前言
个人认为增量学习的定义的边界并不明显,其与其他概念例如:持续学习(Continual Learning)、终身学习(Lifelong Learning),在线学习(online learning),迁移学习(transfer learning)都有交集。
所以我个人粗糙的定义就是:模型基于旧数据学好了参数,但是如今新数据产生了,如何更新模型?
最笨,也最无懈可击的办法就是,将旧数据和新数据混在一起,然后对模型进行继续训练。
现在的一个问题是:能不能不使用旧数据或者少使用旧数据呢?这就是增量学习,也因而有了两种增量学习的方法。前者不使用旧数据,后者少使用旧数据(选一部分作为旧数据的代表)。
重点关注以及解决的问题:
- 学习新知识。
- 不遗忘旧知识。
基于正则化的增量学习
模型经过新数据后会得到损失,我们希望在损失中再加一些项,希望其可以反应旧数据在当前模型上的表现。毕竟我们不能使用旧数据,所以这些项反应得准不准确谁都说不清,只要有道理即可。
所以其思想就是:不但在学习新的知识,而且一定程度上保护旧知识。
我们以多任务学习中的多类学习为例来介绍这种类型的增量学习,多任务学习比如你可以理解为之前学的都是猫的图片,现在给了狗的图片,也要学。我们的任务就是要学习一个图片分类器。你会纳闷我为什么要举这个例子,因为这是目前的热点,大家做的也是这个。你去一搜会发现,增量学习前面通常都会加一个词“类”,即增量针对的是类增量,也就是之前是狗,现在是猫。
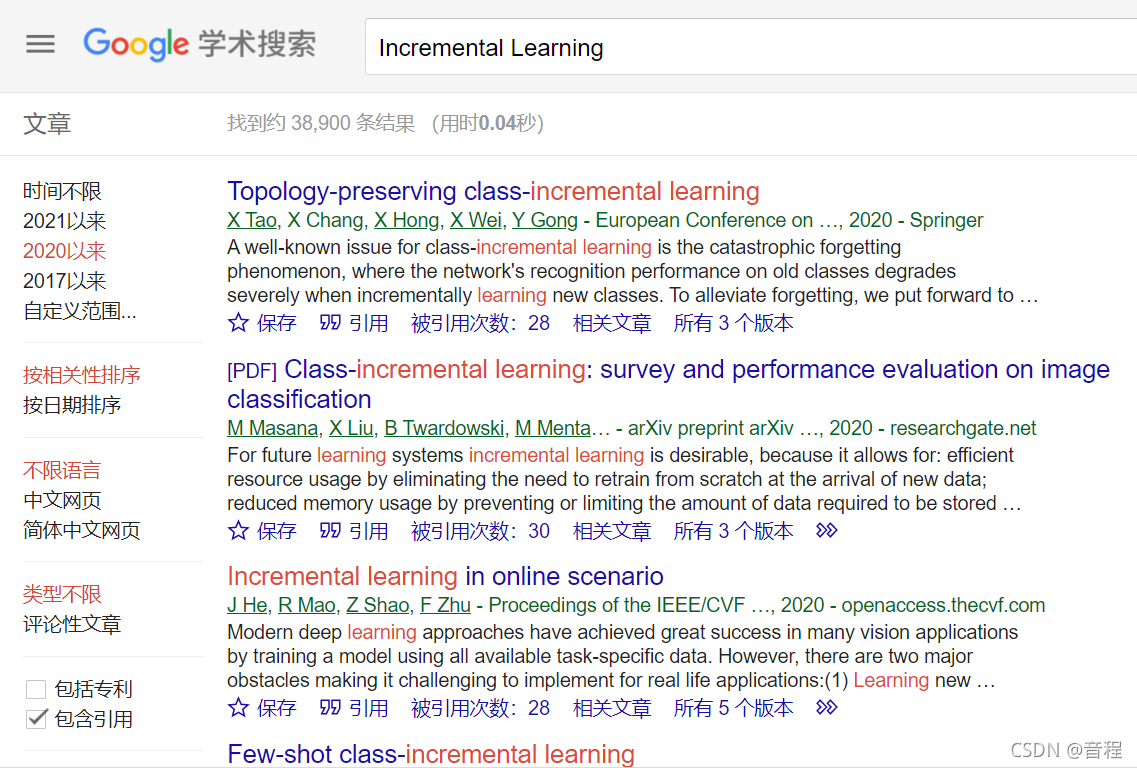
那么这种增量学习我们怎么做到呢?
我们通常会这么做,前面那些几十层是用来提取图片特征的(猫狗都共享),后面那些一两层是任务特定的(猫,狗各自都有自己的层),有点像预训练模型。
这个时候我们有两种选择:
- 根据新数据微调,那么会改变共享参数,这个时候旧数据的表现可能会变得很差。
- 特征抽取,保持共享参数不变,根据新数据只训练新任务的那几个特定层。(也不好,因为之前的共享参数未必学得适用于所有任务,所以单靠后面几层难以学习一个很好的分类器)
Learning without Forgetting (ECCV 2016)提出的LwF算法是基于深度学习的增量学习的里程碑之作。这个其实有点像微调,但是思想上比微调更加丰富。
其算法如下:
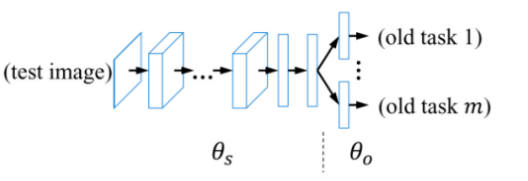

理解:相当于引入了新数据在旧模型上的结果作为旧模型的回忆,希望新数据训练完毕之后,这个
在新模型上也没有怎么变化,从而希望旧数据输入新模型得到的结果也没有怎么变化。
注意,上面的train下的参数有一个\hat你可以直接理解为在新数据训练后,参数在改变。
基于回放的增量学习
这类问题要考虑如下问题:
- 要保留旧任务的哪部分数据
- 以及如何利用旧数据与新数据一起训练模型。
iCaRL: Incremental Classifier and Representation Learning (CVPR 2017)是最经典的基于回放的增量学习模型,iCaRL假设越靠近旧数据均值的样本越有代表性。
GAN
大家都知道GAN网络可以用来在旧数据上进行训练,然后生成狗的图片,下次猫的数据来的时候,相当于让GAN生成狗的图片,然后和猫一起训练。
这个方法其实个人觉得也很局限性,因为其变相保存了旧数据,无非原来是狗图片,现在变成了生成狗图片的GAN参数。
但是,话说回来,其确实没有使用旧数据。
参考:https://blog.csdn.net/abcdefg90876/article/details/114109237。这篇更加详细,为其打call。
文章出处登录后可见!