Unet的文件下载
网盘下载:链接:https://pan.baidu.com/s/1H1Q8QpR0R3pNdJwKxvKD0g
提取码:wn5i
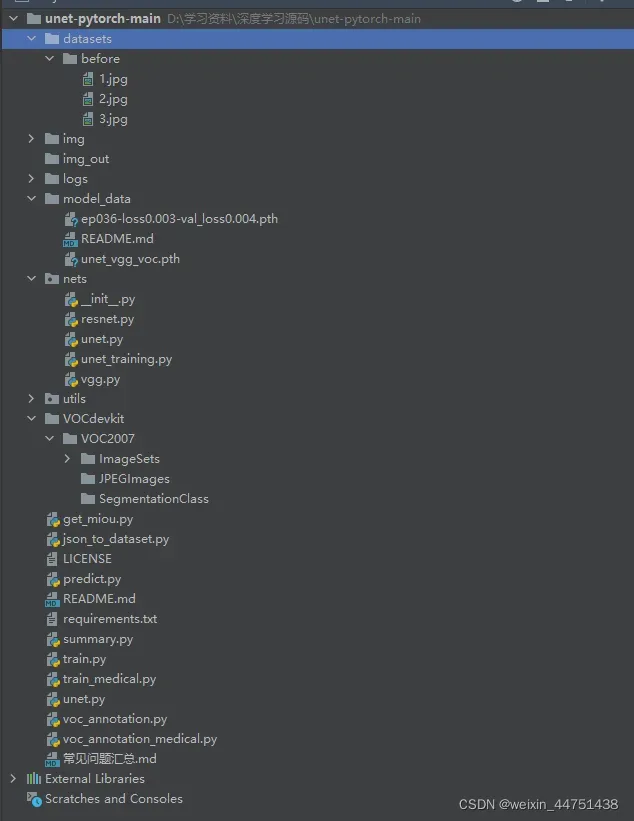
1. 创建数据集
1.安装labelme
Win+R启动cmd,在命令提示符内输入以下命令:
activate pytorch #激活环境
pip install labelme==3.16.7 #安装labelme,尽量安装3.16.7不然运行会出错
2.将要标注的图像放置到下面路径before文件夹中
3.运行labelme进行标注
Win+R启动cmd,在命令提示符内输入以下命令:
labelmelabelme软件就会打开
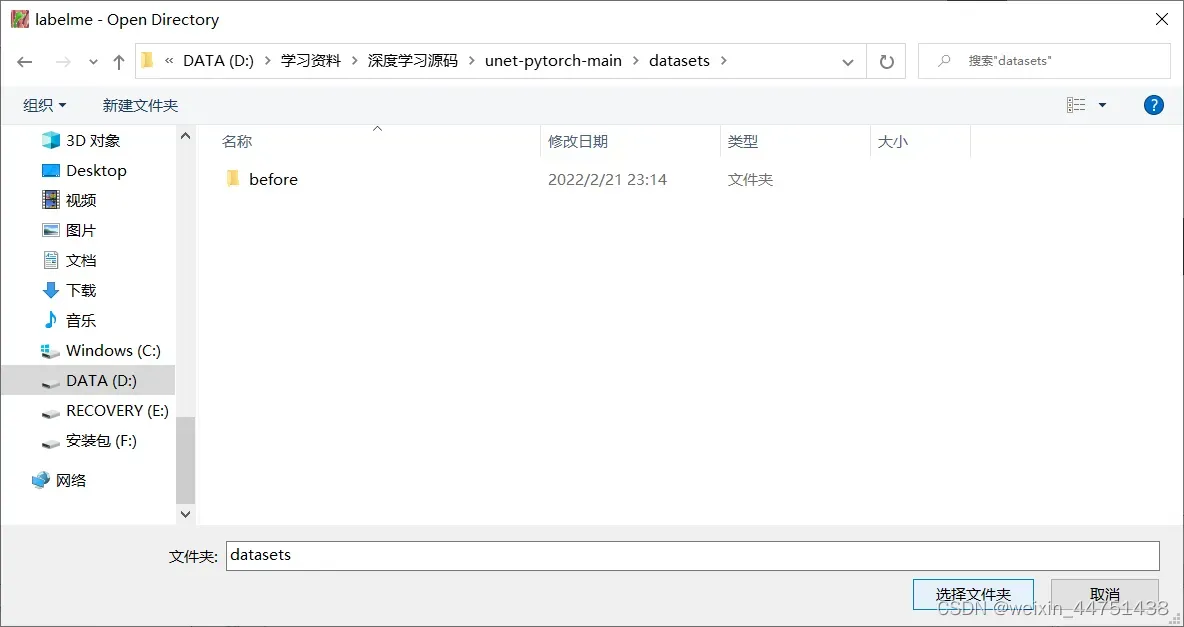
点击Open Dir,跳转到如下路径,点击选择文件夹即可
键盘:A(上一张图片)、D(下一张图片)
Edit中Create Polygons进行不规则标注,其他详细使用方法请百度查询
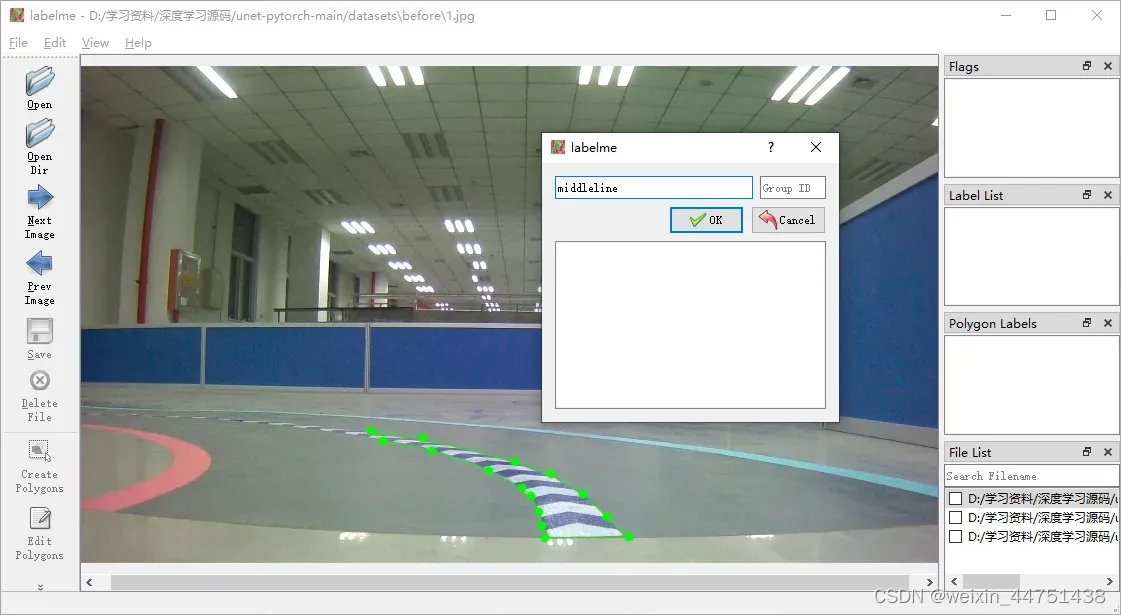
每张图片标注成功之后会出现一个对应的.json格式的文件
4.打开json_to_dataset.py
注意:运行 json_to_dataset.py前datasets中before中放的是1.jpg和1.json文件、JPEGImages和SegmentationClass中为空文件
运行 json_to_dataset.py后datasets中before中放的是1.jpg和1.json文件、JPEGImages中会生成原始的.jpg文件、SegmentationClass中会生成.png文件
修改json_to_dataset.py中的classes中的类别(改为要识别3中物体的名称)
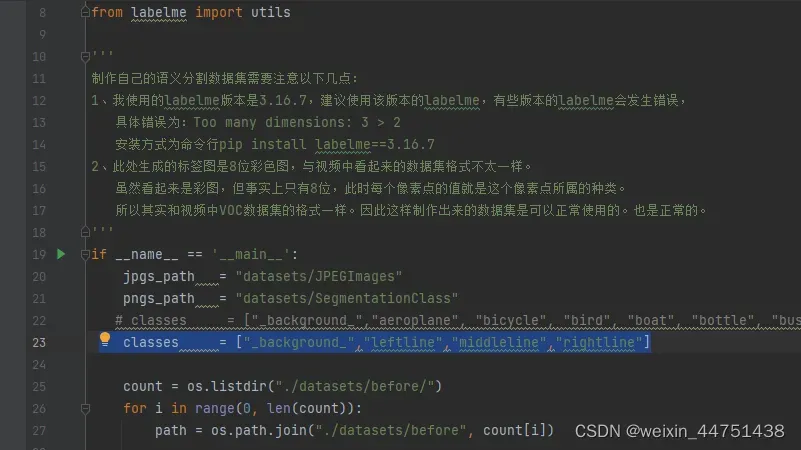
运行json_to_dataset.py文件
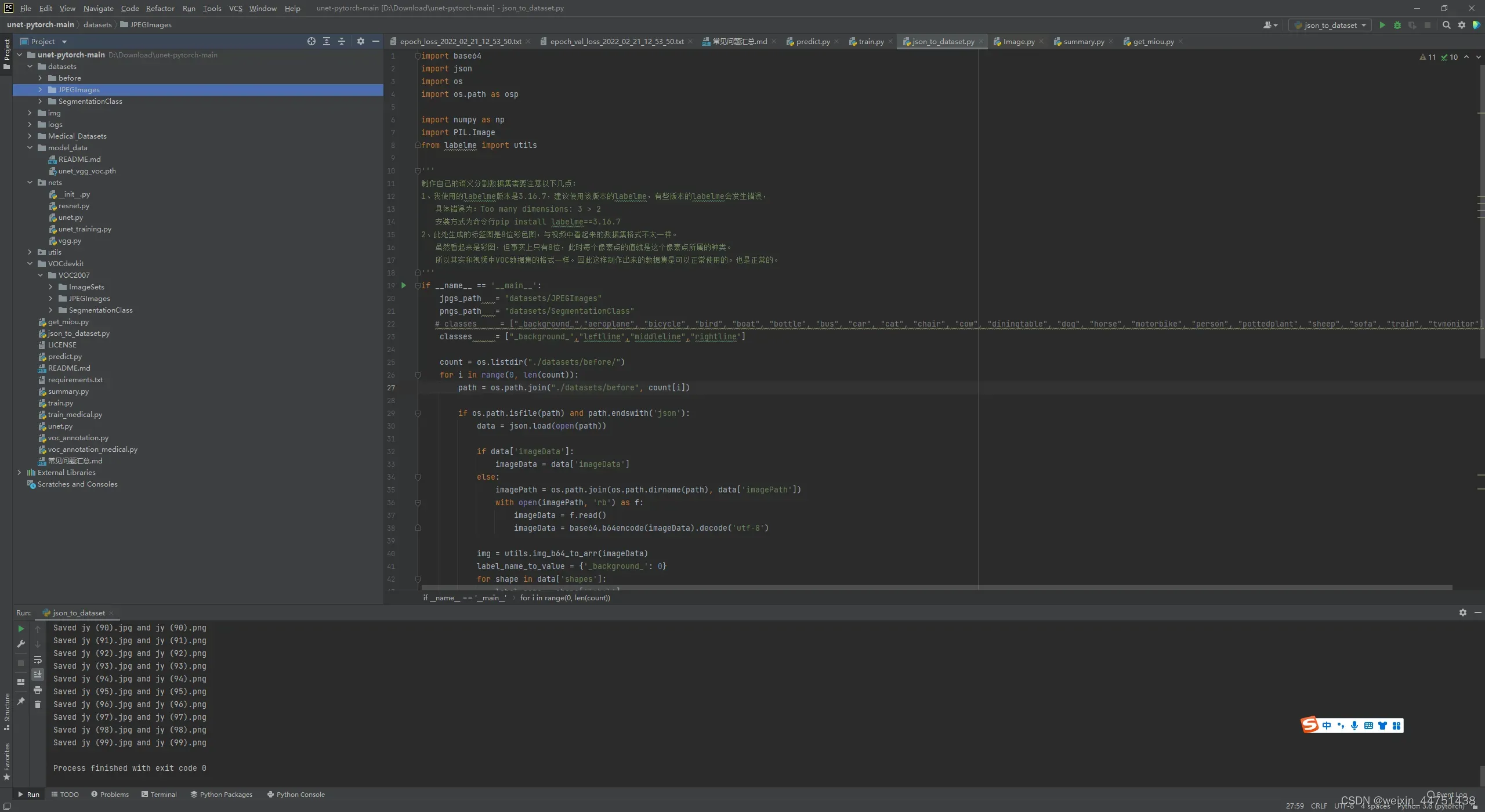
会在JPEGImages和SegmentationClass中分别生成
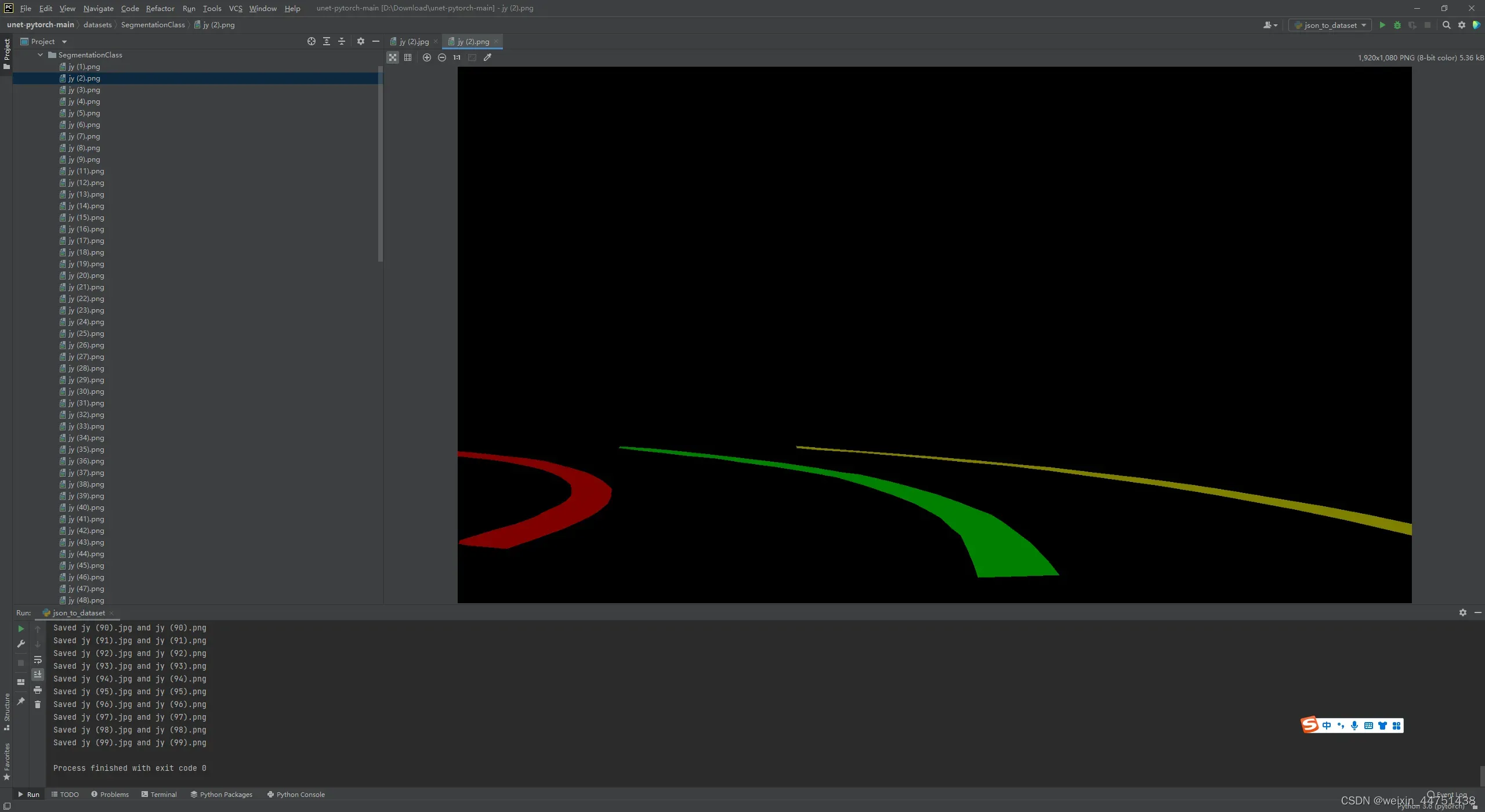
5.数据集
将下面两个文件复制粘贴到VOCdevkit路径下
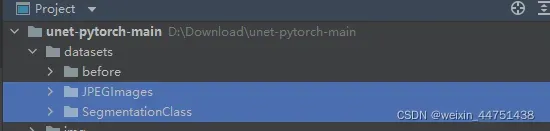
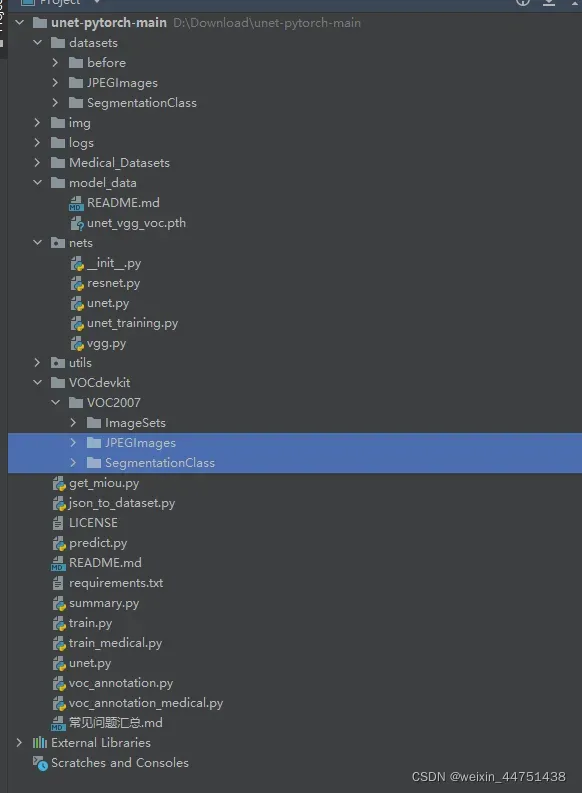
2.划分训练集和数据集
注意:运行voc_annotation.py前此时ImageSets没有文件
运行voc_annotation.py后ImageSets生成四个文件
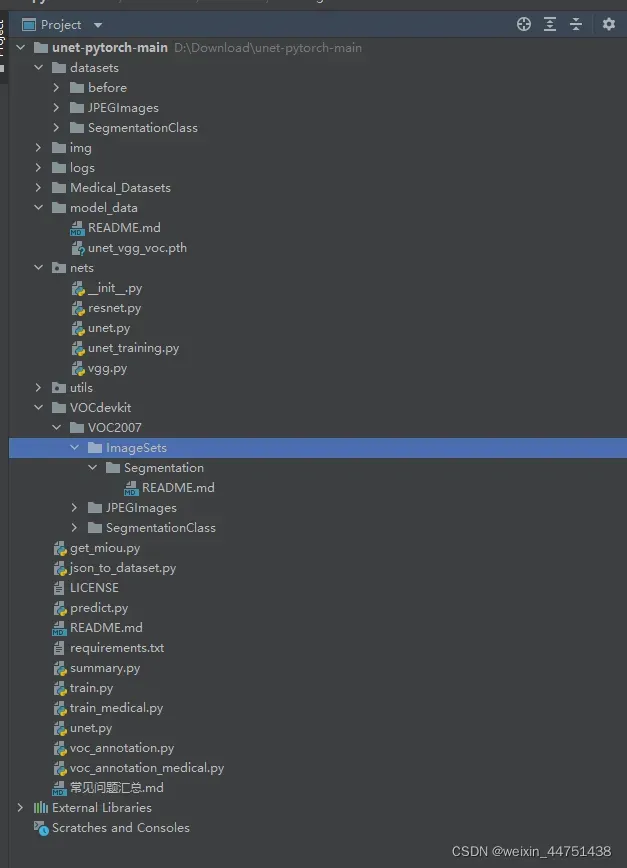
运行voc_annotation.py
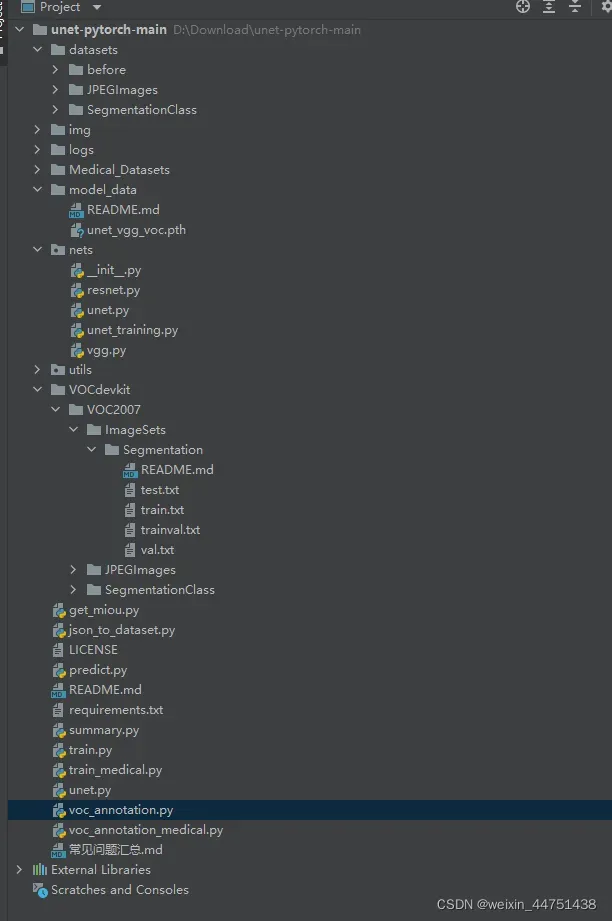
三、训练数据集
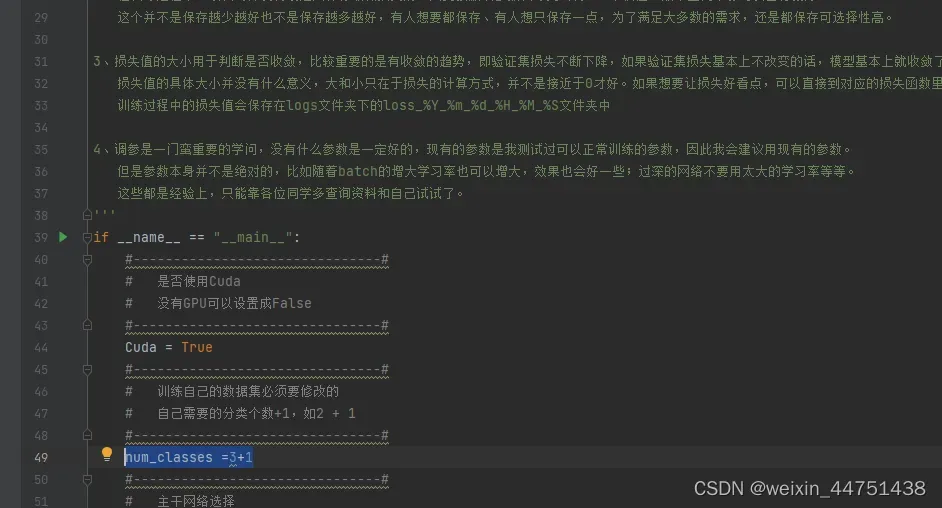
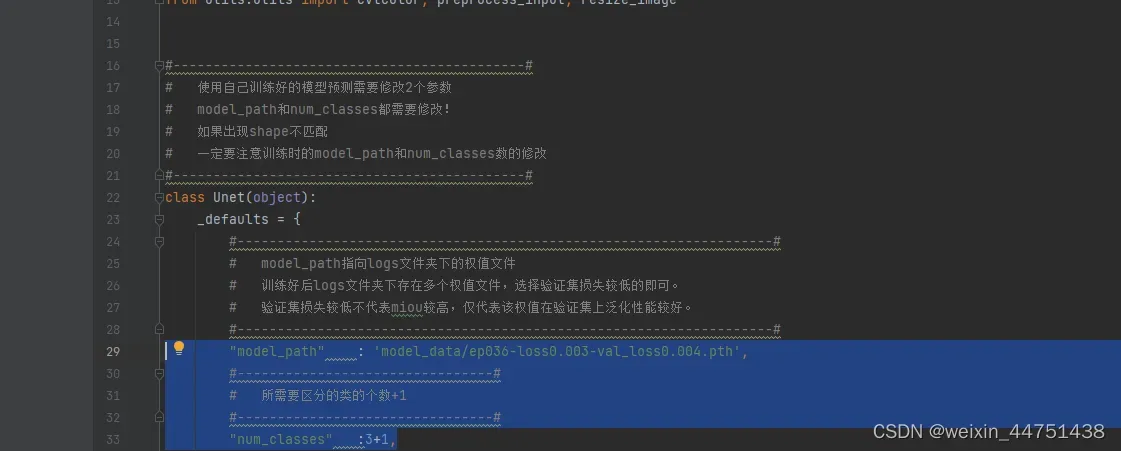
打开train.py文件,修改num_classes=分类的个数+1
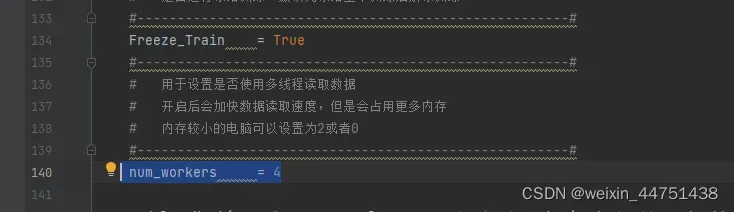
num_workers工作的线程(可以不修改,内存较小的话修改为2或0)
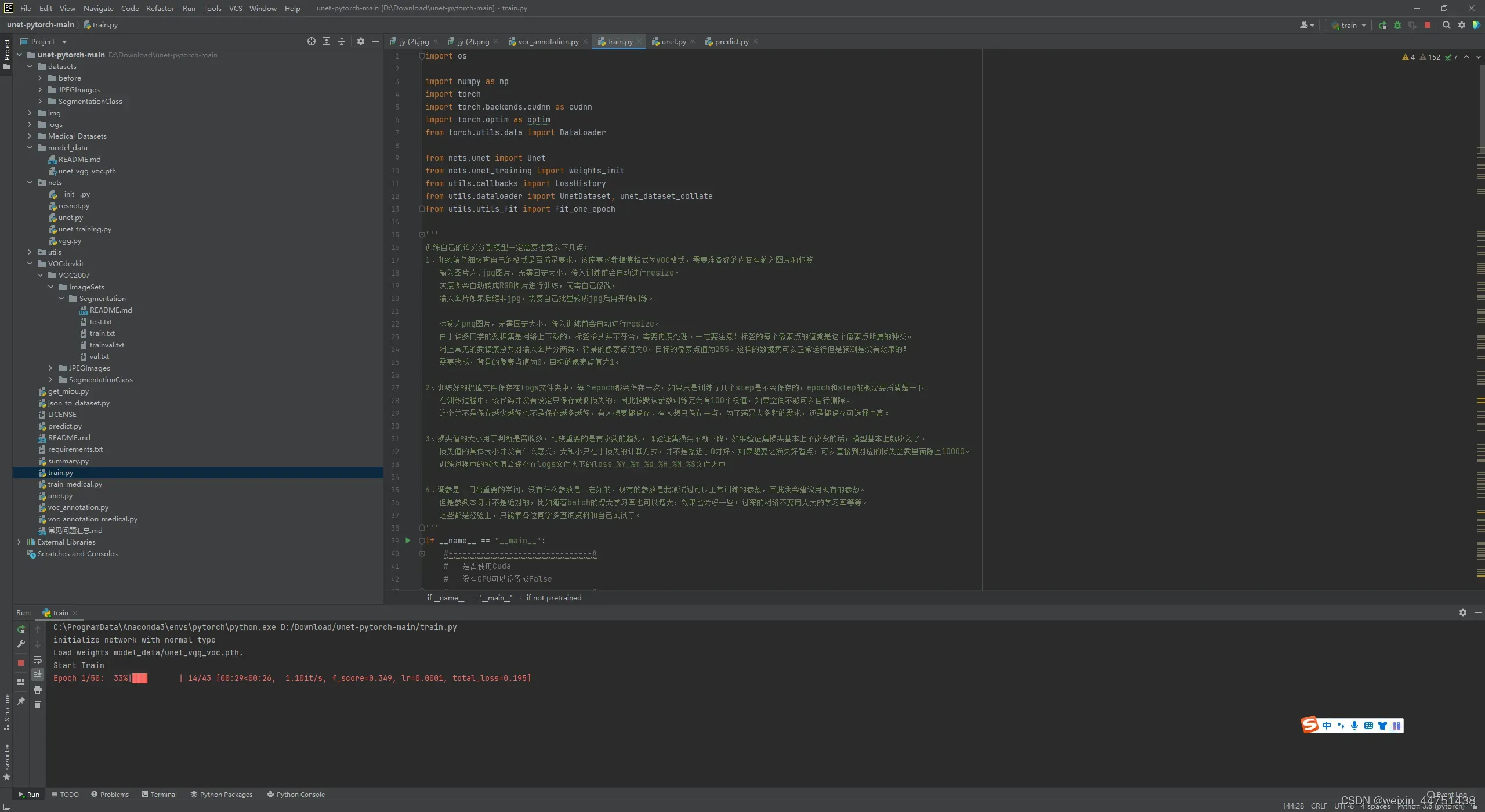
运行train.py文件开始训练
4. 开始预测
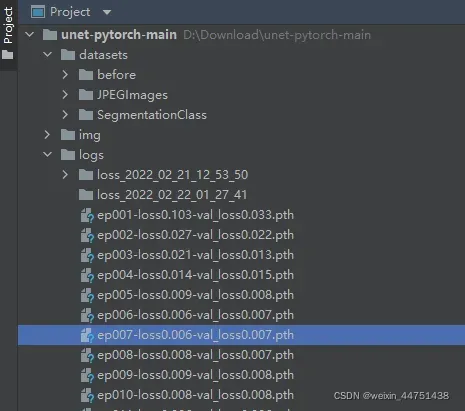
1.将logs中权值文件复制到modal_data下
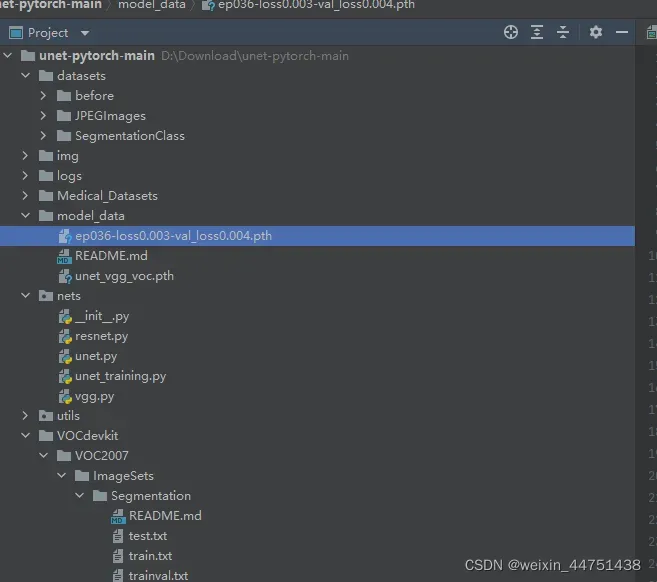
2. 修改unet.py文件中 为下图所示
3. 打开predict.py文件
mode为读取的是图片,摄像头,或者视频
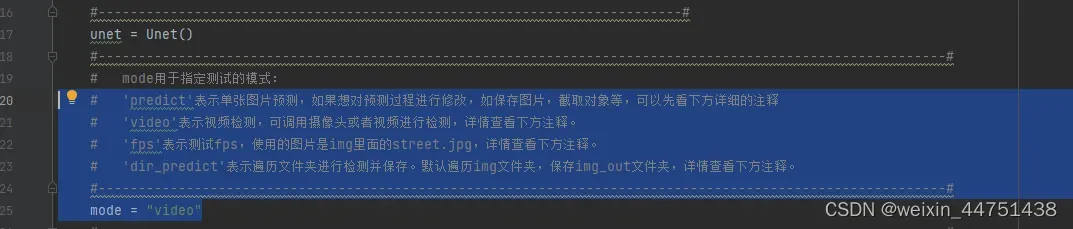
4.运行predict.py文件
视频资料可参考B站博主:Pytorch 搭建自己的Unet语义分割平台(Bubbliiiing 深度学习 教程)_哔哩哔哩_bilibili![]() https://www.bilibili.com/video/BV1rz4y117rR?p=9
https://www.bilibili.com/video/BV1rz4y117rR?p=9
版权声明:本文为博主风吹吹就过原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_44751438/article/details/123058427