本文主要是对"Efficient Convolutional Neural Networks for Depth-Based Multi-Person Pose Estimation"论文的一个介绍,2019年发表,作者是ANMG等,很优秀的一篇论文。链接:https://arxiv.org/pdf/1912.00711.pdf
- 概述
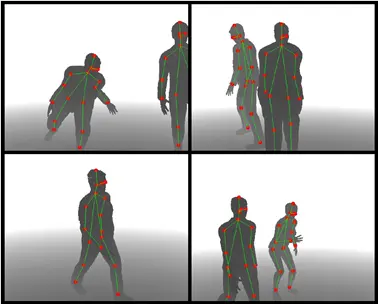
首先,本文的目标是在一副深度图像中获取出人体的关键点坐标,本文中认为有17个,结果实例如下图所示。
本文采用的架构如下:
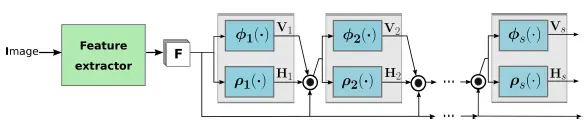
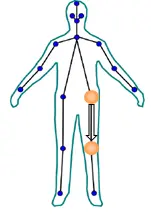
包含两个大的阶段,前一阶段使用CNN进行特征提取;后一阶段是几个级联(cascade)的预测器,从第二个预测器开始输入(input)即考虑前一个预测器的输出,也融合了提取出的原始特征。结果上来看H代表的是人体关键点目标检测的confidence map,越是接近人体关键点的位置其置信度(Confidence)肯定更高,所以在GT中设定关键点附近的像素置信度(Confidence)按高斯(RBM Gaussian RBM)分布(Gaussian distribution)(Distribution),如下图中黄色圆圈所示。V则代表了对人体四肢的预测向量,V代表了连接某两个关节(比如臀关节和膝关节)的向量,如下图中大箭头所示。损失函数(Loss function)也是由这两个部分的回归(Regression)残差组成。

- 特征目标检测与预测网络
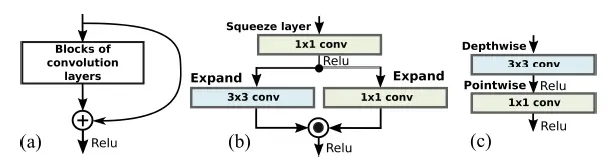
作者对三种特征目标检测网络进行了测试,分别是Residual网络,SqueezeNet网络和MobileNet网络。其网络结构分别如下所示,看不清图可以去原文查看。作者之所以选用了一些轻量级的网络架构是因为姿态目标检测任务经常是在诸如机器人等嵌入(Embedding)式场景使用,没有过高的算力。
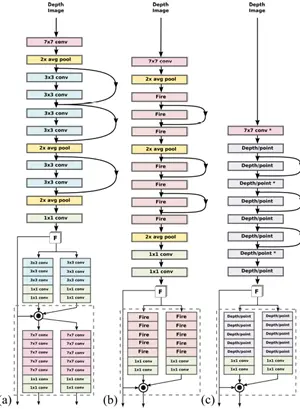
三个网络中的关键构造如下图所示,分别是Residual中的残差层,SqueezeNet中的Fire层和MobileNet中的DepthWise/pointwise层。
- 基于对抗的域自适应
对抗网络(Adversarial Networks)被引入的原因是:在本文中,训练用的是合成的数据集(Dataset),而测试用的是真实的数据集(Dataset),两个数据集(Dataset)存在一定的差别,为了能使训练出的网络在测试集上不拉胯,需要寻求两个数据集(Dataset)的不变(invariant)性表示。这一点我感觉有点意思。
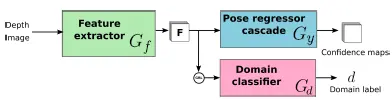
如上图所示,在原来的预测部分,并行添加了一个域分类器(Classifier),用来分类输入(input)图像是合成域的,还是真实域的。如果学习到的特征F即能满足预测出的Confidence map结果准确,又能使域分类器(Classifier)感到发懵,那么设计就成功了。
在该种情况下的损失函数(Loss function)只是加上了域分类器(Classifier)的分类损失函数(Loss function)。
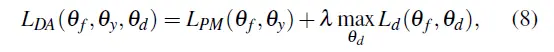
- 知识蒸馏(knowledge distillation)
首先解释一下知识蒸馏,简单点说就是将一个已经训练好的重量级网络中的经验传授给一个泛化(Generalization)能力比较弱的轻量级网络,前者就是老师,后者就是学生。在本文中之所以会引入这一机制是因为不同的数据集(Dataset)差别是比较大的,有的有遮挡有的没有,各种数据集(Dataset)的角度也不同等。
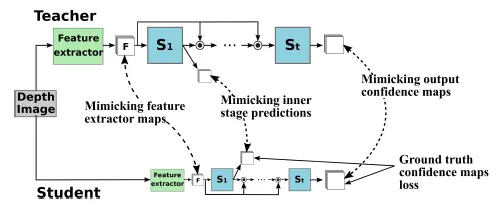
学习的第一步就是模仿,本文的知识蒸馏不仅会把老师的输出结果教给学生,也会把中间的过程教给学生,是与传统知识蒸馏不太一样的地方。 - 最后还是给出一个基于pytorch的实现:https://github.com/idiap/fast_pose_machines

版权声明:本文为博主隋边边原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。