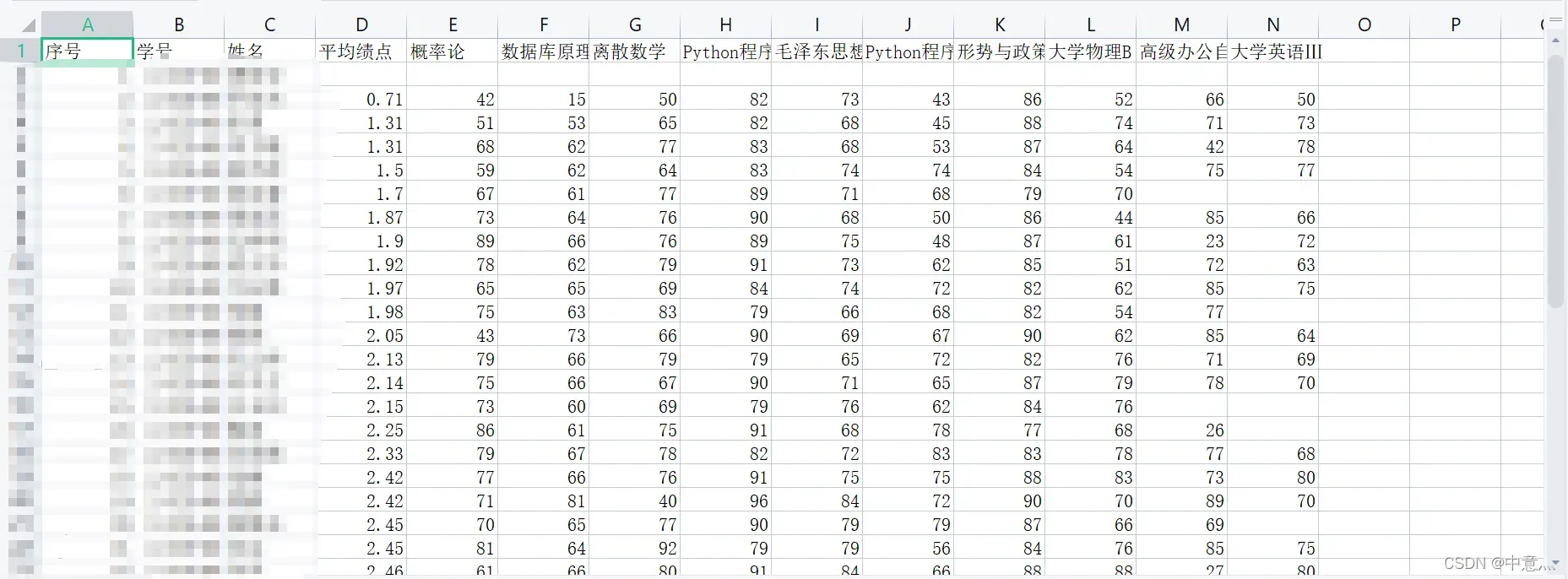
各科目挂科人数分析
# @Time:2022/1/2123:35
# @Author:中意灬
# @File:各班挂科人数分析.py
# @ps:tutu qqnum:2117472285
import copy
import csv
from pyecharts.charts import Bar
from pyecharts.charts import Line
from pyecharts import options as opts
from pyecharts.charts import Pie
import pandas as pd
def Num_eaxm(class_name,columns,Data,file):
df=pd.read_csv(file,encoding='GBK',index_col=0)#读取文件,不将第一列作为索引
item=list(df.columns)[3:]
class_name=class_name
columns=columns
df.rename(columns=columns, inplace = True)
data=copy.deepcopy(Data)
lis=list(data.keys())
data[lis[0]]+=df[df.a<60].count()[0]
data[lis[1]]+=df[df.b<60].count()[0]
data[lis[2]]+=df[df.c<60].count()[0]
data[lis[3]]+=df[df.d<60].count()[0]
data[lis[4]]+=df[df.e<60].count()[0]
data[lis[5]]+=df[df.f<60].count()[0]
data[lis[6]]+=df[df.g<60].count()[0]
data[lis[7]]+=df[df.h<60].count()[0]
data[lis[8]]+=df[df.j<60].count()[0]
data[lis[9]]+=df[df.m<60].count()[0]
return data
if __name__ == '__main__':
Data = {'概率论': 0, '数据库原理与应用': 0, '离散数学': 0, 'Python程序开发语言课程设计': 0, '毛泽东思想和中国特色社会主义理论体系概论Ⅰ': 0, 'Python程序开发语言': 0, '形势与政策Ⅲ': 0,
'大学物理BⅠ': 0,'高级办公自动化':0,'大学英语Ⅲ':0}
class_name = ['概率论', '数据库原理与应用', '离散数学', 'Python程序开发语言课程设计', '毛泽东思想和中国特色社会主义理论体系概论Ⅰ', 'Python程序开发语言', '形势与政策Ⅲ', '大学物理BⅠ', '高级办公自动化', '大学英语Ⅲ']
columns = {'概率论': 'a', '数据库原理与应用': 'b', '离散数学': 'c', 'Python程序开发语言课程设计': 'd', '毛泽东思想和中国特色社会主义理论体系概论Ⅰ': 'e', 'Python程序开发语言': 'f', '形势与政策Ⅲ': 'g',
'大学物理BⅠ': 'h','高级办公自动化':'j','大学英语Ⅲ':'m'}
# 各科目参加考试人数计算
data1= Num_eaxm(class_name, columns, Data, '大数据2020-1级.csv')
data2= Num_eaxm(class_name, columns, Data, '大数据2020-2级.csv')
data3= Num_eaxm(class_name, columns, Data, '大数据2020-3级.csv')
d1=[int(i) for i in list(data1.values())]
d2=[int(i) for i in list(data2.values())]
d3=[int(i) for i in list(data3.values())]
with open('各科挂科人数.csv', mode='w', encoding='utf-8',newline='') as f:
writer = csv.writer(f)
writer.writerow(['班级']+class_name)
writer.writerow(['一班']+d1)
writer.writerow(['二班']+d2)
writer.writerow(['三班']+d3)
bar = (
Bar(init_opts=opts.InitOpts(width="1350px"))
.add_xaxis(class_name) # x轴数据
.add_yaxis('一班', d1) # y轴数据
.add_yaxis('二班', d2)
.add_yaxis('三班', d3)
.set_global_opts(title_opts=opts.TitleOpts(title="2020级各班挂科人数统计"),
xaxis_opts=opts.AxisOpts(name_rotate=60, axislabel_opts={"rotate": 350}))
.set_series_opts(label_opts=opts.LabelOpts(is_show=True))
)
bar.render('2020级各班各科目挂科人数.html')
结果:
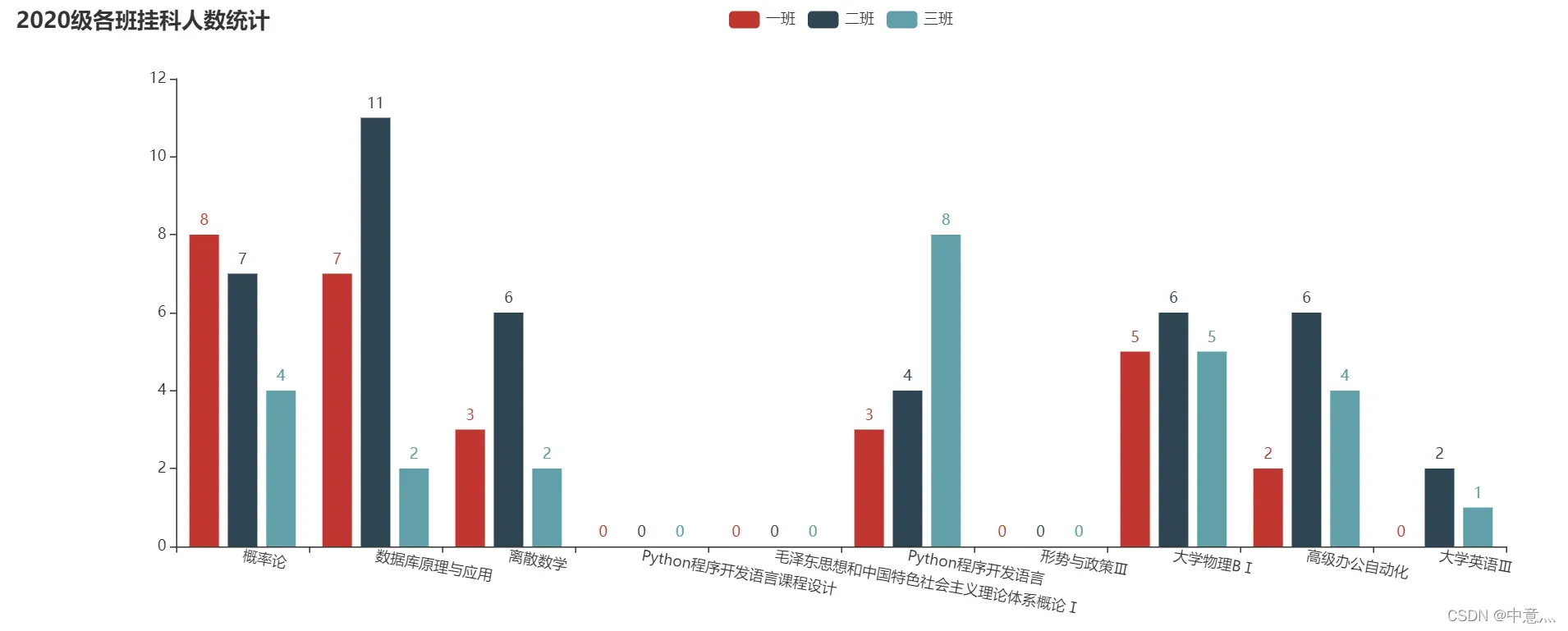
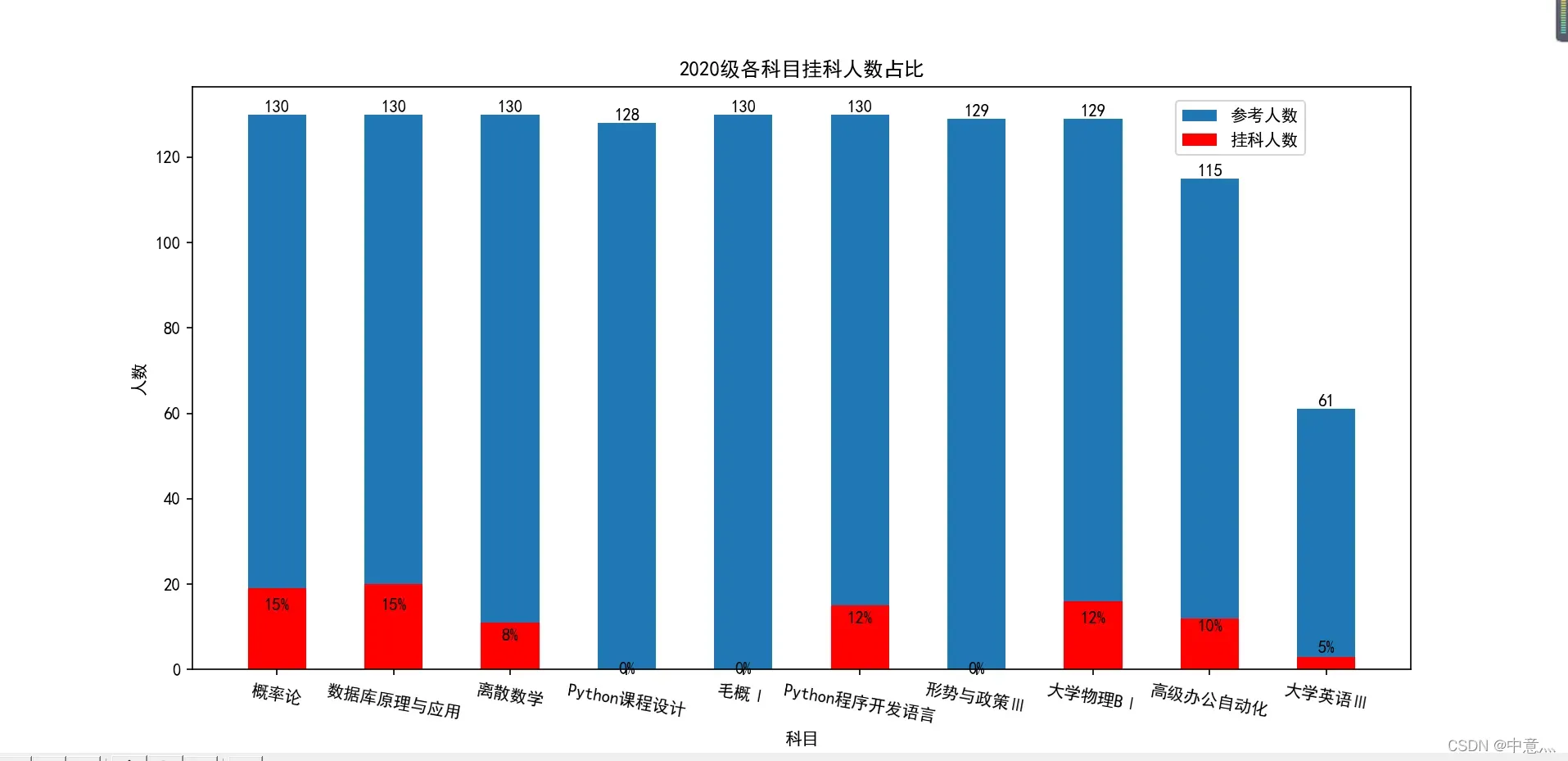
各科挂科人数占比及各班挂科人数
# @Time:2022/1/2213:26
# @Author:中意灬
# @File:各个科目挂科人数比.py
# @ps:tutu qqnum:2117472285
import copy
from matplotlib import pyplot as plt
from pyecharts.charts import Bar
from pyecharts.charts import Line
from pyecharts import options as opts
from pyecharts.charts import Pie
import pandas as pd
def Num_eaxm(class_name,columns,data,file):
df=pd.read_csv(file,encoding='GBK',index_col=0)#读取文件,不将第一列作为索引
item=list(df.columns)[3:]
class_name=class_name
a=df[class_name].count()
columns=columns
df.rename(columns=columns, inplace = True)
num = df[(df.a < 60) | (df.b < 60) | (df.c < 60) | (df.e < 60) | (df.f < 60) | (df.g < 60) | (df.h < 60)].count()[0] # 挂科人数
lis=list(data.keys())
data[lis[0]]+=df[df.a<60].count()[0]
data[lis[1]]+=df[df.b<60].count()[0]
data[lis[2]]+=df[df.c<60].count()[0]
data[lis[3]]+=df[df.d<60].count()[0]
data[lis[4]]+=df[df.e<60].count()[0]
data[lis[5]]+=df[df.f<60].count()[0]
data[lis[6]]+=df[df.g<60].count()[0]
data[lis[7]]+=df[df.h<60].count()[0]
data[lis[8]]+=df[df.j<60].count()[0]
data[lis[9]]+=df[df.m<60].count()[0]
return a,num
if __name__ == '__main__':
data = {'概率论': 0, '数据库原理与应用': 0, '离散数学': 0, 'Python程序开发语言课程设计': 0, '毛泽东思想和中国特色社会主义理论体系概论Ⅰ': 0, 'Python程序开发语言': 0, '形势与政策Ⅲ': 0,
'大学物理BⅠ': 0,'高级办公自动化':0,'大学英语Ⅲ':0}#初始挂科人数
class_name = ['概率论', '数据库原理与应用', '离散数学', 'Python程序开发语言课程设计', '毛泽东思想和中国特色社会主义理论体系概论Ⅰ', 'Python程序开发语言', '形势与政策Ⅲ', '大学物理BⅠ', '高级办公自动化', '大学英语Ⅲ']#课程名称
columns = {'概率论': 'a', '数据库原理与应用': 'b', '离散数学': 'c', 'Python程序开发语言课程设计': 'd', '毛泽东思想和中国特色社会主义理论体系概论Ⅰ': 'e', 'Python程序开发语言': 'f', '形势与政策Ⅲ': 'g',
'大学物理BⅠ': 'h','高级办公自动化':'j','大学英语Ⅲ':'m'}#重命名
#各科目参加考试人数计算
a1,num1=Num_eaxm(class_name,columns,data,'大数据2020-1级.csv')
a2,num2=Num_eaxm(class_name,columns,data,'大数据2020-2级.csv')
a3,num3=Num_eaxm(class_name,columns,data,'大数据2020-3级.csv')
a5 = [int(i + j) for i, j in zip(a1, a2)]
a = [int(i + j) for i, j in zip(a3, a5)]#各科目参考人数
d=list(data.values())#各科目挂科人数
ratio=[round(j/i*100) for i ,j in zip(a,d)]
#绘图
title=['概率论', '数据库原理与应用', '离散数学', 'Python课程设计', '毛概Ⅰ', 'Python程序开发语言', '形势与政策Ⅲ', '大学物理BⅠ', '高级办公自动化', '大学英语Ⅲ']
plt.rcParams['font.sans-serif'] = ['SimHei'] # 处理中文显现问题
plt.figure()
base_num = plt.bar(title,width=0.5, height=a) # 绘制条形图,height表示高度
edu_num = plt.bar(title,width=0.5, height=d,color='r') # 绘制条形图,height表示高度
for x, y in zip(title, ratio):
plt.text(x, y, '%.0f%%' % y, ha='center', va='center', fontsize=10,
c='black') # ha表示水平对齐方式,va表示锤子对其方式,fontsize表示字体大小
for x, y in zip(title, a):
plt.text(x, y, y, ha='center', va='bottom', fontsize=10)
plt.xticks(rotation=350)
plt.xlabel('科目',fontsize=10) # 设置x轴标签
plt.ylabel('人数',fontsize=10) # 设置y轴标签
plt.title('2020级各科目挂科人数占比') # 设置题目
plt.legend([base_num, edu_num], labels=['参考人数', '挂科人数'], bbox_to_anchor=(0.8, 0.99)) # 设置标签,bbox_to_anchor设置绝对位置
plt.tight_layout # 调整多图被截断或遮挡等情况
plt.show()
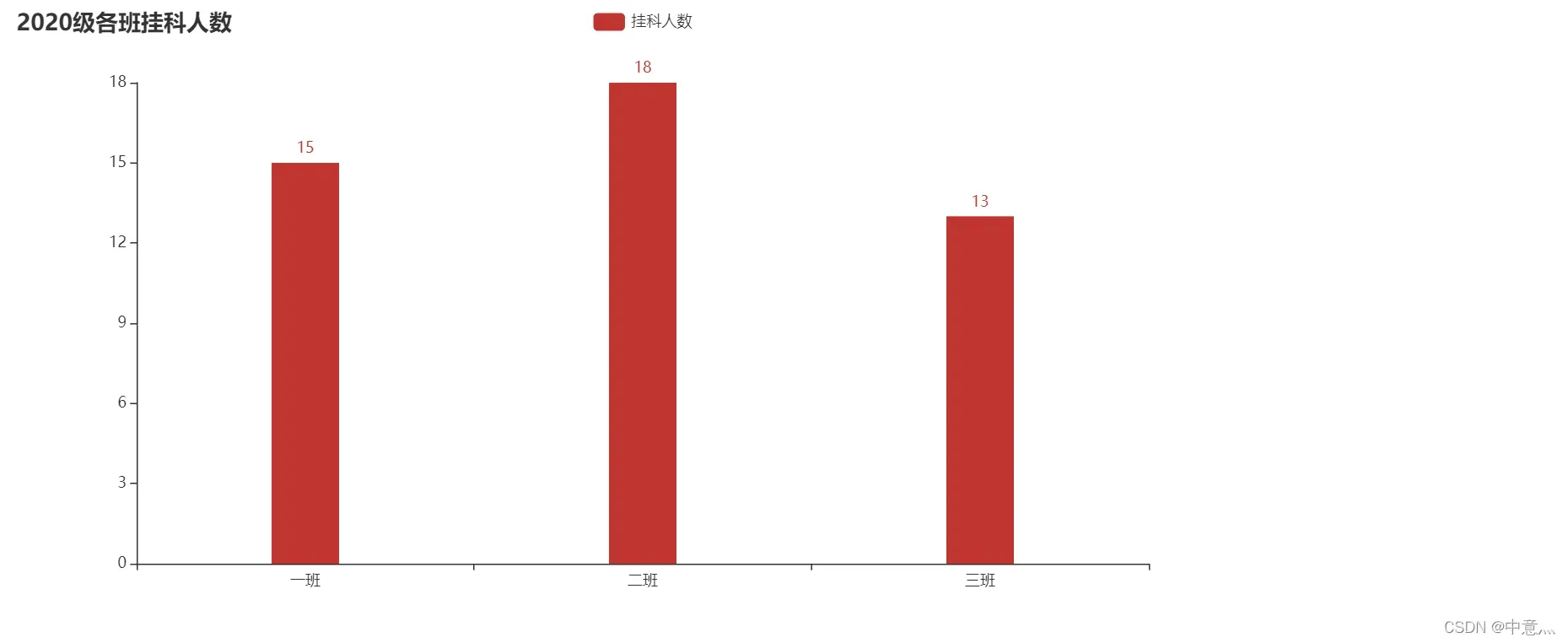
#各班挂科人数柱状图
calssNum=['一班','二班','三班']
faiel_num=[int(num1),int(num2),int(num3)]
bar = (
Bar(init_opts=opts.InitOpts(width="1000px"))
.add_xaxis(calssNum) # x轴数据
.add_yaxis('挂科人数', faiel_num,bar_width='20%') # y轴数据
.set_global_opts(title_opts=opts.TitleOpts(title="2020级各班挂科人数"),
xaxis_opts=opts.AxisOpts(name_rotate=30, axislabel_opts={"rotate": 0})) # 设置一些标题,坐标轴参数
.set_series_opts(label_opts=opts.LabelOpts(is_show=True)) # 是否显示数据值
)
bar.render('2020级各班挂科人数.html')
plt.rcParams['font.sans-serif'] = 'SimHei' # 中文问题
plt.figure()
shuju=[19,20 ,11 ,15,16,12,3 ]
lable=['概率论', '数据库原理与应用', '离散数学', 'Python程序开发语言', '大学物理B','高级办公自动化', '大学英语Ⅲ']
explode = [0.01, 0.01, 0.01, 0.01,0.01,0.01,0.01]
color = ['red', 'orange', 'green', 'blue','m','c','pink']
plt.pie(shuju, labels=lable, explode=explode, autopct='%1.1f%%', colors=color,
shadow=True) # labels表示标签,explode表示各板块离开中心的距离,autopct标签饼图百分比设置,colors表示颜色,shadow表示阴影(增加立体感)
plt.legend(loc='upper left', bbox_to_anchor=(1, 1.01)) # 设置标签,bbox_to_anchor表示设置的绝对位置
plt.title('2020级各科挂科人数情况') # 设置标题
plt.tight_layout # 调整多图被截断或遮挡等情况
plt.show()
结果:

各班绩点分布
# @Time:2022/1/2216:10
# @Author:中意灬
# @File:各班绩点分布.py
# @ps:tutu qqnum:2117472285
import copy
import csv
from pyecharts.charts import Bar
from pyecharts.charts import Line
from pyecharts import options as opts
from pyecharts.charts import Pie
import pandas as pd
def sorce(file):
df = pd.read_csv(file, encoding='GBK', index_col=0) # 读取文件,不将第一列作为索引
a1=df[(df.平均绩点<1)&(df.平均绩点>=0)].count()[0]
a2=df[(df.平均绩点<1.5)&(df.平均绩点>=1)].count()[0]
a3=df[(df.平均绩点<2)&(df.平均绩点>=1.5)].count()[0]
a4=df[(df.平均绩点<2.5)&(df.平均绩点>=2)].count()[0]
a5=df[(df.平均绩点<3)&(df.平均绩点>=2.5)].count()[0]
a6=df[(df.平均绩点<3.5)&(df.平均绩点>=3)].count()[0]
a7=df[(df.平均绩点<4)&(df.平均绩点>=3.5)].count()[0]
a8=df[(df.平均绩点<4.5)&(df.平均绩点>=4)].count()[0]
a9=df[(df.平均绩点<=5)&(df.平均绩点>4.5)].count()[0]
a=[int(a1),int(a2),int(a3),int(a4),int(a5),int(a6),int(a7),int(a8),int(a9)]
return a
if __name__ == '__main__':
title=['[0,1)','[1,1.5)','[1.5,2)','[2,2.5)','[2.5,3)','[3,3.5)','[3.5,4)','(4,4.5)','[4.5,5]']
a1=sorce('大数据2020-1级.csv')
a2=sorce('大数据2020-2级.csv')
a3=sorce('大数据2020-3级.csv')
with open('各班绩点分布.csv',mode='w',encoding='utf-8',newline='')as f:
writer=csv.writer(f)
writer.writerow(['班级']+title)
writer.writerow(['一班']+a1)
writer.writerow(['二班']+a2)
writer.writerow(['三班']+a3)
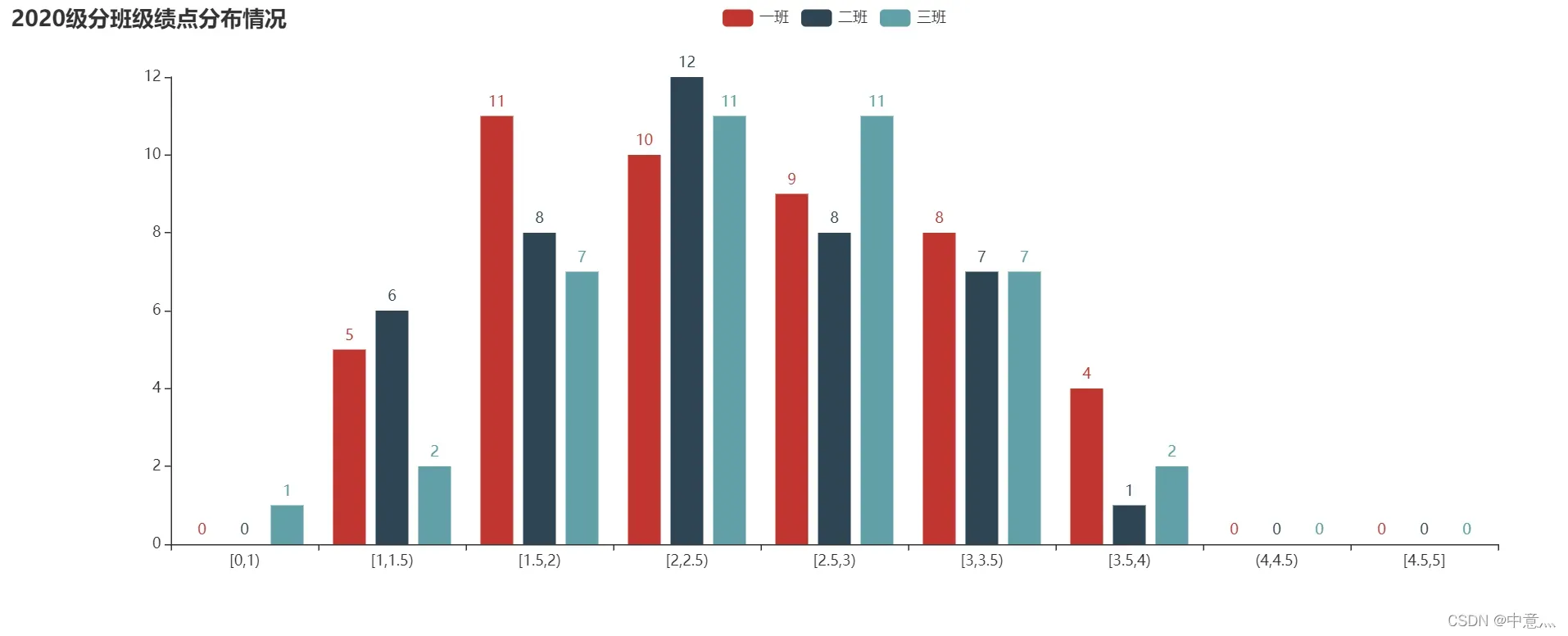
bar = (
Bar(init_opts=opts.InitOpts(width="1350px"))
.add_xaxis(title) # x轴数据
.add_yaxis('一班', a1) # y轴数据
.add_yaxis('二班', a2)
.add_yaxis('三班', a3)
.set_global_opts(title_opts=opts.TitleOpts(title="2020级分班级绩点分布情况"),
xaxis_opts=opts.AxisOpts(name_rotate=60, axislabel_opts={"rotate": 0}))
.set_series_opts(label_opts=opts.LabelOpts(is_show=True))
)
bar.render('2020级分班级绩点分布情况.html')
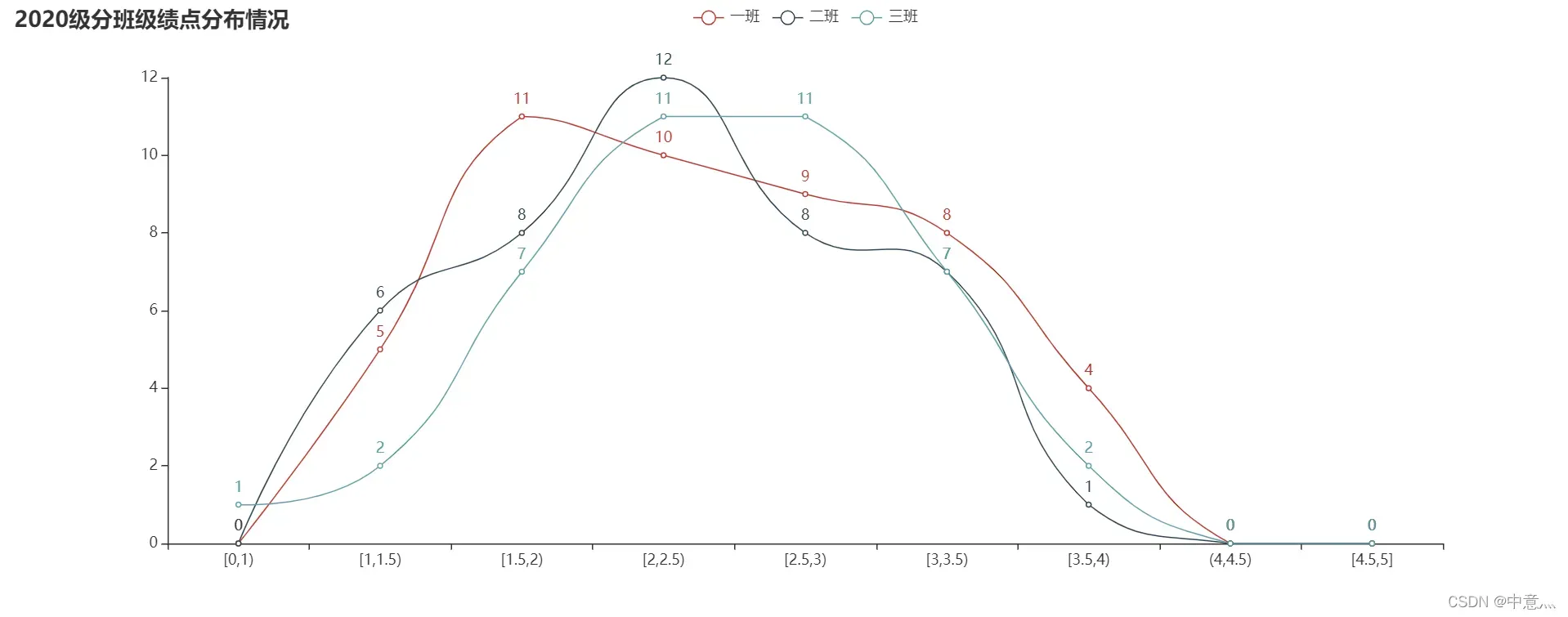
line = (
Line(init_opts=opts.InitOpts(width="1300px"))
.add_xaxis(title)
.add_yaxis('一班', a1,is_smooth=True) # y轴数据
.add_yaxis('二班', a2,is_smooth=True)
.add_yaxis('三班', a3,is_smooth=True)
.set_global_opts(title_opts=opts.TitleOpts(title="2020级分班级绩点分布情况"),
xaxis_opts=opts.AxisOpts(name_rotate=60, axislabel_opts={"rotate": 0}))
.set_series_opts(abel_opts=opts.LabelOpts(is_show=True))
)
line.render('2020级分班级绩点分布折线图.html')
结果:

班级平均绩点
# @Time:2022/1/2216:32
# @Author:中意灬
# @File:班级平均绩点.py
# @ps:tutu qqnum:2117472285
from pyecharts.charts import Bar
from pyecharts.charts import Line
from pyecharts import options as opts
from pyecharts.charts import Pie
import pandas as pd
def avg_sorce(file):
df = pd.read_csv(file, encoding='GBK', index_col=0) # 读取文件,不将第一列作为索引
avg=df['平均绩点'].mean()
s=df['平均绩点'].sum()
cout=df['平均绩点'].count()
return avg,s,cout
def count_sorece_num(file,avg):
df=pd.read_csv(file,encoding='GBK',index_col=0)
high=int(df[df.平均绩点>=avg].count()[0])
low=int(df[df.平均绩点<avg].count()[0])
return high,low
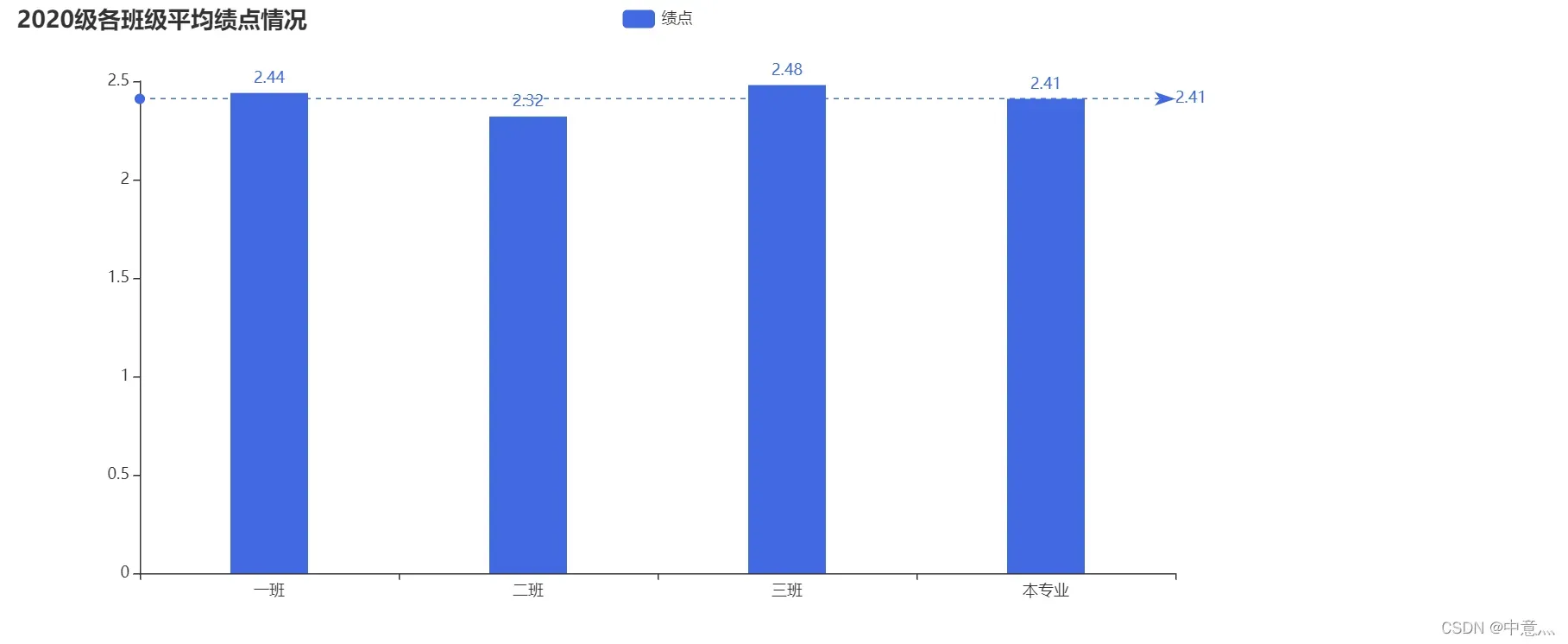
if __name__ == '__main__':
a1,s1,c1=avg_sorce('大数据2020-1级.csv')
a2,s2,c2=avg_sorce('大数据2020-2级.csv')
a3,s3,c3=avg_sorce('大数据2020-3级.csv')
a5=(s1+s2+s3)/(c2+c3+c1)#本专业得平均绩点
a=[float(round(a1,2)),float(round(a2,2)),float(round(a3,2)),float(round(a5,2))]
title=['一班','二班','三班','本专业']
bar = (
Bar(init_opts=opts.InitOpts(width="1000px"))
.add_xaxis(title) # x轴数据
.add_yaxis('绩点', a,bar_width='30%',color='#4169E1') # y轴数据
.set_global_opts(title_opts=opts.TitleOpts(title="2020级各班级平均绩点情况"),
xaxis_opts=opts.AxisOpts(name_rotate=30, axislabel_opts={"rotate": 0})) # 设置一些标题,坐标轴参数
.set_series_opts(label_opts=opts.LabelOpts(is_show=True),
markline_opts=opts.MarkLineOpts(
# 标记线数据
data=[
# MarkLineItem:标记线数据项
opts.MarkLineItem(
name="本专业平均绩点",
y = a5,
)]))
)
bar.render('2020级各班级平均绩点.html')
z1=[]
z2=[]
z3=[]
z1.extend(count_sorece_num('大数据2020-1级.csv',a5))
z2.extend(count_sorece_num('大数据2020-2级.csv',a5))
z3.extend(count_sorece_num('大数据2020-3级.csv',a5))
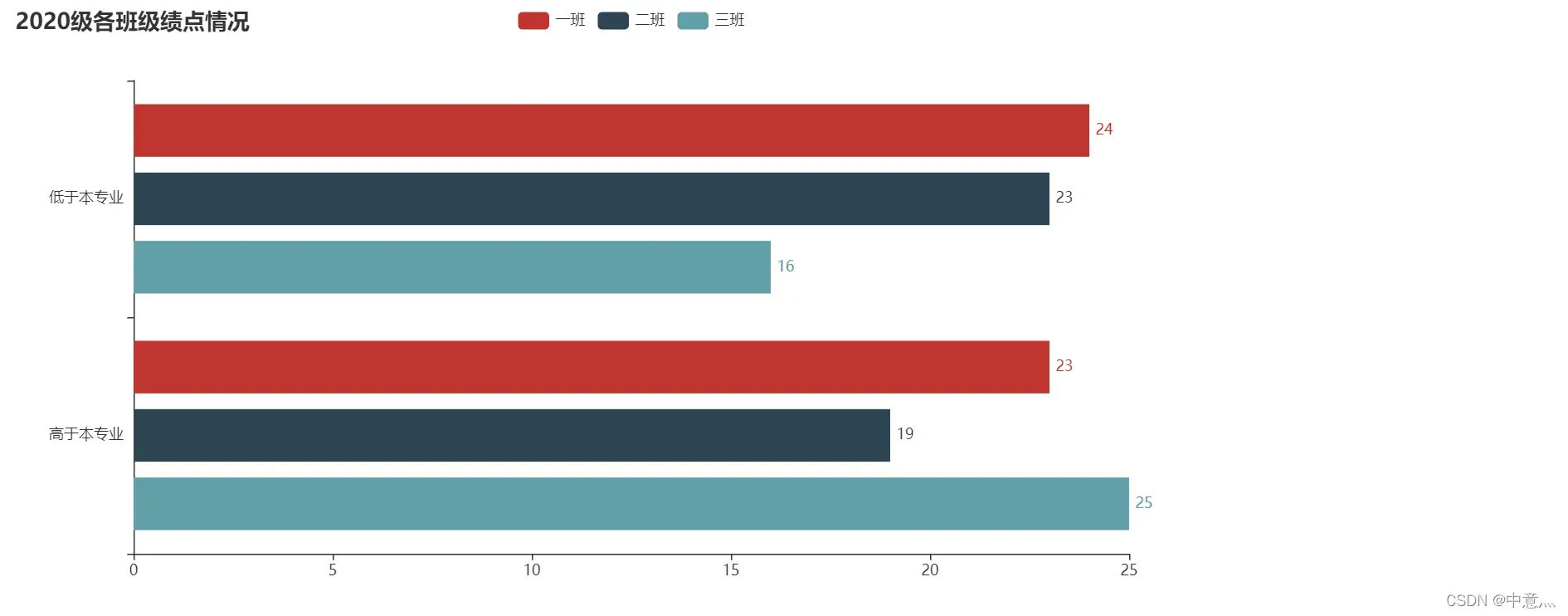
title=['高于本专业','低于本专业']
bar = (
Bar(init_opts=opts.InitOpts(width="1000px"))
.add_xaxis(title) # x轴数据
.add_yaxis('一班', z1) # y轴数据
.add_yaxis('二班', z2) # y轴数据
.add_yaxis('三班', z3) # y轴数据
.reversal_axis()
.set_global_opts(title_opts=opts.TitleOpts(title="2020级各班级绩点情况"),
xaxis_opts=opts.AxisOpts(name_rotate=30, axislabel_opts={"rotate": 0})) # 设置一些标题,坐标轴参数
.set_series_opts(label_opts=opts.LabelOpts(position="right")
))
bar.render('2020级与本专业绩点比较情况.html')
结果:
单人挂科数量分析
# @Time:2022/1/2219:20
# @Author:中意灬
# @File:单人挂科数量统计.py
# @ps:tutu qqnum:2117472285
import csv
from matplotlib import pyplot as plt
from pyecharts.charts import Bar
from pyecharts.charts import Line
from pyecharts import options as opts
from pyecharts.charts import Pie
import pandas as pd
def single_faile_num(file):
df=pd.read_csv(file,encoding="GBK",index_col=0)
d=df.fillna(value=60)
lis=[]
for i in range(len(df)):
a=0
for j in list(d.iloc[i][3:]):
if j <60:
a=a+1
lis.append(a)
return lis
def fun(lis,n):
a=0
b=0
c=0
d=0
e=0
for i in lis:
if i==0:
a=a+1
if i==1:
b=b+1
if i==2:
c=c+1
if i>2:
d=d+1
List=[a-n,b,c,d]
return List
if __name__ == '__main__':
lis1=single_faile_num('大数据2020-1级.csv')
lis2=single_faile_num('大数据2020-2级.csv')
lis3=single_faile_num('大数据2020-3级.csv')
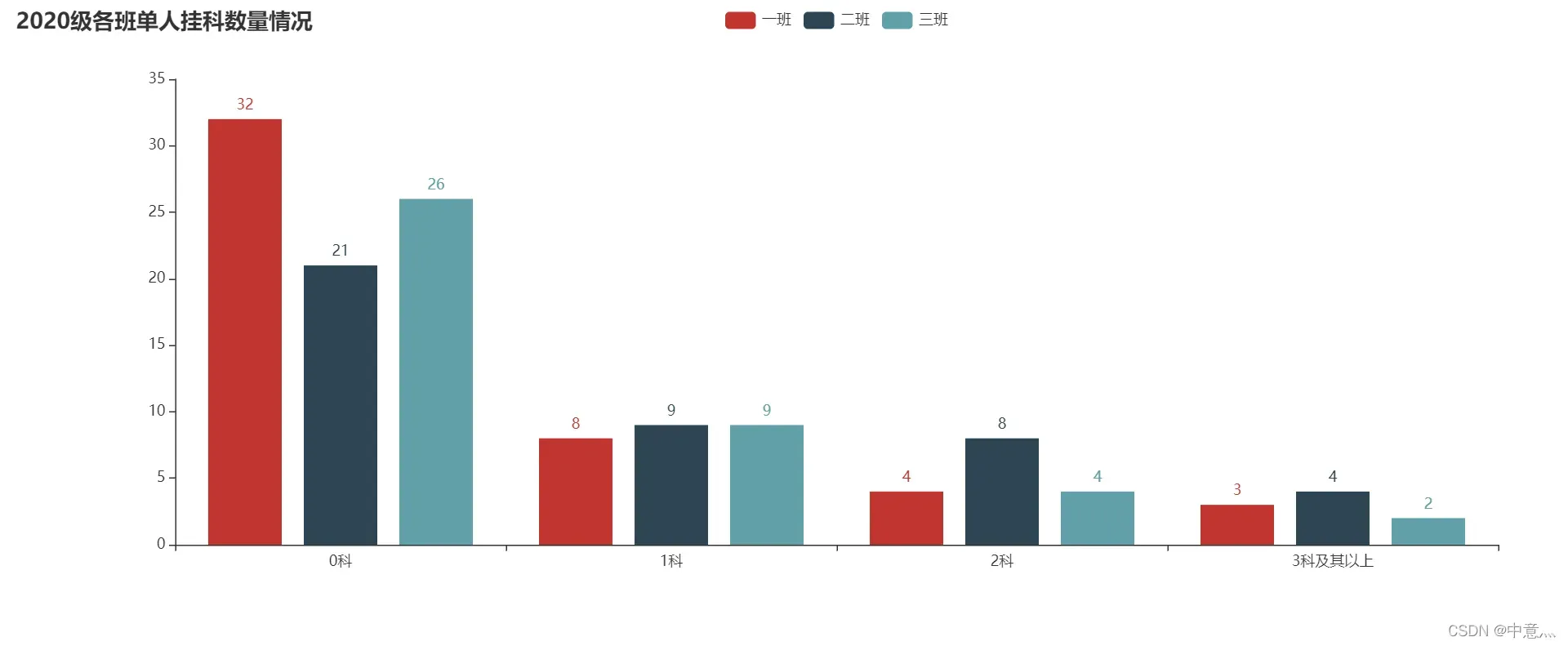
#每班单人挂科数量情况
title=["0科","1科","2科","3科及其以上"]
a1=fun(lis1,2)
a2=fun(lis2,1)
a3=fun(lis3,1)
with open('个人挂科数量情况.csv',mode='w',encoding='utf-8',newline='')as f:
writer=csv.writer(f)
writer.writerow(['班级']+title)
writer.writerow(['一班']+a1)
writer.writerow(['二班']+a2)
writer.writerow(['三班']+a3)
#画图
bar = (
Bar(init_opts=opts.InitOpts(width="1350px"))
.add_xaxis(title) # x轴数据
.add_yaxis('一班', a1) # y轴数据
.add_yaxis('二班', a2)
.add_yaxis('三班', a3)
.set_global_opts(title_opts=opts.TitleOpts(title="2020级各班单人挂科数量情况"),
xaxis_opts=opts.AxisOpts(name_rotate=60, axislabel_opts={"rotate": 0}))
.set_series_opts(label_opts=opts.LabelOpts(is_show=True))
)
bar.render("2020级各班单人挂科情况柱状图.html")
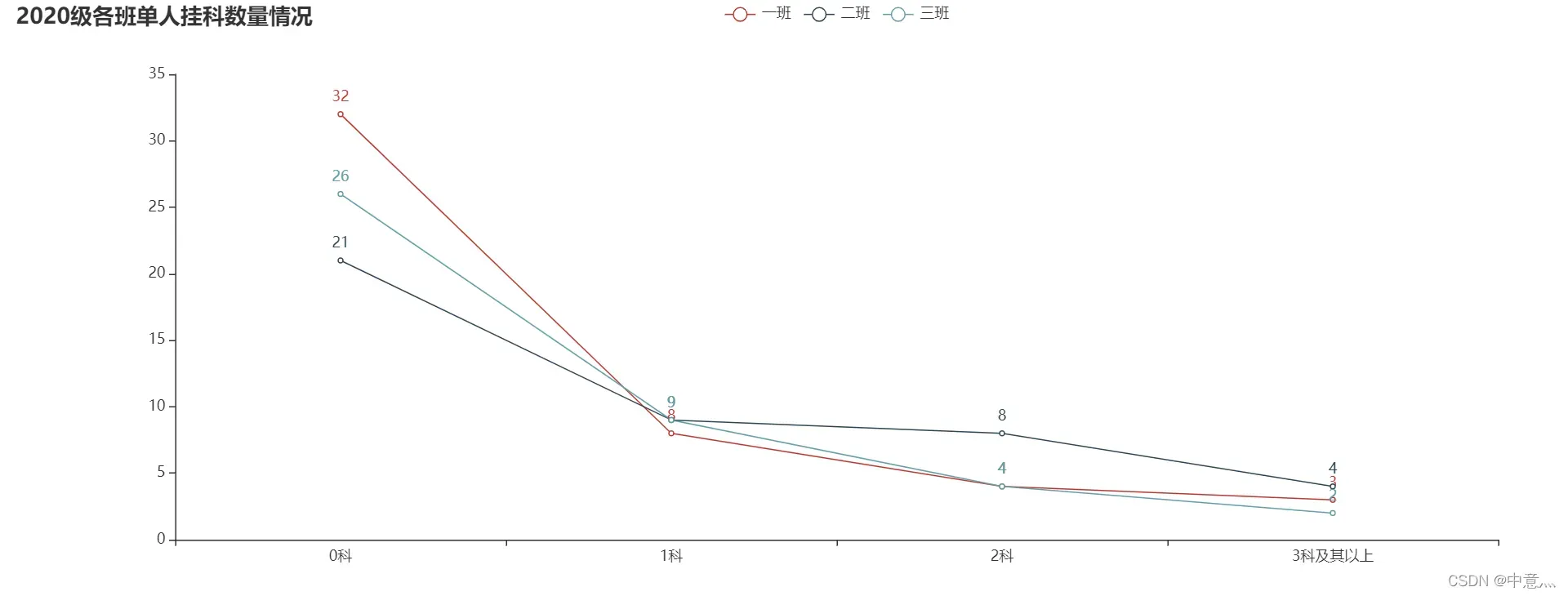
line = (
Line(init_opts=opts.InitOpts(width="1350px"))
.add_xaxis(title) # x轴数据
.add_yaxis('一班', a1) # y轴数据
.add_yaxis('二班', a2)
.add_yaxis('三班', a3)
.set_global_opts(title_opts=opts.TitleOpts(title="2020级各班单人挂科数量情况"),
xaxis_opts=opts.AxisOpts(name_rotate=60, axislabel_opts={"rotate": 0}))
.set_series_opts(label_opts=opts.LabelOpts(is_show=True))
)
line.render("2020级各班单人挂科情况折线图.html")
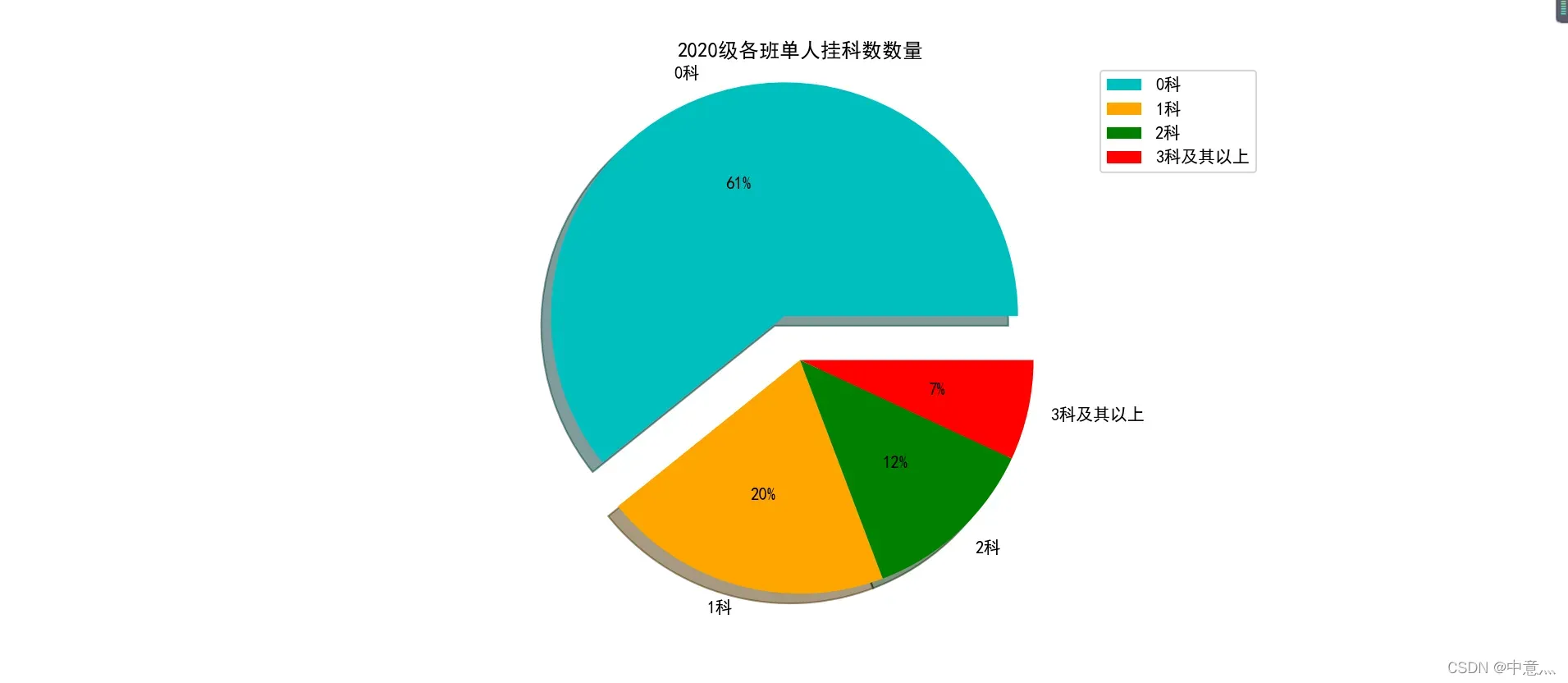
plt.rcParams['font.sans-serif'] = 'SimHei' # 中文问题
plt.figure()
a=[a1[0]+a2[0]+a3[0],a1[1]+a2[1]+a3[1],a1[2]+a2[2]+a3[2],a1[3]+a2[3]+a3[3]]
explode = [0.2, 0.0, 0.0, 0.0]
color = ['c', 'orange', 'green', 'red']
plt.pie(a, labels=title, explode=explode,autopct='%1.0f%%', colors=color,
shadow=True) # labels表示标签,explode表示各板块离开中心的距离,autopct标签饼图百分比设置,colors表示颜色,shadow表示阴影(增加立体感)
plt.legend(loc='upper left', bbox_to_anchor=(1, 1.01)) # 设置标签,bbox_to_anchor表示设置的绝对位置
plt.title('2020级各班单人挂科数数量') # 设置标题
plt.tight_layout # 调整多图被截断或遮挡等情况
plt.show()

最终成绩分析报告
版权声明:本文为博主中意灬原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_55977554/article/details/122667432