0、ClearML介绍
ClearML 是一个开源平台(之前叫TRAINS),可为全球数千个数据科学团队自动化并简化机器学习解决方案的开发和管理。它被设计为端到端的MLOps套件,允许您专注于开发ML代码和自动化,而ClearML确保您的工作可重复和可扩展。
- 仅用 2 行代码跟踪和上传指标和模型
- 创建一个机器人,每当模型的准确性提高时,该机器人就会向你发送 Slack 消息
- 通过 3 次鼠标点击重现实验
简单来讲,比如你进行深度学习的训练,会涉及到输入的超参数管理、控制台输出保存用于复现、模型文件存档、环境信息等。比如有时候训练好的项目还没来得及记录分析软件或系统问题而丢失,如果要保存就要把以上信息都保存为本地文件,而分析时又要从众多实验结果小心处理,令人抓狂。
而ClearML就是一款管理软件,记录实验后,可以在网页登录自己的账户查看,接下来直接展示一下常用功能的效果:
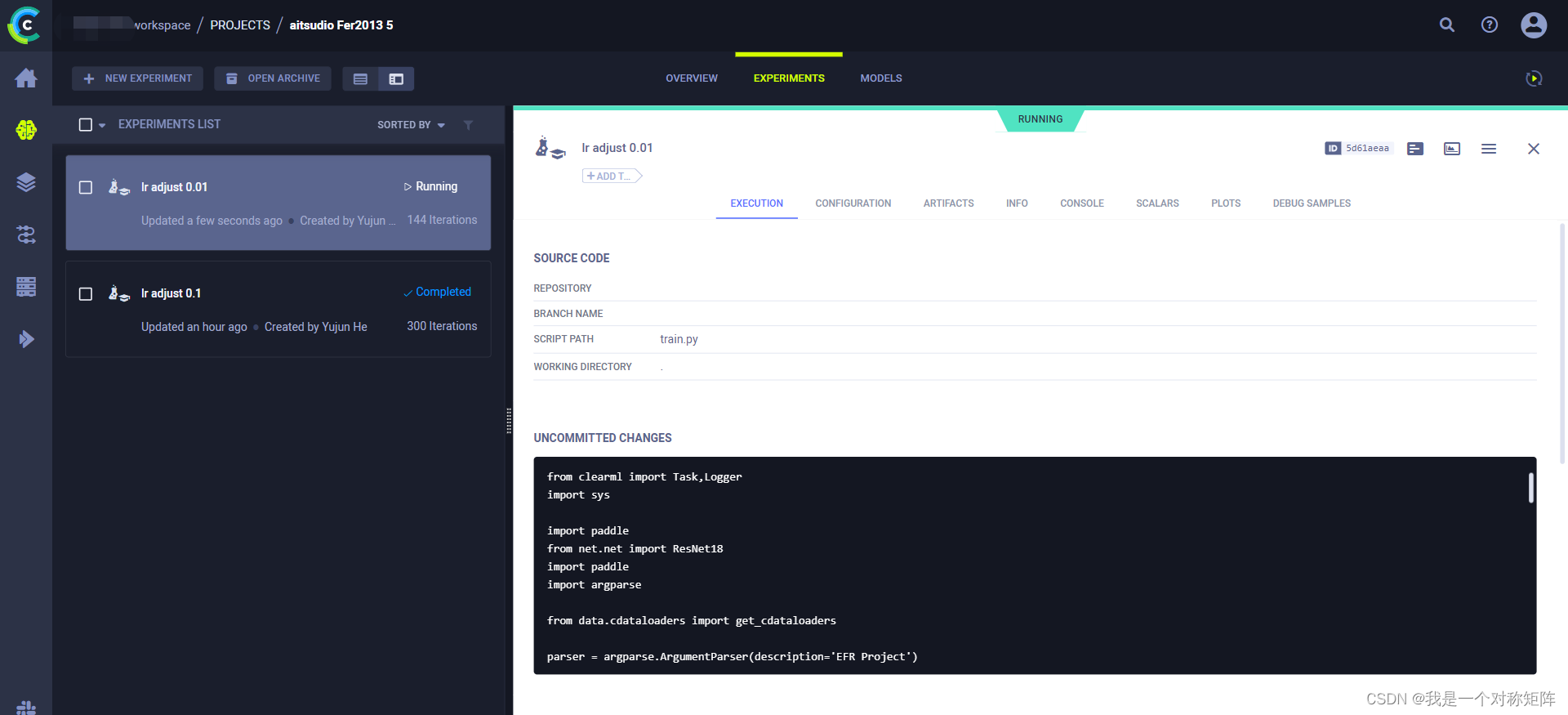
实验管理分了级,如下图所示,首先是项目,项目下有多个实验(项目下也可以是项目),这都是自定义的,比如该段时间你做这个实验,则可以新建一个项目,该改实验的所有不同实验都记录在该项目下。
如下图,该项目(图二)有两个实验,是除了学习率不同的两个实验

我们来查看"lr adjust 0.1"这个实验的详情,每个实验详细记录了信息,有8个页卡,我们展示几个页卡效果,(更多详情见文档)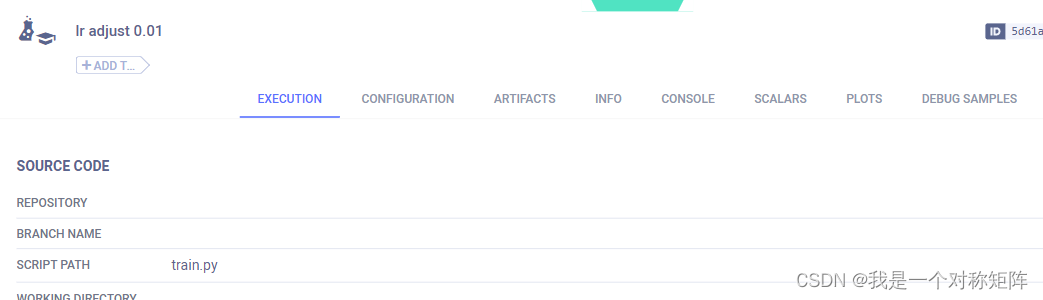
EXECUTION:该页卡记录代码(仅运行代码,其他关联代码能够记录我也暂不知道)、安装的相关库、Docker映像、项目输出目标以及日志记录级别
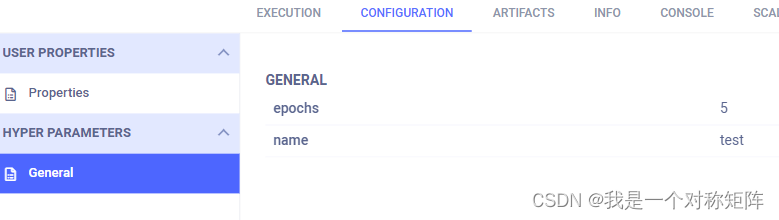
CONFIGURATION:超参数、用户属性和配置对象。每个实验都有超参数,比如命令行指定epoch、lr等,都会被记录在该页卡
ARTIFACTS:输入模型、输出模型、模型快照位置、其他工件。比如模型权重你想保存快照,也是可以的,保存后会在这里提供链接
INFO:有关实验的信息,例如:实验开始、环境信息、创建和上次更新时间和日期、创建实验的用户及其说明。部分截图如下:
CONSOLE:stdout、stderr、从库输出到控制台和 ClearML 显式报告。比如控制台的输出或者pycharm等软件运行后的显示等,都会被记录。如下图所示,这避免了因关闭控制台或软件后,输出信息丢失的问题,方便随时复盘。
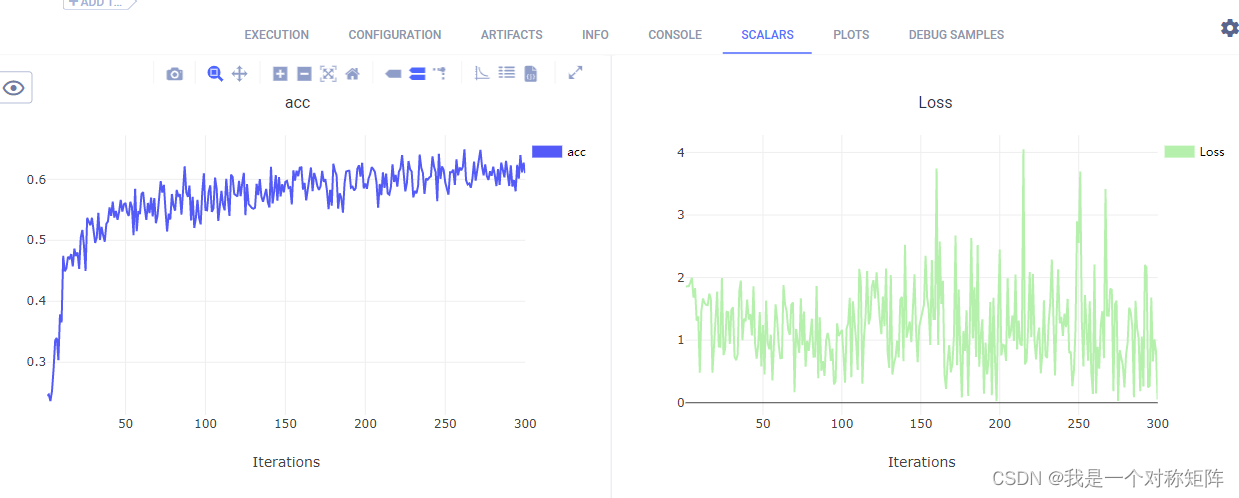
SCALARS:该页卡效果如图,也就是我们可以在训练时通过ClearML的API来记录数值,比如acc,loss等信息,然后在该页卡就会被可视化展示。
PLOTS:其他 Plot 和数据,例如:Matplotlib、Plotly 和 ClearML 显式报告。
DEBUG SAMPLES:图像、音频、视频和 HTML
当然这里只是介绍了ClearML对我有用的一些常用功能,实际上ClearML作为一款简化机器学习解决方案的开发和管理,绝不仅是“记录”,更多功能可以详见官网文档CLEAR | ML
1、一个最简单的使用例子
在你的代码加入代码:
from clearml import Task
task = Task.init(project_name="", task_name="")
一个project可以有很多个task,拥有相同project的task会被归于同一个project下。如果project_name不存在,则直接新建该project,每一次实验就是一个task。
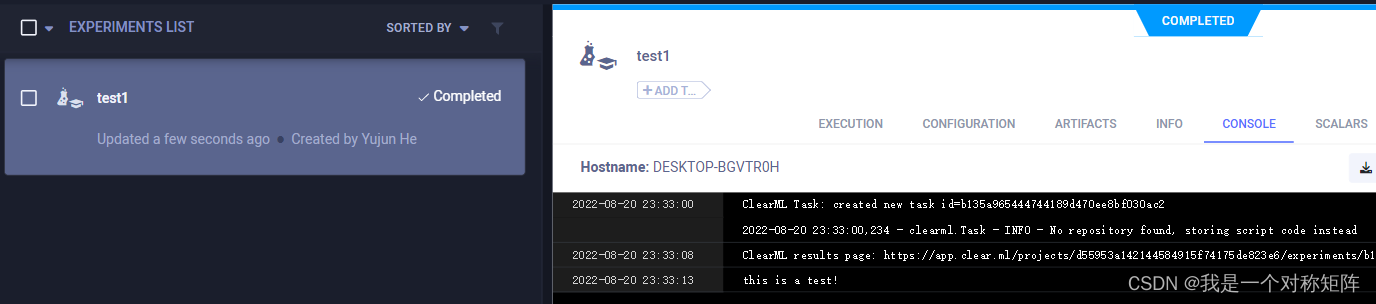
两行代码就能将你的程序的命令行输入和命令行输出记录下来,下面图一展示了代码及控制台的信息,图二是clearml平台记录的本次程序运行(当然还有环境信息,参数等都被记录了)
那么问题来了,我在本地插入两行代码,而在clearml网页端可以查询到实验信息,说明本地代码是上传了实验细节的,所以需要注册一个clearml账号和配置本地账户的步骤
2、注册账号、pip安装和配置本地账户
2.1 注册
注册账号不用多说去官网注册即可。
然后进入个人主页后,点击右上角 然后点击“Setting”,然后按下图依次点击创建许可证书(用于本地账户配置),然后会给出一串JSON格式的API,
然后点击“Setting”,然后按下图依次点击创建许可证书(用于本地账户配置),然后会给出一串JSON格式的API,复制到本地(因为只会出现一次)。
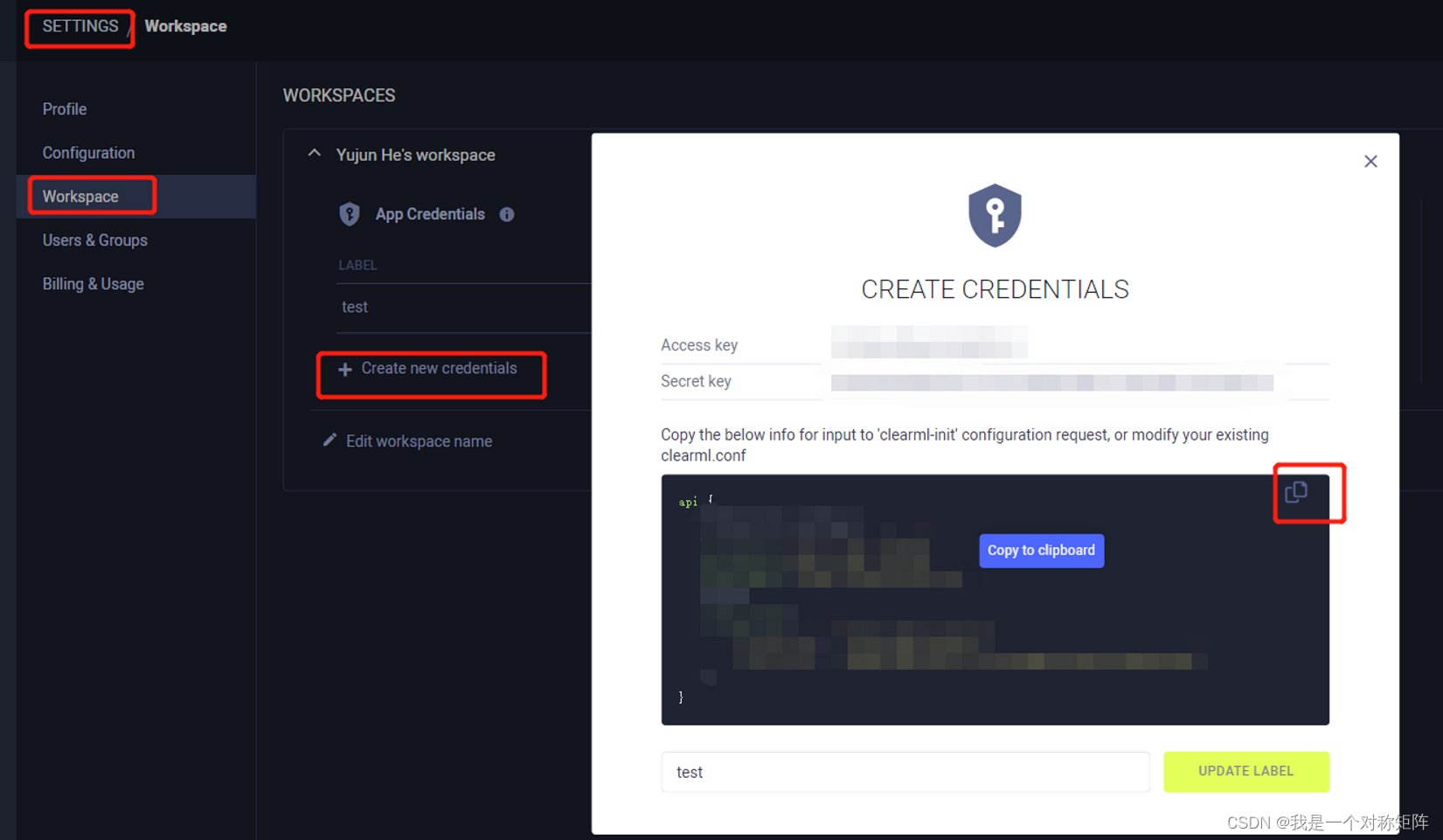
2.2 pip安装和配置本地账户
安装教程参考的官网
安装:pip install clearml
配置(安装后继续键入):clearml-init
此时会出现粘贴api的提示,按下图处理即可(我们使用官方的,所以后面三个全直接回车即可),如果最后出现successfully说明配置成功
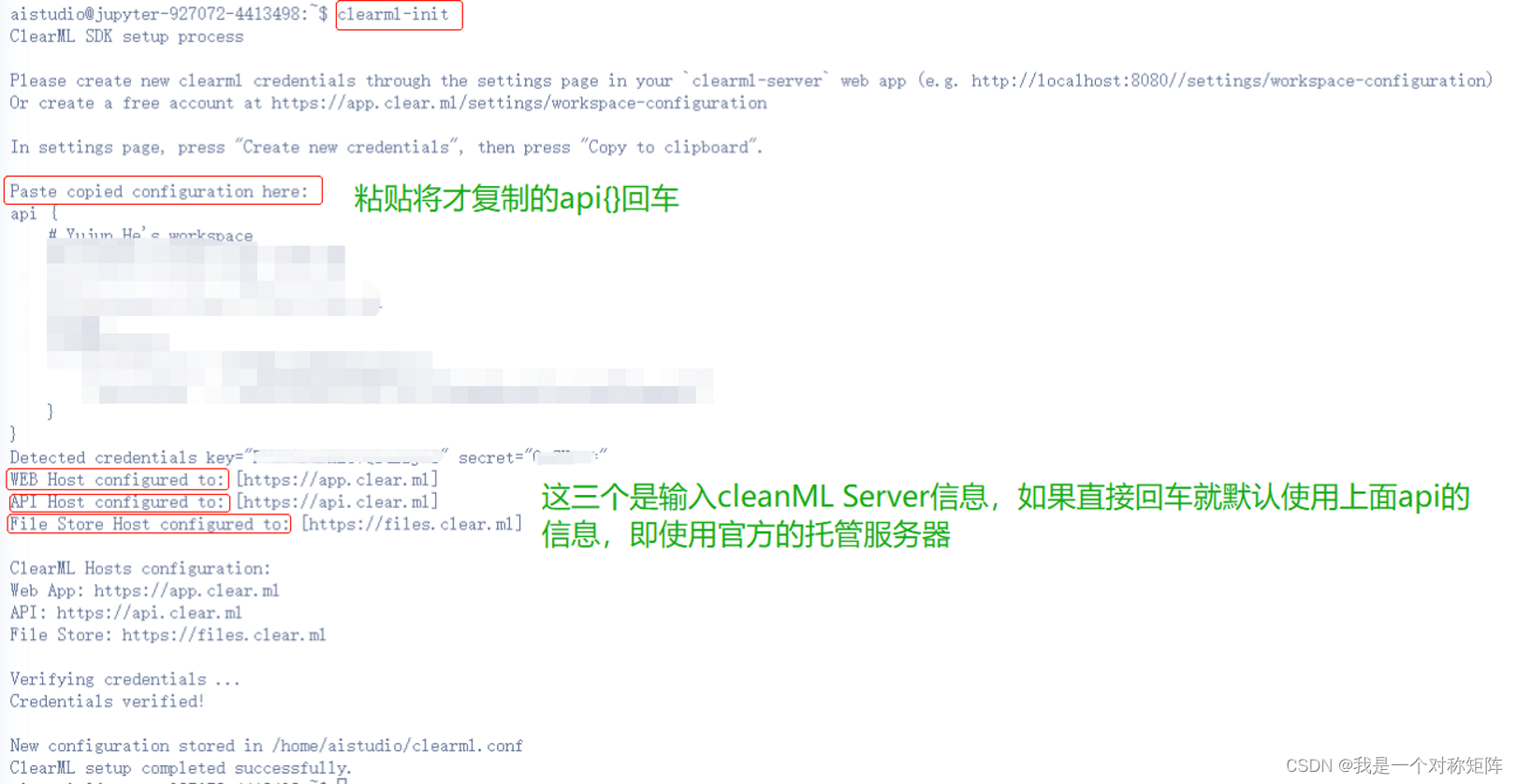
至此我们已经完成本地pip安装和账户配置,然后再次尝试一下第1节的最简单的使用例子,如果正常运行,就能在官网平台看到
你设定的project和task了
3、记录超参数
3.1 记录超参数
虽然第1节能够记录命令行传入的参数,但是比如我们使用argparse设定了很多参数但是含有使用默认值的参数,是不需要从命令行传入的,那么就不会被记录,所以我们可以使用Task.connect()来直接手动记录超参数。
Task.connect 方法直接将 Python 对象(如字典和自定义类)连接到任务。一旦对象连接到任务,ClearML会自动记录所有对象元素(例如.class成员,字典键值对)。此外,ClearML 还会跟踪这些值在代码中的变化。
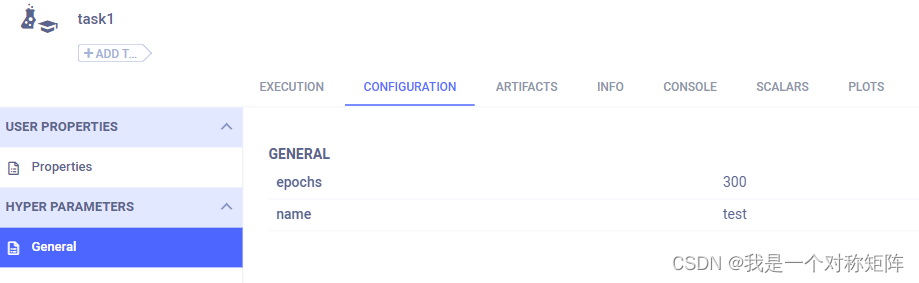
如下图所示,argparse解析后的是键值对NameSpace,可以通过connect直接记录所有超参数(name通过命令行指定,epoche使用的默认值)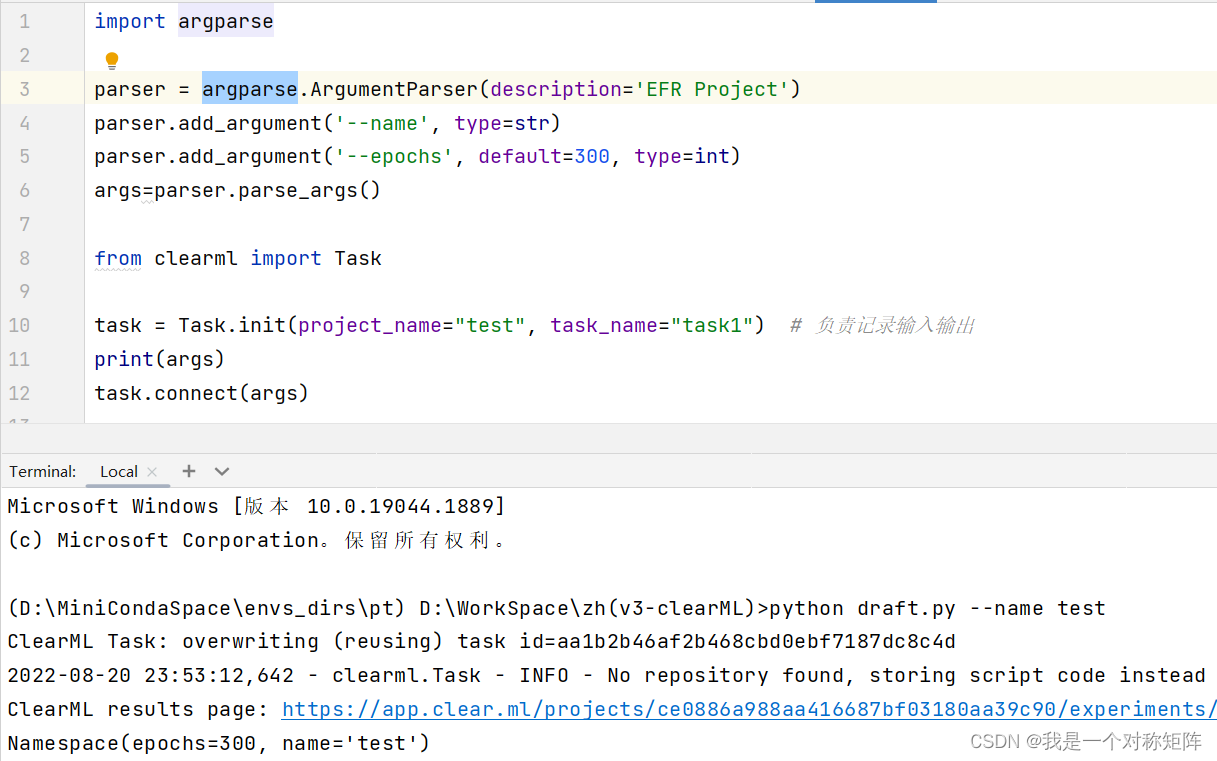
可以看到确实超参数都被记录了
3.2 追加超参数
比如3.1节,记录了args后,我想继续记录lr的值,那么可以:
task.connect(args)
hp={"lr":0.01} # 形成字典
task.connect(hp)
3.3 超参数优化模块
这个功能我还没有使用过,但是肯定对于调参是非常有用的,感兴趣的可以先自行了解
4、记录SCALARS
我们像记录训练中的acc和loss等值,形成类似TensorBoard这种折线图,就要用到SCALARS
clearml的Logger类是用来显式记录(类似手动记录,比如超参数可以手动connect来记录,更加灵活),所以SCALARS也是用Logger来记录
核心代码其实只有一句:
from cearml import Logger # 导入
logger = Logger.current_logger() # 实例化
logger.report_scalar( title='', series=', value, iteration )
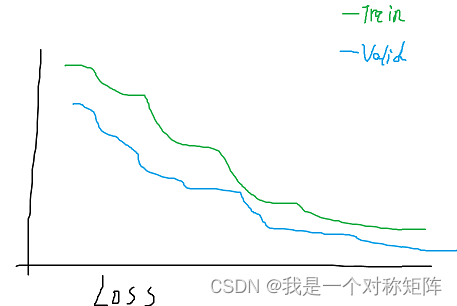
比如将Train和Valid的Loss记录,value是标量(不是tensor等类型,要转换成python的浮点数等)
logger.report_scalar(title='Loss', series='Train', value=train_loss, iteration=epoch)
logger.report_scalar(title='Loss', series='Valid', value=val_loss, iteration=epoch)
你大概会得到这样一张图
5、记录文件
Artifacts能轻松记录实验的输出包括model快照权重文件等,本质上Artifacts就是文件,通过代码中的clearml自动上传。
比如在训练时,需要从不同py脚本导入不同模型定义,然后开始训练。为了方便后面分析,除了记录实验过程外,希望能记录模型定义的代码,则可以通过Artifacts将定义模型的.py文件上传保存:
net_path="utils/models/cbam.py"
task.upload_artifact(name="net path",artifact_object=net_path)
点击下载箭头就会新开网页看到文件内容,方便复盘。
Artifacts可以记录(上传)的包括但不限于:Pandas DataFrames、Numpy object、字典、本地文件、文件夹、模型/权重等。
# 新建Pandas DataFrames并上传
# 唯一支持动态跟踪的类型,详见官方文档
df = pd.DataFrame(
{
'num_legs': [2, 4, 8, 0],
'num_wings': [2, 0, 0, 0],
'num_specimen_seen': [10, 2, 1, 8]
},
index=['falcon', 'dog', 'spider', 'fish']
)
task.upload_artifact(name='pd DataFrame', artifact_object=df)
# 新建Numpy object数据并上传
task.upload_artifact(name='Numpy Eye', artifact_object=np.eye(100, 100))
# 新建dict数据并上传
task.upload_artifact(name='dict',artifact_object={"1":20,"2":55})
# 上传本地文件
task.upload_artifact('/path/to/preprocess_data.csv', name='data')
# 上传文件夹,会被自动打包以压缩包被记录
task.upload_artifact(name='folder', artifact_object=r"utils\models\hub")
# 通配符、pillow_image等......
保存模型快照/权重:PyTorch 模型更新|ClearML
文章出处登录后可见!