关于虚拟数字人的起源最早可以追溯到上个世纪八十年代的日本经典动画片《超时空要塞》的女主角林明美。作为虚拟偶像的开端,动画公司以她的虚拟形象发行唱片,虚拟人第一次进入了现实世界。
2000年-2016年,虚拟数字人还只是停留在研究阶段。2016年以来,深度学习和元宇宙的出现,使得虚拟偶像一夜火遍全世界。
虚拟数字人根据驱动方式的不同可分为AI智能驱动型和真人驱动型(动作捕捉技术)。在真人驱动型虚拟数字人中,真人也被称为“中之人”,配合动作捕捉设备,让虚拟数字人能够与观众进行实时交互。而AI智能驱动型虚拟人,则是通过智能系统自动读取并解析识别外界输入信息,根据解析结果决策输出文本,驱动人物模型生成相应的语音与动作与用户交互。由于虚拟数字人的口型和微表情等微动作较多,真人拍摄耗资巨大,AI语音口型驱动成为主流。
AI语音驱动虚拟数字人微表情
AI语音驱动又称为虚拟形象语音动画合成技术(Voice-to-Animation),用户通过输入文本或语音,以一定规则或深度学习算法,生成对应的3D虚拟形象的人脸表情系数,完成口型和面部表情的精准驱动。开发者可以快速构建丰富的虚拟形象智能驱动应用,如虚拟主持人、虚拟客服、虚拟教师等。根据输入内容的不同(文本/语音),可以分为三种驱动方法:
语音驱动
语音作为驱动源头。将语音输入到深度模型,预测嘴型和面部微表情系数。该方法不受限于不同人、国家,但是受到语音特性(音色、强度、噪声等)影响较大,较难提升模型的泛化能力。
音素驱动
文本作为驱动源头。将文本时间序列转换成音素时间序列,并输入到深度模型,预测嘴型和面部微表情系数。该此方法与语音无关,只与文本内容相关,不受语音特性变换影响。但是模型受限于不同国家的文本语言(中英等);同一文本内容、不同类型的合成声音,最后合成的口型及面部表情相似度高,缺乏风格和特性。
语音和音素多模融合驱动
语音和音素同时作为驱动源头。该方法融合语音和文本两个模态的信息,驱动系数更准确,效果更好,但模型更复杂。
AI语音驱动虚拟数字人全身
近期,百度推出了语音驱动虚拟数字人全身动作的算法框架Speech2Vedio。是一种从语音音频输入合成虚拟人全身运动(包括头、口、臂等)视频的任务。根据其算法框架,预计产生的视频在视觉上较为自然,且与给定的语音一致。
该论文作者将3D骨骼知识和模型学习的个性化语音手势字典,嵌入到整个模型的学习和测试中。通过3D人体骨骼知识限制生成的动作幅度,限定符合正常人类肢体的伸展范围,通过语音驱动算法合成符合语音场景的动作,形成协调一致,口手合一的虚拟数字人形象。其算法流程如下:
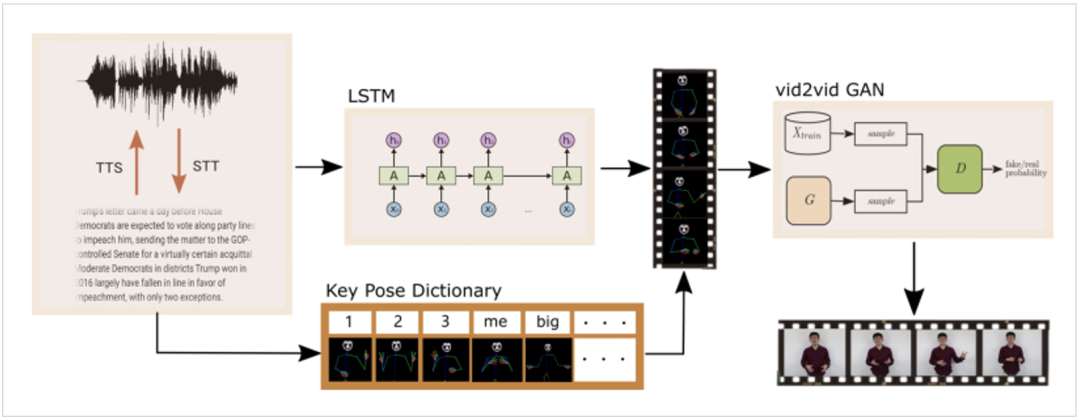
出自Miao Liao. et.al《Speech2Video Synthesis with 3D Skeleton Regularization and Expressive Body Poses》
该系统的输入是音频或文本,用于训练LSTM深度模型。使用文本到语音(TTS)和语音到文本(STT)技术实现音频和文本互换。LSTM的输出是将人体、面部和手部的3D联合模型参数化,形成一系列人体姿态,再通过GAN(生成对抗神经网络)合成最终的虚拟人形象。
AI语音驱动虚拟数字人作为虚拟人落地的核心技术,不仅大幅节省了制作成本,同时精细化的培养了虚拟数字人口手合一的协调性。
AI语音驱动技术的重要底座
自2021年以来,相关部门纷纷出台政策大力支持人工智能、区块链、大数据等产业的发展,而虚拟数字人产业则是这些产业的重要组成部分。根据量子位发布的《虚拟数字人深度产业报告》预测,到2030年,我国虚拟数字人整体市场规模将达到2700亿元。
而所有的虚拟数字人其背后的算法和模型都需要高质量的数据进行大量训练、测试、调参才能达到最终的最优效果。数据作为虚拟数字人的“基础设施”,其重要性不言而喻。

Magic Data 作为全球领先的AI数据解决方案提供商,拥有海量经由专业录音棚录制的高质量数据集。Magic Data TTS数据集涵盖天津话、东北话、四川话、上海话、广西话、长沙话众多方言。同时,拥有英语、葡萄牙语、韩语等多语种TTS数据。并能够匹配男声、女声、童声、二次元、甚至Rap说唱等各类需求。让虚拟数字人的互动拥有更多丰富的可能性,助力企业实现业务增长。
文章出处登录后可见!