自编码器
自动编码器是一种无监督的深度学习算法,它学习输入数据的编码表示,然后重新构造与输出相同的输入。它由编码器和解码器两个网络组成。编码器将高维输入压缩成低维潜在(也称为潜在代码或编码空间) ,以从中提取最相关的信息,而解码器则解压缩编码数据并重新创建原始输入。
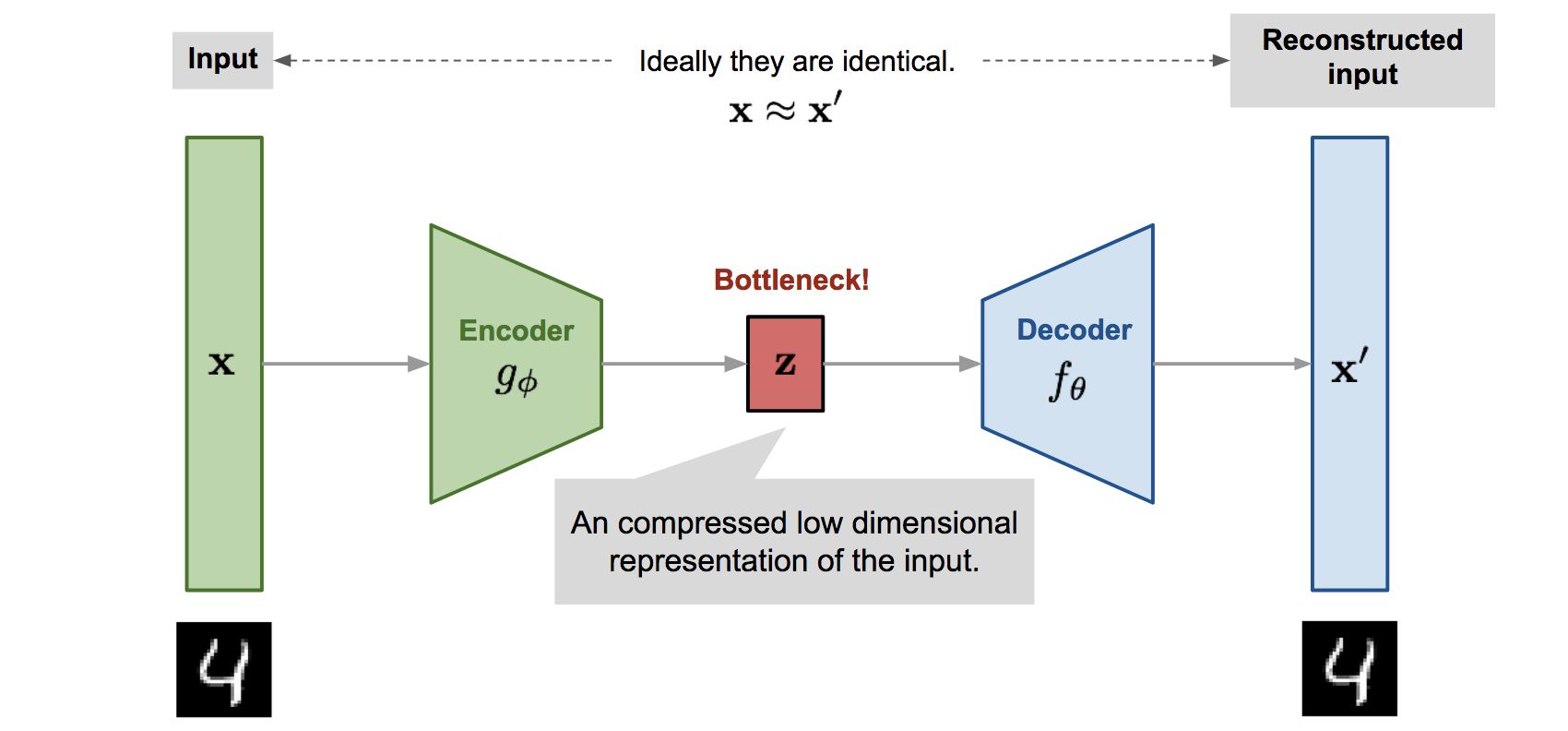
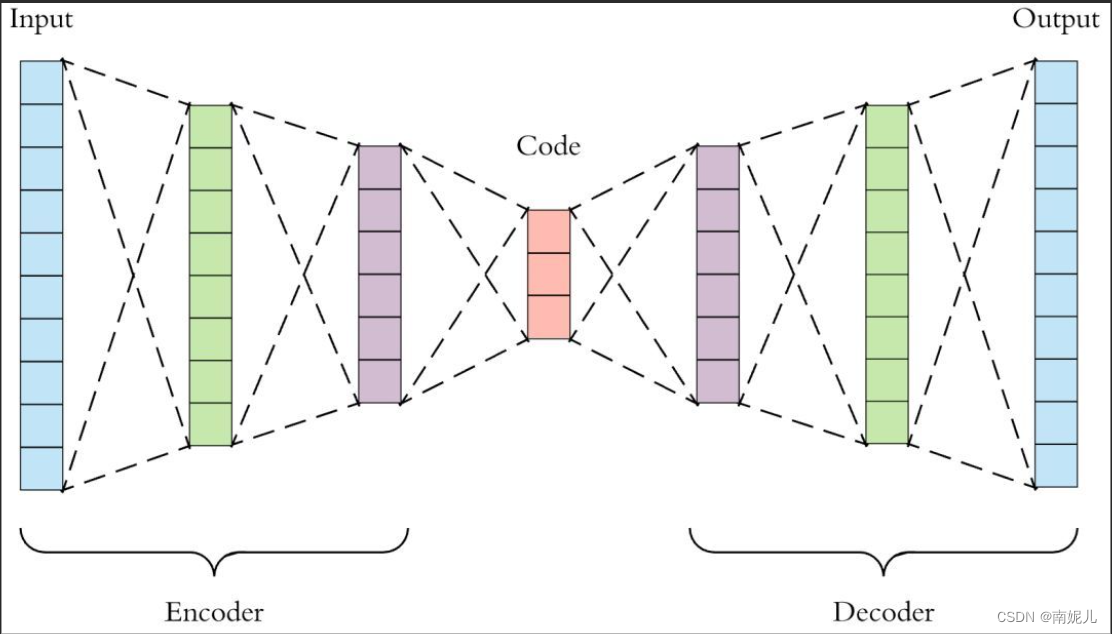
自编码器的输入和输出应该尽可能的相似。
通过输入含有噪声的图像,编码器在编码的过程中会存在信息丢失,将输入和输出最相似的特征保留下来,通过解码器得到最后的输出。在这个转换的过程中实现了图像的去噪。
自编码器主要的用途其实是用于降维,将高维的数据编码为一组向量,解码器通过解码得到输出。
数据集导入可视化
import torchvision
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
import numpy as np
import random
import PIL.Image as Image
import torchvision.transforms as transforms
class AddPepperNoise(object):
"""增加椒盐噪声
Args:
snr (float): Signal Noise Rate
p (float): 概率值,依概率执行该操作
"""
def __init__(self, snr, p=0.9):
assert isinstance(snr, float) and (isinstance(p, float))
self.snr = snr
self.p = p
def __call__(self, img):
"""
Args:
img (PIL Image): PIL Image
Returns:
PIL Image: PIL image.
"""
if random.uniform(0, 1) < self.p:
img_ = np.array(img).copy()
h, w = img_.shape
signal_pct = self.snr
noise_pct = (1 - self.snr)
mask = np.random.choice((0, 1, 2), size=(h, w), p=[signal_pct, noise_pct/2., noise_pct/2.])
img_[mask == 1] = 255 # 盐噪声
img_[mask == 2] = 0 # 椒噪声
return Image.fromarray(img_.astype('uint8'))
else:
return img
class Gaussian_noise(object):
"""增加高斯噪声
此函数用将产生的高斯噪声加到图片上
传入:
img : 原图
mean : 均值
sigma : 标准差
返回:
gaussian_out : 噪声处理后的图片
"""
def __init__(self, mean, sigma):
self.mean = mean
self.sigma = sigma
def __call__(self, img):
"""
Args:
img (PIL Image): PIL Image
Returns:
PIL Image: PIL image.
"""
# 将图片灰度标准化
img_ = np.array(img).copy()
img_ = img_ / 255.0
# 产生高斯 noise
noise = np.random.normal(self.mean, self.sigma, img_.shape)
# 将噪声和图片叠加
gaussian_out = img_ + noise
# 将超过 1 的置 1,低于 0 的置 0
gaussian_out = np.clip(gaussian_out, 0, 1)
# 将图片灰度范围的恢复为 0-255
gaussian_out = np.uint8(gaussian_out*255)
# 将噪声范围搞为 0-255
# noise = np.uint8(noise*255)
return Image.fromarray(gaussian_out)
train_datasets = torchvision.datasets.MNIST('./', train=True, download=True)
test_datasets = torchvision.datasets.MNIST('./', train=False, download=True)
print('训练集的数量', len(train_datasets))
print('测试集的数量', len(test_datasets))
train_loader = DataLoader(train_datasets, batch_size=100, shuffle=True)
test_loader = DataLoader(test_datasets, batch_size=1, shuffle=False)
transform=transforms.Compose([
transforms.ToPILImage(),
Gaussian_noise(0,0.1),
AddPepperNoise(0.9)
# transforms.ToTensor()
])
print('训练集可视化')
fig = plt.figure()
for i in range(12):
plt.subplot(3, 4, i + 1)
img = train_datasets.train_data[i]
label = train_datasets.train_labels[i]
# noise = np.random.normal(0.1, 0.1, img.shape)
# img=transform(img)
plt.imshow(img, cmap='gray')
plt.title(label)
plt.xticks([])
plt.yticks([])
plt.show()
噪声图像
 原始图像
原始图像

模型的搭建
import torch
from torch import nn
class AE(nn.Module):
def __init__(self):
super(AE, self).__init__()
# [b, 784] => [b, 20]
self.encoder = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 64),
nn.ReLU(),
nn.Linear(64, 20),
nn.ReLU()
)
# [b, 20] => [b, 784]
self.decoder = nn.Sequential(
nn.Linear(20, 64),
nn.ReLU(),
nn.Linear(64, 256),
nn.ReLU(),
nn.Linear(256, 784),
nn.Sigmoid()
)
def forward(self, x):
"""
:param x: [b, 1, 28, 28]
:return:
"""
batchsz = x.size(0)
# flatten(打平)
x = x.view(batchsz, 784)
# encoder
x = self.encoder(x)
# decoder
x = self.decoder(x)
# reshape
x = x.view(batchsz, 1, 28, 28)
return x
if __name__=='__main__':
model=AE()
input=torch.randn(1,28,28)
input=input.view(1,-1)
print('输入的维度',input.shape)
encoder_out=model.encoder(input)
print('编码器的输出',encoder_out.shape)
out=model.decoder(encoder_out)
print('解码器的输出',out.shape)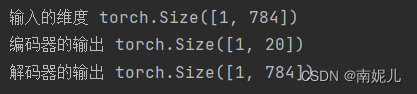
模型的训练
导入训练集训练的时候一定要将使用transforms将所有图像转换为tensor格式,这里的方法不同于tensorflow导入MNIST方法,如果不加transforms则图像的格式为列表类型,下面在训练的时候会报错。

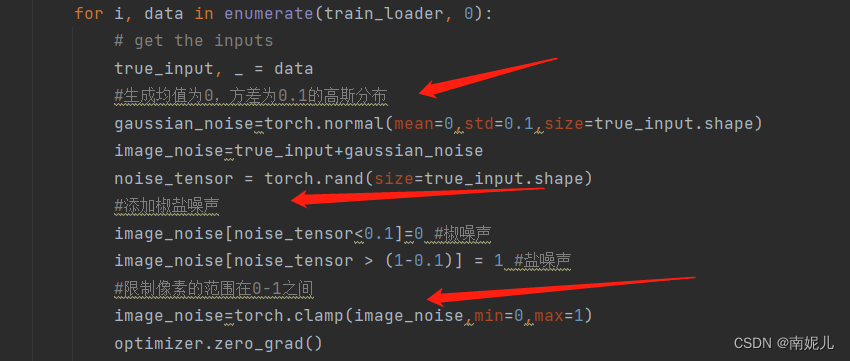
在训练过程中添加噪声。分别添加了高斯噪声和椒盐噪声
import torchvision
from torch.utils.data import DataLoader
import numpy as np
import random,os
import PIL.Image as Image
import torchvision.transforms as transforms
from torch import nn,optim
import torch
from models import AE
from tqdm import tqdm
train_datasets = torchvision.datasets.MNIST('./', train=True, download=True,transform=transforms.ToTensor())
test_datasets = torchvision.datasets.MNIST('./', train=False, download=True,transform=transforms.ToTensor())
print('训练集的数量', len(train_datasets))
print('测试集的数量', len(test_datasets))
train_loader = DataLoader(train_datasets, batch_size=100, shuffle=True)
test_loader = DataLoader(test_datasets, batch_size=1, shuffle=False)
#模型,优化器,损失函数
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model=AE().to(device)
criteon = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
##导入预训练模型
if os.path.exists('./model.pth') :
# 如果存在已保存的权重,则加载
checkpoint = torch.load('model.pth',map_location=lambda storage,loc:storage)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
initepoch = checkpoint['epoch']
loss = checkpoint['loss']
else:
initepoch=0
#开始训练
for epoch in range(initepoch, 50):
with tqdm(total=(len(train_datasets)-len(train_datasets)), ncols=80) as t:
t.set_description('epoch: {}/{}'.format(epoch, 50))
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
# get the inputs
true_input, _ = data
#生成均值为0,方差为0.1的高斯分布
gaussian_noise=torch.normal(mean=0,std=0.1,size=true_input.shape)
image_noise=true_input+gaussian_noise
noise_tensor = torch.rand(size=true_input.shape)
#添加椒盐噪声
image_noise[noise_tensor<0.1]=0 #椒噪声
image_noise[noise_tensor > (1-0.1)] = 1 #盐噪声
#限制像素的范围在0-1之间
image_noise=torch.clamp(image_noise,min=0,max=1)
optimizer.zero_grad()
outputs = model(image_noise)
loss = criteon(outputs, true_input)
loss.backward()
optimizer.step()
running_loss += loss.item()
t.set_postfix(trainloss='{:.6f}'.format(running_loss/len(train_loader)))
t.update(len(true_input))
torch.save({'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': running_loss/len(train_loader)
}, 'model.pth')
模型的测试

在导入模型的时候经常发生上面的错误。模型在导入参数的时候不需要赋值操作。如果保存的方法是torch.load(model,'model.pth'),也就是直接保存模型的所有(包括模型的结构),在导入模型参数的时候可以使用model=torch.load('./model.pth')
import numpy as np
import torchvision
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
import torch
import torchvision.transforms as transforms
from models import AE
from data import AddPepperNoise,Gaussian_noise
test_datasets = torchvision.datasets.MNIST('./', train=False, download=True)
print('测试集的数量', len(test_datasets))
test_loader = DataLoader(test_datasets, batch_size=1, shuffle=False)
transform=transforms.Compose([
transforms.ToPILImage(),
Gaussian_noise(0,0.2),
AddPepperNoise(0.9),
transforms.ToTensor()
])
model=AE()
hh=torch.load('./model.pth',map_location=lambda storage,loc:storage)
model.load_state_dict(hh['model_state_dict'])
#错误写法
# model=model.load_state_dict(hh['model_state_dict'])
fig = plt.figure()
for i in range(12):
plt.subplot(3, 4, i + 1)
img = test_datasets.train_data[i]
label = test_datasets.test_labels[i]
img_noise=transform(img)
out=model(img_noise)
out=out.squeeze()
out=transforms.ToPILImage()(out)
#原始图像,噪声图像,去噪图像
plt.imshow(np.hstack((np.array(img),np.array(transforms.ToPILImage()(img_noise)),np.array(out))), cmap='gray')
plt.title(label)
plt.xticks([])
plt.yticks([])
plt.show()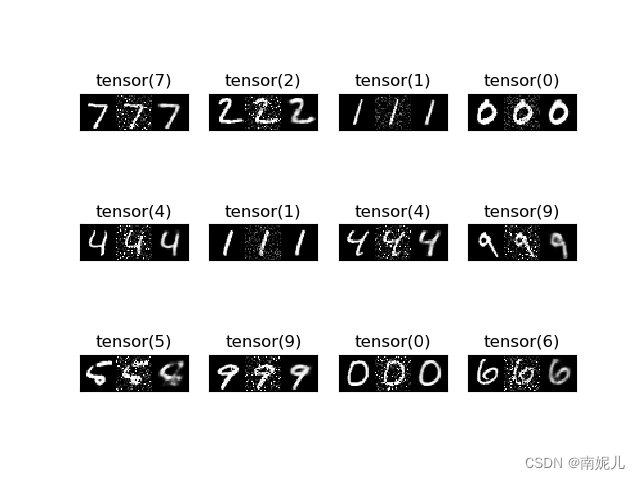
生成随机数看看解码器能解码出什么
生成标准正太分布
import matplotlib.pyplot as plt
import torch
import torchvision.transforms as transforms
from models import AE
model=AE()
model.load_state_dict(torch.load('./model.pth',map_location=lambda storage,loc:storage)['model_state_dict'])
fig = plt.figure()
for i in range(12):
plt.subplot(3, 4, i + 1)
input=torch.randn(1,20)
out=model.decoder(input)
out=out.view(28,28)
out=transforms.ToPILImage()(out)
plt.imshow(out, cmap='gray')
plt.xticks([])
plt.yticks([])
plt.show()
生成0-1之间的均匀分布
import matplotlib.pyplot as plt
import torch
import torchvision.transforms as transforms
from models import AE
model=AE()
model.load_state_dict(torch.load('./model.pth',map_location=lambda storage,loc:storage)['model_state_dict'])
fig = plt.figure()
for i in range(12):
plt.subplot(3, 4, i + 1)
input=torch.rand(1,20)
out=model.decoder(input)
out=out.view(28,28)
out=transforms.ToPILImage()(out)
plt.imshow(out, cmap='gray')
plt.xticks([])
plt.yticks([])
plt.show()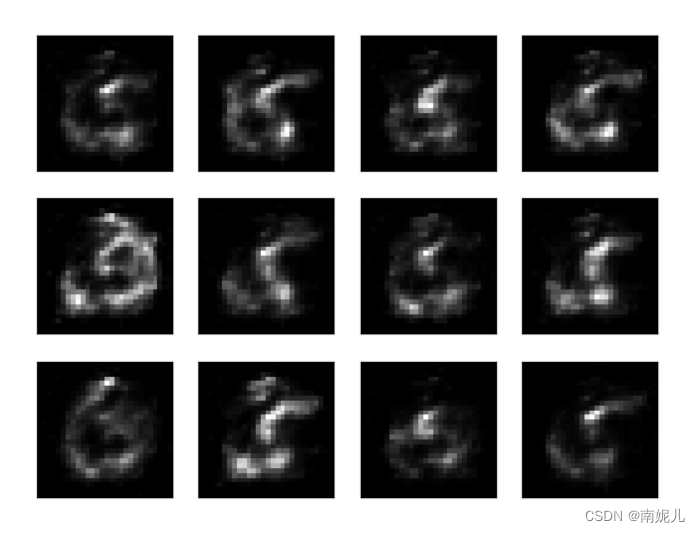
可以看到随机生成的数据用解码器解码得到的数据都很乱。接下来,看看编码器编码后的数据服从什么分布。
看看编码器编码的输出服从什么分布
import numpy as np
import torchvision
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
import torch
import torchvision.transforms as transforms
from models import AE
from data import AddPepperNoise,Gaussian_noise
test_datasets = torchvision.datasets.MNIST('./', train=False, download=True)
print('测试集的数量', len(test_datasets))
test_loader = DataLoader(test_datasets, batch_size=1, shuffle=False)
transform=transforms.Compose([
transforms.ToPILImage(),
Gaussian_noise(0,0.2),
AddPepperNoise(0.9),
transforms.ToTensor()
])
model=AE()
hh=torch.load('./model.pth',map_location=lambda storage,loc:storage)
model.load_state_dict(hh['model_state_dict'])
#错误写法
# model=model.load_state_dict(hh['model_state_dict'])
fig = plt.figure()
for i in range(1):
plt.subplot(1, 1, i + 1)
img = test_datasets.test_data[i]
label = test_datasets.test_labels[i]
img_noise=transform(img)
img_noise=img_noise.view(1,-1)
out=model.encoder(img_noise)
print('encoder的输出',out)
#正太分布检验
import scipy.stats as stats
print(stats.shapiro(out.detach().numpy()))
plt.imshow(img, cmap='gray')
plt.title(label)
plt.xticks([])
plt.yticks([])
plt.show()
print('均值',torch.mean(out))
print('方差',torch.var(out))
 可以看到一张图片7是服从均值为2.5,方差为8.55的正太分布的。
可以看到一张图片7是服从均值为2.5,方差为8.55的正太分布的。
然后生成一些类似的分布看看效果。
import matplotlib.pyplot as plt
import torch
import torchvision.transforms as transforms
from models import AE
model=AE()
model.load_state_dict(torch.load('./model.pth',map_location=lambda storage,loc:storage)['model_state_dict'])
fig = plt.figure()
for i in range(12):
plt.subplot(3, 4, i + 1)
input=torch.normal(mean=2.5928,std=8.5510,size=(1,20))
out=model.decoder(input)
out=out.view(28,28)
out=transforms.ToPILImage()(out)
plt.imshow(out, cmap='gray')
plt.xticks([])
plt.yticks([])
plt.show()
其实效果挺差的,可能是因为一张图片的分布并不能代表所有吧。
文章出处登录后可见!
已经登录?立即刷新