写在最前边
-
这个文章是《图解GPT-2 | The Illustrated GPT-2 (Visualizing Transformer Language Models)》的一部分,因为篇幅太长我就单独拿出来了。
当然如果你只想了解自注意力机制可以只看本文的前半部分。
后半部分主要是讲Masked Self-attention在GPT-2中的应用,不了解GPT-2的可以忽略这部分内容。
-
我补充的内容格式如下:
这是我补充的内容。
仅属于我的个人理解,如有漏误欢迎批评指正。
文章目录
正文
看下图,图中表示的是使用自注意力处理 输入序列中的it单词 的时候。

接下来我们详细介绍一下这一过程是如何实现的。
注意,接下来的图解过程会用到很多 “向量” 来图解算法机制,而实际代码实现是使用 矩阵 进行计算的。这个分析过程是想让读者了解在处理过程中每个单词发生了什么,因此本文的重点是对单词级(word-level)处理逻辑进行解析。
自注意力
我们从原始的自注意开始,它是在一个Transformer组件(encoder)中计算的。我们先来看看这个简单的Transformer组件,假设它一次只处理四个tokens。
仅需三步即可实现自注意力:
- 为每个单词路径创建Query、Key、Value。
- 对于每个输入token,使用其Query向量对其他所有的token的Key向量进行评分,获得注意力分数。
- 将Value向量乘以上一步得到的注意力分数,之后加起来。

1. 创建Query、Key、Value
现在我们只关注第一个路径, 我们需要用它的Query和所有的Key比较,这一步骤会为每个路径都生成一个注意力分数。
先不管什么是多头自注意力,只考虑自注意力,也就是只有一个head的情况。自注意力计算的第一步就是要计算出每个路径的Query、Key、Value三个向量。
1. 看下图是一次处理四个tokens,每个token都有它单独的路径,第一路径指的是
这个token。
2. 对于每个token来说对应的Query、Key、Value是三个向量,而在实际代码计算中是使用整个输入序列的矩阵。
3. 获得Query、Key、Value三个向量的方法是 每个单词的表示向量和对应的权重矩阵()做矩阵乘法。

2. 计算注意力分数
现在我们已经有了Query、Key、Value三个向量。在第二步我们只需要用到Query和Key向量。因为我们关注的是第一个token,所以我们将第一个token的Query和其他token的key向量做点乘,这样计算会得到每一个token的注意力分数。

3. 求和
现在对于每个token,将上一步得到的注意力分数乘以Value向量。将相乘之后的结果加起来,那些注意力分数大的占比会更大。

看下图,注意力分数乘以每个Value向量,原作者用不同深浅的蓝色的框框表示计算之后的结果。可以看到
比较显眼,
几乎看不到了,然后将计算结果加起来得到
。这个
这一过程可以认为注意力分数就是表示不同单词重要性的权重,而整个自注意力计算就是求所有token的加权和,这一过程可以引入其他token的表示,让当前token获得上下文信息。
之后我们对每个token都进行相同的操作,最终会得到每个token新的表示向量,新向量中包含该token的上下文信息。之后会将这些数据传给Transformer组件的下一个子层(前馈神经网络):

图解Masked Self-attention
现在我们已经了解了Transformer中普通的自注意力机制,让我们继续看看带Masked自注意力。
Masked自注意力和普通的自注意力是一样的,除了第二步计算注意力分数的时候有点差异。
假设模型只有两个token作为输入,我们当前正在处理第二个token。在下图的例子中,最后两个token会被屏蔽掉。这样模型就可以干扰计算注意力分数这一步骤,它会让未输入的token的注意力得分为0,这样未输入的token就不会影响当前token的计算,当前token的注意力只会关注到在它之前输入的tokens。

还是假设输入序列由四个单词组成,例如robot must obey orders。在语言建模场景中,每个单词需要一个步骤处理(假设现在每个单词都是一个token),因此这个序列包含四个处理步骤。由于模型是按照批量(batch)进行处理的,我们可以假设这个模型的批量大小为4(batch_size = 4),然后模型将把整个序列作为一个batch进行处理。
假设现在每个单词都是一个token。单词word 不一定等于 token,这是由分词方式决定的。

token无法直接计算注意力分数,因此我们需要用tokens对应的Query和Key进行计算。搞成矩阵乘法的形式,我们通过将Query向量乘以Key矩阵来计算注意力分数。


-
第一步:只输入一个词
robot,当模型处理数据集中的第一个单词时,也就是score矩阵的第一行,因为其中只包含一个单词robot,所以它的注意力100%集中在这个单词上。 -
第二步:输入
robot must,当模型处理第二个单词must时(score矩阵第二行),48%的注意力会放在robot上,52%的注意力会放在must上。 -
以此类推……
GPT-2 的 Masked Self-attention
让我们更详细地了解一下GPT-2中的masked注意力。
现在还是假设模型做预测任务,每次处理一个 token。
使用训练好的模型进行预测的时候,模型在每次迭代后都会增加一个新词,对于已经处理过的token来说,沿着之前的路径重新计算效率很低。
因为一个训练好的模型,每个组件的权重矩阵是固定的。每次增加一个token都要重新计算整个输入序列的QKV的话会造成巨大的计算开销。
比如a robot must obey the rule,如果第一次迭代时候只有a,仅需要计算它的QKV,第二次迭代时候是a robot,就需要计算二者的QKV。但是这样就重复计算了a的QKV
GPT-2的高效处理方法如下:
假设我们处理输入序列的第一个tokena,(暂时忽略<s>)。
之后GPT-2会保留a token的Key和Value向量。以便之后使用。
注意,每个组件的自注意力层都有各自的Key和Value向量,不同的组件中Key和Value向量不共享:

在下一次迭代中,当模型处理单词robot时,它不需要为a重新生成Query、Key、Value,而是直接用第一次迭代中保存的那些:

1. 创建queries, keys和values
让我们假设这个模型正在处理单词it。如果我们讨论的是最底层的decoder组件,那么它接收的token的输入是token的嵌入+ 第九个位置的位置编码:

Transformer中的每个组件之权重不共享,都有自己的权重。我们首先要和权重矩阵进行计算,我们使用权重矩阵创建Query、Key、Value。

自注意力子层会将输入乘以权值矩阵(还会加上bias,图中没表示出来),乘法会产生一个向量,这个向量是单词it的Query、Key、Value的拼接向量。

将输入向量乘以注意力权重向量(然后添加一个偏差向量),就会得到这个token的Query、Key、Value向量。
1.5 划分注意力头
在前面的例子中,我们只专注于自注意力,忽略了“多头”(muti-head)的部分。现在说一下什么是“多头”。
就是将原来一个长的Query、Key、Value向量按照不同位置截取并拆分成短的向量。

前边的例子中我们已经了解了一个注意力头怎么计算,现在我们考虑一下多头注意力,如下图考虑有三个head。

2. 注意力分数
现在我们可以开始打分了,你们应该知道,我们这只画出来一个注意力头(head #1),其他的头也是这么计算的:

现在,该token可以针对其他token的所有Value进行评分:

3. 求和
和前边讲的一样,我们现在将每个Value与它的注意力分数相乘,然后将它们相加,产生head #1的自我注意结果:

3.5 合并注意力头
不同的注意力头会得到不同的,我们处理不同注意力头的方法是把这个
连接成一个向量:

我们需要把这个拼接向量再做一次projection,得到另一个同类表示。
作者原文写的“We need to first turn this Frankenstein’s-monster of hidden states into a homogenous representation.” 直译是“我们需要首先把这个隐藏状态的弗兰肯斯坦怪物变成同类表示。”
弗兰肯斯坦是一个人造人,是个怪物,作者是玛丽·雪莱,这本书可以看作是科幻小说开山之作。感兴趣的可以看一下。
拼接向量再做一次projection(映射): 对于这句我存在一些疑问。因为我看了其他人对这篇文章的翻译,如下图,这个人说这里的projection是因为维度不对,需要调整维度。这是错误的!!! 看下边第4节可以知道这个projection并没有改变维度、向量长度。至于为什么这里需要projection,第4节也进行了解释。

4. 映射 projection
我们要让模型学习到 如何将自注意力的拼接结果更好地映射成前馈神经网络可以处理的向量 。因此这里要做一步映射。
在这就用到了我们的第二大权重矩阵,它将自注意力的拼接结果映射为自注意力子层的输出向量:

注意这里的Zoom out意思是维度没有变,只是用更少的格子来表示这个向量。
既然这有一个权重,那肯定模型训练过程中要学啊,学这个权重矩阵的目的就是为了让模型能把自注意力计算之后拼接的那个矩阵 映射到 前馈神经网更好处理的矩阵,个人认为这里的projection就是做了一个平滑作用。
之后我们就产生了可以发送到下一层的向量:

GPT-2 全连接神经网络第一层
全连接神经网络的输入是自注意力层的输出,用于处理自注意力子层得到的token的新的表示,这个新的表示包含了原始token及其上下文的信息。
全连接神经网络由两层组成。第一层是把向量转化到模型大小的4倍(因为GPT-2 small是隐状态大小是768,所以GPT-2中的全连接神经网络第一层会将其投影到768*4 = 3072个单位的向量中)。为什么是四倍?因为原始Transformer的也是四倍,这里就没改。

上图没画出bias。
GPT-2 全连接神经网络第二层:投影到模型维度
第二层将第一层的结果再投射回模型的维度(GPT-2 small为768)。这个计算结果就是一个完整的Transformer组件(decoder)对token的处理结果。

上图没画出bias。
你学完了!
总结一下输入向量都会遇到哪些权重矩阵:

每个Transformer组件都有自己的权重。组件之间权重不共享!
另外,该模型只有一个token的嵌入矩阵和一个位置编码矩阵:
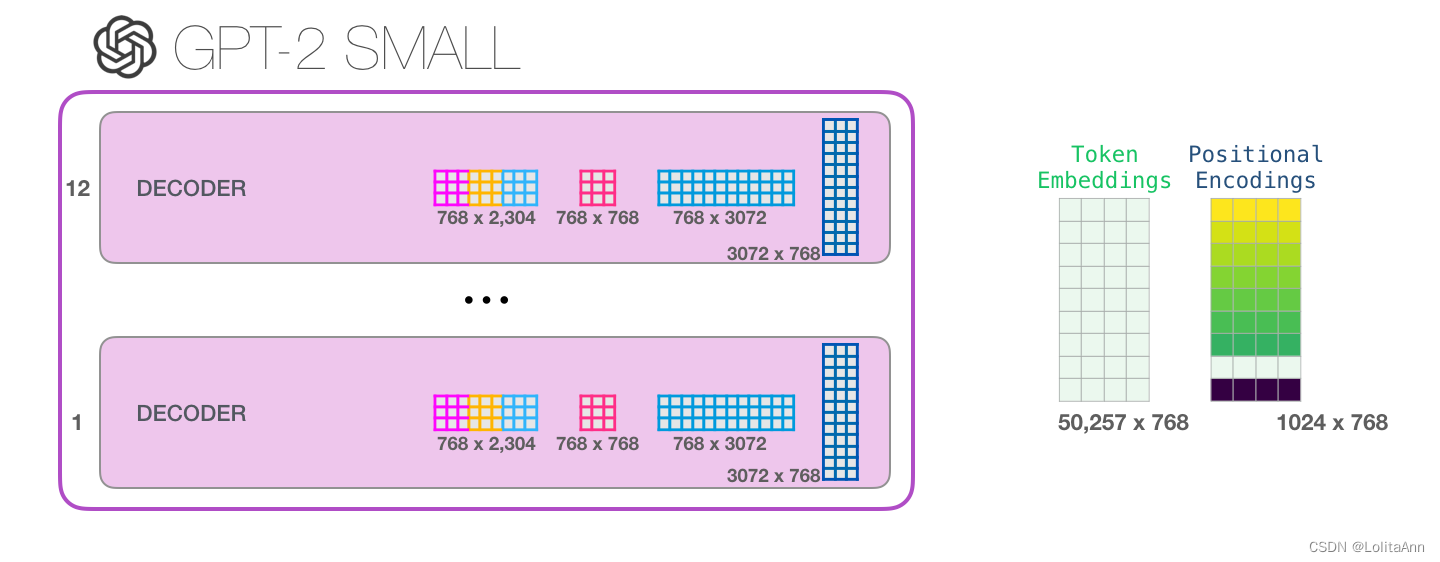
如果你想知道模型的所有参数,我在这进行了统计:
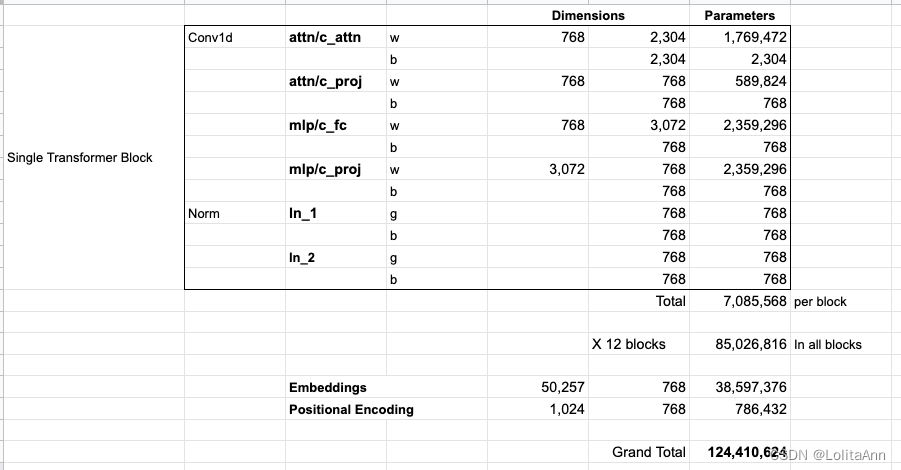
由于某种原因,它们加起来有124M的参数,但是实际GPT-2 small模型只有117M参数。我不知道为什么,但这就是他们发布的代码中的参数数量(如果我错了欢迎指正)。
上图中博客作者对GPT-2 small的参数进行了统计,计算结果和OpenAI开源的GPT-2模型的参数量不一样。
作者算的是124M,实际代码中只有117M,
原因如下:
OpenAI团队说:“我们论文里参数计算方法写错了。所以你现在可以看到GPT-2 small模型参数只有117M……”
截图来源https://github.com/openai/gpt-2

文章出处登录后可见!