE = np.mean(np.abs((y_test - y_pred)/y_test))RMSE(均方根误差)
from sklearn.metrics import mean_squared_error
from math import sqrt
sqrt(mean_squared_error(y_test,y_pred))R Square(R方)
将预测值跟只使用均值的情况下相比。取值范围一般【0,1】,结果越靠近 1 模型准确度度越高,结果越靠近 0 直接瞎猜准确度更高,结果为 负数 直接平均值乘以2倍准确度更高。
from sklearn.metrics import r2_score
r2_score(y_test,y_pred)交叉验证
为什么要使用交叉验证?
将原始数据分成K个子集(一般是均分),将每个子集数据分别做一次测试集 (testing test),其余的K-1组子集数据作为训练集(trainning test),这样会得到K个模型,用这K个模型最终的验证集的分类指标的平均数作为此K-CV下分类器的性能指标
当然在分类和回归当中都可以使用交叉验证
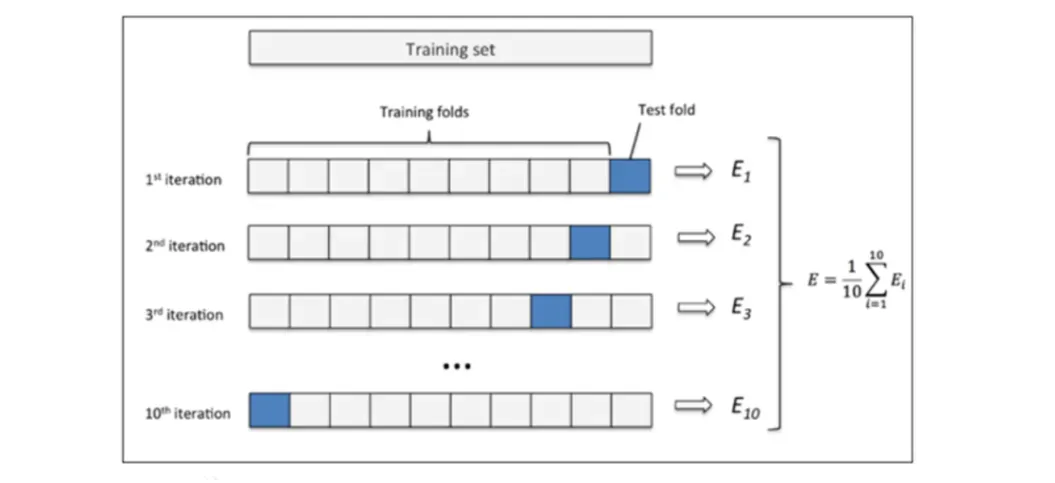
#机器学习库sklearn中,我们使用cross_val_score方法实现:
from sklearn.model_selection import cross_val_score
scores = cross_val_score(knn, X, y, cv=5)
#五折交叉验证
################定义一个返回cross-validation rmse error函数来评估模型以便可以选择正确的参数########
from sklearn.linear_model import Ridge, RidgeCV, ElasticNet, LassoCV, LassoLarsCV
from sklearn.model_selection import cross_val_score
def rmse_cv(model):
##使用K折交叉验证模块,将5次的预测准确率打印出
rmse= np.sqrt(-cross_val_score(model, X_train, y_train, scoring="neg_mean_squared_error", cv = 5)) #输入训练集的数据和目标值
return(rmse)
model_ridge = Ridge()
alphas = [0.05, 0.1, 0.3, 1, 3, 5, 10, 15, 30, 50, 75]
cv_ridge = [rmse_cv(Ridge(alpha = alpha)).mean() #对不同的参数alpha,使用岭回归来计算其准确率
for alpha in alphas]
cv_ridge
#绘制岭回归的准确率和参数alpha的变化图
cv_ridge = pd.Series(cv_ridge, index = alphas)
cv_ridge.plot(title = "Validation - Just Do It")
plt.xlabel("alpha")
plt.ylabel("rmse")保存模型
机器学习库sklearn中,我们使用joblib方法实现:
from sklearn.externals import joblib
joblib.dump(knn, 'filename.pkl')
knn1 = joblib.load('filename.pkl')
#测试读取后的Model
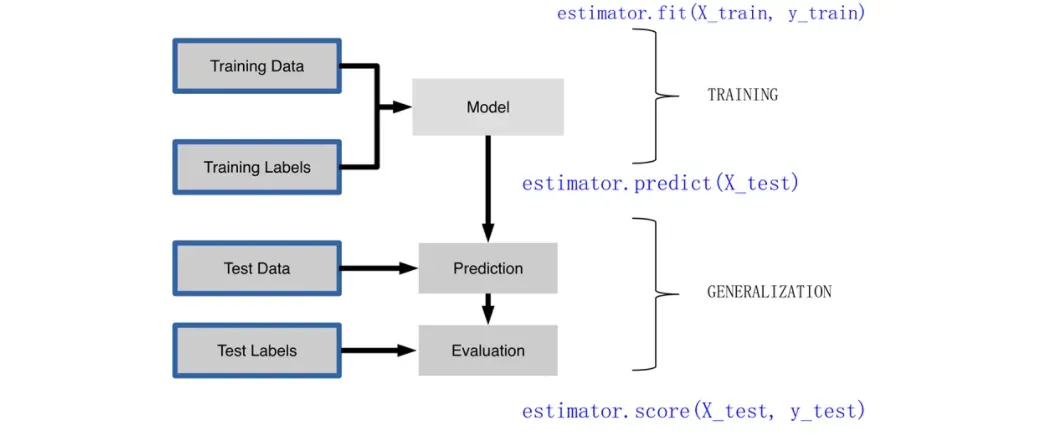
print(knn1.score(X_test, y_test))有人可能会疑惑,为什么要保存模型,一般不是通过一运行就可以了吗,答案是不一定,每次的模型由于数据分割的参数设置的不一样,模型的效果也可能不一样,所以懂得如何保存模型也是不错的。
机器学习中的拟合问题
过拟合是指为了得到一致假设而使假设变得过度严格。避免过拟合是机器学习设计中的一个核心任务。一般是在训练集上评分很高
-
使用的模型比较复杂,学习能力过强
-
有噪声存在
-
数据量有限
-
过拟合:做的太过好以至于偏离了原本,泛化能力差
-
欠拟合:泛化能力强,但过于泛化
那么如何解决呢?
-
寻找参数的最优:超参数优化器
-
使用sklearn中的学习曲线
具体的解决方案如下:
-
收集更多的数据
-
通过正则化引入罚项
-
选择一个参数相对较少的简单模型
-
降低数据的维度
L1正则化
过拟合问题产生的原因,直观来说就是某些维度上的权重系数太”偏激”了,正则化通过添加罚项,使得模型的偏差增大,方差减小,使得权重系数均向0趋近,越是”偏激”的权重系数就越是被打压,一定程度上解决了过拟合问题。
如下图所示,当C的值(也就是罚项的倒数)减小时,也就是当罚项增大时,权重系数都在往0逼近
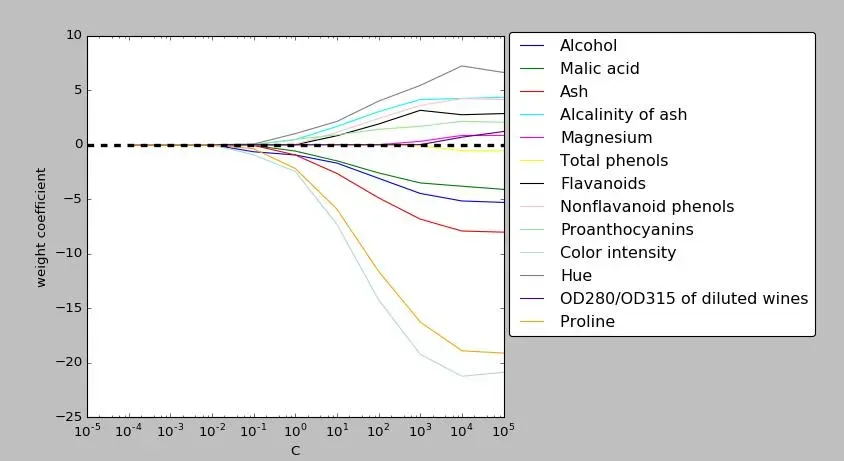
L1和L2的异同点
相同点:都用于避免过拟合
不同点:
(1) L1可以让一部分特征的系数缩小到0,从而间接实现特征选择。所以L1适用于特征之间有关联的情况。
(2) L2让所有特征的系数都缩小,但是不会减为0,它会使优化求解稳定快速。所以L2适用于特征之间没有关联的情况
序列特征选择算法(SBS)
SBS是一个不断删除特征,并通过价值函数进行贪心的特征选择算法,用来降低特征的维度
通过随机森林判断特征的重要性
随机森林可以帮助我们获得特征的重要性等级,从而可以选择出最重要的那几个特征
至于常见的特征筛选,有集成学习里面的各类算法
实现代码
# 使用不同的方法解决过拟合问题
# 1. L1正则
# 2. SBS
# 3. RandomForest
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split # 用于分离训练集和验证集
from sklearn.preprocessing import MinMaxScaler # Min-Max归一化
from sklearn.preprocessing import StandardScaler # 标准化
from sklearn.metrics import accuracy_score # 计算分类准确率
from sklearn.svm import SVC # 支持向量机
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from Chapter4.RatingFeature_SBS import SBS
df_wine = pd.read_csv('./Data/UCI/wine.data')
df_wine.columns = [
'Class label', # 注意:第一行是ClassLabel, 需要额外添加这个column
'Alcohol',
'Malic acid',
'Ash',
'Alcalinity of ash',
'Magnesium',
'Total phenols',
'Flavanoids',
'Nonflavanoid phenols',
'Proanthocyanins',
'Color intensity',
'Hue',
'OD280/OD315 of diluted wines',
'Proline '
]
# print('Class labels', np.unique(df_wine['Class label']))
# print(df_wine.head())
X, y = df_wine.iloc[:, 1:].values, df_wine.iloc[:, 0].values
# X, y = df_wine.values[:, 1:], df_wine.values[:, 0] 与上面这一句等价
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# 对数据进行Min-Max归一化
mms = MinMaxScaler()
X_train_norm = mms.fit_transform(X_train)
x_test_norm = mms.transform(X_test)
# 对数据进行标准化
stdsc = StandardScaler()
X_train_std = stdsc.fit_transform(X_train)
X_test_std = stdsc.transform(X_test)
def solve_by_SBS(num_of_features):
knn = KNeighborsClassifier(n_neighbors=2)
sbs = SBS(knn, k_features=1)
sbs.fit(X_train_std, y_train)
# 查看当使用n个特征的时候,哪n个特征最有用,SBS是一个接一个的删掉最不好的特征
n = num_of_features
total = df_wine.shape[1]-1
k_n = list(sbs.subsets_[total-n])
return k_n
def solve_by_RandomForest(num_of_features):
forest = RandomForestClassifier(n_estimators=10000, random_state=0, n_jobs=-1)
forest.fit(X_train, y_train)
importances = forest.feature_importances_
indices = np.argsort(importances)[::-1]
# 返回最优的n个特征的索引
return indices[:num_of_features]
def train_by_KNN(X_train_std, y_train, X_test_std, y_test):
knn = KNeighborsClassifier(n_neighbors=2, p=2, metric='minkowski')
knn.fit(X_train_std, y_train)
y_prediction = knn.predict(X_test_std)
print('Misclassified samples: %d' % (y_test != y_prediction).sum())
print('Accuracy: %f' % accuracy_score(y_test, y_prediction))
return accuracy_score(y_test, y_prediction)
def train_by_SVM(X_train_std, y_train, X_test_std, y_test):
svm = SVC(kernel='linear', C=1.0, random_state=0)
svm.fit(X_train_std, y_train)
y_prediction = svm.predict(X_test_std)
print('Misclassified samples: %d' % (y_test != y_prediction).sum())
print('Accuracy: %f' % accuracy_score(y_test, y_prediction))
# 使用SBS方法从1开始查找最优的特征
accuracies = []
for n in range(1, X_train.shape[1]):
print('Feature Number', n ,': ')
index = solve_by_SBS(num_of_features=n)
best_train_std = X_train_std[:, index]
best_test_std = X_test_std[:, index]
accuracy = train_by_KNN(best_train_std, y_train, best_test_std, y_test)
accuracies.append(accuracy)
plt.plot(range(len(accuracies)), accuracies, label='SBS', marker='o', color='blue')
# 使用RF方法从1开始查找最优的特征
accuracies = []
for n in range(1, X_train.shape[1]):
print('Feature Number', n, ': ')
index = solve_by_RandomForest(num_of_features=n)
best_train_std = X_train_std[:, index]
best_test_std = X_test_std[:, index]
accuracy = train_by_KNN(best_train_std, y_train, best_test_std, y_test)
accuracies.append(accuracy)
plt.plot(range(len(accuracies)), accuracies, label='RandomForest', marker='x', color='red')
plt.xlabel('Number of Best-Choosed Features')
plt.ylabel('Accuracy')
plt.xlim([-1, len(accuracies)+1])
plt.ylim([0, 1.2])
plt.legend(loc='upper left')
plt.show()
# lr = LogisticRegression(penalty='l1', C=0.1) # 感觉惩罚系数没必要这么大,C是惩罚系数的倒数
# lr.fit(X_train_std, y_train)
# print('Training accuracy:', lr.score(X_train_std, y_train))
# print('Test accuracy:', lr.score(X_test_std, y_test))键盘敲定,写到此处已是深夜烛灯,感慨良多,收获颇多!!!
差不多机器学习的框架和评估指标以及相应的知识点总结的差不多了,后续将会更新模型算法案例及底层原理的剖析!

每文一语
你想要的生活,都是自己选择,没有其他人强迫,活出自己的精彩,趁青春,做点自己想做的事情吧!
版权声明:本文为博主王小王-123原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_47723732/article/details/122660071