ControlNet 和 T2I-Adapter 的突破性在哪里?有什么区别?
其它为 T2I 扩散模型施加条件引导的相关研究
ControlNet 和 T2I-Adapter 的实际应用效果如何?
使用体验上,跟 SD原生支持的 img2img 有什么区别?
ControlNet 在插画创作上的潜力
多种条件引导的组合使用
ControlNet 在3D和动画创作上的潜力
哪里可以免安装且免费玩上?
论文和模型
这几天 AIGC 社区的兴奋程度达到了几个月内的高峰,快赶上去年 Stable Diffusion 首次发布的热闹劲。主角就是 ControlNet,一个基于 Stable Diffusion 1.5 的轻型预训模型,能利用输入图片(input image)里的边缘特征、深度特征 或 人体姿势的骨架特征(posture skeleton),配合文字 prompt,精确引导图像在 SD 1.5 里的生成结果。
下图来自 ControlNet 论文的 demo,使用 Canny 坎尼边缘检测提取了输入图片里鹿的轮廓特征,用 Prompt “a high-quality, detailed, and professional image” 在 SD 1.5 里生成的 4 张结果图片。

ControlNet 的预印本 发布于 2 月 10 日,同时开源了预训模型的和论文里所有 input condition detector 的权重。社区迅速在 Huggingface 部署了可以试用的 Demo, 并打包成可在 Stable Diffusion WebUI 里使用的外挂插件。
6 天后,腾讯 ARC 也发布了类似解决方案 T2I-Adapter。
ControlNet 和 T2I-Adapter 的突破性在哪里?有什么区别?
抛开如何在扩散模型里融合额外的模态输入这样的技术细节(因为我看不懂 ),大面上看,这两者思路很相近。突破点都是 如何在已有的模型基础上添加可训练参数,控制预先训练好的大型扩散模型,以支持额外的输入条件 (input condition),达到在新任务上的效果迁移。即使在训练数据集很小的情况下,也能达到稳健的学习效果。
),大面上看,这两者思路很相近。突破点都是 如何在已有的模型基础上添加可训练参数,控制预先训练好的大型扩散模型,以支持额外的输入条件 (input condition),达到在新任务上的效果迁移。即使在训练数据集很小的情况下,也能达到稳健的学习效果。
通过建立一个框架,在保留大型模型从数十亿图像中获得的优势和能力时,同时拥有快速训练方法,在可接受的时间和算力资源条件内,利用预训练的权重,以及微调策略或转移学习,将大型模型优化后用于特定任务。兼顾对泛问题的处理能力和满足具体任务中用户对生成控制需求的灵活性,最大程度的保留原模型的生成能力。
ControlNet 和 T2I-Adapter 的框架都具备灵活小巧的特征,训练快,成本低,参数少,很容易地被插入到现有的文本-图像扩散模型中,不影响现有大型模型的原始网络拓扑结构和生成能力。同时,它俩都能兼容其它基于 Stable Diffsuion 的 fine-tune 的图像生成模型,而无需重训,比如 Anything v 4.0 (二次元风格的 SD 1.5 fine-tune 模型)。
训练一种新输入条件模型 (input condition detector model),比如支持一种新的边缘或深度检测算法的模型,在这类框架思路下可以做到和常见 fine-tune 一样快。
ControlNet 在论文里提到,Canny Edge detector 模型的训练用了 300 万张边缘-图像-标注对的语料,A100 80G 的 600个 GPU 小时。Human Pose (人体姿态骨架)模型用了 8 万张 姿态-图像-标注 对的语料, A100 80G 的 400 个 GPU 时。
而 T2I-Adapter 的训练是在 4 块 Tesla 32G-V100 上只花了 2 天就完成,包括 3 种引导条件:sketch(15 万张图片语料),Semantic segmentation map(16 万张)和 Keypose(15 万张)。
两者的差异:ControlNet 目前提供的预训模型,可用性完成度更高,支持更多种的条件引导(9 大类)。
而 T2I-Adapter“在工程上设计和实现得更简洁和灵活,更容易集成和扩展”(by 读过其代码的 virushuo)此外,T2I-Adapter 支持一种以上的引导条件,比如可以同时使用 sketch 和 segmentation map 作为输入条件,或 在一个蒙版区域 (也就是 inpaint ) 里使用 sketch 引导
另外值得一提的是,这两篇论文的首作都是年轻的华人 AI 研究者,ControlNet 的首作 Lvmin Zhang,21 年本科毕业,现为斯坦福 PHD,2018 年大二时便一作发表了 ACM Graphics 的高引论文,被视为 AI 领域在本科阶段就有独立科研能力的“天才”。他之前最为著名的项目是 Style2paints, 利用 Enhanced Residual U-net 和 Auxiliary Classifier GAN 为灰度动漫线稿上色。他作为这个小型研究组织的创始人,一直在关注 AI 在二次元风格图像生成方向的模型训练、语料库整理及工具开发。
而发布 T2I-Adapter 的腾讯 ARC 是腾讯关注智能媒体相关技术的事业群,以视觉、音频和自然语言处理为主要方向。
其它为 T2I 扩散模型施加 Input condition 引导的相关研究
当然,这年头没有什么 ML 的解决方案是横空出世的,去年 12 月,Google 就发布了论文 Sketch-Guided Text-to-Image Diffusion Model,使用了 classifier guidance 的思路,设计了一个称为 latent edge predictor 的框架,能够在 Stable Diffusion 的 noisy latent vector 上预测每步的生成是否匹配输入图片里探测到的 sketch 边缘。再将预测结果用于引导 扩散模型的生成。
但这一框架最大的问题在于边缘的生成(梯度引导)是不考虑文本信息且不存在任何交互的。独立引导造成的结果可以让生成结果里图像的边缘与引导输入相吻合,但与所对应的语义信息并不能很好地贴合。

https://arxiv.org/abs/2211.13752
今年 1 月发布的另一篇论文 GLIGEN: Open-Set Grounded Text-to-Image Generation。“以一个类似于 NLP 领域 transformer-adapter 的 parameter efficient 的思路来微调 Stable-Diffusion 模型(即固定已有模型的参数,只训练在模型里额外添加的组件),并成功使得 SD 模型可以参考 bounding box 的位置信息,来对不同实体进行生成 ”。
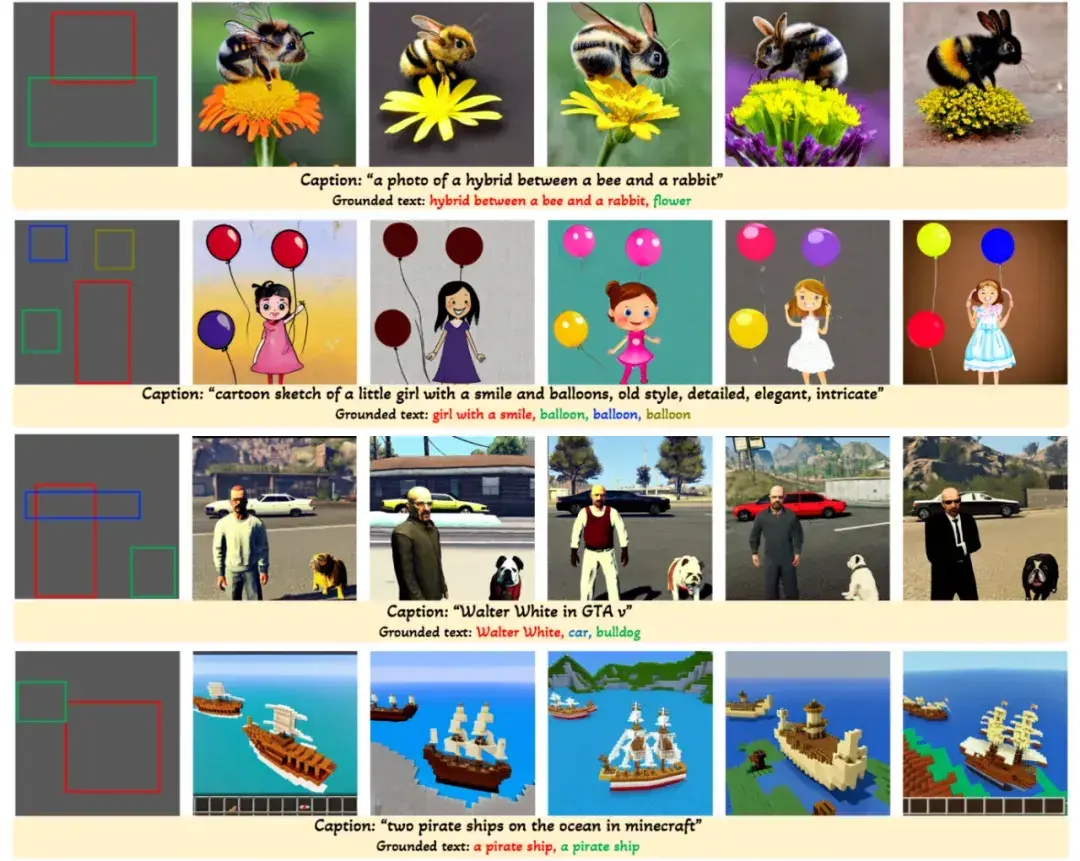

https://arxiv.org/abs/2301.07093
这篇论文里的放出了可运行的 demo,效果得到了实证。知乎上的 NLP 算法工程师 中森 在认为这篇论文论证了“已有的预训练文生图大模型的高度可拓展性,并且在开源模型上添加各种模态控制信息做继续训练的高度可行性”。
demo:https://huggingface.co/spaces/gligen/demo
对于这3篇论文里成果的比较,请移步他的专栏文章:https://zhuanlan.zhihu.com/p/605761756
ControlNet 和 T2I-Adapter 的实际应用效果如何?
对于 Stable Diffusion, 论引导效果,一百句 Text prompt 可能都比不上一张 input image 来得准确和高效。要观察实战效果,一千行文字介绍也比不上几组结果图片更清晰明了。
(除了标注了引用出处的图片外,其它都是作者生成的 raw outcome,基本都是未经挑选的单次生成结果)
人像类:
Input image

ControlNet 测试:将原图转化为 HDE map(Holistically-nested edge detection,一种整体嵌套式边缘检测的 DL 模型,精度比 Canny Edge 高不少),捕捉其边缘特征用于引导。

Prompt:portrait, half body, wearing a delicate shirt, highly detailed face, beautiful detail, sharp focus, by H.R. Giger

Prompt:portrait, half body, wearing a delicate shirt, highly detailed face, beautiful detail, sharp focus, by 不记得谁了

Prompt:portrait, half body, wearing a delicate shirt, highly detailed face, beautiful detail, sharp focus, by Alphonso Mucha

T2I-Adapter 测试:使用 Sketch-guided Synthesis 将原图里转为草稿,捕捉边缘特征用于引导。(Adapter 选用的边缘检测算法是一个基于 CNN 模型的轻量级的像素差异网络 PiDiNet(https://arxiv.org/abs/2108.07009)

Prompt:portrait, half body, wearing a delicate shirt, highly detailed face, beautiful detail, sharp focus (以下3张皆是)



建筑类:
输入图片 (柯布西耶的萨伏伊别墅)

ControlNet 测试:将原图转化为 Hough Line。(霍夫变换是一个1962 年发明的专利算法,最初是为了识别照片中的复杂线条而发明的。擅长用于检测直线和几何形状,适用于捕捉建筑类图像边缘的 )
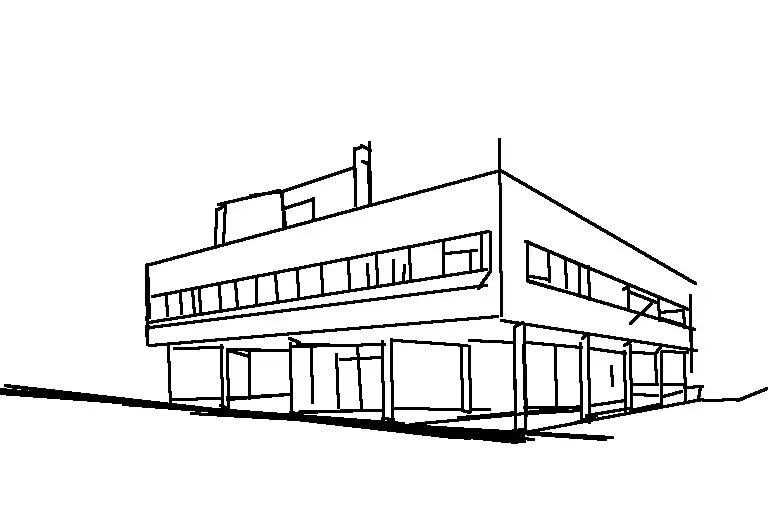
Prompt: building, super detail, by Giorgio de Chirico

Prompt: building, super detail, by Charles Addams

Prompt: building, super detail, by Alena Aenami

T2I-Adapter 测试:使用 Sketch-guided Synthesis 将原图里转为草稿 (纵横比被我搞错了  )
)

Prompt:building, super detail, by Giorgio de Chirico (下同)



风景类:
Input image (由 SD2.0 生成)

ControlNet 测试:将原图转化为 semantic segmentation map(语义分割map),捕捉其中的形状区块用于引导。

Prompt: artwork by Eyvind Earle, stunning city landscape, street view, detailed

Prompt: artwork by John Berkey, stunning city landscape, street view, detailed

Prompt: artwork by Alphonso Mucha, stunning city landscape, street view, detailed

T2I-Adapter 测试:使用 Sketch-guided Synthesis 将原图里转为草稿,捕捉边缘特征用于引导。

在 SD 1.4 里的生成结果 (T2I-Adapter 的预训模型里只支持 PLMS 这一种 sampling,可能会影响它的生成效果):
Prompt: artwork by Eyvind Earle, stunning city landscape, street view, detailed

Prompt: artwork by Eyvind Earle, stunning city landscape, street view, detailed

人体 post skeleton:
Input image

ControlNet 测试:将原图转化为 human pose,捕捉其中的姿势骨骼用于引导
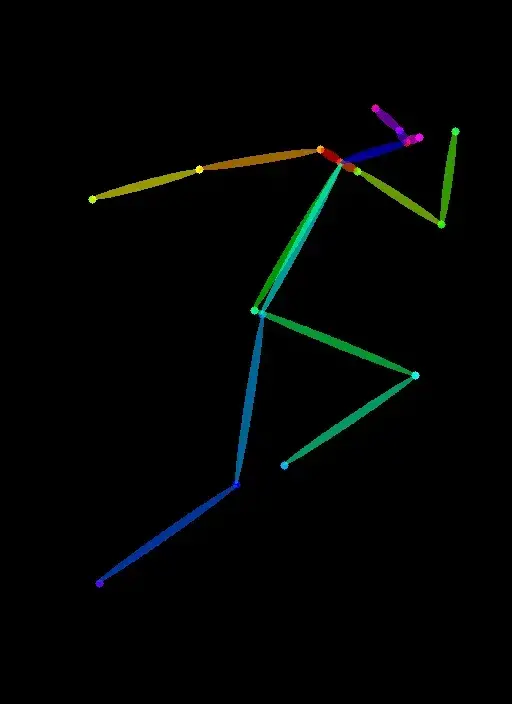
在 SD 1.5 里的生成结果:
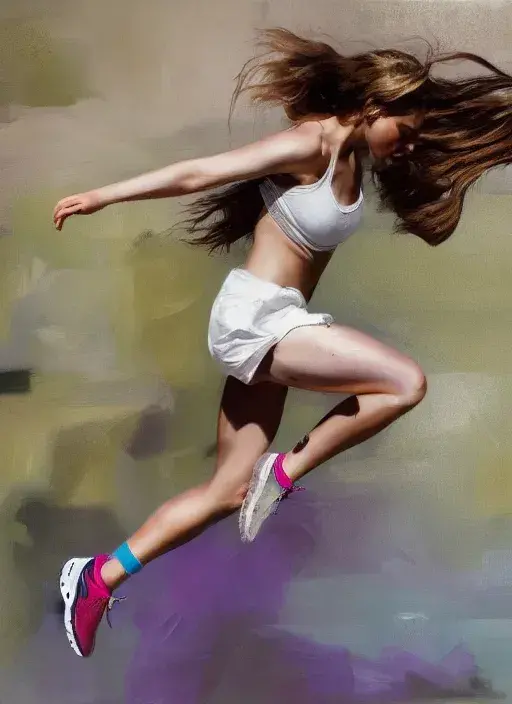

在 Anything 4.0 里的生成结果:

T2I-Adapter 测试:
使用同一张骨骼引导图在 SD 1.4 里的生成结果


用手绘草图作引导:
最后一组是用 User Scribble(Sketch)作为生成引导的测试。我画了个吃手章鱼猫的草图

ControlNet 在 SD 1.5 里的生成结果:
Prompt: Octocat, cat head, cat face, Octopus tentacles, by 忘了是谁

Prompt: Octocat, cat head, cat face, Octopus tentacles, by H.R. Giger

T2I-Adapter 在 SD 1.4 里的生成结果:
Prompt: Octocat, cat head, cat face, Octopus tentacles, oil painting

T2I-Adapter 支持一个匹配强度的参数,上图用了 50% 强度,下图用了40% 强度,prompt 相同。
上图与草稿图里章鱼猫的轮廓更为吻合,而下图中生成的触手有更多偏移。

Depth-based 引导
除了 边缘检测、草稿和 post 骨骼 这 3 类基础 input condition ,ControlNet 还支持了另一种非常有用的深度引导。
输入图片:

在 ControlNet 里将原图转化为 法线贴图 Normal Map (一种模拟凹凸处光照效果的技术,是凸凹贴图的一种实现。相比于深度 Depth Map 模型,法线贴图模型在保留细节方面似乎更好一些)

Prompt: by H.R. Giger, portrait of Snake hair Medusa, snake hair, realistic wild eyes, evil, angry, black and white, detailed, high contrast, sharp edge

by Alberto Seveso, portrait of Snake hair Medusa, snake hair, photography realistic, beautiful eyes and face, evil, black and white, detailed, high contrast, sharp edge, studio light

by Alphonso Mucha, portrait of Snake hair Medusa, snake hair, beautiful eyes and face of a young girl, peaceful, calm face, black and white, detailed, high contrast, sharp edge

使用体验上,上面这些引导控制跟 SD 原生支持的 img2img 有什么区别?
下图是我用 5 分钟快速涂抹的草稿,作为 input image 输入,使用 ControlNet 里的 Canny edge 边缘检测作为输入条件,生成了 3 张结果。


Prompt:a deer standing on the end of a road, super details, by Alice Nee

a deer standing on the end of a road, super details, by C215

a deer standing on the end of a road, super details, by Canaletto

草稿中鹿后腿的边缘其实没有被很好识别出来,但配合 text prompt,所有结果图片里都还原了结构良好的鹿。
而下面这几张是 img2img 引导生成的结果。通过比较输入图片和生成结果,很容易发现,img2img 的 input image 提供的引导主要是噪音的分布,影响构图和颜色,但对生成对象形状 (边缘) 的与输入图片的贴合度并不高(鹿角特别明显)。
Prompt:a vibrant digital illustion of a deer standing on the end of a road, top of mountain, Twilight, Huge antlers like tree branches, giant moon, art by James jean, exquisite details, low poly, isometric art, 3D art, high detail, concept art, sharp focus, ethereal lighting
SD 1.5 里的生成结果


SD 2.0 里的生成结果

而 img2img 的 Noise Strength 参数 ( 0.0 – 1.0)会决定 输入图片和生成结果的近似程度。参数越大,近似度越高。想要获得跟输入图片更贴合的形状,就得牺牲掉 扩散模型的“生成能力”。但引导图片里的颜色和构图都能持续保留为。
Input Image
Output: Noise Strength Parameter: 0.8

Output: Noise Strength Parameter: 0.5

ControlNet 条件引导在图像创作上的潜力
下面是一系列社区使用 ControlNet 引导 AI 进行创作生成的实验和探索。
使用 Post reference 工具生成引导图像,精确控制生成人物的透视及动作。如果只使用 text prompt 引导,这是几乎完全无法做到的事。


Jumping from a wall. ControlNet is fun.
byu/elkar4 inStableDiffusion
另一个用 Post reference 工具(MagicPoser App) 生成引导图后, 使用 SD fine-tune 模型 Realistic Vision 完成的生成效果。
https://civitai.com/models/4201/realistic-vision-v13





ControlNet + MagicPoser App + Realistic Vision
byu/kaiwai_81 inStableDiffusion
使用 Control Net 里的 深度图引导 (depth map),精确控制透视和场景。

ControlNetのDepthめっちゃ面白い!! #Aiart pic.twitter.com/dVlyAYkXI2
— jurai (@cambri_ai) February 16, 2023


— toyxyz (@toyxyz3) February 14, 2023
用 human post 引导,控制多人角色的生成

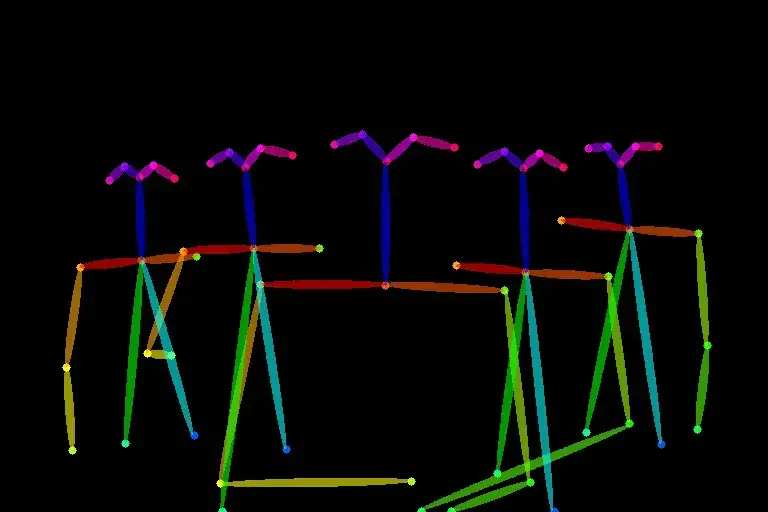


This evening I've installed #ControlNet as an extension for #automatic1111
— TomLikesRobots🤖 (@TomLikesRobots) February 16, 2023
These images use OpenPose to duplicate the pose. Still working on using with 2.1 but I'm enjoying seeing what it can do.
Details here: https://t.co/Vh5J0u8vPG#stablediffusion #aiart pic.twitter.com/wlrRYCUCLQ
日本推友 @toyxyz3 做了一系列 post skeleton 引导的实验,非常有价值。
去掉 post skeleton 上的一部分肢体后引导,ControlNet 会引导生成时 将缺失的四肢处理为被遮挡,头部处理为侧面角度 (可能需要 prompt 辅助引导)。
 https://twitter.com/toyxyz3/status/1626273906528251904?s=20
https://twitter.com/toyxyz3/status/1626273906528251904?s=20
改变 post skeleton 里是四肢的比例,ControlNet 会在引导生成时处理为透视角度。
 https://twitter.com/toyxyz3/status/1626138871598821377?s=20
https://twitter.com/toyxyz3/status/1626138871598821377?s=20
改变 post skeleton 里的头身例,ControlNet 会在引导生成时将人物对象处理为不同年龄(或Q版)。
 https://twitter.com/toyxyz3/status/1626137567178657792?s=20
https://twitter.com/toyxyz3/status/1626137567178657792?s=20
改变 post skeleton 里的肢体数量。。。ControlNet 会在引导生成时将处理为,额~ 半兽人  。
。
 https://twitter.com/toyxyz3/status/1626977005270102016?s=20
https://twitter.com/toyxyz3/status/1626977005270102016?s=20
@toyxyz3 还测试了是否能在画面里合理容纳更多数量人物。
 https://twitter.com/toyxyz3/status/1626138471256715265?s=20
https://twitter.com/toyxyz3/status/1626138471256715265?s=20
多种条件引导的组合使用
虽然 Control Net 还不能原生支持多种 input condition, 但加上人工的后期处理,我们可以看见其应用潜力。
使用两种引导条件分别生成人物和场景
人物使用 post skeleton 引导,场景使用 depth map 引导。分别生成完再进行合成。分开引导效果更好,也让创作设计更为灵活。(人物合成前需要抠图。另外别忘了给人物添加投影  )
)

 https://twitter.com/toyxyz3/status/1626298297211326465?s=20
https://twitter.com/toyxyz3/status/1626298297211326465?s=20

 https://twitter.com/toyxyz3/status/1626594162060718083
https://twitter.com/toyxyz3/status/1626594162060718083
同时使用不同引导图来覆盖满足两种控制需求
Reddit 用户 Ne_Nel 同时使用两张引导图(需要能支持两张 input image 的 SD 生成工具),一张用于 ControlNet 引导,一张上色后用于 img2img 引导,就可以同时控制生成结果的对象轮廓和颜色/光影。
 https://www.reddit.com/r/StableDiffusion/comments/115dr9r/more_madness_controlnet_blend_composition_color/
https://www.reddit.com/r/StableDiffusion/comments/115dr9r/more_madness_controlnet_blend_composition_color/
这也是我非常期望拥有的一种引导方式,能同时从输入图像里读取边缘和颜色这两种引导条件。基于 ControlNet 和 T2I-Adapter 的框架,说不定我们很快能看到 这样一种新的引导模型被训练出来。
下面这个实验中,@toyxyz3 也试图实验 ControlNet 在 读取 Semantic Segmentation map 的 segments 时是否有可能带上深度或颜色信息 (并没有)
 https://twitter.com/toyxyz3/status/1626835630176215045?s=20
https://twitter.com/toyxyz3/status/1626835630176215045?s=20
但第二天,社区就发现了 Semantic Segmentation 的一个特质。Semantic Segmentation 语义分割是一种深度学习算法,名字里有“语义”一词是有含义的。这种算法将一个标签或类别与图像中的每个像素联系起来。被用来识别形成不同类别的像素集合。例如,常见应用于自动驾驶、医疗成像和工业检测。比如帮助自动驾驶汽车识别车辆、行人、交通标志、路面 等不同对象的特征。而每种标签都会有一个对应的标记颜色。
从 ControlNet 的论文中可知,它使用的 segmentation map model 用的是 ADE20K 的协议。ADE20K 公开了它用于标注不同语义segments的颜色代码。
 https://www.researchgate.net/figure/Semantic-labels-of-ADE20K-data-set-in-BGR-format_fig2_339839515
https://www.researchgate.net/figure/Semantic-labels-of-ADE20K-data-set-in-BGR-format_fig2_339839515
这就意味着在设计 Segmentation map 引导图时,创作者可以反过来用。比如 改变某个 segment 的颜色,使之与 ADE20K 算法用于标注时的语义一致,比如 ADE20K 用于标注“钟表”的是草绿色,把背景那个形状块涂成草绿色,生成时,这个形状块就更大概率会被引导向生成钟表,其实该形状块与钟表常见的圆形形状不符。
不得不说,Stable Diffusion 玩家们的 Hacking 能力实在是强大。
 https://twitter.com/toyxyz3/status/1627286943783612416?s=20
https://twitter.com/toyxyz3/status/1627286943783612416?s=20
Google Doc 链接和下图里是 ADE20K 用于标注的颜色代码。
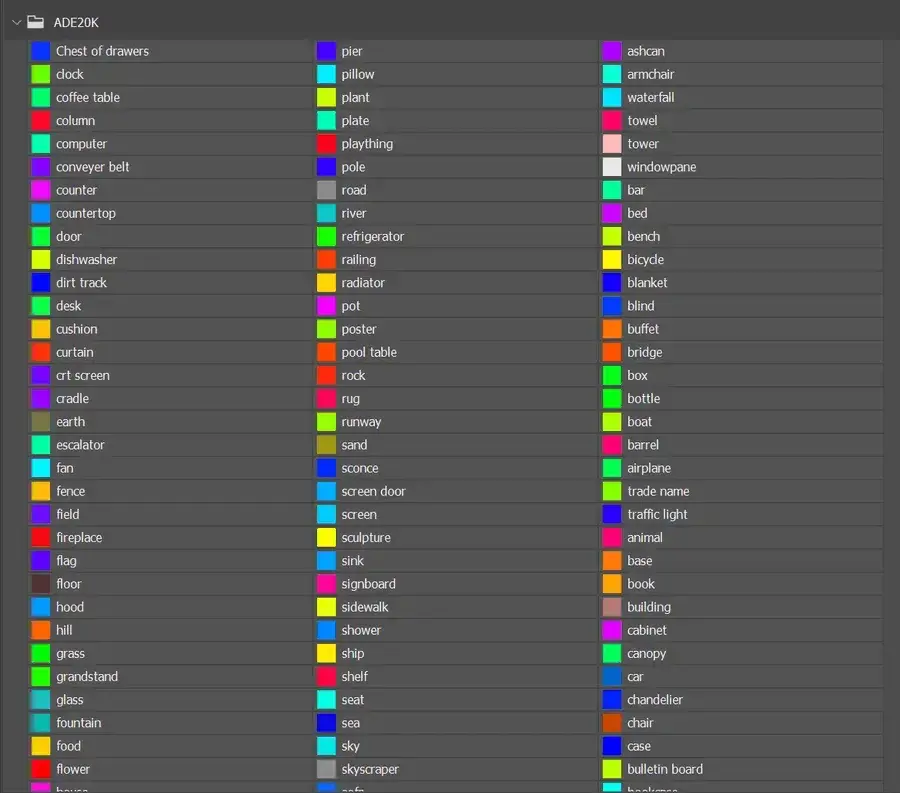 https://docs.google.com/spreadsheets/d/1se8YEtb2detS7OuPE86fXGyD269pMycAWe2mtKUj2W8/edit#gid=0
https://docs.google.com/spreadsheets/d/1se8YEtb2detS7OuPE86fXGyD269pMycAWe2mtKUj2W8/edit#gid=0
ControlNet 条件引导在3D和动画创作上的潜力
结合 Blender 使用 ContrelNet 创作 3D
Blender 里面创建的 3D 模型,导出静态图片作为 input image,使用 controlnet 的深度检测生产图像,再作为贴图贴回 blender 里的原模型上,bingo!虽然用于人体这类复杂曲面,效果会比较粗糙,但用于包装盒或建筑这类简单的几何体,应该会非常实用。
ControlnetのNormalモードを使って、3Dモデルをイラスト、アニメ調に変換した後、元の3Dモデルにテクスチャとして貼り付けます
— TDS (@TDS_95514874) February 16, 2023
Normalモードは細部の構造がよく反映されるので、かなり正確にテクスチャリングが出来ます
少し調整すればシェイプキーすら流用できそうなレベル#aiart #b3d pic.twitter.com/7cF7Qqp8PX
结合 Blender 使用 ContrelNet 创作动画
在 Blender 里生成 3D 模型后,用不同颜色标记各个部位,再把动画序列导出后 在 ControlNet 里作为 Segmentation map condition 输入,生成的动画,各部件的结构有更好的稳定性和一致性,特别适用于身体部件之间有遮挡的动作。
部位ごとにマテリアルを色分けしてレンダリング→controlnetのSegmentationでi2iをすると、かなり精度が上がります
— TDS (@TDS_95514874) February 18, 2023
特に部位が交差する部分や顔の微妙な角度で効力を発揮しているように思います#aiart #b3d pic.twitter.com/boT7Ht4QG3
使用两种输入引导的组合创作动画
人物动作使用 post skeleton 引导,场景使用 depth map 引导。分别生成完再进行合成。虽然还不是真正的 text to animation 生成,但这种方法已经能获得比之前都好的效果,更少的 glitch interference (跳帧感),人物动作更流程,背景也更稳定。
https://twitter.com/toyxyz3/status/1627417453734293504?s=20
哪里可以免安装且免费玩上 ControlNet 和 T2I-Adapter
ControlNet + SD 1.5
https://huggingface.co/spaces/hysts/ControlNet
ControlNet + Anything v4.0
https://huggingface.co/spaces/hysts/ControlNet-with-other-models
T2I-Adapter + SD 1.4
https://replicate.com/cjwbw/t2i-adapter
集成到 Stable Diffusion WebUI 里
1. 更新 WebUI 到最新版本, 在 https://github.com/Mikubill/sd-webui-controlnet 下载或安装,放到 WebUI 的 extensions 文件夹内
2. 在 https://huggingface.co/lllyasviel/ControlNet/tree/main/annotator/ckpts 下载文件放到插件目录下的 annotator 下的 ckpts 目录
3. 在 https://huggingface.co/webui/ControlNet-modules-safetensors/tree/main 下载模型(700M)
或 https://huggingface.co/lllyasviel/ControlNet/tree/main/models(5.7G)放到插件目录下的 models 目录
可以预见,会有很多集成类似引导控制的插件、API、细分工具的爆发式出现,比如
I’m working on API for the A1111 ControlNet extension. Kinda hacky but works well with my Houdini toolset.
byu/stassius inStableDiffusion
https://scribblediffusion.com/

https://huggingface.co/spaces/fffiloni/ControlNet-Video
论文和模型
Adding Conditional Control to Text-to-Image Diffusion Models
https://arxiv.org/abs/2302.05543
https://github.com/lllyasviel/ControlNet
T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models
https://arxiv.org/abs/2302.08453
https://github.com/TencentARC/T2I-Adapter
祝大家玩得愉快

意外获得的鬼畜章鱼猫向您问好。
我刚刚发布了 AIGC 艺术家样式库 lib.KALOS.art 。一个4人小团队前后忙了4周。
– 目前全球规模最大,1300+艺术家共3万余张 4v1 样式图片,
– 覆盖三个主流图像生成模型
– 为每个艺术家都生成了8~11种常见主题,如 人像、风景、科幻、街景、动物、花卉等主题




艺术家和多种主题的结合,会带来很多意想不到的结果
后现代舞台设计师去画废土科幻场景?or 立体主义雕塑家去画一张猫咪?
按人类惯有思维,用肖像画家去生成肖像,用风景画家去生成风景,其实限制了AI模型的创作力和可能性。希望 lib.kalos.art 能帮你发掘AIGC的潜力,得到更多创作灵感


点击阅读原文,访问最新最全的 AIGC 艺术样式数据库
文章出处登录后可见!