一、通过提取语音的MFCC参数,与提前制作好的语音模板进行DTW匹配,实现0-9数字语音识别,且识别率达到一定要求,可以区分0-9中数字以及鉴别非0-9数字语音
二、对充足的模板进行聚类,找到聚类中心,可视化聚类结果,通过实验设定阈值,实现聚类方法的0-9数字语音识别。
(1)流程图: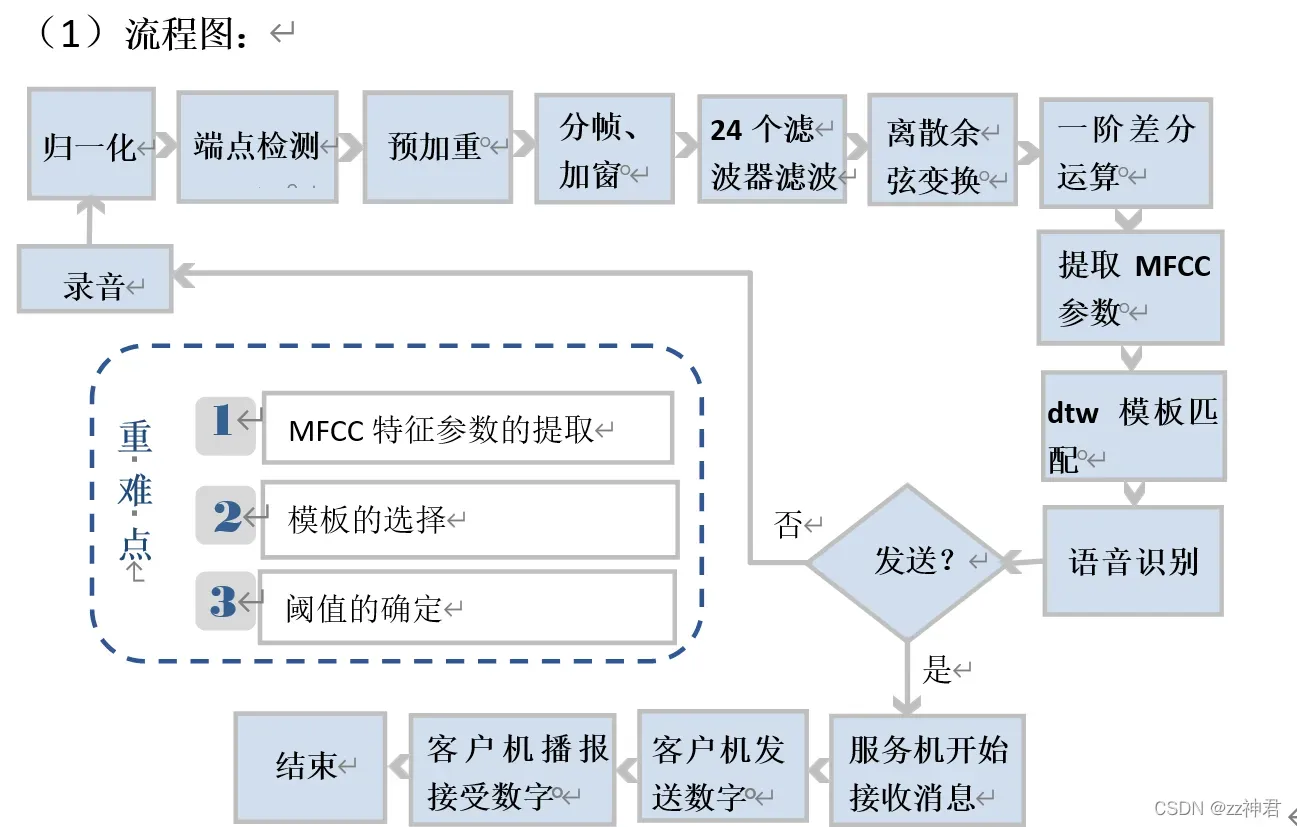
(2)MFCC参数提取
- 语音预处理
假代码:
x←读入的语音;
fs←48000; %系统自己设置的
x← x变为浮点型/x的最大值 %归一化
端点检测:
帧长←256;
帧移←80;
短时能量高门限←20;
短时能量低门限←2;
过零率高门限←10;
过零率低门限←5;
最长静音长度←8;
最短静音长度←15;
状态←0静音状态;
语音长度←0;
静音长度←0;
tmp1←分帧(x(1:end-1), 帧长,帧移);
tmp2←分帧(x(2:end) , 帧长,帧移);
signs←(tmp1.*tmp2)<0;
diffs采样率←(tmp1 - tmp2)>0.02;
过零率←sum(signs.*diffs采样率,2);
短时能量←求和 ((绝对值(分帧(x, 帧长,帧移)),2);
能量最高限←最小值(能量高门限, 最大值(短时能量)/4);
能量最低限←最小值(能量低门限, 最大值(短时能量)/8);
起始点←0
终止点←0
语音段数←0
所有语音段的起点←[]
所有语音段的终点←[]
for n←1:帧数
switch 状态
case 0或1 : %(静音或可能开始)
if 短时能量(n)>能量最高限 then
语音起始点←最大值(n-语音长度-1,1);
状态←2
静音长度←0
语音长度←语音长度+1;
elseif 短时能量(n) >能量最低限||过零率(n) >过零率最低限 then
状态←1;
语音长度←语音长度+1;
else
状态←0;
语音长度←0;
end
case 2 %(语音段)
if 短时能量(n) > 能量最低限 ||过零率(n) > 过零率最低限 then
语音长度←语音长度+1;
else
静音长度←静音长度+1;
if 静音长度←max静音长度 then
语音长度←语音长度+1;
elseif 语音长度 ← 最短静音长度 then
静音状态←0;
静音长度←0;
语音长度←0;
else
状态←3;
end
end
case 3
语音段个数←语音段个数+1;
语音长度←语音长度-取整数(静音长度/2);
语音终点←语音起始点+语音长度-1;
所有语音段起点(1,语音段个数)←语音起始点*帧移;
所有语音段终点(1,语音段个数)←语音终点*帧移;
end
end
x←x(所有语音段起点:所有语音段终点) %端点检测结果
预强调:
加重系数←0.98
for i←2:x的长度
y←x-x*加重系数
- 参数提取
假代码:
24个滤波器设计:
最高语音频率←fs/2;
耳朵响应频率←2595*log10(1+最高语音频率/700);
三角滤波器的个数←24;
帧长←向下取整(0.03*fs);
i←0:25;
滤波器中心频率←700*(10.^(耳朵响应频率/2595*i/(三角滤波器的个数+1))-1);
滤波器←设置0矩阵(24,帧长);
for m←1:24
for k←1:帧长
i←最高语音频率*k/帧长;
if (滤波器中心频率(m)←i)&&(i←滤波器中心频率(m+1))
滤波器(m,k)←(i-滤波器中心频率(m))/(滤波器中心频率(m+1)-滤波器中心频率(m));
else if (滤波器中心频率(m+1)←i)&&(i←滤波器中心频率(m+2))
滤波器(m,k)←(滤波器中心频率(m+2)-i)/(滤波器中心频率(m+2)-滤波器中心频率(m+1));
else
滤波器(m,k)←0;
end
end
end
end
MFCC参数求取(包括分帧、加窗):
离散余弦系数←设置零矩阵(12,24);
for k←1:12
n←1:24;
离散余弦系数(k,:)←cos((2*n-1)*k*pi/(2*24));
end
汉明窗←hamming(帧长);
帧移←向下取整(0.25*帧长);
帧数←向下取整((len-帧长)/帧移+1);
c1←设置零矩阵(帧数,12); %储存MFCC参数
for i←1:帧数
分帧后的音频←y(帧移*(i-1)+1:帧移*(i-1)+帧长); %分帧
w ← 分帧后的音频.* 汉明窗;
Fx←绝对值(快速傅里叶变换(w));
s←取对数(滤波器*Fx.^2);
c1(i,:)←(离散余弦变换系数*s)';
end
一阶差分运算:
差分参数←设置零矩阵(size(c1));
for i←3:size(c1,1)-2
差分参数(i,:)←-2*c1(i-2,:)-c1(i-1,:)+c1(i+1,:)+2*c1(i+2,:);
end
差分参数←差分参数/3;
mfcc←[c1 差分参数]; %合并mfcc参数和一阶差分mfcc参数
mfcc←mfcc(3:size(c1,1)-2,:);%去除首尾两帧,因为这两帧的一阶差分参数为0
- 三角带通滤波器的主要目的:滤波器组对频谱进行平滑化,并消除谐波的作用,突显原先语音的共振峰。(因此一段语音的音调或音高,是不会呈现在 MFCC 参数内,换句话说,以 MFCC 为特征的语音辨识系统,并不会受到输入语音的音调不同而有所影响) 此外,还可以降低运算量。
- mfcc即为最终提取的MFCC参数,由于提取的MFCC参数中含有24个滤波器滤波后的参数,以及滤波参数的一阶差分系数,因此提取的MFCC参数同时包含了语音的静态和动态信息,提高系统的识别性能。
(3)模板选择
本小组通过语音的MFCC参数与所有模板匹配,进行DTW运算取最小值对应模板为识别出的数字,因此模板的选择直接关系到识别的准确率。
本小组成员录音0-9所有数字,每个数字10个录音,考虑到每个数字的语音长短、语音语调,甚至环境噪音等进行录音,一共100个录音文件生成100个MFCC矩阵作为模板,以供DTW模板匹配。对于0-9每个数字区分的准确率还是比较高的,但3和9识别率不是很高,这和模板与端点检测有关,通过多次试验,得到:
(4)阈值确定
本次模板中只有0-9的数字,因此对于0-9以外的音频应该加以区分,本小组采用实验试凑法确定阈值。
通过大量实验验证发现,在环境比较安静,录音比较纯正和正常的情况下,经DTW模板匹配后的距离大致在 ,为留有一定余量,最终确定阈值为 ,可以区分0-9数字和部分英文字母、我、他等的发音和多音节英文、数字的发音。实验中最初确定的是 ,但英文字母a一直会错认为1,如果取 ,则认为’a’是无法识别的非数字,同样,确定阈值后0-9数字识别率也会下降,最终准确率约为83%,准确率下降不多,可以接受。
(5)GUI界面
GUI界面如下图所示,上面三个坐标显示框分别显示录音音频、端点检测后的音频、以及24个MEL滤波器组。下设功能按键,点开始录音,后出现信息提示框显示‘正在录音’,停止录音中包含端点检测过程,点停止录音后前两个坐标显示录音音频和端点检测后的音频,点识别后回在下方显示栏显示识别出的数字并在第三个坐标中显示24个MEL滤波器组。点击“拨号”前需服务机(接收数据电脑)先运行MATLAB程序,开启接收状态,再点击拨号,把目前所有已识别的数字(识别栏显示的数字)发送到服务机,服务机接收到数据后用电子音依次播报每个数据。 - 通过全局变量I增加功能:
- “播放”:在检测到所有识别的记录端点后播放结果。
- “取消”:取消当前号码识别结果,坐标和号码显示栏均显示上次识别后的号码。
- “清除”:清除所有已识别的数字,三个坐标恢复到原来的状态——空白状态。
- “关闭”:关闭界面并清除缓存。
- “保存录音”:保存本次录音,可以自定义文件名
- “打开文件”:打开本电脑里的音频文件,支持m4a、mp3、wav等音频格式,若未打开音频文件则显示对话框“未打开音频文件”,打开文件后相当于停止录音,前两个坐标同时显示原始音频和端点检测后的音频,可以直接识别。
(拨号:涉及matlab信息发送,这里不提)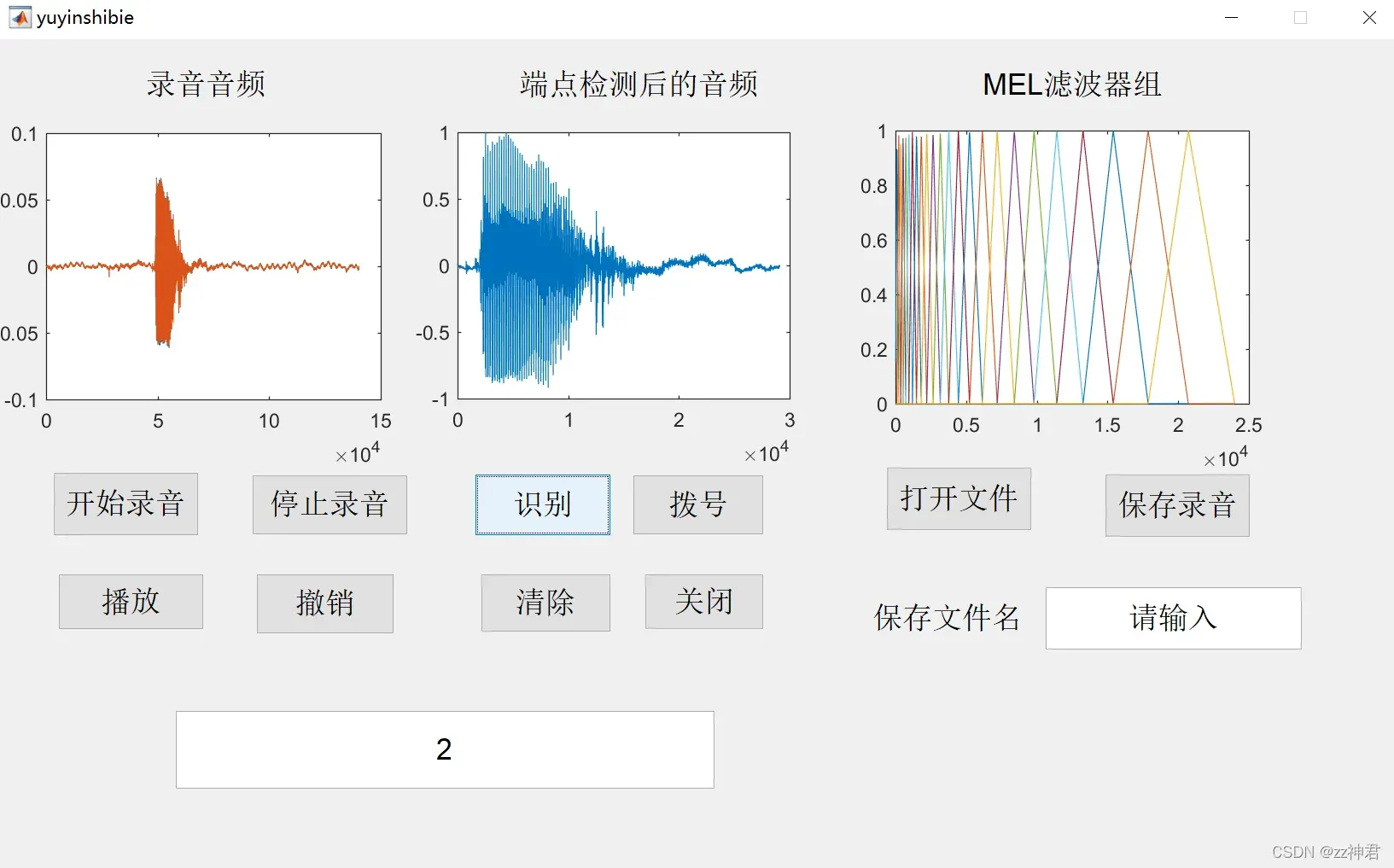
部分代码放在这里,后面会上传整个项目供参考:
端点检测:
global J;
J=J+1;
global msg;
global X0;
close(msg);
stop(handles.recObj); % 停止录音
% thehandles=handles;
handles.Sample=getaudiodata(handles.recObj);% 获取录音
guidata(hObject,handles);
X0{J,1}=handles.Sample;
plot(handles.axes1,cell2mat(X0(J,1)));
x=handles.Sample;
%% ******************端点检测******************
x = double(x);
x = x / max(abs(x));
%常数设置
FrameLen = 256;%帧长为256点
FrameInc = 80;%帧移为80点
amp1 = 20;%初始短时能量高门限
amp2 = 2;%初始短时能量低门限
zcr1 = 10;%初始短时过零率高门限
zcr2 = 5;%初始短时过零率低门限
maxsilence = 8; % 8*10ms = 80ms
%语音段中允许的最大静音长度,如果语音段中的静音帧数未超过此值,则认为语音还没结束;如果超过了
%该值,则对语音段长度count进行判断,若count<minlen,则认为前面的语音段为噪音,舍弃,跳到静音
%状态0;若count>minlen,则认为语音段结束;
minlen = 15; % 15*10ms = 150ms
%语音段的最短长度,若语音段长度小于此值,则认为其为一段噪音
status = 0; %初始状态为静音状态
count = 0; %初始语音段长度为0
silence = 0; %初始静音段长度为0
%计算过零率
x1=x(1:end-1);
x2=x(2:end);
%分帧
tmp1=enframe(x1,FrameLen,FrameInc);
tmp2=enframe(x2,FrameLen,FrameInc);
signs = (tmp1.*tmp2)<0;
diffs = (tmp1 -tmp2)>0.02;
zcr = sum(signs.*diffs, 2);%一帧一个值
%计算短时能量
%一帧一个值
%amp = sum(abs(enframe(filter([1 -0.9375], 1, x), FrameLen, FrameInc)), 2);
amp = sum(abs(enframe(x, FrameLen, FrameInc)), 2);
%调整能量门限
amp1 = min(amp1, max(amp)/4);
amp2 = min(amp2, max(amp)/8);
%开始端点检测
%For循环,整个信号各帧比较
%根据各帧能量判断帧所处的阶段
x1 = 0;
x2 = 0;
v_num=0;%记录语音段数
v_Begin=[];%记录所有语音段的起点
v_End=[];%记录所有语音段的终点
%length(zcr)即为帧数
for n=1:length(zcr)
goto = 0;
switch status
case {0,1} % 0 = 静音, 1 = 可能开始
if amp(n) > amp1 % 确信进入语音段
x1 = max(n-count-1,1);
% '打印每个x1*FrameInc'
% x1*FrameInc
status = 2;
silence = 0;
count = count + 1;
elseif amp(n) > amp2 | ... % 可能处于语音段
zcr(n) > zcr2
status = 1;
count = count + 1;
else % 静音状态
status = 0;
count = 0;
end
case 2, % 2 = 语音段
if amp(n) > amp2 | ... % 保持在语音段
zcr(n) > zcr2
count = count + 1;
else % 语音将结束
silence = silence+1;
if silence < maxsilence % 静音还不够长,尚未结束
count = count + 1;
elseif count < minlen % 语音长度太短,认为是噪声
status = 0;
silence = 0;
count = 0;
else % 语音结束
status = 3;
end
end
case 3,
%break;
%记录当前语音段数据
v_num=v_num+1; %语音段个数加一
count = count-silence/2;
x2 = x1 + count -1;
v_Begin(1,v_num)=x1*FrameInc;
v_End(1,v_num)=x2*FrameInc;
%不跳出 数据归零继续往下查找下一段语音
status = 0; %初始状态为静音状态
count = 0; %初始语音段长度为0
silence = 0; %初始静音段长度为0
end
end
if length(v_End)==0
x2 = x1 + count -1;
v_Begin(1,1)=x1*FrameInc;
v_End(1,1)=x2*FrameInc;
end
lenafter=0;
for len=1:length(v_End)
tmp=v_End(1,len)-v_Begin(1,len);
lenafter=lenafter+tmp;
end
lenafter;
afterEndDet=zeros(lenafter,1);%返回去除静音段的语音信号
beginnum=0;
endnum=0;
for k=1:length(v_End)
tmp=x(v_Begin(1,k):v_End(1,k));
beginnum=endnum+1;
endnum=beginnum+v_End(1,k)-v_Begin(1,k);
afterEndDet(beginnum:endnum)=tmp;
end
plot(handles.axes2,tmp);
global X;
X{J,1}=tmp;
语音识别
global X;
global J;
x=cell2mat(X(J,1));
fs=48000;
fh=fs/2; % fs=8000Hz,fh=4000Hz 语音信号的频率一般在300-3400Hz,所以一般情况下采样频率设为8000Hz即可。
max_melf=2595*log10(1+fh/700);%耳朵响应频率
M=24;%三角滤波器的个数
N=floor(0.03*fs);%设置帧长
i=0:25;
f=700*(10.^(max_melf/2595*i/(M+1))-1);%将mei频域中的 各滤波器的中心频率 转到实际频率
F=zeros(24,N);
for m=1:24
for k=1:N
i=fh*k/N;
if (f(m)<=i)&&(i<=f(m+1))
F(m,k)=(i-f(m))/(f(m+1)-f(m));
else if (f(m+1)<=i)&&(i<=f(m+2))
F(m,k)=(f(m+2)-i)/(f(m+2)-f(m+1));
else
F(m,k)=0;
end
end
end
end
axes(handles.axes3);
plot((1:N)*fh/N,F);
%%%%%%%%%%%%%%%DCT系数%%%%%%%%%%%
dctcoef=zeros(12,24);
for k=1:12
n=1:24;
dctcoef(k,:)=cos((2*n-1)*k*pi/(2*24));
end
%%%%%%%%%%%对语音信号进行预加重处理%%%%%%%%%%
len=length(x);
alpha=0.98;
y=zeros(len,1);
for i=2:len
y(i)=x(i)-alpha*x(i-1);
end
%%%%%%%%%%%%%%%MFCC特征参数的求取%%%%%%%%%%%%
h=hamming(N);%256*1
num=floor(0.25*N); %帧移
count=floor((len-N)/num+1);%帧数
c1=zeros(count,12);
for i=1:count
x_frame=y(num*(i-1)+1:num*(i-1)+N);%256*1
w = x_frame.* h;%
Fx=abs(fft(w));% Fx=abs(fft(x_frame));
s=log(F*Fx.^2);%取对数
c1(i,:)=(dctcoef*s)'; %离散余弦变换
end
%%%%%%%%%%%%差分系数%%%%%%%%%%%
dtm = zeros(size(c1));
for i=3:size(c1,1)-2
dtm(i,:) = -2*c1(i-2,:) - c1(i-1,:) + c1(i+1,:) + 2*c1(i+2,:);
end
dtm = dtm / 3;
%%%%合并mfcc参数和一阶差分mfcc参数%%%%%
ccc = [c1 dtm];
%去除首尾两帧,因为这两帧的一阶差分参数为0
ccc = ccc(3:size(c1,1)-2,:);
% ccc=ccc(:,2:20);
% save('moban8','ccc');
fileFolder='模板\';
dirOutput=dir(strcat(fileFolder,'*'));
fileNames={dirOutput.name};
len = length(fileNames);
for I=3:len
K_Trace = strcat(fileFolder, fileNames(I));
eval(['y','=','load(K_Trace{1,1})',';']);
Y{I-2,1}=cat(1,y.ccc);%按行读取
D(I-2,1)=dtw(cell2mat(Y(I-2,1)),ccc);
end
min1=10^310;
k=-1;
for i=1:100
if (D(i,1)<=min1)
min1=D(i,1);
k=i;
end
end
global shu;
if min1>3*10^4
msgbox('无法识别');
J=J-1;
else
if k>0&&k<=10
shu(J)=0;
elseif k>10&&k<=20
shu(J)=1;
elseif k>20&&k<=30
shu(J)=2;
elseif k>30&&k<=40
shu(J)=3;
elseif k>40&&k<=50
shu(J)=4;
elseif k>50&&k<=60
shu(J)=5;
elseif k>60&&k<=70
shu(J)=6;
elseif k>70&&k<=80
shu(J)=7;
elseif k>80&&k<=90
shu(J)=8;
elseif k>90&&k<=100
shu(J)=9;
end
c=num2str(shu(J));
n1=strcat(get(handles.edit1,'string')); % 获取数字号码
A=strcat(n1,c); %连接每次识别出的号码
set(handles.edit1,'string',A); % 显示号码
end
版权声明:本文为博主zz神君原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_43808138/article/details/123184195