目录
1. 什么是距离度量
距离度量是有监督和无监督学习算法的基础,包括k近邻、支持向量机和k均值聚类等。
距离度量用于计算给定问题空间中两个对象之间的差异,即数据集中的特征。然后可以使用该距离来确定特征之间的相似性, 距离越小特征越相似。
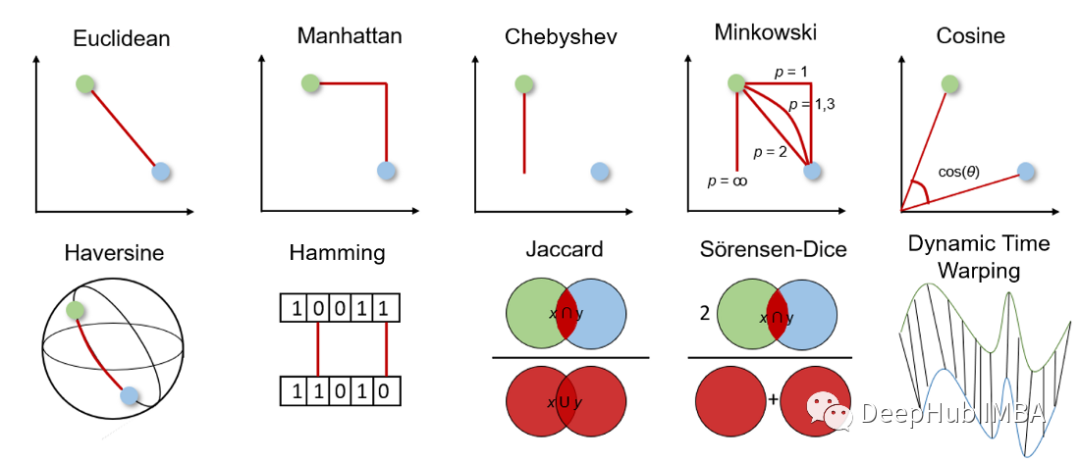
2. 距离度量分类
(1)几何距离度量
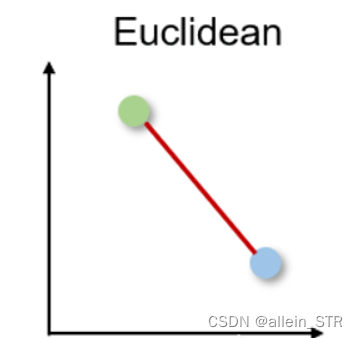
1)欧氏距离 Euclidean distance
可称为L2范数
优点:
直观,使用简单,对许多用例有良好结果,是最常用的距离度量和许多应用程序的默认距离度量。
缺点:
- 距离测量不适用于比2D或3D空间更高维度的数据。
- 如果我们不将特征规范化和/或标准化,距离可能会因为单位的不同而倾斜。
其计算方法为:
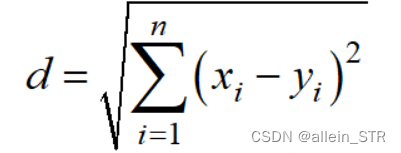
python代码:
from scipy.spatial import distance
distance.euclidean(vector_1, vector_2)2)曼哈顿距离 Manhattan distance
曼哈顿距离也被称为出租车或城市街区距离,因为两个实值向量之间的距离是根据一个人只能以直角移动计算的。
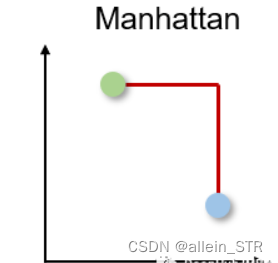
曼哈顿距离以l1范数为基础,计算公式为:
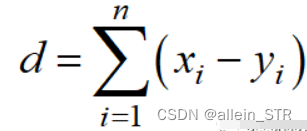
Python代码如下
from scipy.spatial import distance
distance.cityblock(vector_1, vector_2)优点:
这种距离度量通常用于离散和二元属性,这样可以获得真实的路径。
缺点:
它不如高维空间中的欧氏距离直观,它也没有显示可能的最短路径。
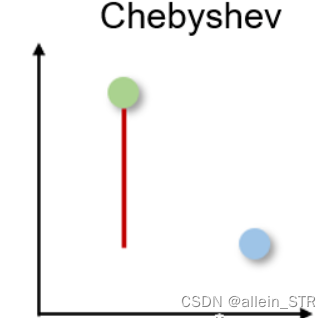
3)切比雪夫距离 Chebyshev distance
切比雪夫距离也称为棋盘距离,因为它是两个实值向量之间任意维度上的最大距离。它通常用于仓库物流中,其中最长的路径决定了从一个点到另一个点所需的时间。
切比雪夫距离由l -无穷范数计算:
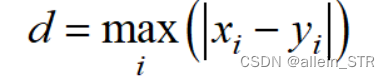
Python代码如下
from scipy.spatial import distance
distance.chebyshev(vector_1, vector_2)缺点:只有非常特定的用例,因此很少使用。
4)闵可夫斯基距离 Minkowski distance
闵可夫斯基距离是上述距离度量的广义形式。它可以用于相同的用例,同时提供高灵活性。我们可以选择 p 值来找到最合适的距离度量。
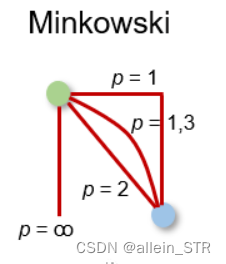
闵可夫斯基距离的计算方法为:
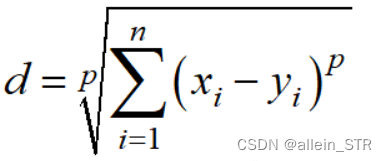
Python代码如下:
from scipy.spatial import distance
distance.minkowski(vector_1, vector_2, p)优点:
灵活性高
缺点:
在高维空间可能有问题;
对特征单位依赖;
p值的灵活性可能降低计算效率,因为找到正确的p值需要进行多次计算。
5)余弦相似度和距离 Cosine similarity
余弦相似度是方向的度量,他的大小由两个向量之间的余弦决定,并且忽略了向量的大小。余弦相似度通常用于与数据大小无关紧要的高维,例如,推荐系统或文本分析。
余弦相似度可以介于-1(相反方向)和1(相同方向)之间,计算方法为:
余弦相似度常用于范围在0到1之间的正空间中。余弦距离就是用1减去余弦相似度,位于0(相似值)和1(不同值)之间。
Python代码如下:
from scipy.spatial import distance
distance.cosine(vector_1, vector_2)优点:
通常用于与数据大小无关紧要的高维
缺点:
不考虑大小而只考虑向量的方向。因此,没有充分考虑到值的差异。
6)半正矢距离 Haversine distance
半正矢距离测量的是球面上两点之间的最短距离。因此常用于导航,其中经度和纬度和曲率对计算都有影响。
半正矢距离的计算公式如下:
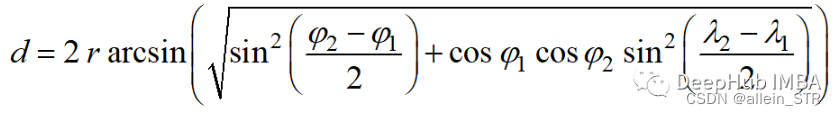
其中r为球面半径,φ和λ为经度和纬度。
Python代码如下:
from sklearn.metrics.pairwise import haversine_distances
haversine_distances([vector_1, vector_2])优点:
常用于导航
缺点:
假设是一个球体,而这种情况很少出现。
7)汉明距离
汉明距离衡量两个二进制向量或字符串之间的差异。
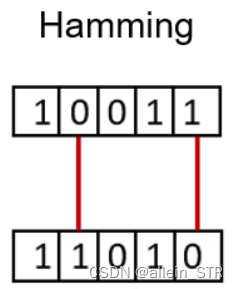
对向量按元素进行比较,并对差异的数量进行平均。如果两个向量相同,得到的距离是0之间,如果两个向量完全不同,得到的距离是1。
Python代码如下:
from scipy.spatial import distance
distance.hamming(vector_1, vector_2)缺点:
距离测量只能比较相同长度的向量,它不能给出差异的大小。所以当差异的大小很重要时,不建议使用汉明距离。
2. 统计距离测量
统计距离测量可用于假设检验、拟合优度检验、分类任务或异常值检测。
1)杰卡德指数和距离 Jaccard Index
Jaccard指数用于确定两个样本集之间的相似性。它反映了与整个数据集相比存在多少一对一匹配。Jaccard指数通常用于二进制数据比如图像识别的深度学习模型的预测与标记数据进行比较,或者根据单词的重叠来比较文档中的文本模式。
Python代码如下
from scipy.spatial import distance
distance.jaccard(vector_1, vector_2)缺点:
受到数据规模的强烈影响,即每个项目的权重与数据集的规模成反比。
2)Sorensen-Dice指数
Sörensen-Dice指数类似于Jaccard指数,它可以衡量的是样本集的相似性和多样性。Sörensen-Dice索引常用于图像分割和文本相似度分析。
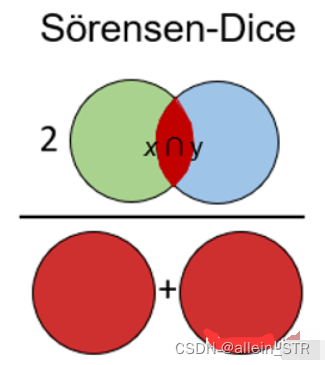
计算公式如下:
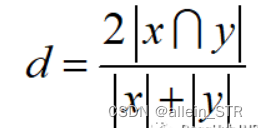
Python代码如下
from scipy.spatial import distance
distance.dice(vector_1, vector_2)优点:
该指数更直观,因为它计算重叠的百分比。
缺点:
受数据集大小的影响很大。
3)动态时间规整 Dynamic Time Warping
动态时间规整是测量两个不同长度时间序列之间距离的一种重要方法。可以用于所有时间序列数据的用例,如语音识别或异常检测。
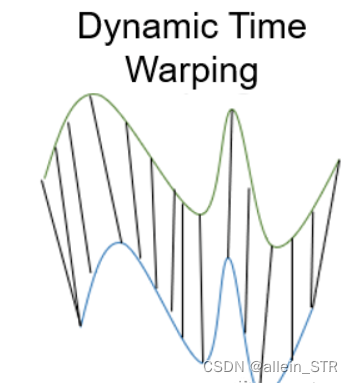
如果两个时间序列的形状相同但在时间上发生了偏移,那么尽管时间序列非常相似,但欧几里得距离会表现出很大的差异。
动态时间规整通过使用多对一或一对多映射来最小化两个时间序列之间的总距离来避免这个问题。
当搜索最佳对齐时,这会产生更直观的相似性度量。通过动态规划找到一条弯曲的路径最小化距离,该路径必须满足以下条件:
- 边界条件:弯曲路径在两个时间序列的起始点和结束点开始和结束
- 单调性条件:保持点的时间顺序,避免时间倒流
- 连续条件:路径转换限制在相邻的时间点上,避免时间跳跃
- 整经窗口条件(可选):允许的点落入给定宽度的整经窗口
- 坡度条件(可选):限制弯曲路径坡度,避免极端运动
python代码
from scipy.spatial.distance import euclidean
from fastdtw import fastdtw
distance, path = fastdtw(timeseries_1, timeseries_2, dist=euclidean)缺点:
计算工作量相对较高。
文章出处登录后可见!