前言
在语义分割领域,由于需要对输入图片进行逐像素的分类,运算量很大。通常,为了减少语义分割所产生的计算量,通常而言有两种方式:减小图片大小和降低模型复杂度。
减小图片大小可以最直接地减少运算量,但是图像会丢失掉大量的细节从而影响精度。
降低模型复杂度则会导致模型的特征提取能力减弱,从而影响分割精度。
所以,如何在语义分割任务中应用轻量级模型,兼顾实时性和精度性能具有相当大的挑战性。
BiseNet
论文地址:[1808.00897] BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation (arxiv.org)
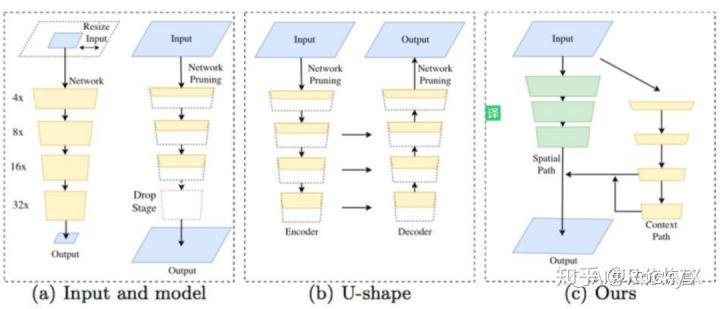
本文对之前的实时性语义分割算法进行了总结,发现当前主要有三种加速方法:
- 通过剪裁或 resize 来限定输入大小,以降低计算复杂度。尽管这种方法简单而有效,空间细节的损失还是让预测打了折扣,尤其是边界部分,导致度量和可视化的精度下降
- 通过减少网络通道数量加快处理速度,尤其是在骨干模型的早期阶段,但是这会弱化空间信息。
- 为追求极其紧凑的框架而丢弃模型的最后阶段(比如ENet)。该方法的缺点也很明显:由于 ENet 抛弃了最后阶段的下采样(Downsampling-缩减像素采样),模型的感受野不足以涵盖大物体,导致判别能力较差。
【下采样 —— 降低图片总像素数的方法,一般采用抽取像素的方式,有时候也用卷积来实现】
BiSeNet是一种新的双向分割网络,设计了一个带有小步长的空间路径来保留空间位置信息生成高分辨率的特征图;同时设计了一个带有快速下采样率的语义路径来获取客观的感受野。在这两个模块之上引入一个新的特征融合模块将二者的特征图进行融合,实现速度和精度的平衡。
【感受野(Receptive Field) —— 卷积神经网络每一层输出的特征图(feature map)上的像素点映射回输入图像上的区域大小。通俗点的解释是,特征图上一点,相对于原图的大小,也是卷积神经网络特征所能看到输入图像的区域,与卷积核大小有关。】
- 空间路径Spatial Path使用较多的 Channel、较浅的网络来保留丰富的空间信息生成高分辨率特征
- 上下文路径Context Path使用较少的 Channel、较深的网络快速 downsample来获取充足的 Context。
- 基于这两路网络的输出,文中还设计了一个Feature Fusion Module(FFM)来融合两种特征。
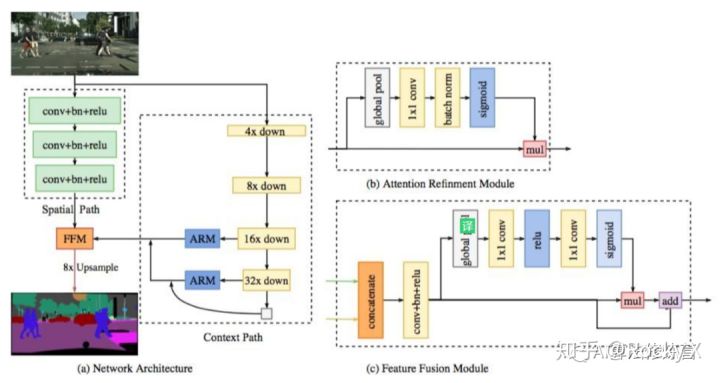
结构解析:


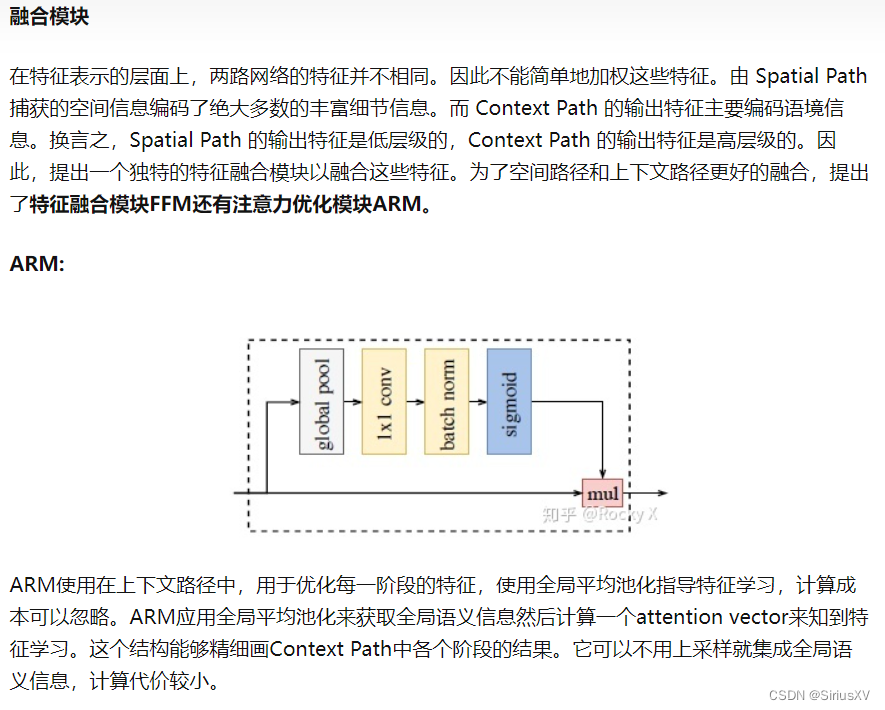
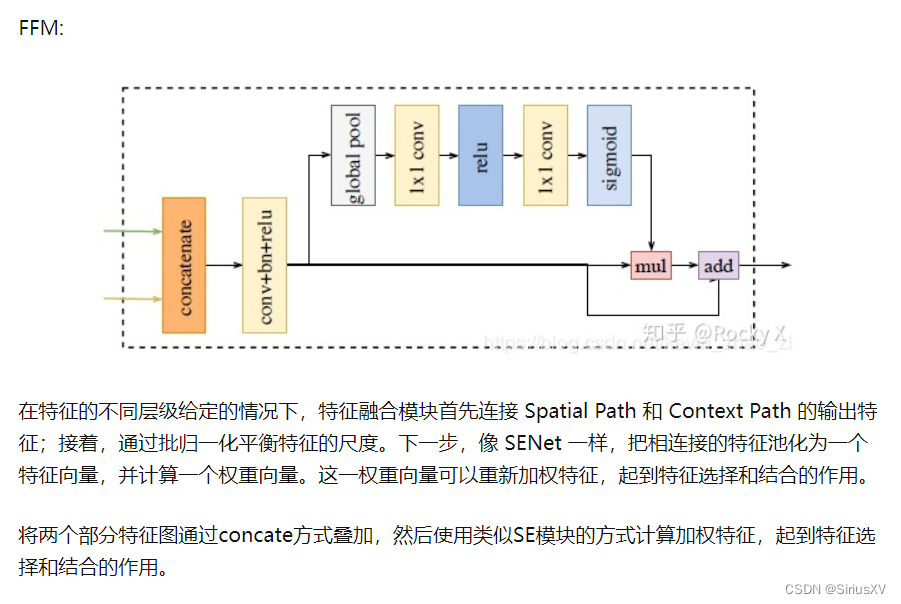
特征叠加方式的区别(add与concate)

损失函数:
通过辅助损失函数监督模型的训练,通过主损失函数监督整个 BiSeNet 的输出。另外,还通过添加两个特殊的辅助损失函数监督 Context Path 的输出,就像多层监督一样。上述所有损失函数都是 Softmax。最后借助参数 α 以平衡主损失函数与辅助损失函数的权重。
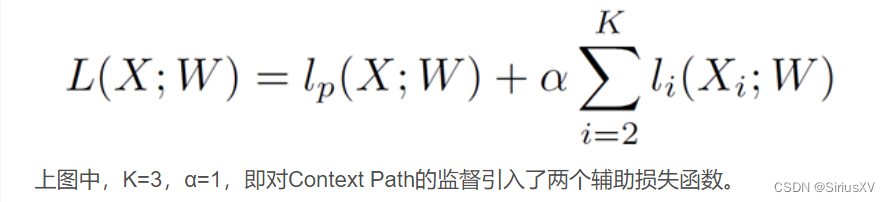
文章出处登录后可见!