一、什么是label smoothing?
标签平滑(Label smoothing),像L1、L2和dropout一样,是机器学习领域的一种正则化方法,通常用于分类问题,目的是防止模型在训练时过于自信地预测标签,改善泛化能力差的问题。
Label smoothing将hard label转变成soft label,使网络优化更加平滑。标签平滑是用于深度神经网络(DNN)的有效正则化工具,该工具通过在均匀分布和hard标签之间应用加权平均值来生成soft标签。它通常用于减少训练DNN的过拟合问题并进一步提高分类性能。
当然这里,还有多种对应的说法:
- Hard target和Soft target

- hard label 和 soft label
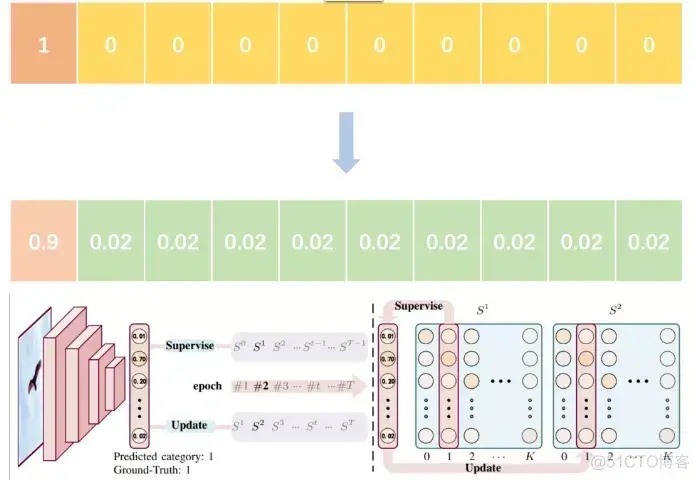
二、为什么需要label smoothing?
对于分类问题,我们通常认为训练数据中标签向量的目标类别概率应为1,非目标类别概率应为0。传统的one-hot编码的标签向量yi为,
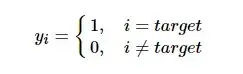
在训练网络时,最小化损失函数 ![]() ,其中 pi 由对模型倒数第二层输出的logits向量z应用Softmax函数计算得到,
,其中 pi 由对模型倒数第二层输出的logits向量z应用Softmax函数计算得到,
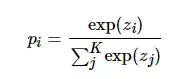
传统one-hot编码标签的网络学习过程中,鼓励模型预测为目标类别的概率趋近1,非目标类别的概率趋近0,即最终预测的logits向量(logits向量经过softmax后输出的就是预测的所有类别的概率分布)中目标类别 zi 的值会趋于无穷大,使得模型向预测正确与错误标签的logit差值无限增大的方向学习,而过大的logit差值会使模型缺乏适应性,对它的预测过于自信。在训练数据不足以覆盖所有情况下,这就会导致网络过拟合,泛化能力差,而且实际上有些标注数据不一定准确,这时候使用交叉熵损失函数作为目标函数也不一定是最优的了。
1、label smoothing的数学定义
label smoothing结合了均匀分布,用更新的标签向量 ![]() 来替换传统的ont-hot编码的 标签向量
来替换传统的ont-hot编码的 标签向量![]()
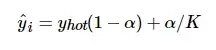
其中K为多分类的类别总个数,αα是一个较小的超参数(一般取0.1),即
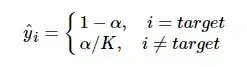
这样,标签平滑后的分布就相当于往真实分布中加入了噪声,避免模型对于正确标签过于自信,使得预测正负样本的输出值差别不那么大,从而避免过拟合,提高模型的泛化能力。
NIPS 2019上的这篇论文When Does Label Smoothing Help?用实验说明了为什么Label smoothing可以work,指出标签平滑可以让分类之间的cluster更加紧凑,增加类间距离,减少类内距离,提高泛化性,同时还能提高Model Calibration(模型对于预测值的confidences和accuracies之间aligned的程度)。但是在模型蒸馏中使用Label smoothing会导致性能下降。
2、举个栗子:
比如有一个六个类别的分类任务,CE-loss是如何计算当前某个预测概率p相对于y的损失呢:

可以看出,根据CE-loss的公式,只有y中为1的那一维度参与了loss的计算,其他的都忽略了。这样就会造成一些后果:
- 真实标签跟其他标签之间的关系被忽略了,很多有用的知识无法学到;比如:“鸟”和“飞机”本来也比较像,因此如果模型预测觉得二者更接近,那么应该给予更小的loss;
- 倾向于让模型更加“武断”,成为一个“非黑即白”的模型,导致泛化性能差;
- 面对易混淆的分类任务、有噪音(误打标)的数据集时,更容易受影响。
总之,这都是由one-hot的不合理表示造成的,因为one-hot只是对真实情况的一种简化。
面对one-hot可能带来的容易过拟合的问题,有研究提出了Label Smoothing方法:
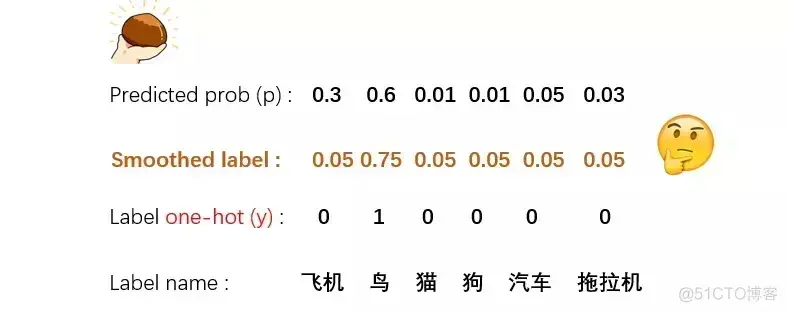
label smoothing就是把原来的one-hot表示,在每一维上都添加了一个随机噪音。这是一种简单粗暴,但又十分有效的方法,目前已经使用在很多的图像分类模型中了。
3、one-hot 和 Label Smoothing 优劣
1、one-hot 劣势:
- 可能导致过拟合。0或1的标记方式导致模型概率估计值为1,或接近于1,这样的编码方式不够soft,容易导致过拟合。为什么? 用于训练模型的training set通常是很有限的,往往不能覆盖所有的情况,特别是在训练样本比较少的情况下更为明显。
- 会造成模型对它的预测过于confident,导致模型对观测变量x的预测严重偏离真实的情况
2、Label Smoothing 优势:
- 一定程度上,可以缓解模型过于武断的问题,也有一定的抗噪能力
- 弥补了简单分类中监督信号不足(信息熵比较少)的问题,增加了信息量;
- 提供了训练数据中类别之间的关系(数据增强);
- 可能增强了模型泛化能力
- 降低feature norm (feature normalization)从而让每个类别的样本聚拢的效果
- 产生更好的校准网络,从而更好地泛化,最终对不可见的生产数据产生更准确的预测。
3、Label Smoothing 劣势:
- 单纯地添加随机噪音,也无法反映标签之间的关系,因此对模型的提升有限,甚至有欠拟合的风险。
- 它对构建将来作为教师的网络没有用处,hard 目标训练将产生一个更好的教师神经网络。
四、label smoothing在什么场景有奇效?
1、适用场景
提及了一些NLP领域使用场景的思考:
- 真实场景下,尤其数据量大的时候 数据里是会有噪音的(当然如果你非要说我100%确定数据都是完全正确的, 那就无所谓了啊),为了避免模型错误的学到这些噪音可以加入label smoothing
- 避免模型太自信了,有时候我们训练一个模型会发现给出相当高的confidence,但有时候我们不希望模型太自信了(可能会导致over-fit 等别的问题),希望提高模型的学习难度,也会引入label smoothing
- 分类的中会有一些模糊的case,比如图片分类,有些图片即像猫又像狗, 利用soft-target可以给两类都提供监督效果
hinton的这篇[when does label smoothing help? ]论文从另一个角度去解释了 label smoothing的作用:多分类可能效果更好, 类别更紧密,不同类别分的更开;小类别可能效果弱一些
在label smoothing中有个参数epsilon,描述了将标签软化的程度,该值越大,经过label smoothing后的标签向量的标签概率值越小,标签越平滑,反之,标签越趋向于hard label。
较大的模型使用label smoothing可以有效的提升模型的精度,较小的模型使用此种方法可能会降低模型精度。
2、不适用场景
标签平滑的泛化有利于教师网络的性能,但是它传递给学生网络的信息更少。
尽管使用标签平滑化训练提高了教师的最终准确性,但与使用“硬”目标训练的教师相比,它未能向学生网络传递足够多的知识(没有标签平滑化)。标签平滑“擦除”了在hard目标训练中保留的一些细节。
标签平滑产生的模型是不好的教师模型的原因可以通过初始的可视化或多或少的表现出来。通过强制将最终的分类划分为更紧密的集群,该网络删除了更多的细节,将重点放在类之间的核心区别上。这种“舍入”有助于网络更好地处理不可见数据。然而,丢失的信息最终会对它教授新学生模型的能力产生负面影响。因此,准确性更高的老师并不能更好地向学生提炼信息。
文章出处登录后可见!