论文题目:Tensor Fusion Network for Multimodal Sentiment Analysis
来源:EMNLP_2017
摘要
以往的多模态情感分析的工作中并没有直接考虑模态内和模态间的动态,而是执行早期融合(也称为特征级融合)或后期融合(也称为决策级融合)。
早期融合主要包括在输入层面上简单地连接多模态特征,但是这种方法不能有效地建模模态内特征。而后期融合包括独立训练单模态分类器和执行决策投票,这种方法也不能有效地建模模态间动态。而且在视频中,由于口语的易变性以及伴随的手势和和声音,容易导致的模态内的动态不稳定。
因此,为了解决这个问题,作者提出了一种新的模型Tensor Fusion Network(张量融合网络,TFN),TFN能够端到端地学习模态内和模态间的动态,采用一种新的多模态融合方法(张量融合)对模态间动态进行建模,模态内动态则通过三个模态嵌入子网络进行建模。
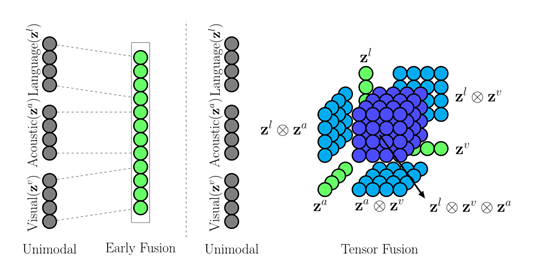
上图,左边为以前的直接concat融合,右边为作者提出的张量融合。
TFN
作者提出的TFN模型主要由以下三个部分组成:
1)模态嵌入子网络(Modality Embedding Subnetworks)以单模态特征作为输入,并输出丰富的模态嵌入。
2)张量融合层(Tensor Fusion Layer)使用模态嵌入的3-fold笛卡尔积显式地模拟单模态、双模态和三模态相互作用。
3)情感推理子网络(Sentiment Inference Subnetwork)是以张量融合层的输出为条件进行情感推理的网络。
Modality Embedding Subnetworks
模态嵌入子网络按照三个不同的模态分为Spoken Language Embedding Subnetwork、Visual Embedding Subnetwork和Acoustic Embedding Subnetwork。
Spoken Language Embedding Subnetwork
在口语中,存在许多不稳定的现象,比如“我觉得还好……嗯……让我想想……是的……不……好的,是的”。而处理口语这种不稳定性质的关键因素是,通过关注重要的词类,建立能够在存在不可靠和特殊语音特征的情况下运行的模型。对此,作者提出的解决方法是在每个单词间隔学习口语单词的丰富表达,并将其作为完全连接的深层网络的输入(如下图),通过这种方式,当模型通过时间发现话语的意义时,如果它在单词i+1中遇到不可用的信息,然后遇到任意数量的单词,则表示直到i没有被稀释或丢失。
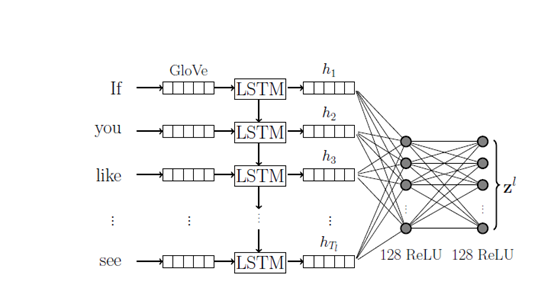
定义Spoken Language Embedding Subnetwork为(),令
![]() ,其中
,其中为话语中的单词数 ,在网络中包含128个ReLU,因此最后输出的特征向量为128维。
在上图提取语言模态特征时,首先通过GloVe将每个单词转化为300维的向量,然后通过LSTM来恢复之前被稀释或丢失的可用信息并输出,将h1、h2、h3……
串联而成的语言矩阵表示为
。然后将
用作全连接网络的输入,该网络生成语言嵌入
,其中
可用如下公式求得:
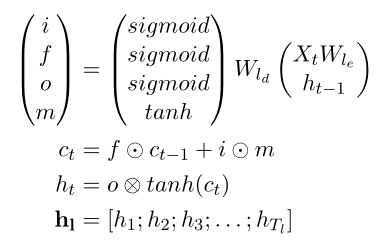
因此,最后语言子网络输出为![]() ,其中
,其中为
网络中所有权重的集合。
Visual Embedding Subnetwork
作者使用FACET模型来检测说话人的面部表情,并提取7种基本情绪(愤怒、蔑视、厌恶、恐惧、喜悦、悲伤和惊讶)和两种高级情绪(挫折和困惑)。还使用OpenFace对每帧的头部位置、头部旋转和68个面部地标位置进行了估计。
输入为视觉特征向量![]() ,另外作者使用了一个具有三个隐藏层的深度神经网络(包含32个ReLU单元和权重Wv)来提取特征。因此最后视觉子网络输出为
,另外作者使用了一个具有三个隐藏层的深度神经网络(包含32个ReLU单元和权重Wv)来提取特征。因此最后视觉子网络输出为![]()
Acoustic Embedding Subnetwork
对于每个意见音频,作者使用COVAREP声学分析框架来提取一组声学特征。
提取音频特征采用了与视觉特征一样的方法,使用一个由32个ReLU单元组成的3层网络,输入为![]() ,E为每段音频帧提取的声学特征的平均池化。
,E为每段音频帧提取的声学特征的平均池化。
音频子网络输出为![]()
Tensor Fusion Layer
作者在TFN中构建了一个张量融合层,定义为使用三次笛卡尔积的以下向量场:
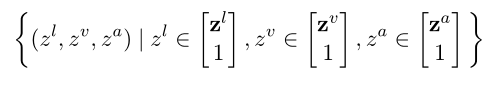
对zl,zv,za 扩充一维,既能计算模态之间的特征相关性,又保留了单个模态的特征。
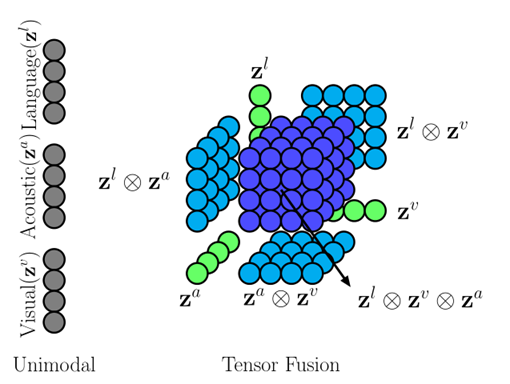
如上图所示,将三个特征向量进行融合,得到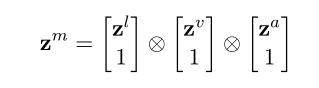
![]() ,并且分割出7个语义不同的子区域,其中,有三个在张量融合中形成单模态相互作用的模态嵌入子网络的单模态嵌入。三个在张量融合中的双模态相互作用。和一个三模态相互作用。
,并且分割出7个语义不同的子区域,其中,有三个在张量融合中形成单模态相互作用的模态嵌入子网络的单模态嵌入。三个在张量融合中的双模态相互作用。和一个三模态相互作用。
Sentiment Inference Subnetwork
在张量融合层之后,每个观点话语都可以表示为一个多模态张量 。作者使用了一个完全连接的深层神经网络,称为情绪推理子网络(),其权重
以为条件。该网络的体系结构由两层128个ReLU激活单元组成,连接到决策层。情绪推理子网络的似然函数定义如下,其中
是情绪预测:
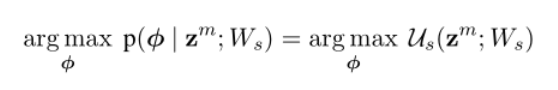
另外,作者在实验中使用了网络的三种变体形式,分别用来完成三个不同的情感分类任务。
(1)第一个网络训练用于二元情感分类,使用二元交叉熵损失的单个sigmoid输出神经元。
(2)第二个网络设计用于五类情绪分类,并使用分类交叉熵损失的softmax概率函数。
(3)第三个网络使用单个sigmoid输出,使用均方误差损失进行情绪回归。
实验及结果分析
在本文中,作者针对不同的研究问题设计了三组实验。
实验1:作者将TFN与以前最先进的多模式情感分析方法进行了比较。
实验2:作者研究了TFN子张量的重要性以及每个单独模式的影响。我们还与常用的早期融合方法进行了比较。
实验3:作者比较了TFN中的三种特定模式网络(语言、视觉和声学)与最先进的单模态方法的性能。
E1: Multimodal Sentiment Analysis
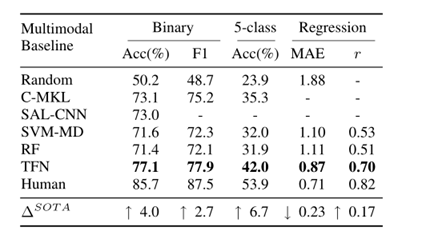
针对实验1,作者在CMU-MOSI数据集上进行实验,并且对比了C-MKL、SAL-CNN、SVM-MD和SF模型。结果显示,TFN优于先前提出的神经和非神经方法。这种差异在5级分类中特别明显。
E2: Tensor Fusion Evaluation
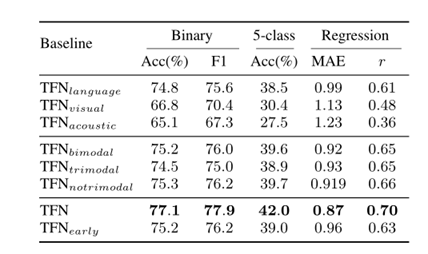
下表为作者针对实验2取得的结果,前三行结果为单模态取得的性能,TFN所取得的效果是最优的。而且全TFN模型比之单模态和双模态也有了很大的改进,证实了三模态融合的重要性以及融合时需要全张量的所有分量。
E3: Modality Embedding Subnetworks Evaluation
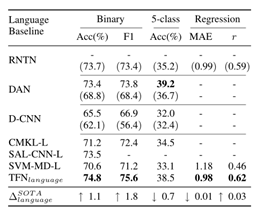
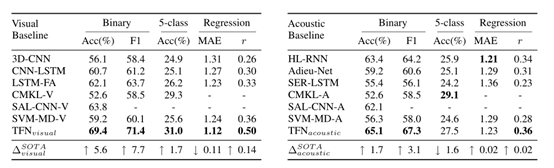
下面三个表格分别为视觉模态、音频模态和语言模态与当前几个常见模型的对比,
其中TFN的视觉模态在三组实验中取得的效果均优于其他模型。
语言模态则在5分类中取得的效果略低于DAN模型,原因可能是DAN模型的句子嵌入方法很容易被与情感或意义不相关的单词冲淡,而作者使用的卷积方法依赖于相关词的空间邻近性,但是这种空间邻进性却不总是存在与口语之中。
总结
作者在本文中介绍了一种新的用于情感分析的端到端融合方法,该方法明确表示行为之间的单模态、双模态和三模态的交互。与当前的多模态方法相比,TFN模型在公共可用的CMU-MOSI数据集上的实验产生了最先进的性能。
但是TFN通过模态之间的张量外积,来计算模态间特征的相关性,会大大增加外积出来的特征向量维度,![]() ,造成模型过大,难以训练,而且计算效率差。在权重张量W中学习的参数数量将呈指数增长。这不仅会引入大量计算,而且会使模型面临过度拟合的风险。
,造成模型过大,难以训练,而且计算效率差。在权重张量W中学习的参数数量将呈指数增长。这不仅会引入大量计算,而且会使模型面临过度拟合的风险。
在ACL2018上的一篇论文Efficient Low-rank Multimodal Fusion with Modality-Specific Factors,提出来了对TFN模型的改进,减少了模型中的参数数量,进而减轻训练难度。
文章出处登录后可见!